Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.

3.4 Sampling Techniques in Quantitative Research
Target population.
The target population includes the people the researcher is interested in conducting the research and generalizing the findings on. 40 For example, if certain researchers are interested in vaccine-preventable diseases in children five years and younger in Australia. The target population will be all children aged 0–5 years residing in Australia. The actual population is a subset of the target population from which the sample is drawn, e.g. children aged 0–5 years living in the capital cities in Australia. The sample is the people chosen for the study from the actual population (Figure 3.9). The sampling process involves choosing people, and it is distinct from the sample. 40 In quantitative research, the sample must accurately reflect the target population, be free from bias in terms of selection, and be large enough to validate or reject the study hypothesis with statistical confidence and minimise random error. 2
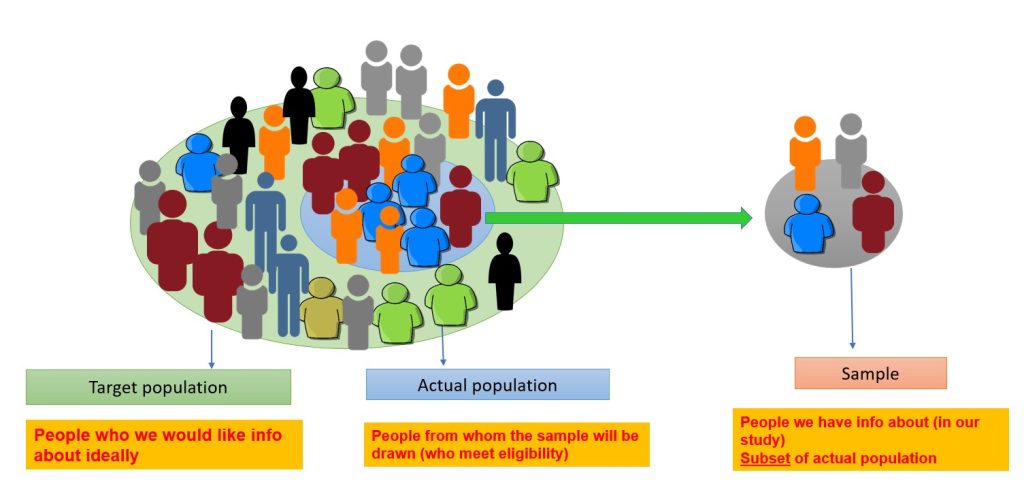
Sampling techniques
Sampling in quantitative research is a critical component that involves selecting a representative subset of individuals or cases from a larger population and often employs sampling techniques based on probability theory. 41 The goal of sampling is to obtain a sample that is large enough and representative of the target population. Examples of probability sampling techniques include simple random sampling, stratified random sampling, systematic random sampling and cluster sampling ( shown below ). 2 The key feature of probability techniques is that they involve randomization. There are two main characteristics of probability sampling. All individuals of a population are accessible to the researcher (theoretically), and there is an equal chance that each person in the population will be chosen to be part of the study sample. 41 While quantitative research often uses sampling techniques based on probability theory, some non-probability techniques may occasionally be utilised in healthcare research. 42 Non-probability sampling methods are commonly used in qualitative research. These include purposive, convenience, theoretical and snowballing and have been discussed in detail in chapter 4.
Sample size calculation
In order to enable comparisons with some level of established statistical confidence, quantitative research needs an acceptable sample size. 2 The sample size is the most crucial factor for reliability (reproducibility) in quantitative research. It is important for a study to be powered – the likelihood of identifying a difference if it exists in reality. 2 Small sample-sized studies are more likely to be underpowered, and results from small samples are more likely to be prone to random error. 2 The formula for sample size calculation varies with the study design and the research hypothesis. 2 There are numerous formulae for sample size calculations, but such details are beyond the scope of this book. For further readings, please consult the biostatistics textbook by Hirsch RP, 2021. 43 However, we will introduce a simple formula for calculating sample size for cross-sectional studies with prevalence as the outcome. 2
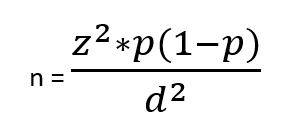
z is the statistical confidence; therefore, z = 1.96 translates to 95% confidence; z = 1.68 translates to 90% confidence
p = Expected prevalence (of health condition of interest)
d = Describes intended precision; d = 0.1 means that the estimate falls +/-10 percentage points of true prevalence with the considered confidence. (e.g. for a prevalence of 40% (0.4), if d=.1, then the estimate will fall between 30% and 50% (0.3 to 0.5).
Example: A district medical officer seeks to estimate the proportion of children in the district receiving appropriate childhood vaccinations. Assuming a simple random sample of a community is to be selected, how many children must be studied if the resulting estimate is to fall within 10% of the true proportion with 95% confidence? It is expected that approximately 50% of the children receive vaccinations
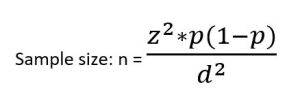
z = 1.96 (95% confidence)
d = 10% = 10/ 100 = 0.1 (estimate to fall within 10%)
p = 50% = 50/ 100 = 0.5
Now we can enter the values into the formula
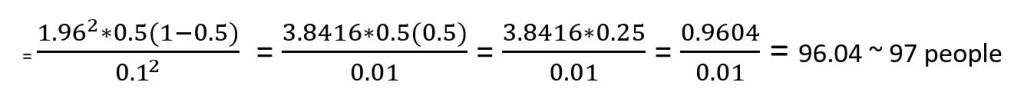
Given that people cannot be reported in decimal points, it is important to round up to the nearest whole number.
An Introduction to Research Methods for Undergraduate Health Profession Students Copyright © 2023 by Faith Alele and Bunmi Malau-Aduli is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
- En español – ExME
- Em português – EME
What are sampling methods and how do you choose the best one?
Posted on 18th November 2020 by Mohamed Khalifa

This tutorial will introduce sampling methods and potential sampling errors to avoid when conducting medical research.
Introduction to sampling methods
Examples of different sampling methods, choosing the best sampling method.
It is important to understand why we sample the population; for example, studies are built to investigate the relationships between risk factors and disease. In other words, we want to find out if this is a true association, while still aiming for the minimum risk for errors such as: chance, bias or confounding .
However, it would not be feasible to experiment on the whole population, we would need to take a good sample and aim to reduce the risk of having errors by proper sampling technique.
What is a sampling frame?
A sampling frame is a record of the target population containing all participants of interest. In other words, it is a list from which we can extract a sample.
What makes a good sample?
A good sample should be a representative subset of the population we are interested in studying, therefore, with each participant having equal chance of being randomly selected into the study.
We could choose a sampling method based on whether we want to account for sampling bias; a random sampling method is often preferred over a non-random method for this reason. Random sampling examples include: simple, systematic, stratified, and cluster sampling. Non-random sampling methods are liable to bias, and common examples include: convenience, purposive, snowballing, and quota sampling. For the purposes of this blog we will be focusing on random sampling methods .
Example: We want to conduct an experimental trial in a small population such as: employees in a company, or students in a college. We include everyone in a list and use a random number generator to select the participants
Advantages: Generalisable results possible, random sampling, the sampling frame is the whole population, every participant has an equal probability of being selected
Disadvantages: Less precise than stratified method, less representative than the systematic method

Example: Every nth patient entering the out-patient clinic is selected and included in our sample
Advantages: More feasible than simple or stratified methods, sampling frame is not always required
Disadvantages: Generalisability may decrease if baseline characteristics repeat across every nth participant

Example: We have a big population (a city) and we want to ensure representativeness of all groups with a pre-determined characteristic such as: age groups, ethnic origin, and gender
Advantages: Inclusive of strata (subgroups), reliable and generalisable results
Disadvantages: Does not work well with multiple variables

Example: 10 schools have the same number of students across the county. We can randomly select 3 out of 10 schools as our clusters
Advantages: Readily doable with most budgets, does not require a sampling frame
Disadvantages: Results may not be reliable nor generalisable

How can you identify sampling errors?
Non-random selection increases the probability of sampling (selection) bias if the sample does not represent the population we want to study. We could avoid this by random sampling and ensuring representativeness of our sample with regards to sample size.
An inadequate sample size decreases the confidence in our results as we may think there is no significant difference when actually there is. This type two error results from having a small sample size, or from participants dropping out of the sample.
In medical research of disease, if we select people with certain diseases while strictly excluding participants with other co-morbidities, we run the risk of diagnostic purity bias where important sub-groups of the population are not represented.
Furthermore, measurement bias may occur during re-collection of risk factors by participants (recall bias) or assessment of outcome where people who live longer are associated with treatment success, when in fact people who died were not included in the sample or data analysis (survivors bias).
By following the steps below we could choose the best sampling method for our study in an orderly fashion.
Research objectiveness
Firstly, a refined research question and goal would help us define our population of interest. If our calculated sample size is small then it would be easier to get a random sample. If, however, the sample size is large, then we should check if our budget and resources can handle a random sampling method.
Sampling frame availability
Secondly, we need to check for availability of a sampling frame (Simple), if not, could we make a list of our own (Stratified). If neither option is possible, we could still use other random sampling methods, for instance, systematic or cluster sampling.
Study design
Moreover, we could consider the prevalence of the topic (exposure or outcome) in the population, and what would be the suitable study design. In addition, checking if our target population is widely varied in its baseline characteristics. For example, a population with large ethnic subgroups could best be studied using a stratified sampling method.
Random sampling
Finally, the best sampling method is always the one that could best answer our research question while also allowing for others to make use of our results (generalisability of results). When we cannot afford a random sampling method, we can always choose from the non-random sampling methods.
To sum up, we now understand that choosing between random or non-random sampling methods is multifactorial. We might often be tempted to choose a convenience sample from the start, but that would not only decrease precision of our results, and would make us miss out on producing research that is more robust and reliable.
References (pdf)

Mohamed Khalifa
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on What are sampling methods and how do you choose the best one?

Thank you for this overview. A concise approach for research.

really helps! am an ecology student preparing to write my lab report for sampling.

I learned a lot to the given presentation.. It’s very comprehensive… Thanks for sharing…

Very informative and useful for my study. Thank you

Oversimplified info on sampling methods. Probabilistic of the sampling and sampling of samples by chance does rest solely on the random methods. Factors such as the random visits or presentation of the potential participants at clinics or sites could be sufficiently random in nature and should be used for the sake of efficiency and feasibility. Nevertheless, this approach has to be taken only after careful thoughts. Representativeness of the study samples have to be checked at the end or during reporting by comparing it to the published larger studies or register of some kind in/from the local population.

Thank you so much Mr.mohamed very useful and informative article
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

How to read a funnel plot
This blog introduces you to funnel plots, guiding you through how to read them and what may cause them to look asymmetrical.

Internal and external validity: what are they and how do they differ?
Is this study valid? Can I trust this study’s methods and design? Can I apply the results of this study to other contexts? Learn more about internal and external validity in research to help you answer these questions when you next look at a paper.

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.
Sampling Methods & Strategies 101
Everything you need to know (including examples)
By: Derek Jansen (MBA) | Expert Reviewed By: Kerryn Warren (PhD) | January 2023
If you’re new to research, sooner or later you’re bound to wander into the intimidating world of sampling methods and strategies. If you find yourself on this page, chances are you’re feeling a little overwhelmed or confused. Fear not – in this post we’ll unpack sampling in straightforward language , along with loads of examples .
Overview: Sampling Methods & Strategies
- What is sampling in a research context?
- The two overarching approaches
Simple random sampling
Stratified random sampling, cluster sampling, systematic sampling, purposive sampling, convenience sampling, snowball sampling.
- How to choose the right sampling method
What (exactly) is sampling?
At the simplest level, sampling (within a research context) is the process of selecting a subset of participants from a larger group . For example, if your research involved assessing US consumers’ perceptions about a particular brand of laundry detergent, you wouldn’t be able to collect data from every single person that uses laundry detergent (good luck with that!) – but you could potentially collect data from a smaller subset of this group.
In technical terms, the larger group is referred to as the population , and the subset (the group you’ll actually engage with in your research) is called the sample . Put another way, you can look at the population as a full cake and the sample as a single slice of that cake. In an ideal world, you’d want your sample to be perfectly representative of the population, as that would allow you to generalise your findings to the entire population. In other words, you’d want to cut a perfect cross-sectional slice of cake, such that the slice reflects every layer of the cake in perfect proportion.
Achieving a truly representative sample is, unfortunately, a little trickier than slicing a cake, as there are many practical challenges and obstacles to achieving this in a real-world setting. Thankfully though, you don’t always need to have a perfectly representative sample – it all depends on the specific research aims of each study – so don’t stress yourself out about that just yet!
With the concept of sampling broadly defined, let’s look at the different approaches to sampling to get a better understanding of what it all looks like in practice.

The two overarching sampling approaches
At the highest level, there are two approaches to sampling: probability sampling and non-probability sampling . Within each of these, there are a variety of sampling methods , which we’ll explore a little later.
Probability sampling involves selecting participants (or any unit of interest) on a statistically random basis , which is why it’s also called “random sampling”. In other words, the selection of each individual participant is based on a pre-determined process (not the discretion of the researcher). As a result, this approach achieves a random sample.
Probability-based sampling methods are most commonly used in quantitative research , especially when it’s important to achieve a representative sample that allows the researcher to generalise their findings.
Non-probability sampling , on the other hand, refers to sampling methods in which the selection of participants is not statistically random . In other words, the selection of individual participants is based on the discretion and judgment of the researcher, rather than on a pre-determined process.
Non-probability sampling methods are commonly used in qualitative research , where the richness and depth of the data are more important than the generalisability of the findings.
If that all sounds a little too conceptual and fluffy, don’t worry. Let’s take a look at some actual sampling methods to make it more tangible.
Need a helping hand?
Probability-based sampling methods
First, we’ll look at four common probability-based (random) sampling methods:
Importantly, this is not a comprehensive list of all the probability sampling methods – these are just four of the most common ones. So, if you’re interested in adopting a probability-based sampling approach, be sure to explore all the options.
Simple random sampling involves selecting participants in a completely random fashion , where each participant has an equal chance of being selected. Basically, this sampling method is the equivalent of pulling names out of a hat , except that you can do it digitally. For example, if you had a list of 500 people, you could use a random number generator to draw a list of 50 numbers (each number, reflecting a participant) and then use that dataset as your sample.
Thanks to its simplicity, simple random sampling is easy to implement , and as a consequence, is typically quite cheap and efficient . Given that the selection process is completely random, the results can be generalised fairly reliably. However, this also means it can hide the impact of large subgroups within the data, which can result in minority subgroups having little representation in the results – if any at all. To address this, one needs to take a slightly different approach, which we’ll look at next.
Stratified random sampling is similar to simple random sampling, but it kicks things up a notch. As the name suggests, stratified sampling involves selecting participants randomly , but from within certain pre-defined subgroups (i.e., strata) that share a common trait . For example, you might divide the population into strata based on gender, ethnicity, age range or level of education, and then select randomly from each group.
The benefit of this sampling method is that it gives you more control over the impact of large subgroups (strata) within the population. For example, if a population comprises 80% males and 20% females, you may want to “balance” this skew out by selecting a random sample from an equal number of males and females. This would, of course, reduce the representativeness of the sample, but it would allow you to identify differences between subgroups. So, depending on your research aims, the stratified approach could work well.

Next on the list is cluster sampling. As the name suggests, this sampling method involves sampling from naturally occurring, mutually exclusive clusters within a population – for example, area codes within a city or cities within a country. Once the clusters are defined, a set of clusters are randomly selected and then a set of participants are randomly selected from each cluster.
Now, you’re probably wondering, “how is cluster sampling different from stratified random sampling?”. Well, let’s look at the previous example where each cluster reflects an area code in a given city.
With cluster sampling, you would collect data from clusters of participants in a handful of area codes (let’s say 5 neighbourhoods). Conversely, with stratified random sampling, you would need to collect data from all over the city (i.e., many more neighbourhoods). You’d still achieve the same sample size either way (let’s say 200 people, for example), but with stratified sampling, you’d need to do a lot more running around, as participants would be scattered across a vast geographic area. As a result, cluster sampling is often the more practical and economical option.
If that all sounds a little mind-bending, you can use the following general rule of thumb. If a population is relatively homogeneous , cluster sampling will often be adequate. Conversely, if a population is quite heterogeneous (i.e., diverse), stratified sampling will generally be more appropriate.
The last probability sampling method we’ll look at is systematic sampling. This method simply involves selecting participants at a set interval , starting from a random point .
For example, if you have a list of students that reflects the population of a university, you could systematically sample that population by selecting participants at an interval of 8 . In other words, you would randomly select a starting point – let’s say student number 40 – followed by student 48, 56, 64, etc.
What’s important with systematic sampling is that the population list you select from needs to be randomly ordered . If there are underlying patterns in the list (for example, if the list is ordered by gender, IQ, age, etc.), this will result in a non-random sample, which would defeat the purpose of adopting this sampling method. Of course, you could safeguard against this by “shuffling” your population list using a random number generator or similar tool.

Non-probability-based sampling methods
Right, now that we’ve looked at a few probability-based sampling methods, let’s look at three non-probability methods :
Again, this is not an exhaustive list of all possible sampling methods, so be sure to explore further if you’re interested in adopting a non-probability sampling approach.
First up, we’ve got purposive sampling – also known as judgment , selective or subjective sampling. Again, the name provides some clues, as this method involves the researcher selecting participants using his or her own judgement , based on the purpose of the study (i.e., the research aims).
For example, suppose your research aims were to understand the perceptions of hyper-loyal customers of a particular retail store. In that case, you could use your judgement to engage with frequent shoppers, as well as rare or occasional shoppers, to understand what judgements drive the two behavioural extremes .
Purposive sampling is often used in studies where the aim is to gather information from a small population (especially rare or hard-to-find populations), as it allows the researcher to target specific individuals who have unique knowledge or experience . Naturally, this sampling method is quite prone to researcher bias and judgement error, and it’s unlikely to produce generalisable results, so it’s best suited to studies where the aim is to go deep rather than broad .

Next up, we have convenience sampling. As the name suggests, with this method, participants are selected based on their availability or accessibility . In other words, the sample is selected based on how convenient it is for the researcher to access it, as opposed to using a defined and objective process.
Naturally, convenience sampling provides a quick and easy way to gather data, as the sample is selected based on the individuals who are readily available or willing to participate. This makes it an attractive option if you’re particularly tight on resources and/or time. However, as you’d expect, this sampling method is unlikely to produce a representative sample and will of course be vulnerable to researcher bias , so it’s important to approach it with caution.
Last but not least, we have the snowball sampling method. This method relies on referrals from initial participants to recruit additional participants. In other words, the initial subjects form the first (small) snowball and each additional subject recruited through referral is added to the snowball, making it larger as it rolls along .
Snowball sampling is often used in research contexts where it’s difficult to identify and access a particular population. For example, people with a rare medical condition or members of an exclusive group. It can also be useful in cases where the research topic is sensitive or taboo and people are unlikely to open up unless they’re referred by someone they trust.
Simply put, snowball sampling is ideal for research that involves reaching hard-to-access populations . But, keep in mind that, once again, it’s a sampling method that’s highly prone to researcher bias and is unlikely to produce a representative sample. So, make sure that it aligns with your research aims and questions before adopting this method.
How to choose a sampling method
Now that we’ve looked at a few popular sampling methods (both probability and non-probability based), the obvious question is, “ how do I choose the right sampling method for my study?”. When selecting a sampling method for your research project, you’ll need to consider two important factors: your research aims and your resources .
As with all research design and methodology choices, your sampling approach needs to be guided by and aligned with your research aims, objectives and research questions – in other words, your golden thread. Specifically, you need to consider whether your research aims are primarily concerned with producing generalisable findings (in which case, you’ll likely opt for a probability-based sampling method) or with achieving rich , deep insights (in which case, a non-probability-based approach could be more practical). Typically, quantitative studies lean toward the former, while qualitative studies aim for the latter, so be sure to consider your broader methodology as well.
The second factor you need to consider is your resources and, more generally, the practical constraints at play. If, for example, you have easy, free access to a large sample at your workplace or university and a healthy budget to help you attract participants, that will open up multiple options in terms of sampling methods. Conversely, if you’re cash-strapped, short on time and don’t have unfettered access to your population of interest, you may be restricted to convenience or referral-based methods.
In short, be ready for trade-offs – you won’t always be able to utilise the “perfect” sampling method for your study, and that’s okay. Much like all the other methodological choices you’ll make as part of your study, you’ll often need to compromise and accept practical trade-offs when it comes to sampling. Don’t let this get you down though – as long as your sampling choice is well explained and justified, and the limitations of your approach are clearly articulated, you’ll be on the right track.

Let’s recap…
In this post, we’ve covered the basics of sampling within the context of a typical research project.
- Sampling refers to the process of defining a subgroup (sample) from the larger group of interest (population).
- The two overarching approaches to sampling are probability sampling (random) and non-probability sampling .
- Common probability-based sampling methods include simple random sampling, stratified random sampling, cluster sampling and systematic sampling.
- Common non-probability-based sampling methods include purposive sampling, convenience sampling and snowball sampling.
- When choosing a sampling method, you need to consider your research aims , objectives and questions, as well as your resources and other practical constraints .
If you’d like to see an example of a sampling strategy in action, be sure to check out our research methodology chapter sample .
Last but not least, if you need hands-on help with your sampling (or any other aspect of your research), take a look at our 1-on-1 coaching service , where we guide you through each step of the research process, at your own pace.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:

Excellent and helpful. Best site to get a full understanding of Research methodology. I’m nolonger as “clueless “..😉

Excellent and helpful for junior researcher!

Grad Coach tutorials are excellent – I recommend them to everyone doing research. I will be working with a sample of imprisoned women and now have a much clearer idea concerning sampling. Thank you to all at Grad Coach for generously sharing your expertise with students.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Indian J Dermatol
- v.61(5); Sep-Oct 2016
Methodology Series Module 5: Sampling Strategies
Maninder singh setia.
Epidemiologist, MGM Institute of Health Sciences, Navi Mumbai, Maharashtra, India
Once the research question and the research design have been finalised, it is important to select the appropriate sample for the study. The method by which the researcher selects the sample is the ‘ Sampling Method’. There are essentially two types of sampling methods: 1) probability sampling – based on chance events (such as random numbers, flipping a coin etc.); and 2) non-probability sampling – based on researcher's choice, population that accessible & available. Some of the non-probability sampling methods are: purposive sampling, convenience sampling, or quota sampling. Random sampling method (such as simple random sample or stratified random sample) is a form of probability sampling. It is important to understand the different sampling methods used in clinical studies and mention this method clearly in the manuscript. The researcher should not misrepresent the sampling method in the manuscript (such as using the term ‘ random sample’ when the researcher has used convenience sample). The sampling method will depend on the research question. For instance, the researcher may want to understand an issue in greater detail for one particular population rather than worry about the ‘ generalizability’ of these results. In such a scenario, the researcher may want to use ‘ purposive sampling’ for the study.
Introduction
The purpose of this section is to discuss various sampling methods used in research. After finalizing the research question and the research design, it is important to select the appropriate sample for the study. The method by which the researcher selects the sample is the “Sampling Method” [ Figure 1 ].

Flowchart from “Universe” to “Sampling Method”
Why do we need to sample?
Let us answer this research question: What is the prevalence of HIV in the adult Indian population?
The best response to this question will be obtained when we test every adult Indian for HIV. However, this is logistically difficult, time consuming, expensive, and difficult for a single researcher – do not forget about ethics of conducting such a study. The government usually conducts an exercise regularly to measure certain outcomes in the whole population – ”the census.” However, as researchers, we often have limited time and resources. Hence, we will have to select a few adult Indians who will consent to be a part of the study. We will test them for HIV and present out results (as our estimates of HIV prevalence). These selected individuals are called our “sample.” We hope that we have selected the appropriate sample that is required to answer our research question.
The researcher should clearly and explicitly mention the sampling method in the manuscript. The description of these helps the reviewers and readers assess the validity and generalizability of the results. Furthermore, the authors should also acknowledge the limitations of their sampling method and its effects on estimated obtained in the study.
Types of Methods
We will try to understand some of these sampling methods that are commonly used in clinical research. There are essentially two types of sampling methods: (1) Probability sampling – based on chance events (such as random numbers, flipping a coin, etc.) and (2) nonprobability sampling – based on researcher's choice, population that accessible and available.
What is a “convenience sample?”
Research question: How many patients with psoriasis also have high cholesterol levels (according to our definition)?
We plan to conduct the study in the outpatient department of our hospital.
This is a common scenario for clinical studies. The researcher recruits the participants who are easily accessible in a clinical setting – this type of sample is called a “convenience sample.” Furthermore, in such a clinic-based setting, the researcher will approach all the psoriasis patients that he/she comes across. They are informed about the study, and all those who consent to be the study are evaluated for eligibility. If they meet the inclusion criteria (and need not be excluded as per the criteria), they are recruited for the study. Thus, this will be “consecutive consenting sample.”
This method is relatively easy and is one of the common types of sampling methods used (particularly in postgraduate dissertations).
Since this is clinic-based sample, the estimates from such a study may not necessarily be generalizable to the larger population. To begin with, the patients who access healthcare potentially have a different “health-seeking behavior” compared with those who do not access health in these settings. Furthermore, many of the clinical cases in tertiary care centers may be severe, complicated, or recalcitrant. Thus, the estimates of biological parameters or outcomes may be different in these compared with the general population. The researcher should clearly discuss in the manuscript/report as to how the convenience sample may have biased the estimates (for example: Overestimated or underestimated the outcome in the population studied).
What is a “random sample?”
A “random sample” is a probability sample where every individual has an equal and independent probability of being selected in the sample.
Please note that “random sample” does not mean arbitrary sample. For example, if the researcher selects 10–12 individuals from the waiting area (without any structure), it is not a random sample. Randomization is a specific process, and only samples that are recruited using this process is a “random sample.”
What is a “simple random sample?”
Let us recruit a “simple random sample” in the above example. The center only allows a fixed number of patients every day. All the patients have to confirm the appointment a day in advance and should present in the clinic between 9 and 9:30 a.m. for the appointment. Thus, by 9:30 a.m., you will all have all the individuals who will be examined day.
We wish to select 50% of these patients for posttreatment survey.
- Make a list of all the patients present at 9:30 a.m.
- Give a number to each individual
- Use a “randomization method” to select five of these numbers. Although “random tables” have been used as a method of randomization, currently, many researchers use “computer-generated lists for random selection” of participants. Most of the statistical packages have programs for random selection of population. Please state the method that you have used for random selection in the manuscript
- Recruit the individuals whose numbers have been selected by the randomization method.
The process is described in Figure 2 .

Representation of Simple Random Sample
What is a major issue with this recruitment process?
As you may notice, “only males” have been recruited for the study. This scenario is possible in a simple random sample selection.
This is a limitation of this type of sampling method – population units which are smaller in number in the sampling frame may be underrepresented in this sample.
What is “stratified sample?”
In a stratified sample, the population is divided into two or more similar groups (based on demographic or clinical characteristics). The sample is recruited from each stratum. The researcher may use a simple random sample procedure within each stratum.
Let us address the limitation in the above example (selection of 50% of the participants for postprocedure survey).
- Divide the list into two strata: Males and females
- Use a “randomization method” to select three numbers among males and two numbers among females. As discussed earlier, the researcher may use random tables or computer generated random selection. Please state the method that you have used for random selection in the manuscript
The process is described in Figure 3 .

Representation of Stratified Random Sample
Thus, with this sampling method, we ensure that people from both sexes are included in the sample. This type of sampling method is used for sampling when we want to ensure that minority populations (in number) are adequately represented in the sample.
Kindly note that in this example, we sampled 50% of the population in each stratum. However, the researcher may oversample in one particular stratum and under-sample in the other. For instance, in this example, we may have taken three females and three males (if want to ensure equal representation of both). All this should be discussed explicitly in methods.
What is a “systematic sample?”
Sometimes, the researcher may decide to include study participants using a fixed pattern. For example, the researcher may recruit every second patient, or every patient whose registration ends with an even number or those who are admitted in certain days of the week (Tuesday/Thursday/Saturday). This type of sample is generally easy to implement. However, a lot of the recruitments are based on the researcher and may lead to selection bias. Furthermore, patients who come to the hospital may differ on different days of the week. For example, a higher proportion of working individuals may access the hospital on Saturdays.
This is not a “random sample.” Please do not write that “we selected the participants using a random sample method” if you have selected the sample systematically.
Another type of sampling discussed by some authors is “systematic random sample.” The steps for this method are:
- Make a list of all the potential recruits
- Using a random method (described earlier) to select a starting point (example number 4)
- Select this number and every fifth number from this starting point. Thus, the researcher will select number 9, 14, and so on.
Please note that the “skip” depends on the total number of potential participants and the total sample size. For instance, you have a total of fifty potential participants and you wish to recruit ten participants, do not skip to every 10 th patient.
Aday (1996) states that the skip depends on the total number of participants and the total sample size required.
- Fraction = total number of participants/total sample size
- In the above example, it will be 50/10 = 5
- Thus, using a random table or computer-generated random number selection, the researcher will select a random number from 1 to 5
- The number selected in two
- The researcher selects the second patient
- The next patient will be the fifth patient after patient number two – patient number 7
- The next patient will be patient number 12 and so on.
What is a “cluster sample?”
For some studies, the sample is selected from larger units or “clusters.” This type of method is generally used for “community-based studies.”
Research question: What is the prevalence of dermatological conditions in school children in city XXXXX?
In this study, we will select students from multiple schools. Thus, each school becomes one cluster. Each individual child in the school has much in common with other children in the same school compared with children from other schools (for example, they are more likely to have the same socioeconomic background). Thus, these children are recruited from the same cluster.
If the researcher uses “cluster sample,” he/she also performs “cluster analysis.” The statistical methods for these are different compared with nonclustered analysis (the methods we use commonly).
What is a “multistage sample?”
In many studies, we have to combine multiple methods for the appropriate and required sample.
Let us use a multistage sample to answer this research question.
Research question: What is the prevalence of dermatological conditions in school children in city XXXXX? (Assumption: The city is divided into four zones).
We have a list of all the schools in the city. How do we sample them?
Method 1: Select 10% of the schools using “simple random sample” method.
Question: What is the problem with this type of method?
Answer: As discussed earlier, it is possible that we may miss most of the schools from one particular zone.
However, we are interested to ensure that all zones are adequately represented in the sample.
- Stage 1: List all the schools in all zones
- Stage 2: Select 10% of schools from each zone using “random selection method” (first stratum)
- Stage 3: List all the students in Grade VIII, IX, and X(population of interest) in each school (second stratum)
- Stage 4: Create a separate list for males and females in each grade in each school (third stratum)
- Stage 5: Select 10% of males and females in each grade in each school.
Please note that this is just an example. You may have to change the proportion selected from each stratum based on the sample size and the total number of individuals in each stratum.
What are other types of sampling methods?
Although these are the common types of sampling methods that we use in clinical studies, we have also listed some other sampling methods in Table 1 .
Some other types of sampling methods

- It is important to understand the different sampling methods used in clinical studies. As stated earlier, please mention this method clearly in the manuscript
- Do not misrepresent the sampling method. For example, if you have not used “random method” for selection, do not state it in the manuscript
- Sometimes, the researcher may want to understand an issue in greater detail for one particular population rather than worry about the “generalizability” of these results. In such a scenario, the researcher may want to use ‘purposive sampling’.
Financial support and sponsorship
Conflicts of interest.
There are no conflicts of interest.
Bibliography

7.3 Sampling in Quantitative Research
Learning objectives.
- Describe how probability sampling differs from nonprobability sampling.
- Define generalizability, and describe how it is achieved in probability samples.
- Identify the various types of probability samples, and provide a brief description of each.
Quantitative researchers are often interested in being able to make generalizations about groups larger than their study samples. While there are certainly instances when quantitative researchers rely on nonprobability samples (e.g., when doing exploratory or evaluation research), quantitative researchers tend to rely on probability sampling techniques. The goals and techniques associated with probability samples differ from those of nonprobability samples. We’ll explore those unique goals and techniques in this section.
Probability Sampling
Unlike nonprobability sampling, probability sampling Sampling techniques for which a person’s likelihood of being selected for membership in the sample is known. refers to sampling techniques for which a person’s (or event’s) likelihood of being selected for membership in the sample is known. You might ask yourself why we should care about a study element’s likelihood of being selected for membership in a researcher’s sample. The reason is that, in most cases, researchers who use probability sampling techniques are aiming to identify a representative sample A sample that resembles the population from which it was drawn in all the ways that are important for the research being conducted. from which to collect data. A representative sample is one that resembles the population from which it was drawn in all the ways that are important for the research being conducted. If, for example, you wish to be able to say something about differences between men and women at the end of your study, you better make sure that your sample doesn’t contain only women. That’s a bit of an oversimplification, but the point with representativeness is that if your population varies in some way that is important to your study, your sample should contain the same sorts of variation.
Obtaining a representative sample is important in probability sampling because a key goal of studies that rely on probability samples is generalizability The idea that a study’s results will tell us something about a group larger than the sample from which the findings were generated. . In fact, generalizability is perhaps the key feature that distinguishes probability samples from nonprobability samples. Generalizability refers to the idea that a study’s results will tell us something about a group larger than the sample from which the findings were generated. In order to achieve generalizability, a core principle of probability sampling is that all elements in the researcher’s target population have an equal chance of being selected for inclusion in the study. In research, this is the principle of random selection The principle that all elements in a researcher’s target population have an equal chance of being selected for inclusion in the study. . Random selection is a mathematical process that we won’t go into too much depth about here, but if you have taken or plan to take a statistics course, you’ll learn more about it there. The important thing to remember about random selection here is that, as previously noted, it is a core principal of probability sampling. If a researcher uses random selection techniques to draw a sample, he or she will be able to estimate how closely the sample represents the larger population from which it was drawn by estimating the sampling error. Sampling error The extent to which a sample represents its population on a particular parameter. is a statistical calculation of the difference between results from a sample and the actual parameters The actual characteristics of a population on any given variable; determined by measuring all elements in a population (as opposed to measuring elements from a sample). of a population.
Types of Probability Samples
There are a variety of probability samples that researchers may use. These include simple random samples, systematic samples, stratified samples, and cluster samples.
Simple random samples The most basic type of probability sample; a researcher begins with a list of every member of his or her population of interest, numbers each element sequentially, and then randomly selects the elements from which he or she will collect data. are the most basic type of probability sample, but their use is not particularly common. Part of the reason for this may be the work involved in generating a simple random sample. To draw a simple random sample, a researcher starts with a list of every single member, or element, of his or her population of interest. This list is sometimes referred to as a sampling frame A list of all elements in a population. . Once that list has been created, the researcher numbers each element sequentially and then randomly selects the elements from which he or she will collect data. To randomly select elements, researchers use a table of numbers that have been generated randomly. There are several possible sources for obtaining a random number table. Some statistics and research methods textbooks offer such tables as appendices to the text. Perhaps a more accessible source is one of the many free random number generators available on the Internet. A good online source is the website Stat Trek, which contains a random number generator that you can use to create a random number table of whatever size you might need ( http://stattrek.com/Tables/Random.aspx ). Randomizer.org also offers a useful random number generator ( http://randomizer.org ).
As you might have guessed, drawing a simple random sample can be quite tedious. Systematic sampling A researcher divides a study population into relevant subgroups then draws a sample from each subgroup. techniques are somewhat less tedious but offer the benefits of a random sample. As with simple random samples, you must be able to produce a list of every one of your population elements. Once you’ve done that, to draw a systematic sample you’d simply select every k th element on your list. But what is k , and where on the list of population elements does one begin the selection process? k is your selection interval The distance between elements selected for inclusion in a study. or the distance between the elements you select for inclusion in your study. To begin the selection process, you’ll need to figure out how many elements you wish to include in your sample. Let’s say you want to interview 25 fraternity members on your campus, and there are 100 men on campus who are members of fraternities. In this case, your selection interval, or k , is 4. To arrive at 4, simply divide the total number of population elements by your desired sample size. This process is represented in Figure 7.5 "Formula for Determining Selection Interval for Systematic Sample" .
Figure 7.5 Formula for Determining Selection Interval for Systematic Sample

To determine where on your list of population elements to begin selecting the names of the 25 men you will interview, select a random number between 1 and k , and begin there. If we randomly select 3 as our starting point, we’d begin by selecting the third fraternity member on the list and then select every fourth member from there. This might be easier to understand if you can see it visually. Table 7.2 "Systematic Sample of 25 Fraternity Members" lists the names of our hypothetical 100 fraternity members on campus. You’ll see that the third name on the list has been selected for inclusion in our hypothetical study, as has every fourth name after that. A total of 25 names have been selected.
Table 7.2 Systematic Sample of 25 Fraternity Members
There is one clear instance in which systematic sampling should not be employed. If your sampling frame has any pattern to it, you could inadvertently introduce bias into your sample by using a systemic sampling strategy. This is sometimes referred to as the problem of periodicity The tendency for a pattern to occur at regular intervals. . Periodicity refers to the tendency for a pattern to occur at regular intervals. Let’s say, for example, that you wanted to observe how people use the outdoor public spaces on your campus. Perhaps you need to have your observations completed within 28 days and you wish to conduct four observations on randomly chosen days. Table 7.3 "Systematic Sample of Observation Days" shows a list of the population elements for this example. To determine which days we’ll conduct our observations, we’ll need to determine our selection interval. As you’ll recall from the preceding paragraphs, to do so we must divide our population size, in this case 28 days, by our desired sample size, in this case 4 days. This formula leads us to a selection interval of 7. If we randomly select 2 as our starting point and select every seventh day after that, we’ll wind up with a total of 4 days on which to conduct our observations. You’ll see how that works out in the following table.
Table 7.3 Systematic Sample of Observation Days
Do you notice any problems with our selection of observation days? Apparently we’ll only be observing on Tuesdays. As you have probably figured out, that isn’t such a good plan if we really wish to understand how public spaces on campus are used. My guess is that weekend use probably differs from weekday use, and that use may even vary during the week, just as class schedules do. In cases such as this, where the sampling frame is cyclical, it would be better to use a stratified sampling technique A researcher divides the study population into relevant subgroups then draws a sample from within each subgroup. . In stratified sampling, a researcher will divide the study population into relevant subgroups and then draw a sample from each subgroup. In this example, we might wish to first divide our sampling frame into two lists: weekend days and weekdays. Once we have our two lists, we can then apply either simple random or systematic sampling techniques to each subgroup.
Stratified sampling is a good technique to use when, as in our example, a subgroup of interest makes up a relatively small proportion of the overall sample. In our example of a study of use of public space on campus, we want to be sure to include weekdays and weekends in our sample, but because weekends make up less than a third of an entire week, there’s a chance that a simple random or systematic strategy would not yield sufficient weekend observation days. As you might imagine, stratified sampling is even more useful in cases where a subgroup makes up an even smaller proportion of the study population, say, for example, if we want to be sure to include both men’s and women’s perspectives in a study, but men make up only a small percentage of the population. There’s a chance simple random or systematic sampling strategy might not yield any male participants, but by using stratified sampling, we could ensure that our sample contained the proportion of men that is reflective of the larger population.
Up to this point in our discussion of probability samples, we’ve assumed that researchers will be able to access a list of population elements in order to create a sampling frame. This, as you might imagine, is not always the case. Let’s say, for example, that you wish to conduct a study of hairstyle preferences across the United States. Just imagine trying to create a list of every single person with (and without) hair in the country. Basically, we’re talking about a list of every person in the country. Even if you could find a way to generate such a list, attempting to do so might not be the most practical use of your time or resources. When this is the case, researchers turn to cluster sampling. Cluster sampling A researcher begins by sampling groups of population elements and then selects elements from within those groups. occurs when a researcher begins by sampling groups (or clusters) of population elements and then selects elements from within those groups.
Let’s take a look at a couple more examples. Perhaps you are interested in the workplace experiences of public librarians. Chances are good that obtaining a list of all librarians that work for public libraries would be rather difficult. But I’ll bet you could come up with a list of all public libraries without too much hassle. Thus you could draw a random sample of libraries (your cluster) and then draw another random sample of elements (in this case, librarians) from within the libraries you initially selected. Cluster sampling works in stages. In this example, we sampled in two stages. As you might have guessed, sampling in multiple stages does introduce the possibility of greater error (each stage is subject to its own sampling error), but it is nevertheless a highly efficient method.
Jessica Holt and Wayne Gillespie (2008) Holt, J. L., & Gillespie, W. (2008). Intergenerational transmission of violence, threatened egoism, and reciprocity: A test of multiple pychosocial factors affecting intimate partner violence. American Journal of Criminal Justice, 33 , 252–266. used cluster sampling in their study of students’ experiences with violence in intimate relationships. Specifically, the researchers randomly selected 14 classes on their campus and then drew a random subsample of students from those classes. But you probably know from your experience with college classes that not all classes are the same size. So if Holt and Gillespie had simply randomly selected 14 classes and then selected the same number of students from each class to complete their survey, then students in the smaller of those classes would have had a greater chance of being selected for the study than students in the larger classes. Keep in mind with random sampling the goal is to make sure that each element has the same chance of being selected. When clusters are of different sizes, as in the example of sampling college classes, researchers often use a method called probability proportionate to size A cluster sampling technique in which each cluster is given a chance of selection based on its size. (PPS). This means that they take into account that their clusters are of different sizes. They do this by giving clusters different chances of being selected based on their size so that each element within those clusters winds up having an equal chance of being selected.
Table 7.4 Types of Probability Samples
Key Takeaways
- In probability sampling, the aim is to identify a sample that resembles the population from which it was drawn.
- There are several types of probability samples including simple random samples, systematic samples, stratified samples, and cluster samples.
- Imagine that you are about to conduct a study of people’s use of public parks. Explain how you could employ each of the probability sampling techniques described earlier to recruit a sample for your study.
- Of the four probability sample types described, which seems strongest to you? Which seems weakest? Explain.
Sampling Methods In Reseach: Types, Techniques, & Examples
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Sampling methods in psychology refer to strategies used to select a subset of individuals (a sample) from a larger population, to study and draw inferences about the entire population. Common methods include random sampling, stratified sampling, cluster sampling, and convenience sampling. Proper sampling ensures representative, generalizable, and valid research results.
- Sampling : the process of selecting a representative group from the population under study.
- Target population : the total group of individuals from which the sample might be drawn.
- Sample: a subset of individuals selected from a larger population for study or investigation. Those included in the sample are termed “participants.”
- Generalizability : the ability to apply research findings from a sample to the broader target population, contingent on the sample being representative of that population.
For instance, if the advert for volunteers is published in the New York Times, this limits how much the study’s findings can be generalized to the whole population, because NYT readers may not represent the entire population in certain respects (e.g., politically, socio-economically).
The Purpose of Sampling
We are interested in learning about large groups of people with something in common in psychological research. We call the group interested in studying our “target population.”
In some types of research, the target population might be as broad as all humans. Still, in other types of research, the target population might be a smaller group, such as teenagers, preschool children, or people who misuse drugs.

Studying every person in a target population is more or less impossible. Hence, psychologists select a sample or sub-group of the population that is likely to be representative of the target population we are interested in.
This is important because we want to generalize from the sample to the target population. The more representative the sample, the more confident the researcher can be that the results can be generalized to the target population.
One of the problems that can occur when selecting a sample from a target population is sampling bias. Sampling bias refers to situations where the sample does not reflect the characteristics of the target population.
Many psychology studies have a biased sample because they have used an opportunity sample that comprises university students as their participants (e.g., Asch ).
OK, so you’ve thought up this brilliant psychological study and designed it perfectly. But who will you try it out on, and how will you select your participants?
There are various sampling methods. The one chosen will depend on a number of factors (such as time, money, etc.).

Random Sampling
Random sampling is a type of probability sampling where everyone in the entire target population has an equal chance of being selected.
This is similar to the national lottery. If the “population” is everyone who bought a lottery ticket, then everyone has an equal chance of winning the lottery (assuming they all have one ticket each).
Random samples require naming or numbering the target population and then using some raffle method to choose those to make up the sample. Random samples are the best method of selecting your sample from the population of interest.
- The advantages are that your sample should represent the target population and eliminate sampling bias.
- The disadvantage is that it is very difficult to achieve (i.e., time, effort, and money).
Stratified Sampling
During stratified sampling , the researcher identifies the different types of people that make up the target population and works out the proportions needed for the sample to be representative.
A list is made of each variable (e.g., IQ, gender, etc.) that might have an effect on the research. For example, if we are interested in the money spent on books by undergraduates, then the main subject studied may be an important variable.
For example, students studying English Literature may spend more money on books than engineering students, so if we use a large percentage of English students or engineering students, our results will not be accurate.
We have to determine the relative percentage of each group at a university, e.g., Engineering 10%, Social Sciences 15%, English 20%, Sciences 25%, Languages 10%, Law 5%, and Medicine 15%. The sample must then contain all these groups in the same proportion as the target population (university students).
- The disadvantage of stratified sampling is that gathering such a sample would be extremely time-consuming and difficult to do. This method is rarely used in Psychology.
- However, the advantage is that the sample should be highly representative of the target population, and therefore we can generalize from the results obtained.
Opportunity Sampling
Opportunity sampling is a method in which participants are chosen based on their ease of availability and proximity to the researcher, rather than using random or systematic criteria. It’s a type of convenience sampling .
An opportunity sample is obtained by asking members of the population of interest if they would participate in your research. An example would be selecting a sample of students from those coming out of the library.
- This is a quick and easy way of choosing participants (advantage)
- It may not provide a representative sample and could be biased (disadvantage).
Systematic Sampling
Systematic sampling is a method where every nth individual is selected from a list or sequence to form a sample, ensuring even and regular intervals between chosen subjects.
Participants are systematically selected (i.e., orderly/logical) from the target population, like every nth participant on a list of names.
To take a systematic sample, you list all the population members and then decide upon a sample you would like. By dividing the number of people in the population by the number of people you want in your sample, you get a number we will call n.
If you take every nth name, you will get a systematic sample of the correct size. If, for example, you wanted to sample 150 children from a school of 1,500, you would take every 10th name.
- The advantage of this method is that it should provide a representative sample.
Sample size
The sample size is a critical factor in determining the reliability and validity of a study’s findings. While increasing the sample size can enhance the generalizability of results, it’s also essential to balance practical considerations, such as resource constraints and diminishing returns from ever-larger samples.
Reliability and Validity
Reliability refers to the consistency and reproducibility of research findings across different occasions, researchers, or instruments. A small sample size may lead to inconsistent results due to increased susceptibility to random error or the influence of outliers. In contrast, a larger sample minimizes these errors, promoting more reliable results.
Validity pertains to the accuracy and truthfulness of research findings. For a study to be valid, it should accurately measure what it intends to do. A small, unrepresentative sample can compromise external validity, meaning the results don’t generalize well to the larger population. A larger sample captures more variability, ensuring that specific subgroups or anomalies don’t overly influence results.
Practical Considerations
Resource Constraints : Larger samples demand more time, money, and resources. Data collection becomes more extensive, data analysis more complex, and logistics more challenging.
Diminishing Returns : While increasing the sample size generally leads to improved accuracy and precision, there’s a point where adding more participants yields only marginal benefits. For instance, going from 50 to 500 participants might significantly boost a study’s robustness, but jumping from 10,000 to 10,500 might not offer a comparable advantage, especially considering the added costs.
Part I: Sampling, Data Collection, & Analysis in Quantitative Research
In this module, we will focus on how quantitative research collects and analyzes data, as well as methods for obtaining sample population.
- Levels of Measurement
- Reliability and Validity
- Population and Samples
- Common Data Collection Methods
- Data Analysis
- Statistical Significance versus Clinical Significance
Objectives:
- Describe levels of measurement
- Describe reliability and validity as applied to critical appraisal of research
- Differentiate methods of obtaining samples for population generalizability
- Describe common data collection methods in quantitative research
- Describe various data analysis methods in quantitative research
- Differentiate statistical significance versus clinical significance
Levels of measurement
Once researchers have collected their data (we will talk about data collection later in this module), they need methods to organize the data before they even start to think about statistical analyses. Statistical operations depend on a variable’s level of measurement. Think about this similarly to shuffling all of your bills in some type of organization before you pay them. With levels of measurement, we are precisely recording variables in a method to help organize them.
There are four levels of measurement:
Nominal: The data can only be categorized
Ordinal: The data can be categorized and ranked
Interval: The data can be categorized, ranked, and evenly spaced
Ratio: The data can be categorized, ranked, even spaced, and has a natural zero
Going from lowest to highest, the 4 levels of measurement are cumulative. This means that they each take on the properties of lower levels and add new properties.

- A variable is nominal if the values could be interchanged (e.g. 1 = male, 2 = female OR 1 = female, 2 = male).
- A variable is ordinal if there is a quantitative ordering of values AND if there are a small number of values (e.g. excellent, good, fair, poor).
- A variable is usually considered interval if it is measured with a composite scale or test.
- A variable is ratio level if it makes sense to say that one value is twice as much as another (e.g. 100 mg is twice as much as 50 mg) (Polit & Beck, 2021).
Reliability and Validity as Applied to Critical Appraisal of Research
Reliability measures the ability of a measure to consistently measure the same way. Validity measures what it is supposed to measure. Do we have the need for both in research? Yes! If a variable is measured inaccurately, the data is useless. Let’s talk about why.
For example, let’s set out to measure blood glucose for our study. The validity is how well the measure can determine the blood glucose. If we used a blood pressure cuff to measure blood glucose, this would not be a valid measure. If we used a blood glucose meter, it would be a more valid measure. It does not stop there, however. What about the meter itself? Has it been calibrated? Are the correct sticks for the meter available? Are they expired? Does the meter have fresh batteries? Are the patient’s hands clean?
Reliability wants to know: Is the blood glucose meter measuring the same way, every time?
Validity is asking, “Does the meter measure what it is supposed to measure?” Construct validity: Does the test measure the concept that it’s intended to measure? Content validity: Is the test fully representative of what it aims to measure? Face validity: Does the content of the test appear to be suitable to its aims?
Leibold, 2020
Obtaining Samples for Population Generalizability
In quantitative research, a population is the entire group that the researcher wants to draw conclusions about.
A sample is the specific group that the researcher will actually collect data from. A sample is always a much smaller group of people than the total size of the population. For example, if we wanted to investigate heart failure, there would be no possible way to measure every single human with heart failure. Therefore, researchers will attempt to select a sample of that large population which would most likely reflect (AKA: be a representative sample) the larger population of those with heart failure. Remember, in quantitative research, the results should be generalizable to the population studied.
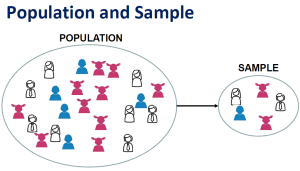
A researcher will specify population characteristics through eligibility criteria. This means that they consider which characteristics to include ( inclusion criteria ) and which characteristics to exclude ( exclusion criteria ).
For example, if we were studying chemotherapy in breast cancer subjects, we might specify:
- Inclusion Criteria: Postmenopausal women between the ages of 45 and 75 who have been diagnosed with Stage II breast cancer.
- Exclusion Criteria: Abnormal renal function tests since we are studying a combination of drugs that may be nephrotoxic. Renal function tests are to be performed to evaluate renal function and the threshold values that would disqualify the prospective subject is serum creatinine above 1.9 mg/dl.
Sampling Designs:
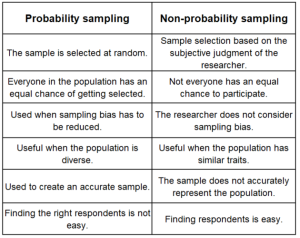
There are two broad classes of sampling in quantitative research: Probability and nonprobability sampling.
Probability sampling : As the name implies, probability sampling means that each eligible individual has a random chance (same probability) of being selected to participate in the study.
There are three types of probability sampling:
Simple random sampling : Every eligible participant is randomly selected (e.g. drawing from a hat).
Stratified random sampling : Eligible population is first divided into two or more strata (categories) from which randomization occurs (e.g. pollution levels selected from restaurants, bars with ordinances of state laws, and bars with no ordinances).
Systematic sampling : Involves the selection of every __ th eligible participant from a list (e.g. every 9 th person).
Nonprobability sampling : In nonprobability sampling, eligible participants are selected using a subjective (non-random) method.
There are four types of nonprobability sampling:
Convenience sampling : Participants are selected for inclusion in the sample because they are the easiest for the researcher to access. This can be due to geographical proximity, availability at a given time, or willingness to participate in the research.
Quota sampling : Participants are from a very tailored sample that’s in proportion to some characteristic or trait of a population. For example, the researcher could divide a population by the state they live in, income or education level, or sex. The population is divided into groups (also called strata) and samples are taken from each group to meet a quota.
Consecutive sampling : A sampling technique in which every subject meeting the criteria of inclusion is selected until the required sample size is achieved. Consecutive sampling is defined as a nonprobability technique where samples are picked at the ease of a researcher more like convenience sampling, only with a slight variation. Here, the researcher selects a sample or group of people, conducts research over a period, collects results, and then moves on to another sample.
Purposive sampling : A group of non-probability sampling techniques in which units are selected because they have characteristics that the researcher needs in their sample. In other words, units are selected “on purpose” in purposive sampling.
Common Data Collection Methods in Quantitative Research
There are various methods that researchers use to collect data for their studies. For nurse researchers, existing records are an important data source. Researchers need to decide if they will collect new data or use existing data. There is also a wealth of clinical data that can be used for non-research purposed to help answer clinical questions.
Let’s look at some general data collection methods and data sources in quantitative research.
Existing data could include medical records, school records, corporate diaries, letters, meeting minutes, and photographs. These are easy to obtain do not require participation from those being studied.
Collecting new data:
Let’s go over a few methods in which researcher can collect new data. These usually requires participation from those being studied.
Self-reports can be obtained via interviews or questionnaires . Closed-ended questions can be asked (“Within the past 6 months, were you ever a member of a fitness gym?” Yes/No) or open-ended questions such as “Why did you decide to join a fitness gym?” Important to remember (this sometimes throws students off) is that conducting interviews and questionnaires does not mean it is qualitative in nature! Do not let that throw you off in assessing whether a published article is quantitative or qualitative. The nature of the questions, however, may help to determine the type of research (quantitative or qualitative), as qualitative questions deal with ascertaining a very organic collection of people’s experiences in open-ended questions.
Advantages of questionnaires (compared to interviews):
- Questionnaires are less costly and are advantageous for geographically dispersed samples.
- Questionnaires offer the possibility of anonymity, which may be crucial in obtaining information about certain opinions or traits.
Advances of interviews (compared to questionnaires):
- Higher response rates
- Some people cannot fill out a questionnaire.
- Opportunities to clarify questions or to determine comprehension
- Opportunity to collect supplementary data through observation
Psychosocial scales are often utilized within questionnaires or interviews. These can help to obtain attitudes, perceptions, and psychological traits.
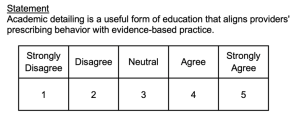
Likert Scales :
- Consist of several declarative statements ( items ) expressing viewpoints
- Responses are on an agree/disagree continuum (usually five or seven response options).
- Responses to items are summed to compute a total scale score.
Visual Analog Scale:
- Used to measure subjective experiences (e.g., pain, nausea)
- Measurements are on a straight line measuring 100 mm.
- End points labeled as extreme limits of sensation

Observational Methods include the observation method of data collection involves seeing people in a certain setting or place at a specific time and day. Essentially, researchers study the behavior of the individuals or surroundings in which they are analyzing. This can be controlled, spontaneous, or participant-based research .
When a researcher utilizes a defined procedure for observing individuals or the environment, this is known as structured observation. When individuals are observed in their natural environment, this is known as naturalistic observation. In participant observation, the researcher immerses himself or herself in the environment and becomes a member of the group being observed.
Biophysiologic Measures are defined as ‘those physiological and physical variables that require specialized technical instruments and equipment for their measurement’. Biophysiological measures are the most common instruments for collecting data in medical science studies. To collect valid and reliable data, it is critical to apply these measures appropriately.
- In vivo refers to when research or work is done with or within an entire, living organism. Examples can include studies in animal models or human clinical trials.
- In vitro is used to describe work that’s performed outside of a living organism. This usually involves isolated tissues, organs, or cells.

Let’s watch a video about Sampling and Data Collection that I made a couple of years ago.

Introduction.
- Sampling Strategies
- Sample Size
- Qualitative Design Considerations
- Discipline Specific and Special Considerations
- Sampling Strategies Unique to Mixed Methods Designs
Related Articles Expand or collapse the "related articles" section about
About related articles close popup.
Lorem Ipsum Sit Dolor Amet
Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Aliquam ligula odio, euismod ut aliquam et, vestibulum nec risus. Nulla viverra, arcu et iaculis consequat, justo diam ornare tellus, semper ultrices tellus nunc eu tellus.
- Mixed Methods Research
- Qualitative Research Design
- Quantitative Research Designs in Educational Research
Other Subject Areas
Forthcoming articles expand or collapse the "forthcoming articles" section.
- Gender, Power, and Politics in the Academy
- Girls' Education in the Developing World
- Non-Formal & Informal Environmental Education
- Find more forthcoming articles...
- Export Citations
- Share This Facebook LinkedIn Twitter
Qualitative, Quantitative, and Mixed Methods Research Sampling Strategies by Timothy C. Guetterman LAST MODIFIED: 26 February 2020 DOI: 10.1093/obo/9780199756810-0241
Sampling is a critical, often overlooked aspect of the research process. The importance of sampling extends to the ability to draw accurate inferences, and it is an integral part of qualitative guidelines across research methods. Sampling considerations are important in quantitative and qualitative research when considering a target population and when drawing a sample that will either allow us to generalize (i.e., quantitatively) or go into sufficient depth (i.e., qualitatively). While quantitative research is generally concerned with probability-based approaches, qualitative research typically uses nonprobability purposeful sampling approaches. Scholars generally focus on two major sampling topics: sampling strategies and sample sizes. Or simply, researchers should think about who to include and how many; both of these concerns are key. Mixed methods studies have both qualitative and quantitative sampling considerations. However, mixed methods studies also have unique considerations based on the relationship of quantitative and qualitative research within the study.
Sampling in Qualitative Research
Sampling in qualitative research may be divided into two major areas: overall sampling strategies and issues around sample size. Sampling strategies refers to the process of sampling and how to design a sampling. Qualitative sampling typically follows a nonprobability-based approach, such as purposive or purposeful sampling where participants or other units of analysis are selected intentionally for their ability to provide information to address research questions. Sample size refers to how many participants or other units are needed to address research questions. The methodological literature about sampling tends to fall into these two broad categories, though some articles, chapters, and books cover both concepts. Others have connected sampling to the type of qualitative design that is employed. Additionally, researchers might consider discipline specific sampling issues as much research does tend to operate within disciplinary views and constraints. Scholars in many disciplines have examined sampling around specific topics, research problems, or disciplines and provide guidance to making sampling decisions, such as appropriate strategies and sample size.
back to top
Users without a subscription are not able to see the full content on this page. Please subscribe or login .
Oxford Bibliographies Online is available by subscription and perpetual access to institutions. For more information or to contact an Oxford Sales Representative click here .
- About Education »
- Meet the Editorial Board »
- Academic Achievement
- Academic Audit for Universities
- Academic Freedom and Tenure in the United States
- Action Research in Education
- Adjuncts in Higher Education in the United States
- Administrator Preparation
- Adolescence
- Advanced Placement and International Baccalaureate Courses
- Advocacy and Activism in Early Childhood
- African American Racial Identity and Learning
- Alaska Native Education
- Alternative Certification Programs for Educators
- Alternative Schools
- American Indian Education
- Animals in Environmental Education
- Art Education
- Artificial Intelligence and Learning
- Assessing School Leader Effectiveness
- Assessment, Behavioral
- Assessment, Educational
- Assessment in Early Childhood Education
- Assistive Technology
- Augmented Reality in Education
- Beginning-Teacher Induction
- Bilingual Education and Bilingualism
- Black Undergraduate Women: Critical Race and Gender Perspe...
- Blended Learning
- Case Study in Education Research
- Changing Professional and Academic Identities
- Character Education
- Children’s and Young Adult Literature
- Children's Beliefs about Intelligence
- Children's Rights in Early Childhood Education
- Citizenship Education
- Civic and Social Engagement of Higher Education
- Classroom Learning Environments: Assessing and Investigati...
- Classroom Management
- Coherent Instructional Systems at the School and School Sy...
- College Admissions in the United States
- College Athletics in the United States
- Community Relations
- Comparative Education
- Computer-Assisted Language Learning
- Computer-Based Testing
- Conceptualizing, Measuring, and Evaluating Improvement Net...
- Continuous Improvement and "High Leverage" Educational Pro...
- Counseling in Schools
- Critical Approaches to Gender in Higher Education
- Critical Perspectives on Educational Innovation and Improv...
- Critical Race Theory
- Crossborder and Transnational Higher Education
- Cross-National Research on Continuous Improvement
- Cross-Sector Research on Continuous Learning and Improveme...
- Cultural Diversity in Early Childhood Education
- Culturally Responsive Leadership
- Culturally Responsive Pedagogies
- Culturally Responsive Teacher Education in the United Stat...
- Curriculum Design
- Data Collection in Educational Research
- Data-driven Decision Making in the United States
- Deaf Education
- Desegregation and Integration
- Design Thinking and the Learning Sciences: Theoretical, Pr...
- Development, Moral
- Dialogic Pedagogy
- Digital Age Teacher, The
- Digital Citizenship
- Digital Divides
- Disabilities
- Distance Learning
- Distributed Leadership
- Doctoral Education and Training
- Early Childhood Education and Care (ECEC) in Denmark
- Early Childhood Education and Development in Mexico
- Early Childhood Education in Aotearoa New Zealand
- Early Childhood Education in Australia
- Early Childhood Education in China
- Early Childhood Education in Europe
- Early Childhood Education in Sub-Saharan Africa
- Early Childhood Education in Sweden
- Early Childhood Education Pedagogy
- Early Childhood Education Policy
- Early Childhood Education, The Arts in
- Early Childhood Mathematics
- Early Childhood Science
- Early Childhood Teacher Education
- Early Childhood Teachers in Aotearoa New Zealand
- Early Years Professionalism and Professionalization Polici...
- Economics of Education
- Education For Children with Autism
- Education for Sustainable Development
- Education Leadership, Empirical Perspectives in
- Education of Native Hawaiian Students
- Education Reform and School Change
- Educational Statistics for Longitudinal Research
- Educator Partnerships with Parents and Families with a Foc...
- Emotional and Affective Issues in Environmental and Sustai...
- Emotional and Behavioral Disorders
- Environmental and Science Education: Overlaps and Issues
- Environmental Education
- Environmental Education in Brazil
- Epistemic Beliefs
- Equity and Improvement: Engaging Communities in Educationa...
- Equity, Ethnicity, Diversity, and Excellence in Education
- Ethical Research with Young Children
- Ethics and Education
- Ethics of Teaching
- Ethnic Studies
- Evidence-Based Communication Assessment and Intervention
- Family and Community Partnerships in Education
- Family Day Care
- Federal Government Programs and Issues
- Feminization of Labor in Academia
- Finance, Education
- Financial Aid
- Formative Assessment
- Future-Focused Education
- Gender and Achievement
- Gender and Alternative Education
- Gender-Based Violence on University Campuses
- Gifted Education
- Global Mindedness and Global Citizenship Education
- Global University Rankings
- Governance, Education
- Grounded Theory
- Growth of Effective Mental Health Services in Schools in t...
- Higher Education and Globalization
- Higher Education and the Developing World
- Higher Education Faculty Characteristics and Trends in the...
- Higher Education Finance
- Higher Education Governance
- Higher Education Graduate Outcomes and Destinations
- Higher Education in Africa
- Higher Education in China
- Higher Education in Latin America
- Higher Education in the United States, Historical Evolutio...
- Higher Education, International Issues in
- Higher Education Management
- Higher Education Policy
- Higher Education Research
- Higher Education Student Assessment
- High-stakes Testing
- History of Early Childhood Education in the United States
- History of Education in the United States
- History of Technology Integration in Education
- Homeschooling
- Inclusion in Early Childhood: Difference, Disability, and ...
- Inclusive Education
- Indigenous Education in a Global Context
- Indigenous Learning Environments
- Indigenous Students in Higher Education in the United Stat...
- Infant and Toddler Pedagogy
- Inservice Teacher Education
- Integrating Art across the Curriculum
- Intelligence
- Intensive Interventions for Children and Adolescents with ...
- International Perspectives on Academic Freedom
- Intersectionality and Education
- Knowledge Development in Early Childhood
- Leadership Development, Coaching and Feedback for
- Leadership in Early Childhood Education
- Leadership Training with an Emphasis on the United States
- Learning Analytics in Higher Education
- Learning Difficulties
- Learning, Lifelong
- Learning, Multimedia
- Learning Strategies
- Legal Matters and Education Law
- LGBT Youth in Schools
- Linguistic Diversity
- Linguistically Inclusive Pedagogy
- Literacy Development and Language Acquisition
- Literature Reviews
- Mathematics Identity
- Mathematics Instruction and Interventions for Students wit...
- Mathematics Teacher Education
- Measurement for Improvement in Education
- Measurement in Education in the United States
- Meta-Analysis and Research Synthesis in Education
- Methodological Approaches for Impact Evaluation in Educati...
- Methodologies for Conducting Education Research
- Mindfulness, Learning, and Education
- Motherscholars
- Multiliteracies in Early Childhood Education
- Multiple Documents Literacy: Theory, Research, and Applica...
- Multivariate Research Methodology
- Museums, Education, and Curriculum
- Music Education
- Narrative Research in Education
- Native American Studies
- Note-Taking
- Numeracy Education
- One-to-One Technology in the K-12 Classroom
- Online Education
- Open Education
- Organizing for Continuous Improvement in Education
- Organizing Schools for the Inclusion of Students with Disa...
- Outdoor Play and Learning
- Outdoor Play and Learning in Early Childhood Education
- Pedagogical Leadership
- Pedagogy of Teacher Education, A
- Performance Objectives and Measurement
- Performance-based Research Assessment in Higher Education
- Performance-based Research Funding
- Phenomenology in Educational Research
- Philosophy of Education
- Physical Education
- Podcasts in Education
- Policy Context of United States Educational Innovation and...
- Politics of Education
- Portable Technology Use in Special Education Programs and ...
- Post-humanism and Environmental Education
- Pre-Service Teacher Education
- Problem Solving
- Productivity and Higher Education
- Professional Development
- Professional Learning Communities
- Program Evaluation
- Programs and Services for Students with Emotional or Behav...
- Psychology Learning and Teaching
- Psychometric Issues in the Assessment of English Language ...
- Qualitative Data Analysis Techniques
- Qualitative, Quantitative, and Mixed Methods Research Samp...
- Queering the English Language Arts (ELA) Writing Classroom
- Race and Affirmative Action in Higher Education
- Reading Education
- Refugee and New Immigrant Learners
- Relational and Developmental Trauma and Schools
- Relational Pedagogies in Early Childhood Education
- Reliability in Educational Assessments
- Religion in Elementary and Secondary Education in the Unit...
- Researcher Development and Skills Training within the Cont...
- Research-Practice Partnerships in Education within the Uni...
- Response to Intervention
- Restorative Practices
- Risky Play in Early Childhood Education
- Scale and Sustainability of Education Innovation and Impro...
- Scaling Up Research-based Educational Practices
- School Accreditation
- School Choice
- School Culture
- School District Budgeting and Financial Management in the ...
- School Improvement through Inclusive Education
- School Reform
- Schools, Private and Independent
- School-Wide Positive Behavior Support
- Science Education
- Secondary to Postsecondary Transition Issues
- Self-Regulated Learning
- Self-Study of Teacher Education Practices
- Service-Learning
- Severe Disabilities
- Single Salary Schedule
- Single-sex Education
- Single-Subject Research Design
- Social Context of Education
- Social Justice
- Social Network Analysis
- Social Pedagogy
- Social Science and Education Research
- Social Studies Education
- Sociology of Education
- Standards-Based Education
- Statistical Assumptions
- Student Access, Equity, and Diversity in Higher Education
- Student Assignment Policy
- Student Engagement in Tertiary Education
- Student Learning, Development, Engagement, and Motivation ...
- Student Participation
- Student Voice in Teacher Development
- Sustainability Education in Early Childhood Education
- Sustainability in Early Childhood Education
- Sustainability in Higher Education
- Teacher Beliefs and Epistemologies
- Teacher Collaboration in School Improvement
- Teacher Evaluation and Teacher Effectiveness
- Teacher Preparation
- Teacher Training and Development
- Teacher Unions and Associations
- Teacher-Student Relationships
- Teaching Critical Thinking
- Technologies, Teaching, and Learning in Higher Education
- Technology Education in Early Childhood
- Technology, Educational
- Technology-based Assessment
- The Bologna Process
- The Regulation of Standards in Higher Education
- Theories of Educational Leadership
- Three Conceptions of Literacy: Media, Narrative, and Gamin...
- Tracking and Detracking
- Traditions of Quality Improvement in Education
- Transformative Learning
- Transitions in Early Childhood Education
- Tribally Controlled Colleges and Universities in the Unite...
- Understanding the Psycho-Social Dimensions of Schools and ...
- University Faculty Roles and Responsibilities in the Unite...
- Using Ethnography in Educational Research
- Value of Higher Education for Students and Other Stakehold...
- Virtual Learning Environments
- Vocational and Technical Education
- Wellness and Well-Being in Education
- Women's and Gender Studies
- Young Children and Spirituality
- Young Children's Learning Dispositions
- Young Children's Working Theories
- Privacy Policy
- Cookie Policy
- Legal Notice
- Accessibility
Powered by:
- [66.249.64.20|185.80.151.41]
- 185.80.151.41
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
Statistics and probability
Course: statistics and probability > unit 6.
- Picking fairly
- Using probability to make fair decisions
- Techniques for generating a simple random sample
- Simple random samples
- Techniques for random sampling and avoiding bias
- Sampling methods
Sampling methods review
- Samples and surveys
What are sampling methods?
Bad ways to sample.
- (Choice A) Convenience sampling A Convenience sampling
- (Choice B) Voluntary response sampling B Voluntary response sampling
Good ways to sample
- (Choice A) Simple random sampling A Simple random sampling
- (Choice B) Stratified random sampling B Stratified random sampling
- (Choice C) Cluster random sampling C Cluster random sampling
- (Choice D) Systematic random sampling D Systematic random sampling
Want to join the conversation?
- Upvote Button navigates to signup page
- Downvote Button navigates to signup page
- Flag Button navigates to signup page

- Privacy Policy
Buy Me a Coffee
Home » Sampling Methods – Types, Techniques and Examples
Sampling Methods – Types, Techniques and Examples
Table of Contents

Sampling refers to the process of selecting a subset of data from a larger population or dataset in order to analyze or make inferences about the whole population.
In other words, sampling involves taking a representative sample of data from a larger group or dataset in order to gain insights or draw conclusions about the entire group.
Sampling Methods
Sampling methods refer to the techniques used to select a subset of individuals or units from a larger population for the purpose of conducting statistical analysis or research.
Sampling is an essential part of the Research because it allows researchers to draw conclusions about a population without having to collect data from every member of that population, which can be time-consuming, expensive, or even impossible.
Types of Sampling Methods
Sampling can be broadly categorized into two main categories:
Probability Sampling
This type of sampling is based on the principles of random selection, and it involves selecting samples in a way that every member of the population has an equal chance of being included in the sample.. Probability sampling is commonly used in scientific research and statistical analysis, as it provides a representative sample that can be generalized to the larger population.
Type of Probability Sampling :
- Simple Random Sampling: In this method, every member of the population has an equal chance of being selected for the sample. This can be done using a random number generator or by drawing names out of a hat, for example.
- Systematic Sampling: In this method, the population is first divided into a list or sequence, and then every nth member is selected for the sample. For example, if every 10th person is selected from a list of 100 people, the sample would include 10 people.
- Stratified Sampling: In this method, the population is divided into subgroups or strata based on certain characteristics, and then a random sample is taken from each stratum. This is often used to ensure that the sample is representative of the population as a whole.
- Cluster Sampling: In this method, the population is divided into clusters or groups, and then a random sample of clusters is selected. Then, all members of the selected clusters are included in the sample.
- Multi-Stage Sampling : This method combines two or more sampling techniques. For example, a researcher may use stratified sampling to select clusters, and then use simple random sampling to select members within each cluster.
Non-probability Sampling
This type of sampling does not rely on random selection, and it involves selecting samples in a way that does not give every member of the population an equal chance of being included in the sample. Non-probability sampling is often used in qualitative research, where the aim is not to generalize findings to a larger population, but to gain an in-depth understanding of a particular phenomenon or group. Non-probability sampling methods can be quicker and more cost-effective than probability sampling methods, but they may also be subject to bias and may not be representative of the larger population.
Types of Non-probability Sampling :
- Convenience Sampling: In this method, participants are chosen based on their availability or willingness to participate. This method is easy and convenient but may not be representative of the population.
- Purposive Sampling: In this method, participants are selected based on specific criteria, such as their expertise or knowledge on a particular topic. This method is often used in qualitative research, but may not be representative of the population.
- Snowball Sampling: In this method, participants are recruited through referrals from other participants. This method is often used when the population is hard to reach, but may not be representative of the population.
- Quota Sampling: In this method, a predetermined number of participants are selected based on specific criteria, such as age or gender. This method is often used in market research, but may not be representative of the population.
- Volunteer Sampling: In this method, participants volunteer to participate in the study. This method is often used in research where participants are motivated by personal interest or altruism, but may not be representative of the population.
Applications of Sampling Methods
Applications of Sampling Methods from different fields:
- Psychology : Sampling methods are used in psychology research to study various aspects of human behavior and mental processes. For example, researchers may use stratified sampling to select a sample of participants that is representative of the population based on factors such as age, gender, and ethnicity. Random sampling may also be used to select participants for experimental studies.
- Sociology : Sampling methods are commonly used in sociological research to study social phenomena and relationships between individuals and groups. For example, researchers may use cluster sampling to select a sample of neighborhoods to study the effects of economic inequality on health outcomes. Stratified sampling may also be used to select a sample of participants that is representative of the population based on factors such as income, education, and occupation.
- Social sciences: Sampling methods are commonly used in social sciences to study human behavior and attitudes. For example, researchers may use stratified sampling to select a sample of participants that is representative of the population based on factors such as age, gender, and income.
- Marketing : Sampling methods are used in marketing research to collect data on consumer preferences, behavior, and attitudes. For example, researchers may use random sampling to select a sample of consumers to participate in a survey about a new product.
- Healthcare : Sampling methods are used in healthcare research to study the prevalence of diseases and risk factors, and to evaluate interventions. For example, researchers may use cluster sampling to select a sample of health clinics to participate in a study of the effectiveness of a new treatment.
- Environmental science: Sampling methods are used in environmental science to collect data on environmental variables such as water quality, air pollution, and soil composition. For example, researchers may use systematic sampling to collect soil samples at regular intervals across a field.
- Education : Sampling methods are used in education research to study student learning and achievement. For example, researchers may use stratified sampling to select a sample of schools that is representative of the population based on factors such as demographics and academic performance.
Examples of Sampling Methods
Probability Sampling Methods Examples:
- Simple random sampling Example : A researcher randomly selects participants from the population using a random number generator or drawing names from a hat.
- Stratified random sampling Example : A researcher divides the population into subgroups (strata) based on a characteristic of interest (e.g. age or income) and then randomly selects participants from each subgroup.
- Systematic sampling Example : A researcher selects participants at regular intervals from a list of the population.
Non-probability Sampling Methods Examples:
- Convenience sampling Example: A researcher selects participants who are conveniently available, such as students in a particular class or visitors to a shopping mall.
- Purposive sampling Example : A researcher selects participants who meet specific criteria, such as individuals who have been diagnosed with a particular medical condition.
- Snowball sampling Example : A researcher selects participants who are referred to them by other participants, such as friends or acquaintances.
How to Conduct Sampling Methods
some general steps to conduct sampling methods:
- Define the population: Identify the population of interest and clearly define its boundaries.
- Choose the sampling method: Select an appropriate sampling method based on the research question, characteristics of the population, and available resources.
- Determine the sample size: Determine the desired sample size based on statistical considerations such as margin of error, confidence level, or power analysis.
- Create a sampling frame: Develop a list of all individuals or elements in the population from which the sample will be drawn. The sampling frame should be comprehensive, accurate, and up-to-date.
- Select the sample: Use the chosen sampling method to select the sample from the sampling frame. The sample should be selected randomly, or if using a non-random method, every effort should be made to minimize bias and ensure that the sample is representative of the population.
- Collect data: Once the sample has been selected, collect data from each member of the sample using appropriate research methods (e.g., surveys, interviews, observations).
- Analyze the data: Analyze the data collected from the sample to draw conclusions about the population of interest.
When to use Sampling Methods
Sampling methods are used in research when it is not feasible or practical to study the entire population of interest. Sampling allows researchers to study a smaller group of individuals, known as a sample, and use the findings from the sample to make inferences about the larger population.
Sampling methods are particularly useful when:
- The population of interest is too large to study in its entirety.
- The cost and time required to study the entire population are prohibitive.
- The population is geographically dispersed or difficult to access.
- The research question requires specialized or hard-to-find individuals.
- The data collected is quantitative and statistical analyses are used to draw conclusions.
Purpose of Sampling Methods
The main purpose of sampling methods in research is to obtain a representative sample of individuals or elements from a larger population of interest, in order to make inferences about the population as a whole. By studying a smaller group of individuals, known as a sample, researchers can gather information about the population that would be difficult or impossible to obtain from studying the entire population.
Sampling methods allow researchers to:
- Study a smaller, more manageable group of individuals, which is typically less time-consuming and less expensive than studying the entire population.
- Reduce the potential for data collection errors and improve the accuracy of the results by minimizing sampling bias.
- Make inferences about the larger population with a certain degree of confidence, using statistical analyses of the data collected from the sample.
- Improve the generalizability and external validity of the findings by ensuring that the sample is representative of the population of interest.
Characteristics of Sampling Methods
Here are some characteristics of sampling methods:
- Randomness : Probability sampling methods are based on random selection, meaning that every member of the population has an equal chance of being selected. This helps to minimize bias and ensure that the sample is representative of the population.
- Representativeness : The goal of sampling is to obtain a sample that is representative of the larger population of interest. This means that the sample should reflect the characteristics of the population in terms of key demographic, behavioral, or other relevant variables.
- Size : The size of the sample should be large enough to provide sufficient statistical power for the research question at hand. The sample size should also be appropriate for the chosen sampling method and the level of precision desired.
- Efficiency : Sampling methods should be efficient in terms of time, cost, and resources required. The method chosen should be feasible given the available resources and time constraints.
- Bias : Sampling methods should aim to minimize bias and ensure that the sample is representative of the population of interest. Bias can be introduced through non-random selection or non-response, and can affect the validity and generalizability of the findings.
- Precision : Sampling methods should be precise in terms of providing estimates of the population parameters of interest. Precision is influenced by sample size, sampling method, and level of variability in the population.
- Validity : The validity of the sampling method is important for ensuring that the results obtained from the sample are accurate and can be generalized to the population of interest. Validity can be affected by sampling method, sample size, and the representativeness of the sample.
Advantages of Sampling Methods
Sampling methods have several advantages, including:
- Cost-Effective : Sampling methods are often much cheaper and less time-consuming than studying an entire population. By studying only a small subset of the population, researchers can gather valuable data without incurring the costs associated with studying the entire population.
- Convenience : Sampling methods are often more convenient than studying an entire population. For example, if a researcher wants to study the eating habits of people in a city, it would be very difficult and time-consuming to study every single person in the city. By using sampling methods, the researcher can obtain data from a smaller subset of people, making the study more feasible.
- Accuracy: When done correctly, sampling methods can be very accurate. By using appropriate sampling techniques, researchers can obtain a sample that is representative of the entire population. This allows them to make accurate generalizations about the population as a whole based on the data collected from the sample.
- Time-Saving: Sampling methods can save a lot of time compared to studying the entire population. By studying a smaller sample, researchers can collect data much more quickly than they could if they studied every single person in the population.
- Less Bias : Sampling methods can reduce bias in a study. If a researcher were to study the entire population, it would be very difficult to eliminate all sources of bias. However, by using appropriate sampling techniques, researchers can reduce bias and obtain a sample that is more representative of the entire population.
Limitations of Sampling Methods
- Sampling Error : Sampling error is the difference between the sample statistic and the population parameter. It is the result of selecting a sample rather than the entire population. The larger the sample, the lower the sampling error. However, no matter how large the sample size, there will always be some degree of sampling error.
- Selection Bias: Selection bias occurs when the sample is not representative of the population. This can happen if the sample is not selected randomly or if some groups are underrepresented in the sample. Selection bias can lead to inaccurate conclusions about the population.
- Non-response Bias : Non-response bias occurs when some members of the sample do not respond to the survey or study. This can result in a biased sample if the non-respondents differ from the respondents in important ways.
- Time and Cost : While sampling can be cost-effective, it can still be expensive and time-consuming to select a sample that is representative of the population. Depending on the sampling method used, it may take a long time to obtain a sample that is large enough and representative enough to be useful.
- Limited Information : Sampling can only provide information about the variables that are measured. It may not provide information about other variables that are relevant to the research question but were not measured.
- Generalization : The extent to which the findings from a sample can be generalized to the population depends on the representativeness of the sample. If the sample is not representative of the population, it may not be possible to generalize the findings to the population as a whole.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Probability Sampling – Methods, Types and...

Quota Sampling – Types, Methods and Examples

Simple Random Sampling – Types, Method and...

Convenience Sampling – Method, Types and Examples

Purposive Sampling – Methods, Types and Examples

Systematic Sampling – Types, Method and Examples

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
10.2: Sampling approaches for quantitative research
- Last updated
- Save as PDF
- Page ID 135139

- Matthew DeCarlo, Cory Cummings, & Kate Agnelli
- Open Social Work Education
Learning Objectives
Learners will be able to…
- Determine whether you will use probability or non-probability sampling, given the strengths and limitations of each specific sampling approach
- Distinguish between approaches to probability sampling and detail the reasons to use each approach
Sampling in quantitative research projects is done because it is not feasible to study the whole population, and researchers hope to take what we learn about a small group of people (your sample) and apply it to a larger population. There are many ways to approach this process, and they can be grouped into two categories—probability sampling and non-probability sampling. Sampling approaches are inextricably linked with recruitment, and researchers should ensure that their proposal’s recruitment strategy matches the sampling approach.
Probability sampling approaches use a random process, usually a computer program, to select participants from the sampling frame so that everyone has an equal chance of being included. It’s important to note that random means the researcher used a process that is truly random . In a project sampling college students, standing outside of the building in which your social work department is housed and surveying everyone who walks past is not random. Because of the location, you are likely to recruit a disproportionately large number of social work students and fewer from other disciplines. Depending on the time of day, you may recruit more traditional undergraduate students, who take classes during the day, or more graduate students, who take classes in the evenings.
In this example, you are actually using non-probability sampling . Another way to say this is that you are using the most common sampling approach for student projects, availability sampling . Also called convenience sampling, this approach simply recruits people who are convenient or easily available to the researcher. If you have ever been asked by a friend to participate in their research study for their class or seen an advertisement for a study on a bulletin board or social media, you were being recruited using an availability sampling approach.
There are a number of benefits to the availability sampling approach. First and foremost, it is less costly and time-consuming for the researcher. As long as the person you are attempting to recruit has knowledge of the topic you are studying, the information you get from the sample you recruit will be relevant to your topic (although your sample may not necessarily be representative of a larger population). Availability samples can also be helpful when random sampling isn’t practical. If you are planning to survey students in an LGBTQ+ support group on campus but attendance varies from meeting to meeting, you may show up at a meeting and ask anyone present to participate in your study. A support group with varied membership makes it impossible to have a real list—or sampling frame—from which to randomly select individuals. Availability sampling would help you reach that population.
Availability sampling is appropriate for student and smaller-scale projects, but it comes with significant limitations. The purpose of sampling in quantitative research is to generalize from a small sample to a larger population. Because availability sampling does not use a random process to select participants, the researcher cannot be sure their sample is representative of the population they hope to generalize to. Instead, the recruitment processes may have been structured by other factors that may bias the sample to be different in some way than the overall population.
So, for instance, if we asked social work students about their level of satisfaction with the services at the student health center, and we sampled in the evenings, we would get most likely get a biased perspective of the issue. Students taking only night classes are much more likely to commute to school, spend less time on campus, and use fewer campus services. Our results would not represent what all social work students feel about the topic. We might get the impression that no social work student had ever visited the health center, when that is not actually true at all. Sampling bias will be discussed in detail in Section 10.3.

Approaches to probability sampling
What might be a better strategy is getting a list of all email addresses of social work students and randomly selecting email addresses of students to whom you can send your survey. This would be an example of simple random sampling . It’s important to note that you need a real list of people in your sampling frame from which to select your email addresses. For projects where the people who could potentially participate is not known by the researcher, probability sampling is not possible. It is likely that administrators at your school’s registrar would be reluctant to share the list of students’ names and email addresses. Always remember to consider the feasibility and ethical implications of the sampling approach you choose.
Usually, simple random sampling is accomplished by assigning each person, or element , in your sampling frame a number and selecting your participants using a random number generator. You would follow an identical process if you were sampling records or documents as your elements, rather than people. True randomness is difficult to achieve, and it takes complex computational calculations to do so. Although you think you can select things at random, human-generated randomness is actually quite predictable, as it falls into patterns called heuristics . To truly randomly select elements, researchers must rely on computer-generated help. Many free websites have good pseudo-random number generators. A good example is the website Random.org , which contains a random number generator that can also randomize lists of participants. Sometimes, researchers use a table of numbers that have been generated randomly. There are several possible sources for obtaining a random number table. Some statistics and research methods textbooks provide such tables in an appendix.
Though simple, this approach to sampling can be tedious since the researcher must assign a number to each person in a sampling frame. Systematic sampling techniques are somewhat less tedious but offer the benefits of a random sample. As with simple random samples, you must possess a list of everyone in your sampling frame. Once you’ve done that, to draw a systematic sample you’d simply select every k th element on your list. But what is k , and where on the list of population elements does one begin the selection process?

Figure 10.2 Systematic sampling
k is your selection interval or the distance between the elements you select for inclusion in your study. To begin the selection process, you’ll need to figure out how many elements you wish to include in your sample. Let’s say you want to survey 25 social work students and there are 100 social work students on your campus. In this case, your selection interval, or k , is 4. To get your selection interval, simply divide the total number of population elements by your desired sample size. Systematic sampling starts by randomly selecting a number between 1 and k to start from, and then recruiting every kth person. In our example, we may start at number 3 and then select the 7th, 11th, 15th (and so forth) person on our list of email addresses. In Figure 10.2, you can see the researcher starts at number 2 and then selects every third person for inclusion in the sample.
There is one clear instance in which systematic sampling should not be employed. If your sampling frame has any pattern to it, you could inadvertently introduce bias into your sample by using a systemic sampling strategy. (Bias will be discussed in more depth in section 10.3.) This is sometimes referred to as the problem of periodicity. Periodicity refers to the tendency for a pattern to occur at regular intervals.
To stray a bit from our example, imagine we were sampling client charts based on the date they entered a health center and recording the reason for their visit. We may expect more admissions for issues related to alcohol consumption on the weekend than we would during the week. The periodicity of alcohol intoxication may bias our sample towards either overrepresenting or underrepresenting this issue, depending on our sampling interval and whether we collected data on a weekday or weekend.
Advanced probability sampling techniques
Returning again to our idea of sampling student email addresses, one of the challenges in our study will be the different types of students. If we are interested in all social work students, it may be helpful to divide our sampling frame, or list of students, into three lists—one for traditional, full-time undergraduate students, another for part-time undergraduate students, and one more for full-time graduate students—and then randomly select from these lists. This is particularly important if we wanted to make sure our sample had the same proportion of each type of student compared with the general population.
This approach is called stratified random sampling . In stratified random sampling, a researcher will divide the study population into relevant subgroups or strata and then draw a sample from each subgroup, or stratum. Strata is the plural of stratum, so it refers to all of the groups while stratum refers to each group. This can be used to make sure your sample has the same proportion of people from each stratum. If, for example, our sample had many more graduate students than undergraduate students, we may draw incorrect conclusions that do not represent what all social work students experience.

Figure 10.3 Stratified sampling
Generally, the goal of stratified random sampling is to recruit a sample that makes sure all elements of the population are included sufficiently that conclusions can be drawn about them. Usually, the purpose is to create a sample that is identical to the overall population along whatever strata you’ve identified. In our sample, it would be graduate and undergraduate students. Stratified random sampling is also useful when a subgroup of interest makes up a relatively small proportion of the overall sample. For example, if your social work program contained relatively few Asian students but you wanted to make sure you recruited enough Asian students to conduct statistical analysis, you could use race to divide people into subgroups or strata and then disproportionately sample from the Asian students to make sure enough of them were in your sample to draw meaningful conclusions. Statistical tests may have a minimum number
Up to this point in our discussion of probability samples, we’ve assumed that researchers will be able to access a list of population elements in order to create a sampling frame. This, as you might imagine, is not always the case. Let’s say, for example, that you wish to conduct a study of health center usage across students at each social work program in your state. Just imagine trying to create a list of every single social work student in the state. Even if you could find a way to generate such a list, attempting to do so might not be the most practical use of your time or resources. When this is the case, researchers turn to cluster sampling. Cluster sampling occurs when a researcher begins by sampling groups (or clusters) of population elements and then selects elements from within those groups.

Figure 10.4 Cluster sampling
Let’s work through how we might use cluster sampling. While creating a list of all social work students in your state would be next to impossible, you could easily create a list of all social work programs in your state. Then, you could draw a random sample of social work programs (your cluster) and then draw another random sample of elements (in this case, social work students) from each of the programs you randomly selected from the list of all programs.
Cluster sampling often works in stages. In this example, we sampled in two stages—(1) social work programs and (2) social work students at each program we selected. However, we could add another stage if it made sense to do so. We could randomly select (1) states in the United States (2) social work programs in that state and (3) individual social work students. As you might have guessed, sampling in multiple stages does introduce a greater possibility of error. Each stage is subject to its own sampling problems. But, cluster sampling is nevertheless a highly efficient method.
Jessica Holt and Wayne Gillespie (2008)\(^3\) used cluster sampling in their study of students’ experiences with violence in intimate relationships. Specifically, the researchers randomly selected 14 classes on their campus and then drew a random sub-sample of students from those classes. But you probably know from your experience with college classes that not all classes are the same size. So, if Holt and Gillespie had simply randomly selected 14 classes and then selected the same number of students from each class to complete their survey, then students in the smaller of those classes would have had a greater chance of being selected for the study than students in the larger classes. Keep in mind, with random sampling the goal is to make sure that each element has the same chance of being selected. When clusters are of different sizes, as in the example of sampling college classes, researchers often use a method called probability proportionate to size (PPS). This means that they take into account that their clusters are of different sizes. They do this by giving clusters different chances of being selected based on their size so that each element within those clusters winds up having an equal chance of being selected.
To summarize, probability samples allow a researcher to make conclusions about larger groups. Probability samples require a sampling frame from which elements, usually human beings, can be selected at random from a list. The use of random selection reduces the error and bias present in non-probability samples, which we will discuss in greater detail in section 10.3, though some error will always remain. In relying on a random number table or generator, researchers can more accurately state that their sample represents the population from which it was drawn. This strength is common to all probability sampling approaches summarized in Table 10.2.
Table 10.2 Types of probability samples
In determining which probability sampling approach makes the most sense for your project, it helps to know more about your population. A simple random sample and systematic sample are relatively similar to carry out. They both require a list all elements in your sampling frame. Systematic sampling is slightly easier in that it does not require you to use a random number generator, instead using a sampling interval that is easy to calculate by hand.
However, the relative simplicity of both approaches is counterweighted by their lack of sensitivity to characteristics of your population. Stratified samples can better account for periodicity by creating strata that reduce or eliminate its effects. Stratified sampling also ensure that smaller subgroups are included in your sample, thereby making your sample more representative of the overall population. While these benefits are important, creating strata for this purpose requires having information about your population before beginning the sampling process. In our social work student example, we would need to know which students are full-time or part-time, graduate or undergraduate, in order to make sure our sample contained the same proportions. Would you know if someone was a graduate student or part-time student, just based on their email address? If the true population parameters are unknown, stratified sampling becomes significantly more challenging.
Common to each of the previous probability sampling approaches is the necessity of using a real list of all elements in your sampling frame. Cluster sampling is different. It allows a researcher to perform probability sampling in cases for which a list of elements is not available or feasible to create. Cluster sampling is also useful for making claims about a larger population (in our previous example, all social work students within a state). However, because sampling occurs at multiple stages in the process, (in our previous example, at the university and student level), sampling error increases. For many researchers, the benefits of cluster sampling outweigh this weaknesses.
Matching recruitment and sampling approach
Recruitment must match the sampling approach you choose in section 10.2. For many students, that will mean using recruitment techniques most relevant to availability sampling. These may include public postings such as flyers, mass emails, or social media posts. However, these methods would not make sense for a study using probability sampling. Probability sampling requires a list of names or other identifying information so you can use a random process to generate a list of people to recruit into your sample. Posting a flyer or social media message means you don’t know who is looking at the flyer, and thus, your sample could not be randomly drawn. Probability sampling often requires knowing how to contact specific participants. For example, you may do as I did, and contact potential participants via phone and email. Even then, it’s important to note that not everyone you contact will enter your study. We will discuss more about evaluating the quality of your sample in section 10.3.
Key Takeaways
- Probability sampling approaches are more accurate when the researcher wants to generalize from a smaller sample to a larger population. However, non-probability sampling approaches are often more feasible. You will have to weigh advantages and disadvantages of each when designing your project.
- There are many kinds of probability sampling approaches, though each require you know some information about people who potentially would participate in your study.
- Probability sampling also requires that you assign people within the sampling frame a number and select using a truly random process.
Building on the step-by-step sampling plan from the exercises in section 10.1:
- Identify one of the sampling approaches listed in this chapter that might be appropriate to answering your question and list the strengths and limitations of it.
- Describe how you will recruit your participants and how your plan makes sense with the sampling approach you identified.
Examine one of the empirical articles from your literature review.
- Identify what sampling approach they used and how they carried it out from start to finish.
- Tools and Resources
- Customer Services
- Business Education
- Business Law
- Business Policy and Strategy
- Entrepreneurship
- Human Resource Management
- Information Systems
- International Business
- Negotiations and Bargaining
- Operations Management
- Organization Theory
- Organizational Behavior
- Problem Solving and Creativity
- Research Methods
- Social Issues
- Technology and Innovation Management
- Share This Facebook LinkedIn Twitter
Article contents
Sampling strategies for quantitative and qualitative business research.
- Vivien Lee Vivien Lee Psychology, University of Minnesota
- and Richard N. Landers Richard N. Landers Psychology, University of Minnesota
- https://doi.org/10.1093/acrefore/9780190224851.013.216
- Published online: 23 March 2022
Sampling refers to the process used to identify and select cases for analysis (i.e., a sample) with the goal of drawing meaningful research conclusions. Sampling is integral to the overall research process as it has substantial implications on the quality of research findings. Inappropriate sampling techniques can lead to problems of interpretation, such as drawing invalid conclusions about a population. Whereas sampling in quantitative research focuses on maximizing the statistical representativeness of a population by a chosen sample, sampling in qualitative research generally focuses on the complete representation of a phenomenon of interest. Because of this core difference in purpose, many sampling considerations differ between qualitative and quantitative approaches despite a shared general purpose: careful selection of cases to maximize the validity of conclusions.
Achieving generalizability, the extent to which observed effects from one study can be used to predict the same and similar effects in different contexts, drives most quantitative research. Obtaining a representative sample with characteristics that reflect a targeted population is critical to making accurate statistical inferences, which is core to such research. Such samples can be best acquired through probability sampling, a procedure in which all members of the target population have a known and random chance of being selected. However, probability sampling techniques are uncommon in modern quantitative research because of practical constraints; non-probability sampling, such as by convenience, is now normative. When sampling this way, special attention should be given to statistical implications of issues such as range restriction and omitted variable bias. In either case, careful planning is required to estimate an appropriate sample size before the start of data collection.
In contrast to generalizability, transferability, the degree to which study findings can be applied to other contexts, is the goal of most qualitative research. This approach is more concerned with providing information to readers and less concerned with making generalizable broad claims for readers. Similar to quantitative research, choosing a population and sample are critical for qualitative research, to help readers determine likelihood of transfer, yet representativeness is not as crucial. Sample size determination in qualitative research is drastically different from that of quantitative research, because sample size determination should occur during data collection, in an ongoing process in search of saturation, which focuses on achieving theoretical completeness instead of maximizing the quality of statistical inference.
Theoretically speaking, although quantitative and qualitative research have distinct statistical underpinnings that should drive different sampling requirements, in practice they both heavily rely on non-probability samples, and the implications of non-probability sampling is often not well understood. Although non-probability samples do not automatically generate poor-quality data, incomplete consideration of case selection strategy can harm the validity of research conclusions. The nature and number of cases collected must be determined cautiously to respect research goals and the underlying scientific paradigm employed. Understanding the commonalities and differences in sampling between quantitative and qualitative research can help researchers better identify high-quality research designs across paradigms.
- non-probability sampling
- convenience sampling
- sample size
- quantitative research
- qualitative research
You do not currently have access to this article
Please login to access the full content.
Access to the full content requires a subscription
Printed from Oxford Research Encyclopedias, Business and Management. Under the terms of the licence agreement, an individual user may print out a single article for personal use (for details see Privacy Policy and Legal Notice).
date: 19 April 2024
- Cookie Policy
- Privacy Policy
- Legal Notice
- Accessibility
- [66.249.64.20|185.80.151.41]
- 185.80.151.41
Character limit 500 /500
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- What Is Quantitative Research? | Definition, Uses & Methods
What Is Quantitative Research? | Definition, Uses & Methods
Published on June 12, 2020 by Pritha Bhandari . Revised on June 22, 2023.
Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations.
Quantitative research is the opposite of qualitative research , which involves collecting and analyzing non-numerical data (e.g., text, video, or audio).
Quantitative research is widely used in the natural and social sciences: biology, chemistry, psychology, economics, sociology, marketing, etc.
- What is the demographic makeup of Singapore in 2020?
- How has the average temperature changed globally over the last century?
- Does environmental pollution affect the prevalence of honey bees?
- Does working from home increase productivity for people with long commutes?
Table of contents
Quantitative research methods, quantitative data analysis, advantages of quantitative research, disadvantages of quantitative research, other interesting articles, frequently asked questions about quantitative research.
You can use quantitative research methods for descriptive, correlational or experimental research.
- In descriptive research , you simply seek an overall summary of your study variables.
- In correlational research , you investigate relationships between your study variables.
- In experimental research , you systematically examine whether there is a cause-and-effect relationship between variables.
Correlational and experimental research can both be used to formally test hypotheses , or predictions, using statistics. The results may be generalized to broader populations based on the sampling method used.
To collect quantitative data, you will often need to use operational definitions that translate abstract concepts (e.g., mood) into observable and quantifiable measures (e.g., self-ratings of feelings and energy levels).
Note that quantitative research is at risk for certain research biases , including information bias , omitted variable bias , sampling bias , or selection bias . Be sure that you’re aware of potential biases as you collect and analyze your data to prevent them from impacting your work too much.
Prevent plagiarism. Run a free check.
Once data is collected, you may need to process it before it can be analyzed. For example, survey and test data may need to be transformed from words to numbers. Then, you can use statistical analysis to answer your research questions .
Descriptive statistics will give you a summary of your data and include measures of averages and variability. You can also use graphs, scatter plots and frequency tables to visualize your data and check for any trends or outliers.
Using inferential statistics , you can make predictions or generalizations based on your data. You can test your hypothesis or use your sample data to estimate the population parameter .
First, you use descriptive statistics to get a summary of the data. You find the mean (average) and the mode (most frequent rating) of procrastination of the two groups, and plot the data to see if there are any outliers.
You can also assess the reliability and validity of your data collection methods to indicate how consistently and accurately your methods actually measured what you wanted them to.
Quantitative research is often used to standardize data collection and generalize findings . Strengths of this approach include:
- Replication
Repeating the study is possible because of standardized data collection protocols and tangible definitions of abstract concepts.
- Direct comparisons of results
The study can be reproduced in other cultural settings, times or with different groups of participants. Results can be compared statistically.
- Large samples
Data from large samples can be processed and analyzed using reliable and consistent procedures through quantitative data analysis.
- Hypothesis testing
Using formalized and established hypothesis testing procedures means that you have to carefully consider and report your research variables, predictions, data collection and testing methods before coming to a conclusion.
Despite the benefits of quantitative research, it is sometimes inadequate in explaining complex research topics. Its limitations include:
- Superficiality
Using precise and restrictive operational definitions may inadequately represent complex concepts. For example, the concept of mood may be represented with just a number in quantitative research, but explained with elaboration in qualitative research.
- Narrow focus
Predetermined variables and measurement procedures can mean that you ignore other relevant observations.
- Structural bias
Despite standardized procedures, structural biases can still affect quantitative research. Missing data , imprecise measurements or inappropriate sampling methods are biases that can lead to the wrong conclusions.
- Lack of context
Quantitative research often uses unnatural settings like laboratories or fails to consider historical and cultural contexts that may affect data collection and results.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square goodness of fit test
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
Operationalization means turning abstract conceptual ideas into measurable observations.
For example, the concept of social anxiety isn’t directly observable, but it can be operationally defined in terms of self-rating scores, behavioral avoidance of crowded places, or physical anxiety symptoms in social situations.
Before collecting data , it’s important to consider how you will operationalize the variables that you want to measure.
Reliability and validity are both about how well a method measures something:
- Reliability refers to the consistency of a measure (whether the results can be reproduced under the same conditions).
- Validity refers to the accuracy of a measure (whether the results really do represent what they are supposed to measure).
If you are doing experimental research, you also have to consider the internal and external validity of your experiment.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2023, June 22). What Is Quantitative Research? | Definition, Uses & Methods. Scribbr. Retrieved April 18, 2024, from https://www.scribbr.com/methodology/quantitative-research/
Is this article helpful?

Pritha Bhandari
Other students also liked, descriptive statistics | definitions, types, examples, inferential statistics | an easy introduction & examples, unlimited academic ai-proofreading.
✔ Document error-free in 5minutes ✔ Unlimited document corrections ✔ Specialized in correcting academic texts

18 10. Quantitative sampling
Chapter outline.
- The sampling process (25 minute read)
- Sampling approaches for quantitative research (15 minute read)
- Sample quality (24 minute read)
Content warning: examples contain references to addiction to technology, domestic violence and batterer intervention, cancer, illegal drug use, LGBTQ+ discrimination, binge drinking, intimate partner violence among college students, child abuse, neocolonialism and Western hegemony.
10.1 The sampling process
Learning objectives.
Learners will be able to…
- Decide where to get your data and who you might need to talk to
- Evaluate whether it is feasible for you to collect first-hand data from your target population
- Describe the process of sampling
- Apply population, sampling frame, and other sampling terminology to sampling people your project’s target population
One of the things that surprised me most as a research methods professor is how much my students struggle with understanding sampling. It is surprising because people engage in sampling all the time. How do you learn whether you like a particular food, like BBQ ribs? You sample them from different restaurants! Obviously, social scientists put a bit more effort and thought into the process than that, but the underlying logic is the same. By sampling a small group of BBQ ribs from different restaurants and liking most of them, you can conclude that when you encounter BBQ ribs again, you will probably like them. You don’t need to eat all of the BBQ ribs in the world to come to that conclusion, just a small sample. [1] Part of the difficulty my students face is learning sampling terminology, which is the focus of this section.

Who is your study about and who should you talk to?
At this point in the research process, you know what your research question is. Our goal in this chapter is to help you understand how to find the people (or documents) you need to study in order to find the answer to your research question. It may be helpful at this point to distinguish between two concepts. Your unit of analysis is the entity that you wish to be able to say something about at the end of your study (probably what you’d consider to be the main focus of your study). Your unit of observation is the entity (or entities) that you actually observe, measure, or collect in the course of trying to learn something about your unit of analysis.
It is often the case that your unit of analysis and unit of observation are the same. For example, we may want to say something about social work students (unit of analysis), so we ask social work students at our university to complete a survey for our study (unit of observation). In this case, we are observing individuals , i.e. students, so we can make conclusions about individual s .
On the other hand, our unit of analysis and observation can differ. We could sample social work students to draw conclusions about organizations or universities. Perhaps we are comparing students at historically Black colleges and universities (HBCUs) and primarily white institutions (PWIs). Even though our sample was made up of individual students from various colleges (our unit of observation), our unit of analysis was the university as an organization. Conclusions we made from individual-level data were used to understand larger organizations.
Similarly, we could adjust our sampling approach to target specific student cohorts. Perhaps we wanted to understand the experiences of Black social work students in PWIs. We could choose either an individual unit of observation by selecting students, or a group unit of observation by studying the National Association of Black Social Workers .
Sometimes the units of analysis and observation differ due to pragmatic reasons. If we wanted to study whether being a social work student impacted family relationships, we may choose to study family members of students in social work programs who could give us information about how they behaved in the home. In this case, we would be observing family members to draw conclusions about individual students.
In sum, there are many potential units of analysis that a social worker might examine, but some of the most common include i ndividuals, groups, and organizations. Table 10.1 details examples identifying the units of observation and analysis in a hypothetical study of student addiction to electronic gadgets.
First-hand vs. second-hand knowledge
Your unit of analysis will be determined by your research question. Specifically, it should relate to your target population. Your unit of observation, on the other hand, is determined largely by the method of data collection you use to answer that research question. Let’s consider a common issue in social work research: understanding the effectiveness of different social work interventions. Who has first-hand knowledge and who has second-hand knowledge? Well, practitioners would have first-hand knowledge about implementing the intervention. For example, they might discuss with you the unique language they use help clients understand the intervention. Clients, on the other hand, have first-hand knowledge about the impact of those interventions on their lives. If you want to know if an intervention is effective, you need to ask people who have received it!
Unfortunately, student projects run into pragmatic limitations with sampling from client groups. Clients are often diagnosed with severe mental health issues or have other ongoing issues that render them a vulnerable population at greater risk of harm. Asking a person who was recently experiencing suicidal ideation about that experience may interfere with ongoing treatment. Client records are also confidential and cannot be shared with researchers unless clients give explicit permission. Asking one’s own clients to participate in the study creates a dual relationship with the client, as both clinician and researcher, and dual relationship have conflicting responsibilities and boundaries.
Obviously, studies are done with social work clients all the time. But for student projects in the classroom, it is often required to get second-hand information from a population that is less vulnerable. Students may instead choose to study clinicians and how they perceive the effectiveness of different interventions. While clinicians can provide an informed perspective, they have less knowledge about personally receiving the intervention. In general, researchers prefer to sample the people who have first-hand knowledge about their topic, though feasibility often forces them to analyze second-hand information instead.
Population: Who do you want to study?
In social scientific research, a population is the cluster of people you are most interested in. It is often the “who” that you want to be able to say something about at the end of your study. While populations in research may be rather large, such as “the American people,” they are more typically more specific than that. For example, a large study for which the population of interest is the American people will likely specify which American people, such as adults over the age of 18 or citizens or legal permanent residents. Based on your work in Chapter 2 , you should have a target population identified in your working question. That might be something like “people with developmental disabilities” or “students in a social work program.”
It is almost impossible for a researcher to gather data from their entire population of interest. This might sound surprising or disappointing until you think about the kinds of research questions that social workers typically ask. For example, let’s say we wish to answer the following question: “How does gender impact attendance in a batterer intervention program?” Would you expect to be able to collect data from all people in batterer intervention programs across all nations from all historical time periods? Unless you plan to make answering this research question your entire life’s work (and then some), I’m guessing your answer is a resounding no. So, what to do? Does not having the time or resources to gather data from every single person of interest mean having to give up your research interest?
Let’s think about who could possibly be in your study.
- What is your population, the people you want to make conclusions about?
- Do your unit of analysis and unit of observation differ or are they the same?
- Can you ethically and practically get first-hand information from the people most knowledgeable about the topic, or will you rely on second-hand information from less vulnerable populations?
Setting: Where will you go to get your data?
While you can’t gather data from everyone, you can find some people from your target population to study. The first rule of sampling is: go where your participants are. You will need to figure out where you will go to get your data. For many student researchers, it is their agency, their peers, their family and friends, or whoever comes across students’ social media posts or emails asking people to participate in their study.
Each setting (agency, social media) limits your reach to only a small segment of your target population who has the opportunity to be a part of your study. This intermediate point between the overall population and the sample of people who actually participate in the researcher’s study is called a sampling frame . A sampling frame is a list of people from which you will draw your sample.
But where do you find a sampling frame? Answering this question is the first step in conducting human subjects research. Social work researchers must think about locations or groups in which your target population gathers or interacts. For example, a study on quality of care in nursing homes may choose a local nursing home because it’s easy to access. The sampling frame could be all of the residents of the nursing home. You would select your participants for your study from the list of residents. Note that this is a real list. That is, an administrator at the nursing home would give you a list with every resident’s name or ID number from which you would select your participants. If you decided to include more nursing homes in your study, then your sampling frame could be all the residents at all the nursing homes who agreed to participate in your study.
Let’s consider some more examples. Unlike nursing home patients, cancer survivors do not live in an enclosed location and may no longer receive treatment at a hospital or clinic. For social work researchers to reach participants, they may consider partnering with a support group that services this population. Perhaps there is a support group at a local church survivors may attend. Without a set list of people, your sampling frame would simply be the people who showed up to the support group on the nights you were there. Similarly, if you posted an advertisement in an online peer-support group for people with cancer, your sampling frame is the people in that group.
More challenging still is recruiting people who are homeless, those with very low income, or those who belong to stigmatized groups. For example, a research study by Johnson and Johnson (2014) [2] attempted to learn usage patterns of “bath salts,” or synthetic stimulants that are marketed as “legal highs.” Users of “bath salts” don’t often gather for meetings, and reaching out to individual treatment centers is unlikely to produce enough participants for a study, as the use of bath salts is rare. To reach participants, these researchers ingeniously used online discussion boards in which users of these drugs communicate. Their sampling frame included everyone who participated in the online discussion boards during the time they collected data. Another example might include using a flyer to let people know about your study, in which case your sampling frame would be anyone who walks past your flyer wherever you hang it—usually in a strategic location where you know your population will be.
In conclusion, sampling frames can be a real list of people like the list of faculty and their ID numbers in a university department, which allows you to clearly identify who is in your study and what chance they have of being selected. However, not all sampling frames allow you to be so specific. It is also important to remember that accessing your sampling frame must be practical and ethical, as we discussed in Chapter 2 and Chapter 6 . For studies that present risks to participants, approval from gatekeepers and the university’s institutional review board (IRB) is needed.
Criteria: What characteristics must your participants have/not have?
Your sampling frame is not just everyone in the setting you identified. For example, if you were studying MSW students who are first-generation college students, you might select your university as the setting, but not everyone in your program is a first-generation student. You need to be more specific about which characteristics or attributes individuals either must have or cannot have before they participate in the study. These are known as inclusion and exclusion criteria, respectively.
Inclusion criteria are the characteristics a person must possess in order to be included in your sample. If you were conducting a survey on LGBTQ+ discrimination at your agency, you might want to sample only clients who identify as LGBTQ+. In that case, your inclusion criteria for your sample would be that individuals have to identify as LGBTQ+.
Comparably, exclusion criteria are characteristics that disqualify a person from being included in your sample. In the previous example, you could think of cisgenderism and heterosexuality as your exclusion criteria because no person who identifies as heterosexual or cisgender would be included in your sample. Exclusion criteria are often the mirror image of inclusion criteria. However, there may be other criteria by which we want to exclude people from our sample. For example, we may exclude clients who were recently discharged or those who have just begun to receive services.

Recruitment: How will you ask people to participate in your study?
Once you have a location and list of people from which to select, all that is left is to reach out to your participants. Recruitment refers to the process by which the researcher informs potential participants about the study and asks them to participate in the research project. Recruitment comes in many different forms. If you have ever received a phone call asking for you to participate in a survey, someone has attempted to recruit you for their study. Perhaps you’ve seen print advertisements on buses, in student centers, or in a newspaper. I’ve received many emails that were passed around my school asking for participants, usually for a graduate student project. As we learn more about specific types of sampling, make sure your recruitment strategy makes sense with your sampling approach. For example, if you put up a flyer in the student health office to recruit student athletes for your study, you may not be targeting your recruitment efforts to settings where your target population is likely to see your recruitment materials.
Recruiting human participants
Sampling is the first time in which you will contact potential study participants. Before you start this process, it is important to make sure you have approval from your university’s institutional review board as well as any gatekeepers at the locations in which you plan to conduct your study. As we discussed in section 10.1, the first rule of sampling is to go where your participants are. If you are studying domestic violence, reach out to local shelters, advocates, or service agencies. Gatekeepers will be necessary to gain access to your participants. For example, a gatekeeper can forward your recruitment email across their employee email list. Review our discussion of gatekeepers in Chapter 2 before proceeding with contacting potential participants as part of recruitment.
Recruitment can take many forms. You may show up at a staff meeting to ask for volunteers. You may send a company-wide email. Each step of this process should be vetted by the IRB as well as other stakeholders and gatekeepers. You will also need to set reasonable expectations for how many reminders you will send to the person before moving on. Generally, it is a good idea to give people a little while to respond, though reminders are often accompanied by an increase in participation. Pragmatically, it is a good idea for you to think through each step of the recruitment process and how much time it will take to complete it.
For example, as a graduate student, I conducted a study of state-level disabilities administrators in which I was recruiting a sample of very busy people and had no financial incentives to offer them for participating in my study. It helped for my research team to bring on board a well-known agency as a research partner, allowing them to review and offer suggestions on our survey and interview questions. This collaborative process took time and had to be completed before sampling could start. Once sampling commenced, I pulled contact names from my collaborator’s database and public websites, and set a weekly schedule of email and phone contacts. I would contact the director once via email. Ten days later, I would follow up via email and by leaving a voicemail with their administrative support staff. Ten days after that, I would reach out to state administrators in a different office via email and then again via phone, if needed. The process took months to complete and required a complex Excel tracking document.
Recruitment will also expose your participants to the informed consent information you prepared. For students going through the IRB, there are templates you will have to follow in order to get your study approved. For students whose projects unfold under the supervision of their department, rather than the IRB, you should check with your professor on what the expectations are for getting participant consent. In the aforementioned study, I used our IRB’s template to create a consent form but did not include a signature line. The IRB allowed me to collect my data without a signature, as there was little risk of harm from the study. It was imperative to review consent information before completing the survey and interview with participants. Only when the participant is totally clear on the purpose, risks and benefits, confidentiality protections, and other information detailed in Chapter 6 , can you ethically move forward with including them in your sample.
Sampling available documents
As with sampling humans, sampling documents centers around the question: which documents are the most relevant to your research question, in that which will provide you first-hand knowledge. Common documents analyzed in student research projects include client files, popular media like film and music lyrics, and policies from service agencies. In a case record review, the student would create exclusion and inclusion criteria based on their research question. Once a suitable sampling frame of potential documents exists, the researcher can use probability or non-probability sampling to select which client files are ultimately analyzed.
Sampling documents must also come with consent and buy-in from stakeholders and gatekeepers. Assuming you have approval to conduct your study and access to the documents you need, the process of recruitment is much easier than in studies sampling humans. There is no informed consent process with documents, though research with confidential health or education records must be done in accordance with privacy laws such as the Health Insurance Portability and Accountability Act and the Family Educational Rights and Privacy Act . Barring any technical or policy obstacles, the gathering of documents should be easier and less time consuming than sampling humans.
Sample: Who actually participates in your study?
Once you find a sampling frame from which you can recruit your participants and decide which characteristics you will include and exclude, you will recruit people using a specific sampling approach, which we will cover in Section 10.2. At the end, you’re left with the group of people you successfully recruited from your sampling frame to participate in your study, your sample . If you are a participant in a research project—answering survey questions, participating in interviews, etc.—you are part of the sample in that research project.
Visualizing sampling terms
Sampling terms can be a bit daunting at first. However, with some practice, they will become second nature. Let’s walk through an example from a research project of mine. I collected data for a research project related to how much it costs to become a licensed clinical social worker (LCSW) in each state. Becoming an LCSW is necessary to work in private clinical practice and is used by supervisors in human service organizations to sign off on clinical charts from less credentialed employees, and to provide clinical supervision. If you are interested in providing clinical services as a social worker, you should become familiar with the licensing laws in your state.

Using Figure 10.1 as a guide, my population is clearly clinical social workers, as these are the people about whom I want to draw conclusions. The next step inward would be a sampling frame. Unfortunately, there is no list of every licensed clinical social worker in the United States. I could write to each state’s social work licensing board and ask for a list of names and addresses, perhaps even using a Freedom of Information Act request if they were unwilling to share the information. That option sounds time-consuming and has a low likelihood of success. Instead, I tried to figure out a convenient setting social workers are likely to congregate. I considered setting up a booth at a National Association of Social Workers (NASW) conference and asking people to participate in my survey. Ultimately, this would prove too costly, and the people who gather at an NASW conference may not be representative of the general population of clinical social workers. I finally discovered the NASW membership email list, which is available to advertisers, including researchers advertising for research projects. While the NASW list does not contain every clinical social worker, it reaches over one hundred thousand social workers regularly through its monthly e-newsletter, a large proportion of social workers in practice, so the setting was likely to draw a representative sample. To gain access to this setting from gatekeepers, I had to provide paperwork showing my study had undergone IRB review and submit my measures for approval by the mailing list administrator.
Once I gained access from gatekeepers, my setting became the members of the NASW membership list. I decided to recruit 5,000 participants because I knew that people sometimes do not read or respond to email advertisements, and I figured maybe 20% would respond, which would give me around 1,000 responses. Figuring out my sample size was a challenge, because I had to balance the costs associated with using the NASW newsletter. As you can see on their pricing page , it would cost money to learn personal information about my potential participants, which I would need to check later in order to determine if my population was representative of the overall population of social workers. For example, I could see if my sample was comparable in race, age, gender, or state of residence to the broader population of social workers by comparing my sample with information about all social workers published by NASW. I presented my options to my external funder as:
- I could send an email advertisement to a lot of people (5,000), but I would know very little about them and they would get only one advertisement.
- I could send multiple advertisements to fewer people (1,000) reminding them to participate, but I would also know more about them by purchasing access to personal information.
- I could send multiple advertisements to fewer people (2,500), but not purchase access to personal information to minimize costs.
In your project, there is no expectation you purchase access to anything, and if you plan on using email advertisements, consider places that are free to access like employee or student listservs. At the same time, you will need to consider what you can know or not know about the people who will potentially be in your study, and I could collect any personal information we wanted to check representativeness in the study itself. For this reason, we decided to go with option #1. When I sent my email recruiting participants for the study, I specified that I only wanted to hear from social workers who were either currently receiving or recently received clinical supervision for licensure—my inclusion criteria. This was important because many of the people on the NASW membership list may not be licensed or license-seeking social workers. So, my sampling frame was the email addresses on the NASW mailing list who fit the inclusion criteria for the study, which I figured would be at least a few thousand people. Unfortunately, only 150 licensed or license-seeking clinical social workers responded to my recruitment email and completed the survey. You will learn in Section 10.3 why this did not make for a very good sample.
From this example, you can see that sampling is a process. The process flows sequentially from figuring out your target population, to thinking about where to find people from your target population, to figuring out how much information you know about potential participants, and finally to selecting recruiting people from that list to be a part of your sample. Through the sampling process, you must consider where people in your target population are likely to be and how best to get their attention for your study. Sampling can be an easy process, like calling every 100th name from the phone book, or challenging, like standing every day for a few weeks in an area in which people who are homeless gather for shelter. In either case, your goal is to recruit enough people who will participate in your study so you can learn about your population.
What about sampling non-humans?
Many student projects do not involve recruiting and sampling human subjects. Instead, many research projects will sample objects like client charts, movies, or books. The same terms apply, but the process is a bit easier because there are no humans involved. If a research project involves analyzing client files, it is unlikely you will look at every client file that your agency has. You will need to figure out which client files are important to your research question. Perhaps you want to sample clients who have a diagnosis of reactive attachment disorder. You would have to create a list of all clients at your agency (setting) who have reactive attachment disorder (your inclusion criteria) then use your sampling approach (which we will discuss in the next section) to select which client files you will actually analyze for your study (your sample). Recruitment is a lot easier because, well, there’s no one to convince but your gatekeepers, the managers of your agency. However, researchers who publish chart reviews must obtain IRB permission before doing so.
Key Takeaways
- The first rule of sampling is to go where your participants are. Think about virtual or in-person settings in which your target population gathers. Remember that you may have to engage gatekeepers and stakeholders in accessing many settings, and that you will need to assess the pragmatic challenges and ethical risks and benefits of your study.
- Consider whether you can sample documents like agency files to answer your research question. Documents are much easier to “recruit” than people!
- Researchers must consider which characteristics are necessary for people to have (inclusion criteria) or not have (exclusion criteria), as well as how to recruit participants into the sample.
- Social workers can sample individuals, groups, or organizations.
- Sometimes the unit of analysis and the unit of observation in the study differ. In student projects, this is often true as target populations may be too vulnerable to expose to research whose potential harms may outweigh the benefits.
- One’s recruitment method has to match one’s sampling approach, as will be explained in the next chapter.
Once you have identified who may be a part of your study, the next step is to think about where those people gather. Are there in-person locations in your community or on the internet that are easily accessible. List at least one potential setting for your project. Describe for each potential setting:
- Based on what you know right now, how representative of your population are potential participants in the setting?
- How much information can you reasonably know about potential participants before you recruit them?
- Are there gatekeepers and what kinds of concerns might they have?
- Are there any stakeholders that may be beneficial to bring on board as part of your research team for the project?
- What interests might stakeholders and gatekeepers bring to the project and would they align with your vision for the project?
- What ethical issues might you encounter if you sampled people in this setting.
Even though you may not be 100% sure about your setting yet, let’s think about the next steps.
- For the settings you’ve identified, how might you recruit participants?
- Identify your inclusion criteria and exclusion criteria, and assess whether you have enough information on whether people in each setting will meet them.
10.2 Sampling approaches for quantitative research
- Determine whether you will use probability or non-probability sampling, given the strengths and limitations of each specific sampling approach
- Distinguish between approaches to probability sampling and detail the reasons to use each approach
Sampling in quantitative research projects is done because it is not feasible to study the whole population, and researchers hope to take what we learn about a small group of people (your sample) and apply it to a larger population. There are many ways to approach this process, and they can be grouped into two categories—probability sampling and non-probability sampling. Sampling approaches are inextricably linked with recruitment, and researchers should ensure that their proposal’s recruitment strategy matches the sampling approach.
Probability sampling approaches use a random process, usually a computer program, to select participants from the sampling frame so that everyone has an equal chance of being included. It’s important to note that random means the researcher used a process that is truly random . In a project sampling college students, standing outside of the building in which your social work department is housed and surveying everyone who walks past is not random. Because of the location, you are likely to recruit a disproportionately large number of social work students and fewer from other disciplines. Depending on the time of day, you may recruit more traditional undergraduate students, who take classes during the day, or more graduate students, who take classes in the evenings.
In this example, you are actually using non-probability sampling . Another way to say this is that you are using the most common sampling approach for student projects, availability sampling . Also called convenience sampling, this approach simply recruits people who are convenient or easily available to the researcher. If you have ever been asked by a friend to participate in their research study for their class or seen an advertisement for a study on a bulletin board or social media, you were being recruited using an availability sampling approach.
There are a number of benefits to the availability sampling approach. First and foremost, it is less costly and time-consuming for the researcher. As long as the person you are attempting to recruit has knowledge of the topic you are studying, the information you get from the sample you recruit will be relevant to your topic (although your sample may not necessarily be representative of a larger population). Availability samples can also be helpful when random sampling isn’t practical. If you are planning to survey students in an LGBTQ+ support group on campus but attendance varies from meeting to meeting, you may show up at a meeting and ask anyone present to participate in your study. A support group with varied membership makes it impossible to have a real list—or sampling frame—from which to randomly select individuals. Availability sampling would help you reach that population.
Availability sampling is appropriate for student and smaller-scale projects, but it comes with significant limitations. The purpose of sampling in quantitative research is to generalize from a small sample to a larger population. Because availability sampling does not use a random process to select participants, the researcher cannot be sure their sample is representative of the population they hope to generalize to. Instead, the recruitment processes may have been structured by other factors that may bias the sample to be different in some way than the overall population.
So, for instance, if we asked social work students about their level of satisfaction with the services at the student health center, and we sampled in the evenings, we would get most likely get a biased perspective of the issue. Students taking only night classes are much more likely to commute to school, spend less time on campus, and use fewer campus services. Our results would not represent what all social work students feel about the topic. We might get the impression that no social work student had ever visited the health center, when that is not actually true at all. Sampling bias will be discussed in detail in Section 10.3.

Approaches to probability sampling
What might be a better strategy is getting a list of all email addresses of social work students and randomly selecting email addresses of students to whom you can send your survey. This would be an example of simple random sampling . It’s important to note that you need a real list of people in your sampling frame from which to select your email addresses. For projects where the people who could potentially participate is not known by the researcher, probability sampling is not possible. It is likely that administrators at your school’s registrar would be reluctant to share the list of students’ names and email addresses. Always remember to consider the feasibility and ethical implications of the sampling approach you choose.
Usually, simple random sampling is accomplished by assigning each person, or element , in your sampling frame a number and selecting your participants using a random number generator. You would follow an identical process if you were sampling records or documents as your elements, rather than people. True randomness is difficult to achieve, and it takes complex computational calculations to do so. Although you think you can select things at random, human-generated randomness is actually quite predictable, as it falls into patterns called heuristics . To truly randomly select elements, researchers must rely on computer-generated help. Many free websites have good pseudo-random number generators. A good example is the website Random.org , which contains a random number generator that can also randomize lists of participants. Sometimes, researchers use a table of numbers that have been generated randomly. There are several possible sources for obtaining a random number table. Some statistics and research methods textbooks provide such tables in an appendix.
Though simple, this approach to sampling can be tedious since the researcher must assign a number to each person in a sampling frame. Systematic sampling techniques are somewhat less tedious but offer the benefits of a random sample. As with simple random samples, you must possess a list of everyone in your sampling frame. Once you’ve done that, to draw a systematic sample you’d simply select every k th element on your list. But what is k , and where on the list of population elements does one begin the selection process?

k is your selection interval or the distance between the elements you select for inclusion in your study. To begin the selection process, you’ll need to figure out how many elements you wish to include in your sample. Let’s say you want to survey 25 social work students and there are 100 social work students on your campus. In this case, your selection interval, or k , is 4. To get your selection interval, simply divide the total number of population elements by your desired sample size. Systematic sampling starts by randomly selecting a number between 1 and k to start from, and then recruiting every kth person. In our example, we may start at number 3 and then select the 7th, 11th, 15th (and so forth) person on our list of email addresses. In Figure 10.2, you can see the researcher starts at number 2 and then selects every third person for inclusion in the sample.
There is one clear instance in which systematic sampling should not be employed. If your sampling frame has any pattern to it, you could inadvertently introduce bias into your sample by using a systemic sampling strategy. (Bias will be discussed in more depth in section 10.3.) This is sometimes referred to as the problem of periodicity. Periodicity refers to the tendency for a pattern to occur at regular intervals.
To stray a bit from our example, imagine we were sampling client charts based on the date they entered a health center and recording the reason for their visit. We may expect more admissions for issues related to alcohol consumption on the weekend than we would during the week. The periodicity of alcohol intoxication may bias our sample towards either overrepresenting or underrepresenting this issue, depending on our sampling interval and whether we collected data on a weekday or weekend.
Advanced probability sampling techniques
Returning again to our idea of sampling student email addresses, one of the challenges in our study will be the different types of students. If we are interested in all social work students, it may be helpful to divide our sampling frame, or list of students, into three lists—one for traditional, full-time undergraduate students, another for part-time undergraduate students, and one more for full-time graduate students—and then randomly select from these lists. This is particularly important if we wanted to make sure our sample had the same proportion of each type of student compared with the general population.
This approach is called stratified random sampling . In stratified random sampling, a researcher will divide the study population into relevant subgroups or strata and then draw a sample from each subgroup, or stratum. Strata is the plural of stratum, so it refers to all of the groups while stratum refers to each group. This can be used to make sure your sample has the same proportion of people from each stratum. If, for example, our sample had many more graduate students than undergraduate students, we may draw incorrect conclusions that do not represent what all social work students experience.

Generally, the goal of stratified random sampling is to recruit a sample that makes sure all elements of the population are included sufficiently that conclusions can be drawn about them. Usually, the purpose is to create a sample that is identical to the overall population along whatever strata you’ve identified. In our sample, it would be graduate and undergraduate students. Stratified random sampling is also useful when a subgroup of interest makes up a relatively small proportion of the overall sample. For example, if your social work program contained relatively few Asian students but you wanted to make sure you recruited enough Asian students to conduct statistical analysis, you could use race to divide people into subgroups or strata and then disproportionately sample from the Asian students to make sure enough of them were in your sample to draw meaningful conclusions. Statistical tests may have a minimum number
Up to this point in our discussion of probability samples, we’ve assumed that researchers will be able to access a list of population elements in order to create a sampling frame. This, as you might imagine, is not always the case. Let’s say, for example, that you wish to conduct a study of health center usage across students at each social work program in your state. Just imagine trying to create a list of every single social work student in the state. Even if you could find a way to generate such a list, attempting to do so might not be the most practical use of your time or resources. When this is the case, researchers turn to cluster sampling. Cluster sampling occurs when a researcher begins by sampling groups (or clusters) of population elements and then selects elements from within those groups.

Let’s work through how we might use cluster sampling. While creating a list of all social work students in your state would be next to impossible, you could easily create a list of all social work programs in your state. Then, you could draw a random sample of social work programs (your cluster) and then draw another random sample of elements (in this case, social work students) from each of the programs you randomly selected from the list of all programs.
Cluster sampling often works in stages. In this example, we sampled in two stages—(1) social work programs and (2) social work students at each program we selected. However, we could add another stage if it made sense to do so. We could randomly select (1) states in the United States (2) social work programs in that state and (3) individual social work students. As you might have guessed, sampling in multiple stages does introduce a greater possibility of error. Each stage is subject to its own sampling problems. But, cluster sampling is nevertheless a highly efficient method.
Jessica Holt and Wayne Gillespie (2008) [3] used cluster sampling in their study of students’ experiences with violence in intimate relationships. Specifically, the researchers randomly selected 14 classes on their campus and then drew a random sub-sample of students from those classes. But you probably know from your experience with college classes that not all classes are the same size. So, if Holt and Gillespie had simply randomly selected 14 classes and then selected the same number of students from each class to complete their survey, then students in the smaller of those classes would have had a greater chance of being selected for the study than students in the larger classes. Keep in mind, with random sampling the goal is to make sure that each element has the same chance of being selected. When clusters are of different sizes, as in the example of sampling college classes, researchers often use a method called probability proportionate to size (PPS). This means that they take into account that their clusters are of different sizes. They do this by giving clusters different chances of being selected based on their size so that each element within those clusters winds up having an equal chance of being selected.
To summarize, probability samples allow a researcher to make conclusions about larger groups. Probability samples require a sampling frame from which elements, usually human beings, can be selected at random from a list. The use of random selection reduces the error and bias present in non-probability samples, which we will discuss in greater detail in section 10.3, though some error will always remain. In relying on a random number table or generator, researchers can more accurately state that their sample represents the population from which it was drawn. This strength is common to all probability sampling approaches summarized in Table 10.2.
In determining which probability sampling approach makes the most sense for your project, it helps to know more about your population. A simple random sample and systematic sample are relatively similar to carry out. They both require a list all elements in your sampling frame. Systematic sampling is slightly easier in that it does not require you to use a random number generator, instead using a sampling interval that is easy to calculate by hand.
However, the relative simplicity of both approaches is counterweighted by their lack of sensitivity to characteristics of your population. Stratified samples can better account for periodicity by creating strata that reduce or eliminate its effects. Stratified sampling also ensure that smaller subgroups are included in your sample, thereby making your sample more representative of the overall population. While these benefits are important, creating strata for this purpose requires having information about your population before beginning the sampling process. In our social work student example, we would need to know which students are full-time or part-time, graduate or undergraduate, in order to make sure our sample contained the same proportions. Would you know if someone was a graduate student or part-time student, just based on their email address? If the true population parameters are unknown, stratified sampling becomes significantly more challenging.
Common to each of the previous probability sampling approaches is the necessity of using a real list of all elements in your sampling frame. Cluster sampling is different. It allows a researcher to perform probability sampling in cases for which a list of elements is not available or feasible to create. Cluster sampling is also useful for making claims about a larger population (in our previous example, all social work students within a state). However, because sampling occurs at multiple stages in the process, (in our previous example, at the university and student level), sampling error increases. For many researchers, the benefits of cluster sampling outweigh this weaknesses.
Matching recruitment and sampling approach
Recruitment must match the sampling approach you choose in section 10.2. For many students, that will mean using recruitment techniques most relevant to availability sampling. These may include public postings such as flyers, mass emails, or social media posts. However, these methods would not make sense for a study using probability sampling. Probability sampling requires a list of names or other identifying information so you can use a random process to generate a list of people to recruit into your sample. Posting a flyer or social media message means you don’t know who is looking at the flyer, and thus, your sample could not be randomly drawn. Probability sampling often requires knowing how to contact specific participants. For example, you may do as I did, and contact potential participants via phone and email. Even then, it’s important to note that not everyone you contact will enter your study. We will discuss more about evaluating the quality of your sample in section 10.3.
- Probability sampling approaches are more accurate when the researcher wants to generalize from a smaller sample to a larger population. However, non-probability sampling approaches are often more feasible. You will have to weigh advantages and disadvantages of each when designing your project.
- There are many kinds of probability sampling approaches, though each require you know some information about people who potentially would participate in your study.
- Probability sampling also requires that you assign people within the sampling frame a number and select using a truly random process.
Building on the step-by-step sampling plan from the exercises in section 10.1:
- Identify one of the sampling approaches listed in this chapter that might be appropriate to answering your question and list the strengths and limitations of it.
- Describe how you will recruit your participants and how your plan makes sense with the sampling approach you identified.
Examine one of the empirical articles from your literature review.
- Identify what sampling approach they used and how they carried it out from start to finish.
10.3 Sample quality
- Assess whether your sampling plan is likely to produce a sample that is representative of the population you want to draw conclusions about
- Identify the considerations that go into producing a representative sample and determining sample size
- Distinguish between error and bias in a sample and explain the factors that lead to each
Okay, so you’ve chosen where you’re going to get your data (setting), what characteristics you want and don’t want in your sample (inclusion/exclusion criteria), and how you will select and recruit participants (sampling approach and recruitment). That means you are done, right? (I mean, there’s an entire section here, so probably not.) Even if you make good choices and do everything the way you’re supposed to, you can still draw a poor sample. If you are investigating a research question using quantitative methods, the best choice is some kind of probability sampling, but aside from that, how do you know a good sample from a bad sample? As an example, we’ll use a bad sample I collected as part of a research project that didn’t go so well. Hopefully, your sampling will go much better than mine did, but we can always learn from what didn’t work.

Representativeness
A representative sample is, “a sample that looks like the population from which it was selected in all respects that are potentially relevant to the study” (Engel & Schutt, 2011). [4] For my study on how much it costs to get an LCSW in each state, I did not get a sample that looked like the overall population to which I wanted to generalize. My sample had a few states with more than ten responses and most states with no responses. That does not look like the true distribution of social workers across the country. I could compare the number of social workers in each state, based on data from the National Association of Social Workers, or the number of recent clinical MSW graduates from the Council on Social Work Education. More than that, I could see whether my sample matched the overall population of clinical social workers in gender, race, age, or any other important characteristics. Sadly, it wasn’t even close. So, I wasn’t able to use the data to publish a report.
Critique the representativeness of the sample you are planning to gather.
- Will the sample of people (or documents) look like the population to which you want to generalize?
- Specifically, what characteristics are important in determining whether a sample is representative of the population? How do these characteristics relate to your research question?
Consider returning to this question once you have completed the sampling process and evaluate whether the sample in your study was similar to what you designed in this section.
Many of my students erroneously assume that using a probability sampling technique will guarantee a representative sample. This is not true. Engel and Schutt (2011) identify that probability sampling increases the chance of representativeness; however, it does not guarantee that the sample will be representative. If a representative sample is important to your study, it would be best to use a sampling approach that allows you to control the proportion of specific characteristics in your sample. For instance, stratified random sampling allows you to control the distribution of specific variables of interest within your sample. However, that requires knowing information about your participants before you hand them surveys or expose them to an experiment.
In my study, if I wanted to make sure I had a certain number of people from each state (state being the strata), making the proportion of social workers from each state in my sample similar to the overall population, I would need to know which email addresses were from which states. That was not information I had. So, instead I conducted simple random sampling and randomly selected 5,000 of 100,000 email addresses on the NASW list. There was less of a guarantee of representativeness, but whatever variation existed between my sample and the population would be due to random chance. This would not be true for an availability or convenience sample. While these sampling approaches are common for student projects, they come with significant limitations in that variation between the sample and population is due to factors other than chance. We will discuss these non-random differences later in the chapter when we talk about bias. For now, just remember that the representativeness of a sample is helped by using random sampling, though it is not a guarantee.
- Before you start sampling, do you know enough about your sampling frame to use stratified random sampling, which increases the potential of getting a representative sample?
- Do you have enough information about your sampling frame to use another probability sampling approach like simple random sampling or cluster sampling?
- If little information is available on which to select people, are you using availability sampling? Remember that availability sampling is okay if it is the only approach that is feasible for the researcher, but it comes with significant limitations when drawing conclusions about a larger population.
Assessing representativeness should start prior to data collection. I mentioned that I drew my sample from the NASW email list, which (like most organizations) they sell to advertisers when companies or researchers need to advertise to social workers. How representative of my population is my sampling frame? Well, the first question to ask is what proportion of my sampling frame would actually meet my exclusion and inclusion criteria. Since my study focused specifically on clinical social workers, my sampling frame likely included social workers who were not clinical social workers, like macro social workers or social work managers. However, I knew, based on the information from NASW marketers, that many people who received my recruitment email would be clinical social workers or those working towards licensure, so I was satisfied with that. Anyone who didn’t meet my inclusion criteria and opened the survey would be greeted with clear instructions that this survey did not apply to them.
At the same time, I should have assessed whether the demographics of the NASW email list and the demographics of clinical social workers more broadly were similar. Unfortunately, this was not information I could gather. I had to trust that this was likely to going to be the best sample I could draw and the most representative of all social workers.
- Before you start, what do you know about your setting and potential participants?
- Are there likely to be enough people in the setting of your study who meet the inclusion criteria?
You want to avoid throwing out half of the surveys you get back because the respondents aren’t a part of your target population. This is a common error I see in student proposals.
Many of you will sample people from your agency, like clients or staff. Let’s say you work for a children’s mental health agency, and you wanted to study children who have experienced abuse. Walking through the steps here might proceed like this:
- Think about or ask your coworkers how many of the clients at your agency have experienced this issue. If it’s common, then clients at your agency would probably make a good sampling frame for your study. If not, then you may want to adjust your research question or consider a different agency to sample. You could also change your target population to be more representative with your sample. For example, while your agency’s clients may not be representative of all children who have survived abuse, they may be more representative of abuse survivors in your state, region, or county. In this way, you can draw conclusions about a smaller population, rather than everyone in the world who is a victim of child abuse.
- Think about those characteristics that are important for individuals in your sample to have or not have. Obviously, the variables in your research question are important, but so are the variables related to it. Take a look at the empirical literature on your topic. Are there different demographic characteristics or covariates that are relevant to your topic?
- All of this assumes that you can actually access information about your sampling frame prior to collecting data. This is a challenge in the real world. Even if you ask around your office about client characteristics, there is no way for you to know for sure until you complete your study whether it was the most representative sampling frame you could find. When in doubt, go with whatever is feasible and address any shortcomings in sampling within the limitations section of your research report. A good project is a done project.
- While using a probability sampling approach helps with sample representativeness, it does not guarantee it. Due to random variation, samples may differ across important characteristics. If you can feasibly use a probability sampling approach, particularly stratified random sampling, it will help make your sample more representative of the population.
- Even if you choose a sampling frame that is representative of your population and use a probability sampling approach, there is no guarantee that the sample you are able to collect will be representative. Sometimes, people don’t respond to your recruitment efforts. Other times, random chance will mean people differ on important characteristics from your target population. ¯\_(ツ)_/¯
In agency-based samples, the small size of the pool of potential participants makes it very likely that your sample will not be representative of a broader target population. Sometimes, researchers look for specific outcomes connected with sub-populations for that reason. Not all agency-based research is concerned with representativeness, and it is still worthwhile to pursue research that is relevant to only one location as its purpose is often to improve social work practice.

Sample size
Let’s assume you have found a representative sampling frame, and that you are using one of the probability sampling approaches we reviewed in section 10.2. That should help you recruit a representative sample, but how many people do you need to recruit into your sample? As with many questions about sample quality, students should keep feasibility in mind. The easiest answer I’ve given as a professor is, “as many as you can, without hurting yourself.” While your quantitative research question would likely benefit from hundreds or thousands of respondents, that is not likely to be feasible for a student who is working full-time, interning part-time, and in school full-time. Don’t feel like your study has to be perfect, but make sure you note any limitations in your final report.
To the extent possible, you should gather as many people as you can in your sample who meet your criteria. But why? Let’s think about an example you probably know well. Have you ever watched the TV show Family Feud ? Each question the host reads off starts with, “we asked 100 people…” Believe it or not, Family Feud uses simple random sampling to conduct their surveys the American public. Part of the challenge on Family Feud is that people can usually guess the most popular answers, but those answers that only a few people chose are much harder. They seem bizarre, and are more difficult to guess. That’s because 100 people is not a lot of people to sample. Essentially, Family Feud is trying to measure what the answer is for all 327 million people in the United States by asking 100 of them. As a result, the weird and idiosyncratic responses of a few people are likely to remain on the board as answers, and contestants have to guess answers fewer and fewer people in the sample provided. In a larger sample, the oddball answers would likely fade away and only the most popular answers would be represented on the game show’s board.
In my ill-fated study of clinical social workers, I received 87 complete responses. That is far below the hundred thousand licensed or license-eligible clinical social workers. Moreover, since I wanted to conduct state-by-state estimates, there was no way I had enough people in each state to do so. For student projects, samples of 50-100 participants are more than enough to write a paper (or start a game show), but for projects in the real world with real-world consequences, it is important to recruit the appropriate number of participants. For example, if your agency conducts a community scan of people in your service area on what services they need, the results will inform the direction of your agency, which grants they apply for, who they hire, and its mission for the next several years. Being overly confident in your sample could result in wasted resources for clients.
So what is the right number? Theoretically, we could gradually increase the sample size so that the sample approaches closer and closer to the total size of the population (Bhattacherjeee, 2012). [5] But as we’ve talked about, it is not feasible to sample everyone. How do we find that middle ground? To answer this, we need to understand the sampling distribution . Imagine in your agency’s survey of the community, you took three different probability samples from your community, and for each sample, you measured whether people experienced domestic violence. If each random sample was truly representative of the population, then your rate of domestic violence from the three random samples would be about the same and equal to the true value in the population.
But this is extremely unlikely, given that each random sample will likely constitute a different subset of the population, and hence, the rate of domestic violence you measure may be slightly different from sample to sample. Think about the sample you collect as existing on a distribution of infinite possible samples. Most samples you collect will be close to the population mean but many will not be. The degree to which they differ is associated with how much the subject you are sampling about varies in the population. In our example, samples will vary based on how varied the incidence of domestic violence is from person to person. The difference between the domestic violence rate we find and the rate for our overall population is called the sampling error .
An easy way to minimize sampling error is to increase the number of participants in your sample, but in actuality, minimizing sampling error relies on a number of factors outside of the scope of a basic student project. You can see this online textbook for more examples on sampling distributions or take an advanced methods course at your university, particularly if you are considering becoming a social work researcher. Increasing the number of people in your sample also increases your study’s power , or the odds you will detect a significant relationship between variables when one is truly present in your sample. If you intend on publishing the findings of your student project, it is worth using a power analysis to determine the appropriate sample size for your project. You can follow this excellent video series from the Center for Open Science on how to conduct power analyses using free statistics software. A faculty members who teaches research or statistics could check your work. You may be surprised to find out that there is a point at which you adding more people to your sample will not make your study any better.
Honestly, I did not do a power analysis for my study. Instead, I asked for 5,000 surveys with the hope that 1,000 would come back. Given that only 87 came back, a power analysis conducted after the survey was complete would likely to reveal that I did not have enough statistical power to answer my research questions. For your projects, try to get as many respondents as you feasibly can, but don’t worry too much about not reaching the optimal amount of people to maximize the power of your study unless you goal is to publish something that is generalizable to a large population.
A final consideration is which statistical test you plan to use to analyze your data. We have not covered statistics yet, though we will provide a brief introduction to basic statistics in this textbook. For now, remember that some statistical tests have a minimum number of people that must be present in the sample in order to conduct the analysis. You will complete a data analysis plan before you begin your project and start sampling, so you can always increase the number of participants you plan to recruit based on what you learn in the next few chapters.
- How many people can you feasibly sample in the time you have to complete your project?

One of the interesting things about surveying professionals is that sometimes, they email you about what they perceive to be a problem with your study. I got an email from a well-meaning participant in my LCSW study saying that my results were going to be biased! She pointed out that respondents who had been in practice a long time, before clinical supervision was required, would not have paid anything for supervision. This would lead me to draw conclusions that supervision was cheap, when in fact, it was expensive. My email back to her explained that she hit on one of my hypotheses, that social workers in practice for a longer period of time faced fewer costs to becoming licensed. Her email reinforced that I needed to account for the impact of length of practice on the costs of licensure I found across the sample. She was right to be on the lookout for bias in the sample.
One of the key questions you can ask is if there is something about your process that makes it more likely you will select a certain type of person for your sample, making it less representative of the overall population. In my project, it’s worth thinking more about who is more likely to respond to an email advertisement for a research study. I know that my work email and personal email filter out advertisements, so it’s unlikely I would even see the recruitment for my own study (probably something I should have thought about before using grant funds to sample the NASW email list). Perhaps an older demographic that does not screen advertisements as closely, o r those whose NASW account was linked to a personal email with fewer junk filters would be more likely to respond. To the extent I made conclusions about clinical social workers of all ages based on a sample that was biased towards older social workers, my results would be biased. This is called selection bias , or the degree to which people in my sample differ from the overall population.
Another potential source of bias here is nonresponse bias . Because people do not often respond to email advertisements (no matter how well-written they are), my sample is likely to be representative of people with characteristics that make them more likely to respond. They may have more time on their hands to take surveys and respond to their junk mail. To the extent that the sample is comprised of social workers with a lot of time on their hands (who are those people?) my sample will be biased and not representative of the overall population.
It’s important to note that both bias and error describe how samples differ from the overall population. Error describes random variations between samples, due to chance. Using a random process to recruit participants into a sample means you will have random variation between the sample and the population. Bias creates variance between the sample and population in a specific direction, such as towards those who have time to check their junk mail. Bias may be introduced by the sampling method used or due to conscious or unconscious bias introduced by the researcher (Rubin & Babbie, 2017). [6] A researcher might select people who “look like good research participants,” in the process transferring their unconscious biases to their sample. They might exclude people from the sampling from who “would not do well with the intervention.” Careful researchers can avoid these, but unconscious and structural biases can be challenging to root out.
- Identify potential sources of bias in your sample and brainstorm ways you can minimize them, if possible.
Critical considerations
Think back to you undergraduate degree. Did you ever participate in a research project as part of an introductory psychology or sociology course? Social science researchers on college campuses have a luxury that researchers elsewhere may not share—they have access to a whole bunch of (presumably) willing and able human guinea pigs. But that luxury comes at a cost—sample representativeness. One study of top academic journals in psychology found that over two-thirds (68%) of participants in studies published by those journals were based on samples drawn in the United States (Arnett, 2008). [7] Further, the study found that two-thirds of the work that derived from US samples published in the Journal of Personality and Social Psychology was based on samples made up entirely of American undergraduate students taking psychology courses.
These findings certainly raise the question: What do we actually learn from social science studies and about whom do we learn it? That is exactly the concern raised by Joseph Henrich and colleagues (Henrich, Heine, & Norenzayan, 2010), [8] authors of the article “The Weirdest People in the World?” In their piece, Henrich and colleagues point out that behavioral scientists very commonly make sweeping claims about human nature based on samples drawn only from WEIRD (Western, Educated, Industrialized, Rich, and Democratic) societies, and often based on even narrower samples, as is the case with many studies relying on samples drawn from college classrooms. As it turns out, robust findings about the nature of human behavior when it comes to fairness, cooperation, visual perception, trust, and other behaviors are based on studies that excluded participants from outside the United States and sometimes excluded anyone outside the college classroom (Begley, 2010). [9] This certainly raises questions about what we really know about human behavior as opposed to US resident or US undergraduate behavior. Of course, not all research findings are based on samples of WEIRD folks like college students. But even then, it would behoove us to pay attention to the population on which studies are based and the claims being made about those to whom the studies apply.
Another thing to keep in mind is that just because a sample may be representative in all respects that a researcher thinks are relevant, there may be relevant aspects that didn’t occur to the researcher when she was drawing her sample. You might not think that a person’s phone would have much to do with their voting preferences, for example. But had pollsters making predictions about the results of the 2008 presidential election not been careful to include both cell phone-only and landline households in their surveys, it is possible that their predictions would have underestimated Barack Obama’s lead over John McCain because Obama was much more popular among cell phone-only users than McCain (Keeter, Dimock, & Christian, 2008). [10] This is another example of bias.

Putting it all together
So how do we know how good our sample is or how good the samples gathered by other researchers are? While there might not be any magic or always-true rules we can apply, there are a couple of things we can keep in mind as we read the claims researchers make about their findings.
First, remember that sample quality is determined only by the sample actually obtained, not by the sampling method itself. A researcher may set out to administer a survey to a representative sample by correctly employing a random sampling approach with impeccable recruitment materials. But, if only a handful of the people sampled actually respond to the survey, the researcher should not make claims like their sample went according to plan.
Another thing to keep in mind, as demonstrated by the preceding discussion, is that researchers may be drawn to talking about implications of their findings as though they apply to some group other than the population actually sampled. Whether the sampling frame does not match the population or the sample and population differ on important criteria, the resulting sampling error can lead to bad science.
We’ve talked previously about the perils of generalizing social science findings from graduate students in the United States and other Western countries to all cultures in the world, imposing a Western view as the right and correct view of the social world. As consumers of theory and research, it is our responsibility to be attentive to this sort of (likely unintentional) bait and switch. And as researchers, it is our responsibility to make sure that we only make conclusions from samples that are representative. A larger sample size and probability sampling can improve the representativeness and generalizability of the study’s findings to larger populations, though neither are guarantees.
Finally, keep in mind that a sample allowing for comparisons of theoretically important concepts or variables is certainly better than one that does not allow for such comparisons. In a study based on a nonrepresentative sample, for example, we can learn about the strength of our social theories by comparing relevant aspects of social processes. We talked about this as theory-testing in Chapter 8 .
At their core, questions about sample quality should address who has been sampled, how they were sampled, and for what purpose they were sampled. Being able to answer those questions will help you better understand, and more responsibly interpret, research results. For your study, keep the following questions in mind.
- Are your sample size and your sampling approach appropriate for your research question?
- How much do you know about your sampling frame ahead of time? How will that impact the feasibility of different sampling approaches?
- What gatekeepers and stakeholders are necessary to engage in order to access your sampling frame?
- Are there any ethical issues that may make it difficult to sample those who have first-hand knowledge about your topic?
- Does your sampling frame look like your population along important characteristics? Once you get your data, ask the same question of the sample you successfully recruit.
- What about your population might make it more difficult or easier to sample?
- Are there steps in your sampling procedure that may bias your sample to render it not representative of the population?
- If you want to skip sampling altogether, are there sources of secondary data you can use? Or might you be able to answer you questions by sampling documents or media, rather than people?
- The sampling plan you implement should have a reasonable likelihood of producing a representative sample. Student projects are given more leeway with nonrepresentative samples, and this limitation should be discussed in the student’s research report.
- Researchers should conduct a power analysis to determine sample size, though quantitative student projects should endeavor to recruit as many participants as possible. Sample size impacts representativeness of the sample, its power, and which statistical tests can be conducted.
- The sample you collect is one of an infinite number of potential samples that could have been drawn. To the extent the data in your sample varies from the data in the entire population, it includes some error or bias. Error is the result of random variations. Bias is systematic error that pushes the data in a given direction.
- Even if you do everything right, there is no guarantee that you will draw a good sample. Flawed samples are okay to use as examples in the classroom, but the results of your research would have limited generalizability beyond your specific participants.
- Historically, samples were drawn from dominant groups and generalized to all people. This shortcoming is a limitation of some social science literature and should be considered a colonialist scientific practice.
- I clearly need a snack. ↵
- Johnson, P. S., & Johnson, M. W. (2014). Investigation of “bath salts” use patterns within an online sample of users in the United States. Journal of psychoactive drugs , 46 (5), 369-378. ↵
- Holt, J. L., & Gillespie, W. (2008). Intergenerational transmission of violence, threatened egoism, and reciprocity: A test of multiple psychosocial factors affecting intimate partner violence. American Journal of Criminal Justice, 33 , 252–266. ↵
- Engel, R. & Schutt (2011). The practice of research in social work (2nd ed.) . California: SAGE ↵
- Bhattacherjee, A. (2012). Social science research: Principles, methods, and practices . Retrieved from: https://scholarcommons.usf.edu/cgi/viewcontent.cgi?article=1002&context=oa_textbooks ↵
- Rubin, C. & Babbie, S. (2017). Research methods for social work (9th edition) . Boston, MA: Cengage. ↵
- Arnett, J. J. (2008). The neglected 95%: Why American psychology needs to become less American. American Psychologist , 63, 602–614. ↵
- Henrich, J., Heine, S. J., & Norenzayan, A. (2010). The weirdest people in the world? Behavioral and Brain Sciences , 33, 61–135. ↵
- Newsweek magazine published an interesting story about Henrich and his colleague’s study: Begley, S. (2010). What’s really human? The trouble with student guinea pigs. Retrieved from http://www.newsweek.com/2010/07/23/what-s-really-human.html ↵
- Keeter, S., Dimock, M., & Christian, L. (2008). Calling cell phones in ’08 pre-election polls. The Pew Research Center for the People and the Press . Retrieved from http://people-press.org/files/legacy-pdf/cell-phone-commentary.pdf ↵
entity that a researcher wants to say something about at the end of her study (individual, group, or organization)
the entities that a researcher actually observes, measures, or collects in the course of trying to learn something about her unit of analysis (individuals, groups, or organizations)
the larger group of people you want to be able to make conclusions about based on the conclusions you draw from the people in your sample
the list of people from which a researcher will draw her sample
the people or organizations who control access to the population you want to study
an administrative body established to protect the rights and welfare of human research subjects recruited to participate in research activities conducted under the auspices of the institution with which it is affiliated
Inclusion criteria are general requirements a person must possess to be a part of your sample.
characteristics that disqualify a person from being included in a sample
the process by which the researcher informs potential participants about the study and attempts to get them to participate
the group of people you successfully recruit from your sampling frame to participate in your study
sampling approaches for which a person’s likelihood of being selected from the sampling frame is known
sampling approaches for which a person’s likelihood of being selected for membership in the sample is unknown
researcher gathers data from whatever cases happen to be convenient or available
(as in generalization) to make claims about a large population based on a smaller sample of people or items
selecting elements from a list using randomly generated numbers
the units in your sampling frame, usually people or documents
selecting every kth element from your sampling frame
the distance between the elements you select for inclusion in your study
the tendency for a pattern to occur at regular intervals
dividing the study population into subgroups based on a characteristic (or strata) and then drawing a sample from each subgroup
the characteristic by which the sample is divided in stratified random sampling
a sampling approach that begins by sampling groups (or clusters) of population elements and then selects elements from within those groups
in cluster sampling, giving clusters different chances of being selected based on their size so that each element within those clusters has an equal chance of being selected
a sample that looks like the population from which it was selected in all respects that are potentially relevant to the study
the set of all possible samples you could possibly draw for your study
The difference between what you find in a sample and what actually exists in the population from which the sample was drawn.
the odds you will detect a significant relationship between variables when one is truly present in your sample
the degree to which people in my sample differs from the overall population
The bias that occurs when those who respond to your request to participate in a study are different from those who do not respond to you request to participate in a study.
Graduate research methods in social work Copyright © 2021 by Matthew DeCarlo, Cory Cummings, Kate Agnelli is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
What are quantitative research sampling methods?
The quantitative research sampling method is the process of selecting representable units from a large population. Quantitative research refers to the analysis wherein mathematical, statistical, or computational method is used for studying the measurable or quantifiable dataset. The core purpose of quantitative research is the generalization of a phenomenon or an opinion. This involves collecting and gathering information from a small group out of a population or universe.
To find out what drives Amazon’s popularity as the most preferred e-commerce company, a small group of Amazon’s customers can be surveyed. It will help arrive at a consensus on the most significant traits that make it successful.
Therefore, an assumption about a population is based on a small or selected dataset. In order to derive accurate results, it is essential to use an appropriate sampling method. The purpose of this article is to review different quantitative sampling methods and their applicability in different types of research.
Quantitative research sampling methods
By examining the nature of the small group, the researcher can deduce the behaviour of the larger population. Quantitative research sampling methods are broadly divided into two categories i.e.
- Probability sampling
- Non-probability sampling

Probability sampling method
In probability sampling, each unit in the population has an equal chance of being selected for the sample. The purpose is to identify those sample sets which majorly represent the characteristics of the population. Herein, all the characteristics of the population are required to be known. This is done through a process known as ‘listing’. This process of listing is called the sampling frame. As probability sampling is a type of random sampling, the generalization is more accurate.
Probability sampling is quite time-consuming and expensive. Hence, this method is only suitable in cases wherein the population are similar in characteristics, and the researcher has time, money, and access to the whole population. Probability sampling is further categorized into 4 types: simple random, systematic, stratified and cluster sampling. The figure below depicts the types of probability sampling.

The difference between and applicability of these sampling methods are depicted in the table below.
Non-probability sampling method
Non-probability-based quantitative research sampling method involves non-random selection of the sample from the entire population. All units of the population do not an equal chance of participating in the survey. Therefore, the results cannot be generalized for the population.
The non-probability technique of sampling is based on the subjective judgement of the researcher. Hence this method can be applied in cases wherein limited information about the population is available. Moreover, it requires less time and money. Non-probability sampling method can be of four types as shown below.

Table 2: Non-probability-based Quantitative research sampling method
The results of the quantitative research are mainly based on the information acquired from the sample. An effective sample yields a representable outcome. To draw valid and reliable conclusions, it is essential to carefully compute the sample size of the study and define the sampling technique of the study.
- McCombes, S. (2019) Understanding different sampling methods . Available at: https://www.scribbr.com/methodology/sampling-methods/ (Accessed: 7 February 2020).
- Click to share on Twitter (Opens in new window)
- Click to share on Facebook (Opens in new window)
- Click to share on LinkedIn (Opens in new window)
- Click to share on WhatsApp (Opens in new window)
- Click to share on Telegram (Opens in new window)
Notify me of follow-up comments by email.
1 thought on “What are quantitative research sampling methods?”
Proofreading.
Research Methodology Explained: A Beginner's Guide

Research methodology stands as the backbone of credible study, guiding the generation and analysis of data towards solving research queries. It encompasses not just the practical aspects of data collection but also the theoretical framework that shapes the study's direction, distinguishing methodology in research from mere methods.
This foundational process, characterized by its systematic, logical, empirical, and replicable nature, underscores the importance of research methodology in contributing to the vast expanse of knowledge across disciplines.
Beyond a mere overview, we will explore varied research methodology types such as applied, basic, and correlational research, offering insight into how each approach serves the objectives of research methodology. Through a methodological approach, readers will gain knowledge of the critical steps and decisions that shape a robust study, from selecting the right research methodology to interpreting findings.
Understanding Research Methodology
Research methodology is essential in scientific investigations, providing a structured approach to data collection, analysis, and interpretation. This systematic method ensures that research findings are reliable, valid, and generalizable, making it possible to draw credible conclusions that contribute to existing knowledge.
Key Elements of Research Methodology
- Research Design : This includes the overall strategy that outlines the procedures for collecting, analyzing, and interpreting data. The design is crucial as it helps align the research methods with the objectives of the study, ensuring that the results are effective in addressing the research questions.
- Data Collection Methods : Depending on the nature of the study, researchers may employ various techniques such as surveys, interviews, or observation. Each method is chosen based on its ability to gather the necessary data effectively.
- Data Analysis Techniques : After data collection, the next step is analyzing this data to derive meaningful insights. Techniques vary widely from statistical analysis in quantitative studies to content analysis in qualitative research.
Research Approaches and Their Applications
- Qualitative Methods : These are used to gather in-depth insights into people’s attitudes, behaviors, and experiences and often involve methods like interviews and focus groups.
- Quantitative Methods : In contrast, quantitative methods focus on numerical data and often employ statistical tests to validate hypotheses.
- Mixed Methods : Combining both qualitative and quantitative approaches, mixed methods provide a comprehensive analysis that strengthens the research findings by addressing the limitations of each method alone.
By employing a well-structured research methodology, scientists and scholars can ensure that their studies are robust, replicable, and impactful. This foundation not only supports the validity of the research findings but also enhances the overall credibility of the scientific inquiry.
Types of Research Methodology
Overview of methodological approaches.
The landscape of research methodology is dominated by three primary approaches: quantitative, qualitative, and mixed methods. Each approach offers unique insights and tools for investigation, catering to different research objectives.
- Objective : Focuses on quantifying data and generalizing results from a sample to a larger population.
- Methods : Employs structured techniques such as surveys and statistical analysis to produce numerical data.
- Applications : Ideal for testing hypotheses, establishing patterns, and making predictions.
- Objective : Aims to provide a detailed description and interpretation of research subjects.
- Methods : Utilizes interviews, focus groups, and observations to gather in-depth, non-numerical data.
- Applications : Best suited for exploring complex concepts and understanding underlying motivations or behaviors.
- Objective : Combines elements of both qualitative and quantitative research to cover more ground.
- Methods : Integrates numerical data analysis with detailed descriptions, enhancing the robustness of the findings.
- Applications : Useful for validating quantitative data with qualitative insights and explaining anomalies.
Data Collection and Analysis Techniques
Each methodological approach employs specific techniques for data collection and analysis, tailored to its unique requirements.
- Data Collection : Includes sampling, surveys, and structured observations.
- Data Analysis : Features statistical methods such as regression analysis, correlation, and descriptive statistics.
- Data Collection : Comprises one-on-one interviews, document reviews, and qualitative observations.
- Data Analysis : Involves methods like thematic analysis, discourse analysis, and narrative analysis.
- Data Collection : A combination of both quantitative and qualitative data collection methods.
- Data Analysis : Integrates quantitative statistical analysis with qualitative content analysis.
Sampling Designs
The choice of sampling design plays a critical role in the credibility and generalizability of the research.
- Types : Includes simple random, stratified, systematic, and cluster sampling.
- Feature : Each member of the population has a known chance of being selected.
- Types : Encompasses convenience, purposive, snowball, and quota sampling.
- Feature : Selection is based on the researcher’s judgment, often used when probability sampling is not feasible.
This structured approach to understanding the types of research methodology not only clarifies the distinctions between them but also highlights their specific applications and techniques, providing a comprehensive framework for researchers to base their methodological choices.
Choosing the Right Research Methodology
Assessing research goals and context.
- Clarify Research Objectives : It's crucial to start by clearly understanding the research goals, objectives, and questions. This clarity will guide the choice of methodology, ensuring it aligns with what you aim to discover or prove.
- Evaluate the Setting and Participants : Consider the physical, social, or cultural context of the study along with the characteristics of the population involved. This assessment helps in choosing a methodology that is sensitive to contextual variables and participant demographics.
Methodological Considerations
- Review Previous Studies : Look at the methodologies employed in previous research within the same discipline or those that addressed similar objectives. This can provide insights into what methods might be most effective or what new approaches could offer fresh perspectives.
- Practical Constraints : Acknowledge any practical limitations such as experimental conditions, resource availability, and time constraints. These factors can significantly influence the feasibility of certain research methodologies over others.
Choosing Between Qualitative and Quantitative Approaches
- Quantitative Research : Opt for quantitative methods when the goal is to quantify data and generalize results from a sample to a larger population. This approach is suitable for establishing facts or testing hypotheses.
- Qualitative Research : Choose qualitative methods if the aim is to gain a deeper understanding of people’s experiences or perspectives. This approach is ideal for exploring complex issues in detail.
- Mixed Methods : Consider using mixed methods to leverage the strengths of both qualitative and quantitative approaches, especially when the research aims to provide a comprehensive analysis of the topic.
By carefully considering these factors, researchers can select the most appropriate methodology to address their specific research questions effectively and efficiently.
Key Components of Research Methodology
Research design and planning.
- Clarify Research Objectives : Begin by defining clear and measurable objectives, which guide all subsequent decisions in the research process.
- Select Research Type : Determine whether the study is exploratory, descriptive, explanatory, or experimental, as this shapes the research design.
- Choose Appropriate Methods : Based on the research type, select methods for data collection and analysis that best suit the study's needs.
Data Collection and Analysis
- Qualitative : Includes interviews, focus groups, and observations, which provide depth and context.
- Quantitative : Involves surveys and experiments that yield quantifiable data for statistical analysis.
- Probability Sampling : Ensures every member of the population has a known chance of selection.
- Nonprobability Sampling : Used when probability sampling isn't feasible; based on researcher’s judgment.
Ethical Considerations and Methodological Rigor
- Ethical Standards : Adhere to ethical guidelines such as informed consent, confidentiality, and minimizing harm.
- Validity and Reliability : Implement measures to ensure the research is both valid (accurately measures what it is supposed to measure) and reliable (yields consistent results).
- Pilot Testing : Conduct preliminary testing to refine data collection strategies and address potential issues.
By integrating these components, researchers can enhance the credibility and impact of their studies, ensuring that findings are both trustworthy and actionable.
Throughout this exploration of research methodology, we have journeyed from the foundational principles that delineate methodology from mere methods to the intricate distinctions between qualitative, quantitative, and mixed methods research.
This comprehensive guide underscores the pivotal role that a well-structured methodology plays in validating research findings, enhancing the credibility of scientific inquiries, and ultimately, contributing to the vast expanse of knowledge across various fields.
For those looking to dive deeper into the intricacies of research methods or seeking to refine their methodology choice, tools like TLDR This offer valuable resources for further exploration and understanding. By continually engaging with research methodologies and embracing their evolution, the scientific community can forge new paths of discovery, innovation, and impact.
1. How can one describe their research methodology effectively?
To effectively describe your research methodology, follow these steps:
- Begin by restating your thesis or research problem.
- Detail the approach you chose for the research.
- Mention any unique methodologies you employed.
- Describe the data collection process.
- Explain how the data was analyzed.
2. What are the main types of research methodologies?
The four primary research methodologies are:
- Qualitative research, which focuses on understanding concepts, thoughts, or experiences.
- Quantitative research, which involves the statistical, mathematical, or numerical analysis of data.
- Mixed methods research, which combines elements of both qualitative and quantitative research.
3. What does the term "research methodology" mean for beginners?
Research methodology refers to the section in a research paper that outlines the tools, techniques, and procedures used to gather and analyze data. This section is crucial as it helps readers assess the study's reliability and validity.
4. What are the seven fundamental research methods commonly used?
The seven basic research methods frequently utilized in studies are:
- Observation and Participant Observation
- Focus Groups
- Experiments
- Secondary Data Analysis or Archival Study
- Mixed Methods, which is a combination of several of the aforementioned methods.
Sign up for more like this.
- Reference Manager
- Simple TEXT file
People also looked at
Original research article, how to manifest the fertilizer reduction effect of pro-environmental agricultural technologies from the perspective of farmers’ perception and behavioral adoption.

- 1 School of Economics, Nanjing University of Finance and Economics, Nanjing, Jiangsu, China
- 2 State Key Laboratory of Earth Surface Processes and Resource Ecology (ESPRE), Beijing Normal University, Beijing, China
- 3 School of Natural Resources, Faculty of Geographical Science, Beijing Normal University, Beijing, China
- 4 School of Economics and Management, Nanchang Hangkong University, Nanchang, Jiangxi, China
Introduction: The ecological and environmental pollution problem at the source of agriculture cannot be ignored, and the manifestation of the fertilizer reduction effect of pro-environmentally agricultural technologies (PEATs) will help motivate farmers to adopt technology, thereby promoting sustainable agricultural development.
Methods: From the dual perspectives of farmers’ perception and behavior effects, this paper uses 607 survey data of Chinese farmers, and an endogenous switching regression model is employed to identify the influencing factors of farmers’ adoption of PEATs and manifest its fertilizer reduction effect.
Results and discussion: The results of the perception survey show that the farmers’ recognition of the fertilizer reduction effect of PEATs is not high, and the technical effect needs to be further demonstrated. Moreover, the estimated results suggest that PEATs can significantly reduce the fertilizer application of farmers. Specifically, if farmers who have adopted PEATs do not adopt them, they will apply more chemical fertilizers, the farmers who have not adopted PEATs will use less chemical fertilizer if they do. Overall, the main influencing factors for farmers adopting PEATs include education level, government officials, cultivated land area, soil fertility, information access channels, and the distance of home-agricultural technology station. This study aims to provide empirical evidence for the formulation of strategies and plans to promote sustainable agricultural development.
1 Introduction
There is a consensus that chemical fertilizers play an important role in addressing global hunger and malnutrition, achieving increased production and income for farmers, and effectively ensuring food security ( Erisman et al., 2008 ; Guo et al., 2022 ; Schulte-Uebbing et al., 2022 ), especially for developing countries ( Wang et al., 2018 ; Shahzad et al., 2019 ; Lin et al., 2022 ). For example, fertilizer contributes over 40% of China’ s crop yields growth, making it possible for China to feed 22% of the world’s population with 9% of the world’s cultivated land ( Huang et al., 2010 ; Lu et al., 2015 ; Hu et al., 2019 ). Nevertheless, the excessive and uncontrolled use of chemical fertilizers has led to serious environmental problems, such as non-point source pollution, water pollution, soil quality degradation, greenhouse gas emissions ( Trimpler et al., 2016 ; Wang et al., 2018 ; Guo et al., 2022 ; Anik et al., 2023 ). As the world’s largest consumer of chemical fertilizers, China’s use of agricultural chemical fertilizer application increased from 8.84 million tons to 50.79 million tons between 1978 and 2023 ( National Bureau of Statistics of China (NBSC), 2023 ), with fertilizer application intensity far exceeding international standards ( Guo et al., 2022 ). Furthermore, the chemical fertilizer utilization rate for major food crops was only 40.2%, lower than in the EU and other developed countries. Therefore, how to reduce fertilizer application requires more policy intervention and empirical study.
In order to address the adverse effects of excessive use of chemical fertilizers, a global consensus has been reached on promoting sustainable agricultural development strategies ( Shahzad et al., 2019 ; Schulte-Uebbing et al., 2022 ; Zhou et al., 2023 ). In view of this, policy-and technology-led solutions are designed to reduce fertilizer use. On the one hand, subsidies and tax tools are used to advocate for farmers to reduce fertilization, while laws and regulations are designed to regulate and restrict the use of fertilizer to farmers ( Brady, 2003 ; Wang et al., 2018 ; Lin et al., 2022 ). In such cases, in 2015, China released a detailed document entitled “action plan for zero-growth in fertilizer use by 2020 ” (see Jin and Zhou, 2018 ). On the other hand, some PEATs dedicated to improving soil fertility and improving fertilizer utilization efficiency have been developed and promoted by relevant departments and institutions ( Egodawatta et al., 2012 ; Jordan-Meille et al., 2012 ; Kuang et al., 2023 ).
It is worth noting that the implementation of policies and technical solutions to reduce fertilizers application cannot be separated from farmers. As the user of cultivated land, farmers are also the decision-making subject of chemical fertilizer reduction, and play an important role in promoting the sustainable development of agriculture ( Bopp et al., 2019 ; Lai et al., 2020 ; Kuang et al., 2023 ). In China, lots of work and effort have been put into promoting PEATs, but the actual promotion effect is not satisfactory. Specifically, farmers still follow the “heavy utilization, light protection” approach to cultivated land utilization, and the actual adoption rate of PEATs is not high ( Lai et al., 2020 ; Kuang et al., 2023 ; Qing et al., 2023 ), even stay at the cognitive level of “whether they have heard of it” ( Liu et al., 2019 ; Rust et al., 2021 ). Undoubtedly, this goes against the original intention of designing a plan to reduce fertilizer use. So, what exactly is the reason that inhibits farmers from adopting PEATs?
After reviewing previous studies, we found that existing studies mainly reveal the reasons why farmers are unwilling to adopt PEAT from two aspects. For one thing, the transformation of farmers from the traditional agricultural production mode to the sustainable agriculture is a complex behavioral decision-making process ( Baumgart-Getz et al., 2012 ; Ward et al., 2018 ; Kuang et al., 2023 ), which is influenced by multi-dimensional factors ( Burton, 2014 ; Wang et al., 2018 ; Pham et al., 2022 ). However, existing studies do not agree on the influence mechanism of PEATs adoption, and even have opposite results. For another thing, farmers do not agree that PEATs are effective, and even have doubts about this ( Abdallah et al., 2021 ).
Therefore, the potential contribution of this article lies in answering the question of whether adopting PEATs can reduce chemical fertilizer application from the perspectives of farmer perception and behavioral adoption. Furthermore, an endogenous switching regression model that can solve the problems of sample selection and endogeneity is employed for unbiased estimation, revealing the impact mechanism of PEATs adoption by farmers.
2 Methodology
2.1 study area.
The Poyang Lake Plain is mainly distributed in the northern part of Jiangxi Province, China, located at 27°32′-30°06′ N and 115°01′-117°34′ E. The Poyang Lake Plain is formed by the impact of the Poyang Lake water body, covering a land area of 38760.6 km 2 , accounting for 23.2% of Jiangxi Province, while the cultivated land area accounts for 37.3% of Jiangxi Province. The humid subtropical monsoon climate brings abundant rainfall and sufficient heat and light, convenient irrigation resources and long farming culture create favorable agricultural development conditions for the region, which also brings wealth to the local farmers ( Kuang et al., 2023 ). The Poyang Lake Plain has always been a major grain producing area in Jiangxi Province and one of the important rice producing areas in China ( Li et al., 2012 ). The rice planting area in this region accounts for more than half of the total crop planting area in Jiangxi Province, and 86% of the grain crop planting area in Jiangxi Province is concentrated here ( Kuang et al., 2023 ).
2.2 Sampling procedure
The sampling procedure was carried out in accordance with the four stages shown in Figure 1 . The first stage, the preliminary questionnaire was designed. After literature review and expert consultation, we designed the preliminary survey questionnaire. In the second stage, the final survey questionnaire was determined. In October 2020, 50 farmers in Poyang County were selected to test the preliminary questionnaire. Local government officials and villagers were invited to participate in the focus group discussion (FGDs). After FGDs and pre-survey, the preliminary questionnaire was modified and improved, and the final survey questionnaire was determined. The third stage, a formal survey is conducted. In December 2020, we organized a field survey of farmers in the Poyang Lake Plain. The fourth stage, data review and analysis was carried out. We conducted a logical relationship check on the collected survey data, eliminating incomplete and contradictory questionnaire data, and the valid data was used for subsequent analysis.

Figure 1 . The schematic flow chart of questionnaire survey.
In field investigation, the method of combining simple random sampling and stratified random sampling is used to obtain the survey data of farmers. Specifically, based on the results of advanced grain production counties in China and Jiangxi Province from 2004 to 2014, 1 we preferentially selected six Counties around the Poyang Lake as sample points. Moreover, township population, size, and geographical location were considered as a sampling basis, and 2 sample townships were selected from each county. Then, 3 sample villages were randomly selected from each township, 15–20 farmers in each selected village were randomly invited to participate in the questionnaire. As mentioned above, we conducted this survey in October 2020 and distributed 630 questionnaires. After reviewing the questionnaire data, we finally obtained 607 valid farmer survey data.
2.3 Econometric model
In Eq. (1) , where Y j represents the amount of chemical fertilizer applied by farmers in planting rice; X j ' indicates the influencing factors of chemical fertilizer application (e.g., personal, household and cultivated land resource characteristics); D j is set as the production decision of whether farmers adopt PEATs, D j = 1 indicates that farmers have adopted PEATs, and D j = 0 indicates that farmers have not adopted PEATs; β 0 and γ 0 are the corresponding estimated coefficients; ε j is the random error term.
If the decision of farmers adopting PEATs is exogenous, then γ 0 can accurately assess the impact of PEATs. However, farmers’ adoption behavior decision-making of PEATs is also affected by factors (e.g., personal, household and cultivated land resource characteristics), making farmers’ PEATs adoption behavior not entirely exogenous, leading to the existence of self selection problems in the model. If the problem of sample self selection is ignored and the ordinary least square method (OLS) is continued for estimation, it will easily lead to biased estimation ( Lokshin and Sajaia, 2004 ; Kuang et al., 2023 ).
Due to the fact that deciding whether to adopt PEATs is a self choice made by farmers after analyzing expected benefits, there are some unobservable factors such as personal preferences and management skills of farmers, which simultaneously affect their adoption behavior and the level of behavioral effects. In other words, there is a problem of sample self selection. Therefore, we cannot consider the decision variable PEAT in model (1) as an exogenous variable. If the problem of sample self selection is ignored, model (1) uses the least squares method (OLS) to estimate, and the estimated results of the model will be biased. After reviewing existing literature, many scholars have used propensity score matching (PSM) to solve the problem of selectivity bias. However, this method cannot solve the endogeneity problem of omitted variables caused by unobservable factors. In addition, some scholars have attempted to use instrumental variable method (IV) to estimate, but this method did not consider the heterogeneity of treatment effects. Many scholars use the endogenous switching regression (ESR) model to explore the behavioral effects of farmers. Besides inheriting the advantages of the propensity score matching (PSM) method and instrumental variable method, ESR model also has its unique advantages. Specifically, it not only addresses the sample selectivity bias and endogenous problems resulting from both observable and unobservable factors, but also corrects the setting bias or missing variables in the equation by introducing inverse Mills ratio coefficients ( Lokshin and Sajaia, 2004 ; Ma and Abdulai, 2016 ). Furthermore, the full information maximum likelihood estimation is employed to implement counterfactual analysis, which will ameliorate the problem of models missing valid information ( Khanal et al., 2018 ). ESR model includes the following equations:
In Eqs. (2–4) , where Q j indicates the influencing factor of farmers’ response to PEATs; V j represents identification variable; Y j n and Y j a represent the behavioral effects of farmers who did not adopt and adopt PEATs, respectively; X j n and X j y are the influencing factors of behavioral effects; π , δ , β n , β y are the corresponding coefficients to be estimated; ξ j , μ j n , μ j a are the random standard error terms for each equation.
Based on the construction of the counterfactual analysis framework, the average treatment effect of the behavioral effect of farmers adopting PEATs in both the real and counterfactual scenarios was estimated.
2.4 Selection of variables
Dependent variable. Given that it is not possible for farmers to apply only single element fertilizers (e.g., Nitrogen, Phosphorus and Potassium fertilizer) when planting rice, exploring only single element fertilizers often masks the true effect of PEATs in reducing chemical fertilizer application. Therefore, the amount of pure chemical fertilization was set as the explanatory variable.
Key independent variables. PEATs are a generic term that includes multiple types of agricultural technologies, and farmers may also adopt more than one of these agricultural technologies. Learning from the processing method of Kuang et al. (2023) , this study will focus on three production stages of growing rice (before, during and postpartum), and select a PEATs commonly used by farmers in each production stage. Therefore, three kinds of PEATs, namely green manure (GM), soil testing and formula fertilization (STFF) and straw returning to field (SR), were set as the key independent variables.
Control variables. According to existing studies ( Khonje et al., 2018 ; Wossen et al., 2019 ; Xie and Huang, 2021 ; Kuang et al., 2023 ), this study selected 3–4 control variables from three aspects: personal characteristics, family characteristics, and farm characteristics of the surveyed farmers. Specifically, age, gender, education (personal characteristics), population, income, government officials (family characteristics), cultivated land area, cultivated land fragmentation, soil fertility, and cultivation distance (farm characteristics) were set as control variables.
Identification variables. “Information acquisition channels” and “the distance to agricultural technology station” are set as identification variables. The reason is that information channels such as agricultural technology stations are the main sources for farmers to receive the latest agricultural information, especially for new agricultural technologies such as PEATs. In other words, these two identification variables have a direct and important impact on farmers’ adoption of PEATs. Moreover, the commuting distance from home to the agricultural technology stations is objectively exists, and the impact on fertilizer application is weak. The variable setting and descriptive statistical results were shown in Table 1 .

Table 1 . Variable setting and descriptive statistics.
3.1 Farmers’ perceived benefits of PEATs
Each interviewed farmer was asked to evaluate the fertilizer reduction effects of three types of PEATs separately, and an evaluation option with five levels of agreement was designed. As shown in Figure 2 , farmers feel that the proportion of GM in reducing fertilizer application is not obvious (including “disagree” and “strongly disagree,” similarly hereinafter), general, and obvious (including “agree” and “strongly agree,” similarly hereinafter) is 34.60, 25.86, and 39.54%, respectively. Moreover, 34.43% of farmers believe that STFF has a poor effect on reducing chemical fertilizer application, 42.67% of farmers believe that the effect is good, and 22.90% of farmers still believe that the effect is general. Similarly, farmers believe that the proportion of SR in reducing fertilizer application is not obvious, general, and obvious is 35.25, 23.89, and 40.86%, respectively. Overall, about 40% of farmers believe that PEATs can significantly reduce fertilizer usage, while the proportion of those who consider the effect to be average and insignificant is about 25 and 35%, respectively.

Figure 2 . Farmers’ perception of the fertilizer reduction effect of PEATs.
3.2 Difference test of fertilizer application among rice farmers
According to the statistical results of fertilizer application of rice farmers, overall, the pure amount of chemical fertilizer applied by most rice farmers is 25 ~ 40 kg/mu, with a small number of farmers applying less than 25 kg/mu, while a large number of farmers applying more than 40 kg/mu, or even more than 60 kg/mu. Table 2 presents the statistical results of mean difference in chemical fertilizer application under different adoption scenarios. The chemica fertilizer application level of farmers who did not adopt PEATs was significantly higher than the sample average. According to the T -test results of independent samples, farmers who adopted different types or degrees of PEATs can reduce the application of nitrogen, phosphorus, and potassium fertilizers. However, the results in Table 2 do not infer that PEATs have an impact on fertilizer application. The influence of observable factors (such as the personal, family and land characteristics of farmers) and unobservable factors still needs to be further explored.

Table 2 . Farmers’ fertilizer application under different adoption scenarios.
3.3 The econometric results of ESR model
Tables 3 – 5 present the econometric regression results of the model. The 2–3 columns of each table provide the estimated results of the selection equation, while the 4–7 columns provide the result equations for the farmer groups who did not adopt or adopted PEATs. Specifically, both identified variables were significant in all three models, indicating that the identification effect of the variables is good. The estimation results of ρ μ a or ρ μ n are significant, which proves the existence of sample self selection problem ( Lokshin and Sajaia, 2004 ; Ma and Abdulai, 2016 ; Kuang et al., 2023 ). In other words, ignoring this issue may lead to biased estimation results.In other words, the problem needs to be addressed with the ESR model to obtain more plausible estimation results.

Table 3 . The estimation results of farmers’ response to GM.

Table 4 . The estimation results of farmers’ response to STFF.

Table 5 . The estimation results of farmers’ response to SR.
3.4 Quantitative analysis of farmers’ response to GM
Table 3 presents the estimated results of farmers adopting GM and its impact on chemical fertilizer application. The results show that gender, education level, government officials, cultivated land area, soil fertility, information access channels, and the distance from home to agricultural technology stations are the main influencing factors for farmers to adopt GM. Specifically, farmers with male, higher education, better soil fertility and more diverse information acquisition channels are more likely to adopt GM. Conversely, farmers with family members including government officials, large-scale planting and homes farther away from agricultural stations are less likely to adopt GM.
As shown in Table 3 , the impact of GM adoption by farmers on chemical fertilizer application was estimated. The estimated results of the cultivated land fragmentation variable indicate that farmers with a higher degree of farmland fragmentation use more chemical fertilizers. Similarly, this significant positive impact also occurs in the variables of education and the distance from home to farmland. Conversely, the negative effect of the cultivated land area variable on fertilizer application indicates that farmers with larger farm areas are more inclined to use more chemical fertilizer. Moreover, soil fertility has a positive driving effect on farmers to reduce the application of chemical fertilizer.
3.4.1 Quantitative analysis of farmers’ response to STFF
The influencing factors of farmers adopting STFF and its impact on fertilizer application are estimated in Table 4 . In the selection equation, the main influencing factors for farmers to adopt STFF include cultivated land area, information acquisition channels, and distance from home to agricultural technology stations. In other words, farmers with larger cultivated land area, more information access channels, and closer homes to agricultural technology stations are more likely to adopt STFF.
Table 4 also presents the estimation results of the result equations for different adoption groups of STFF. For all farmers (adopted or not adopted), the cultivated land fragmentation and soil fertility variables have significant positive and negative effects on fertilizer application, respectively. In other words, farmers with greater cultivated land fragmentation or poorer soil are more inclined to use more chemical fertilizer. In addition, for farmers who adopt STFF, men are more likely to apply more chemical fertilizer. For unadopted farmers, farmers with larger household populations or farther away from the cultivated land tend to apply more chemical fertilizer.
3.4.2 Quantitative analysis of farmers’ response to SR
Table 5 shows the estimated results of the farmers’ responses to SR. The results indicate that farmers adopting was mainly influenced by education, cultivated land area, family population, income, soil fertility, officials, the distance from home to land, information acquisition channels, and the distance from home to agricultural technology stations. Specifically, farmers with higher income, greater cultivated land area, more information access channels, and better soil fertility are more inclined to adopt SR. Conversely, farmers with high education, large family population, government officials in families, farther away from land, and farther away from agricultural technology stations have lower probability of adopting SR.
From Table 5 , we also found the results of farmers’ response to SR on fertilizer application. Soil fertility has a significant negative effect on chemical fertilizers application, indicating that farmers with more fertile land have a higher probability of using less chemical fertilizer. For unadopted farmers, the distance from home to cultivated land has a significant positive influence on chemical fertilizer application, suggesting that farmers who are farther away from farmland use more fertilizer. For adopted farmers, farmers with greater age and cultivated land fragmentation use more chemical fertilizer, while farmers with larger cultivation areas use less chemical fertilizer.
3.5 Estimating the behavioral effects of farmers adopting PEATs
The effect results of PEATs on chemical fertilizer application is presented in Table 6 . Overall, the adoption of PEATs will help farmers reduce chemical fertilizer use. Specifically, the estimation results indicate that if farmers who have adopted GM, STFF, and SR choose not to adopt the corresponding types of PEATs, the chemical fertilizer application will increase by 4.84, 2.14, and 7.20%, respectively. Furthermore, for farmers who have not actually adopted PGM, STFFT and SRT, if they adopt the corresponding types of PEATs in the future, the chemical fertilizer application will reduce by 3.16, 1.00 and 4.91%, respectively.

Table 6 . Average treatment effect of farmers’ behavior under different PAETs adoption scenarios.
Is the robustness of the results of PEATs having significant fertilizer reduction effects? This is a key issue that this study focuses on. In addition, since farmers may not only adopt one PEATs, this study will again explore the effect of adoption behavior on chemical fertilizer application from the “adoption degree” dimension. As shown in Table 6 , the three adoption degree of PEATs have been verified to have significant fertilizer reduction effects, indicating that farmers adopting one or more PEATs can achieve the effect of reduced chemical fertilizer application. Specifically, for farmers who have already adopted one, two, and three types of PEATs, if they do not adopt the corresponding degree of PEATs, the chemical fertilizer application will increase by 4.84, 4.42, and 0.60%, respectively. Correspondingly, for farmers who have not actually adopted one kind, two kinds, and three kinds, if they adopt the corresponding degree of PEATs in the future, their chemical fertilizer will increase by 3.16, 5.42 and 2.96%, respectively. Farmers who did not adopt one, two and three types of PEATs, if they decided to adopt the corresponding degree of PEATs, fertilizer use would increase by 3.16, 5.42 and 2.96%, respectively.
4 Discussion
The results indicate that adopting PEATs by farmers can effectively reduce the use of chemical fertilizers. Specifically, green manure can improve surface coverage, enhance the gas regulation function of the farmland system, reduce nutrient loss to the environment, and improve soil organic matter content, thereby achieving chemical fertilizer reduction ( Egodawatta et al., 2012 ; Hong et al., 2019 ; Chang et al., 2022 ). Based on the results of soil testing, STFF achieves precision fertilization, improves soil fertility, meets the needs of crops for various nutrients, and improves the utilization rate of fertilizers by crops, so as to realize the reduction of chemical fertilizer usage ( Jordan-Meille et al., 2012 ; Zebarth et al., 2012 ; Wu et al., 2022 ). SR can release rich nutrient elements from crop straw, maintain a balance of nutrients, increase soil organic matter, improve soil nutrient content, and enhance soil fertility, thereby reducing chemical fertilizer application ( Malhi et al., 2011 ; Islam et al., 2022 ; Liu et al., 2023 ). In addition, we also need to note that the perception level of farmers that PEATs can significantly reduce fertilizer use still needs to be improved. Descriptive statistical results indicate that a large proportion of farmers still believe that the reduction effect of PEATs on fertilizer is not significant, which is also the reason why Chinese farmers generally have low enthusiasm for adopting PEATs.
Our results suggest that different factors influence different PEATs. Due to the different application conditions of different PEATs, farmers have different preferences for technology ( Zhao and Zhou, 2021 ; Kotu et al., 2022 ; Pham et al., 2022 ), which is very normal and easy to understand. Nevertheless, we have found some similar results, which will help us reveal the regularity of farmers’ adoption of PEATs behavior decision-making. Specifically, farmers with easier access to information or closer to agricultural technical stations have a higher probability of adopting PEATs. Similar studies have pointed out that information asymmetry is an important reason why farmers are reluctant or afraid to adopt new agricultural technologies ( Aker et al., 2016 ; Ullah et al., 2020 ). Therefore, providing more farmers with timely agricultural information and technical guidance is an important task for the agricultural technology extension department, which will encourage farmers to actively adopt PEATs ( Shikuku, 2019 ; Campenhout et al., 2021 ; Li et al., 2021 ).
Generally speaking, expanding farm size drives farmers to achieve economies of scale, internalizes the cost of farmland construction, motivate farmers to improve soil fertility through increasing investment, and thus increase the adoption rate of PEATs ( Cao et al., 2020 ; Xie and Huang, 2021 ). Interestingly, The results show that expanding cultivated land area does not necessarily promote farmers to adopt PEATs, and even has an inhibitory effect. This finding is supported by Gong et al. (2016) , Abera et al. (2020) , and Kuang et al. (2023) , suggesting that expanding farmland scale cannot achieve economies of scale, but has negative scale effects, and does not promote farmers to adopt PEATs. The possible reason is that almost all large-scale farmers choose agricultural machinery to reduce the expensive labor input, while some PEATs (such as GM) are easy to damage agricultural machinery, resulting in incompatibility with agricultural mechanization ( Kuang et al., 2023 ). Furthermore, as the results of this study show, farmers’ perceived benefits of PEATs need to be improved, and some farmers do not recognize the effectiveness of the technology.
Finally, although this article reveals some important findings, it cannot be ignored that there are still some limitations. The estimated results of farmers adopting PEAT to reduce fertilizer use may be overestimated. Because farmers may adopt more than these three types of PEATs when planting rice. In other words, some farmers have also adopted other PEATs, which has an impact on chemical fertilizer application. Therefore, this article has done the following three tasks. Firstly, three commonly used PEATs by farmers were selected from the three production stages (before, middle and after) of planting rice. Secondly, examine the impact of PEATs on fertilizer reduction from the dimensions of “adoption or non adoption” and “degree of adoption.” Thirdly, this article explores the fertilizer reduction effects of farmers adopting PEATs from two perspectives: perception surveys and behavioral effect estimation. In general, how to scientifically and reasonably reveal the driving mechanism of farmers’ response to PEATs and demonstrate technology benefits are still the focus of follow-up research ( Kuang et al., 2023 ), which will be related to how to get through the last kilometer of farmers adopting PEATs.
5 Conclusions and policy suggestions
By highlighting the chemical fertilizer reduction effect of PEATs and identifying obstacle factors, we aim to incentivize farmers to adopt PEATs, thereby achieving green and sustainable agricultural development. Our perception survey results indicate that some farmers acknowledge that PEATs have good fertilizer reduction effects, while a large proportion of farmers still hold a skeptical attitude towards this. The estimated results indicate that the adoption of PEATs can significantly reduce the use of chemical fertilizer by farmers. Specifically, if farmers who actually adopt PEATs do not adopt them in the future, the chemical fertilizer application will increase; If farmers who have not actually adopted PEATs adopt them in the future, the chemical fertilizer application will be reduced. Furthmore, there are differences in the influencing factors of different types of PEATs. Overall, farmers’ adoption of PEATs is mainly influenced by factors such as education level, government officials, cultivated land area, soil fertility, information access channels and distance from home to agricultural machinery stations. Finally, the effect of PEATs on chemical fertilizer reduction was different among farmers’ endowments, which is mainly manifested as farmers with higher cultivated land fragmentation, more distant their homes from the cultivated land will choose to apply more chemical fertilizer, and farmers with better soil fertility apply less chemical fertilizer.
Therefore, the following three policy suggestions are proposed. Firstly, increase technical publicity and reduce the threshold for information acquisition. Cognition is the precursor of behavior, and solving the problem of information asymmetry is a key issue for agricultural technology promotion. Therefore, it is recommended to establish a PEATs promotion and publicity system led by the technology promotion department and participated by multiple entities. Secondly, promote the moderate scale management of cultivated land. It is suggested that government departments take the lead, taking villages as a unit, reduce the cultivated land fragmentation through land adjustment and land leveling, and encourage farmers to conduct moderate scale operations through land transfer. Thirdly, manifest the behavioral effects of PEATs. It is suggested to select a group of farmers or new agricultural business entities with high grain production efficiency under the leadership of the government, establish PEATs promotion and demonstration bases, organize farmers to visit and experience the benefits of PEATs, so as to encourage farmers to actively adopt PEATs.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: Data will be made available on request. Requests to access these datasets should be directed to [email protected] .
Author contributions
FK: Conceptualization, Funding acquisition, Investigation, Project administration, Writing – original draft, Writing – review & editing. JL: Software, Visualization, Writing – original draft, Writing – review & editing. JJ: Conceptualization, Funding acquisition, Project administration, Supervision, Writing – review & editing. CL: Conceptualization, Funding acquisition, Writing – review & editing. XQ: Investigation, Methodology, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by the National Natural Science Foundation of China Fund Project (grant number: 72304132; 42271203; 72064030).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. ^ According to the available information, China conducted the selection of national and provincial advanced counties in grain production every year since 2004, and 2014 was the last year.
Abdallah, A., Abdul-Rahaman, A., and Issahaku, G. (2021). Sustainable agricultural practices, farm income and food security among rural households in Africa. Environ. Dev. Sustain. 23, 17668–17701. doi: 10.1007/s10668-021-01407-y
Crossref Full Text | Google Scholar
Abera, W., Assen, M., and Budds, J. (2020). Determinants of agricultural land management practices among smallholder farmers in the Wanka watershed, northwestern highlands of Ethiopia. Land Use Policy 99:104841. doi: 10.1016/j.landusepol.2020.104841
Aker, J. C., Ghosh, I., and Burrell, J. (2016). The promise (and pitfalls) of ICT for agriculture initiatives. Agric. Econ. 47, 35–48. doi: 10.1111/agec.12301
Anik, A. R., Eory, V., Begho, T., and Rahman, M. M. (2023). Determinants of nitrogen use efficiency and gaseous emissions assessed from farm survey: a case of wheat in Bangladesh. Agric. Syst. 206:103617. doi: 10.1016/j.agsy.2023.103617
Baumgart-Getz, A., Prokopy, L. S., and Floress, K. (2012). Why farmers adopt best management practice in the United States: a meta-analysis of the adoption literature. J. Environ. Manag. 96, 17–25. doi: 10.1016/j.jenvman.2011.10.006
Bopp, C., Engler, A., Poortvliet, P. M., and Jara-Rojas, R. (2019). The role of farmers’ intrinsic motivation in the effectiveness of policy incentives to promote sustainable agriculturalpractices. J. Environ. Manag. 244, 320–327. doi: 10.1016/j.jenvman.2019.04.107
Brady, M. (2003). The relative cost-efficiency of arable nitrogen management in Sweden. Ecol. Econ. 47, 53–70. doi: 10.1016/j.ecolecon.2002.11.001
Burton, R. J. F. (2014). The influence of farmer demographic characteristics on environmental behaviour: a review. J. Environ. Manag. 135, 19–26. doi: 10.1016/j.jenvman.2013.12.005
Campenhout, B. V., Spielman, D. J., and Lecoutere, E. (2021). Information and communication technologies to provide agricultural advice to smallholder farmers: experimental evidence from Uganda. Am. J. Agric. Econ. 103, 317–337. doi: 10.1002/ajae.12089
Cao, H., Zhu, X., Heijman, W., and Zhao, K. (2020). The impact of land transfer and farmers’ knowledge of farmland protection policy on pro-environmental agricultural practices: the case of straw return to fields in Ningxia, China. J. Clean. Prod. 277:123701. doi: 10.1016/j.jclepro.2020.123701
Chang, S., Yi, X., Sauer, J., Yin, C., and Li, F. (2022). Explaining farmers’ reluctance to adopt green manure cover crops planting for sustainable agriculture in Northwest China. J. Integr. Agric. 21, 3382–3394. doi: 10.1016/j.jia.2022.09.005
Egodawatta, W. C. P., Sangakkara, U. R., and Stamp, P. (2012). Impact of green manure and mineral fertilizer inputs on soil organic matter and crop productivity in a sloping landscape of Sri Lanka. Field Crop Res. 129, 21–27. doi: 10.1016/j.fcr.2012.01.010
Erisman, J. W., Sutton, M. A., Galloway, J., Klimont, Z., and Winiwarter, W. (2008). How a century of ammonia synthesis changed the world. Nat. Geosci. 1, 636–639. doi: 10.1038/ngeo325
Gong, Y., Baylis, K., Kozak, R., and Bull, G. (2016). Farmers’ risk preferences and pesticide use decisions: evidence from field experiments in China. Agric. Econ. 47, 411–421. doi: 10.1111/agec.12240
Guo, J., Li, C., Xu, X., Sun, M., and Zhang, L. (2022). Farmland scale and chemical fertilizer use in rural China: new evidence from the perspective of nutrient elements. J. Clean. Prod. 376:134278. doi: 10.1016/j.jclepro.2022.134278
Hong, X., Ma, C., Gao, J., Su, S., Li, T., Luo, Z., et al. (2019). Effects of different green manure treatments on soil apparent N and P balance under a 34-year double-rice cropping system. J. Soils Sediments 19, 73–80. doi: 10.1007/s11368-018-2049-5
Hu, L., Zhang, X., and Zhou, Y. (2019). Farm size and fertilizer sustainable use: an empirical study in Jiangsu, China. J. Integr. Agric. 18, 2898–2909. doi: 10.1016/S2095-3119(19)62732-2
Huang, J., Yang, J., and Rozelle, S. (2010). China’s agriculture: drivers of change and implications for China and the rest of world. Agric. Econ. 41, 47–55. doi: 10.1111/j.1574-0862.2010.00487.x
Islam, M. U., Guo, Z., Jiang, F., and Peng, X. (2022). Does straw return increase crop yield in the wheat-maize cropping system in China? A meta-analysis. Field Crop Res. 279:108447. doi: 10.1016/j.fcr.2022.108447
Jin, S., and Zhou, F. (2018). Zero growth of chemical fertilizer and pesticide use: China’s objectives, progress and challenges. J. Resour. Ecol. 9, 50–58. doi: 10.5814/j.issn.1674-764x.2018.01.006
Jordan-Meille, L., Rubaek, G. H., Ehlert, P. A. I., Genot, V., Hofman, G., Goulding, K., et al. (2012). An overview of fertilizer-P recommendations in Europe: soil testing, calibration and fertilizer recommendations. Soil Use Manag. 28, 419–435. doi: 10.1111/j.1475-2743.2012.00453.x
Khanal, U., Wilson, C., Lee, B. L., and Hoang, V. (2018). Climate change adaptation strategies and food productivity in Nepal: a counterfactual analysis. Clim. Chang. 148, 575–590. doi: 10.1007/s10584-018-2214-2
Khonje, M. G., Manda, J., Mkandawire, P., Tufa, A. H., and Alene, A. D. (2018). Adoption and welfare impacts of multiple agricultural technologies: evidence from eastern Zambia. Agric. Econ. 49, 599–609. doi: 10.1111/agec.12445
Kotu, B. H., Oyinbo, O., Hoeschle-Zeledon, I., Nurudeen, A. R., Kizito, F., and Boyubie, B. (2022). Smallholder farmers’ preferences for sustainable intensification attributes in maize production: evidence from Ghana. World Dev. 152:105789. doi: 10.1016/j.worlddev.2021.105789
Kuang, F., Li, J., Jin, J., and Qiu, X. (2023). Do green production technologies improve household income? Evidence from rice farmers in China. Land 12:1848. doi: 10.3390/land12101848
Lai, Z., Chen, M., and Liu, T. (2020). Changes in and prospects for cultivated land use since the reform and opening up in China. Land Use Policy 97:104781. doi: 10.1016/j.landusepol.2020.104781
Li, Y., Fan, Z., Jiang, G., and Quan, Z. (2021). Addressing the differences in farmers’ willingness and behavior regarding developing green agriculture—a case study in XiChuan County, China. Land 10:316. doi: 10.3390/land10030316
Li, P., Feng, Z., Jiang, L., Liu, Y., and Xiao, X. (2012). Changes in rice cropping systems in the Poyang Lake region, China during 2004-2010. J. Geogr. Sci. 22, 653–668. doi: 10.1007/s11442-012-0954-x
Lin, Y., Hu, R., Zhang, C., and Chen, K. (2022). The role of public agricultural extension services in driving fertilizer use in rice production in China. Ecol. Econ. 200:107513. doi: 10.1016/j.ecolecon.2022.107513
Liu, J., Qiu, T., Pe Uelas, J., Sardans, J., Tan, W., Wei, X., et al. (2023). Crop residue return sustains global soil ecological stoichiometry balance. Glob. Chang. Biol. 29, 2203–2226. doi: 10.1111/gcb.16584
Liu, Y., Ruiz-Menjivar, J., Zhang, L., Zhang, J., and Swisher, M. E. (2019). Technical training and rice farmers’ adoption of low-carbon management practices: the case of soil testing and formulated fertilization technologies in Hubei, China. J. Clean. Prod. 226, 454–462. doi: 10.1016/j.jclepro.2019.04.026
Lokshin, M., and Sajaia, Z. (2004). Maximum likelihood estimation of endogenous switching regression models. Stata J. 4, 282–289. doi: 10.1177/1536867X0400400306
Lu, Y., Jenkins, A., Ferrier, R. C., Bailey, M., Gordon, I. J., Song, S., et al. (2015). Addressing China’s grand challenge of achieving food security while ensuring environmental sustainability. Sci. Adv. 1:e1400039. doi: 10.1126/sciadv.1400039
Ma, W., and Abdulai, A. (2016). Does cooperative membership improve household welfare? Evidence from apple farmers in China. Food Policy 58, 94–102. doi: 10.1016/j.foodpol.2015.12.002
Malhi, S. S., Nyborg, M., Solberg, E. D., Dyck, M. F., and Puurveen, D. (2011). Improving crop yield and N uptake with long-term straw retention in two contrasting soil types. Field Crop Res. 124, 378–391. doi: 10.1016/j.fcr.2011.07.009
National Bureau of Statistics of China (NBSC). (2023). Jiangxi statistical yearbook . China Statistics Press, Beijing.
Google Scholar
Pham, H., Chuah, S., and Feeny, S. (2022). Coffee farmer preferences for sustainable agricultural practices: findings from discrete choice experiments in Vietnam. J. Environ. Manag. 318:115627. doi: 10.1016/j.jenvman.2022.115627
Qing, C., Zhou, W., Song, J., Deng, X., and Xu, D. (2023). Impact of outsourced machinery services on farmers’ green production behavior: evidence from Chinese rice farmers. J. Environ. Manag. 327:116843. doi: 10.1016/j.jenvman.2022.116843
Rust, N. A., Jarvis, R. M., Reed, M. S., and Cooper, J. (2021). Framing of sustainable agricultural practices by the farming press and its effect on adoption. Agric. Hum. Values 38, 753–765. doi: 10.1007/s10460-020-10186-7
Schulte-Uebbing, L. F., Beusen, A. H. W., Bouwman, A. F., and de Vries, W. (2022). From planetary to regional boundaries for agricultural nitrogen pollution. Nature 610, 507–512. doi: 10.1038/s41586-022-05158-2
Shahzad, A. N., Qureshi, M. K., Wakeel, A., and Misselbrook, T. (2019). Crop production in Pakistan and low nitrogen use efficiencies. Nat. Sustain. 2, 1106–1114. doi: 10.1038/s41893-019-0429-5
Shikuku, K. M. (2019). Information exchange links, knowledge exposure, and adoption of agricultural technologies in northern Uganda. World Dev. 115, 94–106. doi: 10.1016/j.worlddev.2018.11.012
Trimpler, K., Stockfisch, N., and Märländer, B. (2016). The relevance of N fertilization for the amount of total greenhouse gas emissions in sugar beet cultivation. Eur. J. Agron. 81, 64–71. doi: 10.1016/j.eja.2016.08.013
Ullah, A., Arshad, M., Kächele, H., Zeb, A., Mahmood, N., and Müller, K. (2020). Socioeconomic analysis of farmers facing asymmetric information in inputs markets: evidence from the rainfed zone of Pakistan. Technol. Soc. 63:101405. doi: 10.1016/j.techsoc.2020.101405
Wang, Y., Zhu, Y., Zhang, S., and Wang, Y. (2018). What could promote farmers to replace chemical fertilizers with organic fertilizers? J. Clean. Prod. 199, 882–890. doi: 10.1016/j.jclepro.2018.07.222
Ward, P. S., Bell, A. R., Droppelmann, K., and Benton, T. G. (2018). Early adoption of conservation agriculture practices: understanding partial compliance in programs with multiple adoption decisions. Land Use Policy 70, 27–37. doi: 10.1016/j.landusepol.2017.10.001
Wossen, T., Alene, A., Abdoulaye, T., Feleke, S., and Manyong, V. (2019). Agricultural technology adoption and household welfare: measurement and evidence. Food Policy 87:101742. doi: 10.1016/j.foodpol.2019.101742
Wu, H., Li, J., and Ge, Y. (2022). Ambiguity preference, social learning and adoption of soil testing and formula fertilization technology. Technol. Forecast. Soc. Chang. 184:122037. doi: 10.1016/j.techfore.2022.122037
Xie, H., and Huang, Y. (2021). Influencing factors of farmers’ adoption of pro-environmental agricultural technologies in China: meta-analysis. Land Use Policy 109:105622. doi: 10.1016/j.landusepol.2021.105622
Zebarth, B. J., Snowdon, E., Burton, D. L., Goyer, C., and Dowbenko, R. (2012). Controlled release fertilizer product effects on potato crop response and nitrous oxide emissions under rain-fed production on a medium-textured soil. Can. J. Soil Sci. 92, 759–769. doi: 10.4141/cjss2012-008
Zhao, D., and Zhou, H. (2021). Livelihoods, technological constraints, and low-carbon agricultural technology preferences of farmers: analytical frameworks of technology adoption and farmer livelihoods. Int. J. Environ. Res. Public Health 18:13364. doi: 10.3390/ijerph182413364
Zhou, X., Niu, A., and Lin, C. (2023). Optimizing carbon emission forecast for modelling China’s 2030 provincial carbon emission quota allocation. J. Environ. Manag. 325:116523. doi: 10.1016/j.jenvman.2022.116523
Keywords: sustainable agriculture, PEATs, the fertilizer reduction effect, Chinese farmers, endogenous switching regression model
Citation: Kuang F, Li J, Jin J, Liu C and Qiu X (2024) How to manifest the fertilizer reduction effect of pro-environmental agricultural technologies? From the perspective of farmers’ perception and behavioral adoption. Front. Sustain. Food Syst . 8:1377040. doi: 10.3389/fsufs.2024.1377040
Received: 26 January 2024; Accepted: 08 April 2024; Published: 17 April 2024.
Reviewed by:
Copyright © 2024 Kuang, Li, Jin, Liu and Qiu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jianjun Jin, [email protected]
IMAGES
VIDEO
COMMENTS
Probability sampling methods. Probability sampling means that every member of the population has a chance of being selected. It is mainly used in quantitative research. If you want to produce results that are representative of the whole population, probability sampling techniques are the most valid choice.
Types of Sampling Techniques in Quantitative Research. There are two main types of sampling techniques are observed—probability and non-probability sampling (Malhotra & Das, 2010; Sekaran & Bougie, 2016 ). If the population is known and each element has an equal chance of being picked, then probability sampling applies.
3.4 Sampling Techniques in Quantitative Research Target Population. The target population includes the people the researcher is interested in conducting the research and generalizing the findings on. 40 For example, if certain researchers are interested in vaccine-preventable diseases in children five years and younger in Australia. The target population will be all children aged 0-5 years ...
We could choose a sampling method based on whether we want to account for sampling bias; a random sampling method is often preferred over a non-random method for this reason. Random sampling examples include: simple, systematic, stratified, and cluster sampling. Non-random sampling methods are liable to bias, and common examples include ...
Probability-based sampling methods are most commonly used in quantitative research, especially when it's important to achieve a representative sample that allows the researcher to generalise their findings. Non-probability sampling, on the other hand, refers to sampling methods in which the selection of participants is not statistically random.
Sampling types. There are two major categories of sampling methods ( figure 1 ): 1; probability sampling methods where all subjects in the target population have equal chances to be selected in the sample [ 1, 2] and 2; non-probability sampling methods where the sample population is selected in a non-systematic process that does not guarantee ...
Abstract. Knowledge of sampling methods is essential to design quality research. Critical questions are provided to help researchers choose a sampling method. This article reviews probability and non-probability sampling methods, lists and defines specific sampling techniques, and provides pros and cons for consideration.
The method by which the researcher selects the sample is the ' Sampling Method'. There are essentially two types of sampling methods: 1) probability sampling - based on chance events (such as random numbers, flipping a coin etc.); and 2) non-probability sampling - based on researcher's choice, population that accessible & available.
Probability Sampling. Unlike nonprobability sampling, probability sampling refers to sampling techniques for which a person's (or event's) likelihood of being selected for membership in the sample is known. You might ask yourself why we should care about a study element's likelihood of being selected for membership in a researcher's sample.
Types of Sampling Techniques in Quantitative Research. There are two main types of sampling techniques are observed—probability and non-probability sampling (Malhotra & Das, 2010; Sekaran & Bougie, 2016). If the population is known and each element has an equal chance of being picked, then probability sampling applies.
Sampling methods in psychology refer to strategies used to select a subset of individuals (a sample) from a larger population, to study and draw inferences about the entire population. Common methods include random sampling, stratified sampling, cluster sampling, and convenience sampling. Proper sampling ensures representative, generalizable, and valid research results.
This page titled 7.3: Sampling in Quantitative Research is shared under a CC BY-NC-SA 3.0 license and was authored, remixed, and/or curated by Anonymous via source content that was edited to the style and standards of the LibreTexts platform; a detailed edit history is available upon request.
Obtaining Samples for Population Generalizability. In quantitative research, a population is the entire group that the researcher wants to draw conclusions about.. A sample is the specific group that the researcher will actually collect data from. A sample is always a much smaller group of people than the total size of the population.
However, mixed methods studies also have unique considerations based on the relationship of quantitative and qualitative research within the study. Sampling in Qualitative Research Sampling in qualitative research may be divided into two major areas: overall sampling strategies and issues around sample size.
22. Chapter 8: Quantitative Sampling. I. Introduction to Sampling a. The primary goal of sampling is to get a representative sample, or a small collection of units or cases from a much larger collection or population, such that the researcher can study the smaller group and produce accurate generalizations about the larger group.
Cluster sampling- she puts 50 into random groups of 5 so we get 10 groups then randomly selects 5 of them and interviews everyone in those groups --> 25 people are asked. 2. Stratified sampling- she puts 50 into categories: high achieving smart kids, decently achieving kids, mediumly achieving kids, lower poorer achieving kids and clueless ...
The data collected is quantitative and statistical analyses are used to draw conclusions. Purpose of Sampling Methods. The main purpose of sampling methods in research is to obtain a representative sample of individuals or elements from a larger population of interest, in order to make inferences about the population as a whole. ...
10.3 Sampling in quantitative research. Learning Objectives. Describe how probability sampling differs from nonprobability sampling. Define generalizability, and describe how it is achieved in probability samples. Identify the various types of probability samples, and describe why a researcher may use one type over another.
Matching recruitment and sampling approach. Recruitment must match the sampling approach you choose in section 10.2. For many students, that will mean using recruitment techniques most relevant to availability sampling. These may include public postings such as flyers, mass emails, or social media posts.
Such samples can be best acquired through probability sampling, a procedure in which all members of the target population have a known and random chance of being selected. However, probability sampling techniques are uncommon in modern quantitative research because of practical constraints; non-probability sampling, such as by convenience, is ...
Revised on June 22, 2023. Quantitative research is the process of collecting and analyzing numerical data. It can be used to find patterns and averages, make predictions, test causal relationships, and generalize results to wider populations. Quantitative research is the opposite of qualitative research, which involves collecting and analyzing ...
Availability sampling is appropriate for student and smaller-scale projects, but it comes with significant limitations. The purpose of sampling in quantitative research is to generalize from a small sample to a larger population. Because availability sampling does not use a random process to select participants, the researcher cannot be sure ...
The quantitative research sampling method is the process of selecting representable units from a large population. Quantitative research refers to the analysis wherein mathematical, statistical, or computational method is used for studying the measurable or quantifiable dataset. The core purpose of quantitative research is the generalization of ...
The choice of sampling design plays a critical role in the credibility and generalizability of the research. Probability Sampling: Types: Includes simple random, stratified, systematic, ... Quantitative Research: Opt for quantitative methods when the goal is to quantify data and generalize results from a sample to a larger population. This ...
The sampling procedure was carried out in accordance with the four stages shown in ... 3.4 Quantitative analysis of farmers' response to GM. ... authorship, and/or publication of this article. This research was supported by the National Natural Science Foundation of China Fund Project (grant number: 72304132; 42271203; 72064030). Conflict of ...