Choose Your Test
Sat / act prep online guides and tips, 113 great research paper topics.
General Education

One of the hardest parts of writing a research paper can be just finding a good topic to write about. Fortunately we've done the hard work for you and have compiled a list of 113 interesting research paper topics. They've been organized into ten categories and cover a wide range of subjects so you can easily find the best topic for you.
In addition to the list of good research topics, we've included advice on what makes a good research paper topic and how you can use your topic to start writing a great paper.

What Makes a Good Research Paper Topic?
Not all research paper topics are created equal, and you want to make sure you choose a great topic before you start writing. Below are the three most important factors to consider to make sure you choose the best research paper topics.
#1: It's Something You're Interested In
A paper is always easier to write if you're interested in the topic, and you'll be more motivated to do in-depth research and write a paper that really covers the entire subject. Even if a certain research paper topic is getting a lot of buzz right now or other people seem interested in writing about it, don't feel tempted to make it your topic unless you genuinely have some sort of interest in it as well.
#2: There's Enough Information to Write a Paper
Even if you come up with the absolute best research paper topic and you're so excited to write about it, you won't be able to produce a good paper if there isn't enough research about the topic. This can happen for very specific or specialized topics, as well as topics that are too new to have enough research done on them at the moment. Easy research paper topics will always be topics with enough information to write a full-length paper.
Trying to write a research paper on a topic that doesn't have much research on it is incredibly hard, so before you decide on a topic, do a bit of preliminary searching and make sure you'll have all the information you need to write your paper.
#3: It Fits Your Teacher's Guidelines
Don't get so carried away looking at lists of research paper topics that you forget any requirements or restrictions your teacher may have put on research topic ideas. If you're writing a research paper on a health-related topic, deciding to write about the impact of rap on the music scene probably won't be allowed, but there may be some sort of leeway. For example, if you're really interested in current events but your teacher wants you to write a research paper on a history topic, you may be able to choose a topic that fits both categories, like exploring the relationship between the US and North Korea. No matter what, always get your research paper topic approved by your teacher first before you begin writing.
113 Good Research Paper Topics
Below are 113 good research topics to help you get you started on your paper. We've organized them into ten categories to make it easier to find the type of research paper topics you're looking for.
Arts/Culture
- Discuss the main differences in art from the Italian Renaissance and the Northern Renaissance .
- Analyze the impact a famous artist had on the world.
- How is sexism portrayed in different types of media (music, film, video games, etc.)? Has the amount/type of sexism changed over the years?
- How has the music of slaves brought over from Africa shaped modern American music?
- How has rap music evolved in the past decade?
- How has the portrayal of minorities in the media changed?

Current Events
- What have been the impacts of China's one child policy?
- How have the goals of feminists changed over the decades?
- How has the Trump presidency changed international relations?
- Analyze the history of the relationship between the United States and North Korea.
- What factors contributed to the current decline in the rate of unemployment?
- What have been the impacts of states which have increased their minimum wage?
- How do US immigration laws compare to immigration laws of other countries?
- How have the US's immigration laws changed in the past few years/decades?
- How has the Black Lives Matter movement affected discussions and view about racism in the US?
- What impact has the Affordable Care Act had on healthcare in the US?
- What factors contributed to the UK deciding to leave the EU (Brexit)?
- What factors contributed to China becoming an economic power?
- Discuss the history of Bitcoin or other cryptocurrencies (some of which tokenize the S&P 500 Index on the blockchain) .
- Do students in schools that eliminate grades do better in college and their careers?
- Do students from wealthier backgrounds score higher on standardized tests?
- Do students who receive free meals at school get higher grades compared to when they weren't receiving a free meal?
- Do students who attend charter schools score higher on standardized tests than students in public schools?
- Do students learn better in same-sex classrooms?
- How does giving each student access to an iPad or laptop affect their studies?
- What are the benefits and drawbacks of the Montessori Method ?
- Do children who attend preschool do better in school later on?
- What was the impact of the No Child Left Behind act?
- How does the US education system compare to education systems in other countries?
- What impact does mandatory physical education classes have on students' health?
- Which methods are most effective at reducing bullying in schools?
- Do homeschoolers who attend college do as well as students who attended traditional schools?
- Does offering tenure increase or decrease quality of teaching?
- How does college debt affect future life choices of students?
- Should graduate students be able to form unions?

- What are different ways to lower gun-related deaths in the US?
- How and why have divorce rates changed over time?
- Is affirmative action still necessary in education and/or the workplace?
- Should physician-assisted suicide be legal?
- How has stem cell research impacted the medical field?
- How can human trafficking be reduced in the United States/world?
- Should people be able to donate organs in exchange for money?
- Which types of juvenile punishment have proven most effective at preventing future crimes?
- Has the increase in US airport security made passengers safer?
- Analyze the immigration policies of certain countries and how they are similar and different from one another.
- Several states have legalized recreational marijuana. What positive and negative impacts have they experienced as a result?
- Do tariffs increase the number of domestic jobs?
- Which prison reforms have proven most effective?
- Should governments be able to censor certain information on the internet?
- Which methods/programs have been most effective at reducing teen pregnancy?
- What are the benefits and drawbacks of the Keto diet?
- How effective are different exercise regimes for losing weight and maintaining weight loss?
- How do the healthcare plans of various countries differ from each other?
- What are the most effective ways to treat depression ?
- What are the pros and cons of genetically modified foods?
- Which methods are most effective for improving memory?
- What can be done to lower healthcare costs in the US?
- What factors contributed to the current opioid crisis?
- Analyze the history and impact of the HIV/AIDS epidemic .
- Are low-carbohydrate or low-fat diets more effective for weight loss?
- How much exercise should the average adult be getting each week?
- Which methods are most effective to get parents to vaccinate their children?
- What are the pros and cons of clean needle programs?
- How does stress affect the body?
- Discuss the history of the conflict between Israel and the Palestinians.
- What were the causes and effects of the Salem Witch Trials?
- Who was responsible for the Iran-Contra situation?
- How has New Orleans and the government's response to natural disasters changed since Hurricane Katrina?
- What events led to the fall of the Roman Empire?
- What were the impacts of British rule in India ?
- Was the atomic bombing of Hiroshima and Nagasaki necessary?
- What were the successes and failures of the women's suffrage movement in the United States?
- What were the causes of the Civil War?
- How did Abraham Lincoln's assassination impact the country and reconstruction after the Civil War?
- Which factors contributed to the colonies winning the American Revolution?
- What caused Hitler's rise to power?
- Discuss how a specific invention impacted history.
- What led to Cleopatra's fall as ruler of Egypt?
- How has Japan changed and evolved over the centuries?
- What were the causes of the Rwandan genocide ?

- Why did Martin Luther decide to split with the Catholic Church?
- Analyze the history and impact of a well-known cult (Jonestown, Manson family, etc.)
- How did the sexual abuse scandal impact how people view the Catholic Church?
- How has the Catholic church's power changed over the past decades/centuries?
- What are the causes behind the rise in atheism/ agnosticism in the United States?
- What were the influences in Siddhartha's life resulted in him becoming the Buddha?
- How has media portrayal of Islam/Muslims changed since September 11th?
Science/Environment
- How has the earth's climate changed in the past few decades?
- How has the use and elimination of DDT affected bird populations in the US?
- Analyze how the number and severity of natural disasters have increased in the past few decades.
- Analyze deforestation rates in a certain area or globally over a period of time.
- How have past oil spills changed regulations and cleanup methods?
- How has the Flint water crisis changed water regulation safety?
- What are the pros and cons of fracking?
- What impact has the Paris Climate Agreement had so far?
- What have NASA's biggest successes and failures been?
- How can we improve access to clean water around the world?
- Does ecotourism actually have a positive impact on the environment?
- Should the US rely on nuclear energy more?
- What can be done to save amphibian species currently at risk of extinction?
- What impact has climate change had on coral reefs?
- How are black holes created?
- Are teens who spend more time on social media more likely to suffer anxiety and/or depression?
- How will the loss of net neutrality affect internet users?
- Analyze the history and progress of self-driving vehicles.
- How has the use of drones changed surveillance and warfare methods?
- Has social media made people more or less connected?
- What progress has currently been made with artificial intelligence ?
- Do smartphones increase or decrease workplace productivity?
- What are the most effective ways to use technology in the classroom?
- How is Google search affecting our intelligence?
- When is the best age for a child to begin owning a smartphone?
- Has frequent texting reduced teen literacy rates?

How to Write a Great Research Paper
Even great research paper topics won't give you a great research paper if you don't hone your topic before and during the writing process. Follow these three tips to turn good research paper topics into great papers.
#1: Figure Out Your Thesis Early
Before you start writing a single word of your paper, you first need to know what your thesis will be. Your thesis is a statement that explains what you intend to prove/show in your paper. Every sentence in your research paper will relate back to your thesis, so you don't want to start writing without it!
As some examples, if you're writing a research paper on if students learn better in same-sex classrooms, your thesis might be "Research has shown that elementary-age students in same-sex classrooms score higher on standardized tests and report feeling more comfortable in the classroom."
If you're writing a paper on the causes of the Civil War, your thesis might be "While the dispute between the North and South over slavery is the most well-known cause of the Civil War, other key causes include differences in the economies of the North and South, states' rights, and territorial expansion."
#2: Back Every Statement Up With Research
Remember, this is a research paper you're writing, so you'll need to use lots of research to make your points. Every statement you give must be backed up with research, properly cited the way your teacher requested. You're allowed to include opinions of your own, but they must also be supported by the research you give.
#3: Do Your Research Before You Begin Writing
You don't want to start writing your research paper and then learn that there isn't enough research to back up the points you're making, or, even worse, that the research contradicts the points you're trying to make!
Get most of your research on your good research topics done before you begin writing. Then use the research you've collected to create a rough outline of what your paper will cover and the key points you're going to make. This will help keep your paper clear and organized, and it'll ensure you have enough research to produce a strong paper.
What's Next?
Are you also learning about dynamic equilibrium in your science class? We break this sometimes tricky concept down so it's easy to understand in our complete guide to dynamic equilibrium .
Thinking about becoming a nurse practitioner? Nurse practitioners have one of the fastest growing careers in the country, and we have all the information you need to know about what to expect from nurse practitioner school .
Want to know the fastest and easiest ways to convert between Fahrenheit and Celsius? We've got you covered! Check out our guide to the best ways to convert Celsius to Fahrenheit (or vice versa).
These recommendations are based solely on our knowledge and experience. If you purchase an item through one of our links, PrepScholar may receive a commission.

Christine graduated from Michigan State University with degrees in Environmental Biology and Geography and received her Master's from Duke University. In high school she scored in the 99th percentile on the SAT and was named a National Merit Finalist. She has taught English and biology in several countries.
Student and Parent Forum
Our new student and parent forum, at ExpertHub.PrepScholar.com , allow you to interact with your peers and the PrepScholar staff. See how other students and parents are navigating high school, college, and the college admissions process. Ask questions; get answers.

Ask a Question Below
Have any questions about this article or other topics? Ask below and we'll reply!
Improve With Our Famous Guides
- For All Students
The 5 Strategies You Must Be Using to Improve 160+ SAT Points
How to Get a Perfect 1600, by a Perfect Scorer
Series: How to Get 800 on Each SAT Section:
Score 800 on SAT Math
Score 800 on SAT Reading
Score 800 on SAT Writing
Series: How to Get to 600 on Each SAT Section:
Score 600 on SAT Math
Score 600 on SAT Reading
Score 600 on SAT Writing
Free Complete Official SAT Practice Tests
What SAT Target Score Should You Be Aiming For?
15 Strategies to Improve Your SAT Essay
The 5 Strategies You Must Be Using to Improve 4+ ACT Points
How to Get a Perfect 36 ACT, by a Perfect Scorer
Series: How to Get 36 on Each ACT Section:
36 on ACT English
36 on ACT Math
36 on ACT Reading
36 on ACT Science
Series: How to Get to 24 on Each ACT Section:
24 on ACT English
24 on ACT Math
24 on ACT Reading
24 on ACT Science
What ACT target score should you be aiming for?
ACT Vocabulary You Must Know
ACT Writing: 15 Tips to Raise Your Essay Score
How to Get Into Harvard and the Ivy League
How to Get a Perfect 4.0 GPA
How to Write an Amazing College Essay
What Exactly Are Colleges Looking For?
Is the ACT easier than the SAT? A Comprehensive Guide
Should you retake your SAT or ACT?
When should you take the SAT or ACT?
Stay Informed
Get the latest articles and test prep tips!
Looking for Graduate School Test Prep?
Check out our top-rated graduate blogs here:
GRE Online Prep Blog
GMAT Online Prep Blog
TOEFL Online Prep Blog
Holly R. "I am absolutely overjoyed and cannot thank you enough for helping me!”
- Search Menu
- Computer Science
- Earth Sciences
- Information Science
- Life Sciences
- Materials Science
- Science Policy
- Advance Access
- Special Topics
- Author Guidelines
- Submission Site
- Open Access Options
- Self-Archiving Policy
- About National Science Review
- Editorial Board
- Advertising and Corporate Services
- Journals Career Network
- Dispatch Dates
- Journals on Oxford Academic
- Books on Oxford Academic
2021 Best Paper Awards
On the origin and continuing evolution of sars-cov-2.

The SARS-CoV-2 epidemic started in late December 2019 in Wuhan, China, and has since impacted a large portion of China and raised major global concern. Herein, we investigated the extent of molecular divergence between SARS-CoV-2 and other related coronaviruses. Although we found only 4% variability in genomic nucleotides between SARS-CoV-2 and a bat SARS-related coronavirus (SARSr-CoV; RaTG13)...
Pathogenic T-cells and inflammatory monocytes incite inflammatory storms in severe COVID-19 patients

Organic photovoltaic cell with 17% efficiency and superior processability

A highly alkaline-stable metal oxide@metal–organic framework composite for high-performance electrochemical energy storage

High-Chern-number and high-temperature quantum Hall effect without Landau levels

Elevated plasma levels of selective cytokines in COVID-19 patients reflect viral load and lung injury

Contrasting trends of PM2.5 and surface-ozone concentrations in China from 2013 to 2017

Electrochemical synthesis of nitric acid from air and ammonia through waste utilization

The revival of thermal utilization from the Sun: interfacial solar vapor generation

Deep forest

- Recommend to Your Librarian
Affiliations
- Online ISSN 2053-714X
- Print ISSN 2095-5138
- Copyright © 2024 China Science Publishing & Media Ltd. (Science Press)
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
- Privacy Policy
Buy Me a Coffee
Home » Research Paper – Structure, Examples and Writing Guide
Research Paper – Structure, Examples and Writing Guide
Table of Contents

Research Paper
Definition:
Research Paper is a written document that presents the author’s original research, analysis, and interpretation of a specific topic or issue.
It is typically based on Empirical Evidence, and may involve qualitative or quantitative research methods, or a combination of both. The purpose of a research paper is to contribute new knowledge or insights to a particular field of study, and to demonstrate the author’s understanding of the existing literature and theories related to the topic.
Structure of Research Paper
The structure of a research paper typically follows a standard format, consisting of several sections that convey specific information about the research study. The following is a detailed explanation of the structure of a research paper:
The title page contains the title of the paper, the name(s) of the author(s), and the affiliation(s) of the author(s). It also includes the date of submission and possibly, the name of the journal or conference where the paper is to be published.
The abstract is a brief summary of the research paper, typically ranging from 100 to 250 words. It should include the research question, the methods used, the key findings, and the implications of the results. The abstract should be written in a concise and clear manner to allow readers to quickly grasp the essence of the research.
Introduction
The introduction section of a research paper provides background information about the research problem, the research question, and the research objectives. It also outlines the significance of the research, the research gap that it aims to fill, and the approach taken to address the research question. Finally, the introduction section ends with a clear statement of the research hypothesis or research question.
Literature Review
The literature review section of a research paper provides an overview of the existing literature on the topic of study. It includes a critical analysis and synthesis of the literature, highlighting the key concepts, themes, and debates. The literature review should also demonstrate the research gap and how the current study seeks to address it.
The methods section of a research paper describes the research design, the sample selection, the data collection and analysis procedures, and the statistical methods used to analyze the data. This section should provide sufficient detail for other researchers to replicate the study.
The results section presents the findings of the research, using tables, graphs, and figures to illustrate the data. The findings should be presented in a clear and concise manner, with reference to the research question and hypothesis.
The discussion section of a research paper interprets the findings and discusses their implications for the research question, the literature review, and the field of study. It should also address the limitations of the study and suggest future research directions.
The conclusion section summarizes the main findings of the study, restates the research question and hypothesis, and provides a final reflection on the significance of the research.
The references section provides a list of all the sources cited in the paper, following a specific citation style such as APA, MLA or Chicago.
How to Write Research Paper
You can write Research Paper by the following guide:
- Choose a Topic: The first step is to select a topic that interests you and is relevant to your field of study. Brainstorm ideas and narrow down to a research question that is specific and researchable.
- Conduct a Literature Review: The literature review helps you identify the gap in the existing research and provides a basis for your research question. It also helps you to develop a theoretical framework and research hypothesis.
- Develop a Thesis Statement : The thesis statement is the main argument of your research paper. It should be clear, concise and specific to your research question.
- Plan your Research: Develop a research plan that outlines the methods, data sources, and data analysis procedures. This will help you to collect and analyze data effectively.
- Collect and Analyze Data: Collect data using various methods such as surveys, interviews, observations, or experiments. Analyze data using statistical tools or other qualitative methods.
- Organize your Paper : Organize your paper into sections such as Introduction, Literature Review, Methods, Results, Discussion, and Conclusion. Ensure that each section is coherent and follows a logical flow.
- Write your Paper : Start by writing the introduction, followed by the literature review, methods, results, discussion, and conclusion. Ensure that your writing is clear, concise, and follows the required formatting and citation styles.
- Edit and Proofread your Paper: Review your paper for grammar and spelling errors, and ensure that it is well-structured and easy to read. Ask someone else to review your paper to get feedback and suggestions for improvement.
- Cite your Sources: Ensure that you properly cite all sources used in your research paper. This is essential for giving credit to the original authors and avoiding plagiarism.
Research Paper Example
Note : The below example research paper is for illustrative purposes only and is not an actual research paper. Actual research papers may have different structures, contents, and formats depending on the field of study, research question, data collection and analysis methods, and other factors. Students should always consult with their professors or supervisors for specific guidelines and expectations for their research papers.
Research Paper Example sample for Students:
Title: The Impact of Social Media on Mental Health among Young Adults
Abstract: This study aims to investigate the impact of social media use on the mental health of young adults. A literature review was conducted to examine the existing research on the topic. A survey was then administered to 200 university students to collect data on their social media use, mental health status, and perceived impact of social media on their mental health. The results showed that social media use is positively associated with depression, anxiety, and stress. The study also found that social comparison, cyberbullying, and FOMO (Fear of Missing Out) are significant predictors of mental health problems among young adults.
Introduction: Social media has become an integral part of modern life, particularly among young adults. While social media has many benefits, including increased communication and social connectivity, it has also been associated with negative outcomes, such as addiction, cyberbullying, and mental health problems. This study aims to investigate the impact of social media use on the mental health of young adults.
Literature Review: The literature review highlights the existing research on the impact of social media use on mental health. The review shows that social media use is associated with depression, anxiety, stress, and other mental health problems. The review also identifies the factors that contribute to the negative impact of social media, including social comparison, cyberbullying, and FOMO.
Methods : A survey was administered to 200 university students to collect data on their social media use, mental health status, and perceived impact of social media on their mental health. The survey included questions on social media use, mental health status (measured using the DASS-21), and perceived impact of social media on their mental health. Data were analyzed using descriptive statistics and regression analysis.
Results : The results showed that social media use is positively associated with depression, anxiety, and stress. The study also found that social comparison, cyberbullying, and FOMO are significant predictors of mental health problems among young adults.
Discussion : The study’s findings suggest that social media use has a negative impact on the mental health of young adults. The study highlights the need for interventions that address the factors contributing to the negative impact of social media, such as social comparison, cyberbullying, and FOMO.
Conclusion : In conclusion, social media use has a significant impact on the mental health of young adults. The study’s findings underscore the need for interventions that promote healthy social media use and address the negative outcomes associated with social media use. Future research can explore the effectiveness of interventions aimed at reducing the negative impact of social media on mental health. Additionally, longitudinal studies can investigate the long-term effects of social media use on mental health.
Limitations : The study has some limitations, including the use of self-report measures and a cross-sectional design. The use of self-report measures may result in biased responses, and a cross-sectional design limits the ability to establish causality.
Implications: The study’s findings have implications for mental health professionals, educators, and policymakers. Mental health professionals can use the findings to develop interventions that address the negative impact of social media use on mental health. Educators can incorporate social media literacy into their curriculum to promote healthy social media use among young adults. Policymakers can use the findings to develop policies that protect young adults from the negative outcomes associated with social media use.
References :
- Twenge, J. M., & Campbell, W. K. (2019). Associations between screen time and lower psychological well-being among children and adolescents: Evidence from a population-based study. Preventive medicine reports, 15, 100918.
- Primack, B. A., Shensa, A., Escobar-Viera, C. G., Barrett, E. L., Sidani, J. E., Colditz, J. B., … & James, A. E. (2017). Use of multiple social media platforms and symptoms of depression and anxiety: A nationally-representative study among US young adults. Computers in Human Behavior, 69, 1-9.
- Van der Meer, T. G., & Verhoeven, J. W. (2017). Social media and its impact on academic performance of students. Journal of Information Technology Education: Research, 16, 383-398.
Appendix : The survey used in this study is provided below.
Social Media and Mental Health Survey
- How often do you use social media per day?
- Less than 30 minutes
- 30 minutes to 1 hour
- 1 to 2 hours
- 2 to 4 hours
- More than 4 hours
- Which social media platforms do you use?
- Others (Please specify)
- How often do you experience the following on social media?
- Social comparison (comparing yourself to others)
- Cyberbullying
- Fear of Missing Out (FOMO)
- Have you ever experienced any of the following mental health problems in the past month?
- Do you think social media use has a positive or negative impact on your mental health?
- Very positive
- Somewhat positive
- Somewhat negative
- Very negative
- In your opinion, which factors contribute to the negative impact of social media on mental health?
- Social comparison
- In your opinion, what interventions could be effective in reducing the negative impact of social media on mental health?
- Education on healthy social media use
- Counseling for mental health problems caused by social media
- Social media detox programs
- Regulation of social media use
Thank you for your participation!
Applications of Research Paper
Research papers have several applications in various fields, including:
- Advancing knowledge: Research papers contribute to the advancement of knowledge by generating new insights, theories, and findings that can inform future research and practice. They help to answer important questions, clarify existing knowledge, and identify areas that require further investigation.
- Informing policy: Research papers can inform policy decisions by providing evidence-based recommendations for policymakers. They can help to identify gaps in current policies, evaluate the effectiveness of interventions, and inform the development of new policies and regulations.
- Improving practice: Research papers can improve practice by providing evidence-based guidance for professionals in various fields, including medicine, education, business, and psychology. They can inform the development of best practices, guidelines, and standards of care that can improve outcomes for individuals and organizations.
- Educating students : Research papers are often used as teaching tools in universities and colleges to educate students about research methods, data analysis, and academic writing. They help students to develop critical thinking skills, research skills, and communication skills that are essential for success in many careers.
- Fostering collaboration: Research papers can foster collaboration among researchers, practitioners, and policymakers by providing a platform for sharing knowledge and ideas. They can facilitate interdisciplinary collaborations and partnerships that can lead to innovative solutions to complex problems.
When to Write Research Paper
Research papers are typically written when a person has completed a research project or when they have conducted a study and have obtained data or findings that they want to share with the academic or professional community. Research papers are usually written in academic settings, such as universities, but they can also be written in professional settings, such as research organizations, government agencies, or private companies.
Here are some common situations where a person might need to write a research paper:
- For academic purposes: Students in universities and colleges are often required to write research papers as part of their coursework, particularly in the social sciences, natural sciences, and humanities. Writing research papers helps students to develop research skills, critical thinking skills, and academic writing skills.
- For publication: Researchers often write research papers to publish their findings in academic journals or to present their work at academic conferences. Publishing research papers is an important way to disseminate research findings to the academic community and to establish oneself as an expert in a particular field.
- To inform policy or practice : Researchers may write research papers to inform policy decisions or to improve practice in various fields. Research findings can be used to inform the development of policies, guidelines, and best practices that can improve outcomes for individuals and organizations.
- To share new insights or ideas: Researchers may write research papers to share new insights or ideas with the academic or professional community. They may present new theories, propose new research methods, or challenge existing paradigms in their field.
Purpose of Research Paper
The purpose of a research paper is to present the results of a study or investigation in a clear, concise, and structured manner. Research papers are written to communicate new knowledge, ideas, or findings to a specific audience, such as researchers, scholars, practitioners, or policymakers. The primary purposes of a research paper are:
- To contribute to the body of knowledge : Research papers aim to add new knowledge or insights to a particular field or discipline. They do this by reporting the results of empirical studies, reviewing and synthesizing existing literature, proposing new theories, or providing new perspectives on a topic.
- To inform or persuade: Research papers are written to inform or persuade the reader about a particular issue, topic, or phenomenon. They present evidence and arguments to support their claims and seek to persuade the reader of the validity of their findings or recommendations.
- To advance the field: Research papers seek to advance the field or discipline by identifying gaps in knowledge, proposing new research questions or approaches, or challenging existing assumptions or paradigms. They aim to contribute to ongoing debates and discussions within a field and to stimulate further research and inquiry.
- To demonstrate research skills: Research papers demonstrate the author’s research skills, including their ability to design and conduct a study, collect and analyze data, and interpret and communicate findings. They also demonstrate the author’s ability to critically evaluate existing literature, synthesize information from multiple sources, and write in a clear and structured manner.
Characteristics of Research Paper
Research papers have several characteristics that distinguish them from other forms of academic or professional writing. Here are some common characteristics of research papers:
- Evidence-based: Research papers are based on empirical evidence, which is collected through rigorous research methods such as experiments, surveys, observations, or interviews. They rely on objective data and facts to support their claims and conclusions.
- Structured and organized: Research papers have a clear and logical structure, with sections such as introduction, literature review, methods, results, discussion, and conclusion. They are organized in a way that helps the reader to follow the argument and understand the findings.
- Formal and objective: Research papers are written in a formal and objective tone, with an emphasis on clarity, precision, and accuracy. They avoid subjective language or personal opinions and instead rely on objective data and analysis to support their arguments.
- Citations and references: Research papers include citations and references to acknowledge the sources of information and ideas used in the paper. They use a specific citation style, such as APA, MLA, or Chicago, to ensure consistency and accuracy.
- Peer-reviewed: Research papers are often peer-reviewed, which means they are evaluated by other experts in the field before they are published. Peer-review ensures that the research is of high quality, meets ethical standards, and contributes to the advancement of knowledge in the field.
- Objective and unbiased: Research papers strive to be objective and unbiased in their presentation of the findings. They avoid personal biases or preconceptions and instead rely on the data and analysis to draw conclusions.
Advantages of Research Paper
Research papers have many advantages, both for the individual researcher and for the broader academic and professional community. Here are some advantages of research papers:
- Contribution to knowledge: Research papers contribute to the body of knowledge in a particular field or discipline. They add new information, insights, and perspectives to existing literature and help advance the understanding of a particular phenomenon or issue.
- Opportunity for intellectual growth: Research papers provide an opportunity for intellectual growth for the researcher. They require critical thinking, problem-solving, and creativity, which can help develop the researcher’s skills and knowledge.
- Career advancement: Research papers can help advance the researcher’s career by demonstrating their expertise and contributions to the field. They can also lead to new research opportunities, collaborations, and funding.
- Academic recognition: Research papers can lead to academic recognition in the form of awards, grants, or invitations to speak at conferences or events. They can also contribute to the researcher’s reputation and standing in the field.
- Impact on policy and practice: Research papers can have a significant impact on policy and practice. They can inform policy decisions, guide practice, and lead to changes in laws, regulations, or procedures.
- Advancement of society: Research papers can contribute to the advancement of society by addressing important issues, identifying solutions to problems, and promoting social justice and equality.
Limitations of Research Paper
Research papers also have some limitations that should be considered when interpreting their findings or implications. Here are some common limitations of research papers:
- Limited generalizability: Research findings may not be generalizable to other populations, settings, or contexts. Studies often use specific samples or conditions that may not reflect the broader population or real-world situations.
- Potential for bias : Research papers may be biased due to factors such as sample selection, measurement errors, or researcher biases. It is important to evaluate the quality of the research design and methods used to ensure that the findings are valid and reliable.
- Ethical concerns: Research papers may raise ethical concerns, such as the use of vulnerable populations or invasive procedures. Researchers must adhere to ethical guidelines and obtain informed consent from participants to ensure that the research is conducted in a responsible and respectful manner.
- Limitations of methodology: Research papers may be limited by the methodology used to collect and analyze data. For example, certain research methods may not capture the complexity or nuance of a particular phenomenon, or may not be appropriate for certain research questions.
- Publication bias: Research papers may be subject to publication bias, where positive or significant findings are more likely to be published than negative or non-significant findings. This can skew the overall findings of a particular area of research.
- Time and resource constraints: Research papers may be limited by time and resource constraints, which can affect the quality and scope of the research. Researchers may not have access to certain data or resources, or may be unable to conduct long-term studies due to practical limitations.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples
How to Write and Publish a Research Paper for a Peer-Reviewed Journal
- Open access
- Published: 30 April 2020
- Volume 36 , pages 909–913, ( 2021 )
Cite this article
You have full access to this open access article
- Clara Busse ORCID: orcid.org/0000-0002-0178-1000 1 &
- Ella August ORCID: orcid.org/0000-0001-5151-1036 1 , 2
261k Accesses
15 Citations
703 Altmetric
Explore all metrics
Communicating research findings is an essential step in the research process. Often, peer-reviewed journals are the forum for such communication, yet many researchers are never taught how to write a publishable scientific paper. In this article, we explain the basic structure of a scientific paper and describe the information that should be included in each section. We also identify common pitfalls for each section and recommend strategies to avoid them. Further, we give advice about target journal selection and authorship. In the online resource 1 , we provide an example of a high-quality scientific paper, with annotations identifying the elements we describe in this article.
Similar content being viewed by others

Literature reviews as independent studies: guidelines for academic practice
Sascha Kraus, Matthias Breier, … João J. Ferreira

Plagiarism in research
Gert Helgesson & Stefan Eriksson

How to design bibliometric research: an overview and a framework proposal
Oğuzhan Öztürk, Rıdvan Kocaman & Dominik K. Kanbach
Avoid common mistakes on your manuscript.
Introduction
Writing a scientific paper is an important component of the research process, yet researchers often receive little formal training in scientific writing. This is especially true in low-resource settings. In this article, we explain why choosing a target journal is important, give advice about authorship, provide a basic structure for writing each section of a scientific paper, and describe common pitfalls and recommendations for each section. In the online resource 1 , we also include an annotated journal article that identifies the key elements and writing approaches that we detail here. Before you begin your research, make sure you have ethical clearance from all relevant ethical review boards.
Select a Target Journal Early in the Writing Process
We recommend that you select a “target journal” early in the writing process; a “target journal” is the journal to which you plan to submit your paper. Each journal has a set of core readers and you should tailor your writing to this readership. For example, if you plan to submit a manuscript about vaping during pregnancy to a pregnancy-focused journal, you will need to explain what vaping is because readers of this journal may not have a background in this topic. However, if you were to submit that same article to a tobacco journal, you would not need to provide as much background information about vaping.
Information about a journal’s core readership can be found on its website, usually in a section called “About this journal” or something similar. For example, the Journal of Cancer Education presents such information on the “Aims and Scope” page of its website, which can be found here: https://www.springer.com/journal/13187/aims-and-scope .
Peer reviewer guidelines from your target journal are an additional resource that can help you tailor your writing to the journal and provide additional advice about crafting an effective article [ 1 ]. These are not always available, but it is worth a quick web search to find out.
Identify Author Roles Early in the Process
Early in the writing process, identify authors, determine the order of authors, and discuss the responsibilities of each author. Standard author responsibilities have been identified by The International Committee of Medical Journal Editors (ICMJE) [ 2 ]. To set clear expectations about each team member’s responsibilities and prevent errors in communication, we also suggest outlining more detailed roles, such as who will draft each section of the manuscript, write the abstract, submit the paper electronically, serve as corresponding author, and write the cover letter. It is best to formalize this agreement in writing after discussing it, circulating the document to the author team for approval. We suggest creating a title page on which all authors are listed in the agreed-upon order. It may be necessary to adjust authorship roles and order during the development of the paper. If a new author order is agreed upon, be sure to update the title page in the manuscript draft.
In the case where multiple papers will result from a single study, authors should discuss who will author each paper. Additionally, authors should agree on a deadline for each paper and the lead author should take responsibility for producing an initial draft by this deadline.
Structure of the Introduction Section
The introduction section should be approximately three to five paragraphs in length. Look at examples from your target journal to decide the appropriate length. This section should include the elements shown in Fig. 1 . Begin with a general context, narrowing to the specific focus of the paper. Include five main elements: why your research is important, what is already known about the topic, the “gap” or what is not yet known about the topic, why it is important to learn the new information that your research adds, and the specific research aim(s) that your paper addresses. Your research aim should address the gap you identified. Be sure to add enough background information to enable readers to understand your study. Table 1 provides common introduction section pitfalls and recommendations for addressing them.

The main elements of the introduction section of an original research article. Often, the elements overlap
Methods Section
The purpose of the methods section is twofold: to explain how the study was done in enough detail to enable its replication and to provide enough contextual detail to enable readers to understand and interpret the results. In general, the essential elements of a methods section are the following: a description of the setting and participants, the study design and timing, the recruitment and sampling, the data collection process, the dataset, the dependent and independent variables, the covariates, the analytic approach for each research objective, and the ethical approval. The hallmark of an exemplary methods section is the justification of why each method was used. Table 2 provides common methods section pitfalls and recommendations for addressing them.
Results Section
The focus of the results section should be associations, or lack thereof, rather than statistical tests. Two considerations should guide your writing here. First, the results should present answers to each part of the research aim. Second, return to the methods section to ensure that the analysis and variables for each result have been explained.
Begin the results section by describing the number of participants in the final sample and details such as the number who were approached to participate, the proportion who were eligible and who enrolled, and the number of participants who dropped out. The next part of the results should describe the participant characteristics. After that, you may organize your results by the aim or by putting the most exciting results first. Do not forget to report your non-significant associations. These are still findings.
Tables and figures capture the reader’s attention and efficiently communicate your main findings [ 3 ]. Each table and figure should have a clear message and should complement, rather than repeat, the text. Tables and figures should communicate all salient details necessary for a reader to understand the findings without consulting the text. Include information on comparisons and tests, as well as information about the sample and timing of the study in the title, legend, or in a footnote. Note that figures are often more visually interesting than tables, so if it is feasible to make a figure, make a figure. To avoid confusing the reader, either avoid abbreviations in tables and figures, or define them in a footnote. Note that there should not be citations in the results section and you should not interpret results here. Table 3 provides common results section pitfalls and recommendations for addressing them.
Discussion Section
Opposite the introduction section, the discussion should take the form of a right-side-up triangle beginning with interpretation of your results and moving to general implications (Fig. 2 ). This section typically begins with a restatement of the main findings, which can usually be accomplished with a few carefully-crafted sentences.

Major elements of the discussion section of an original research article. Often, the elements overlap
Next, interpret the meaning or explain the significance of your results, lifting the reader’s gaze from the study’s specific findings to more general applications. Then, compare these study findings with other research. Are these findings in agreement or disagreement with those from other studies? Does this study impart additional nuance to well-accepted theories? Situate your findings within the broader context of scientific literature, then explain the pathways or mechanisms that might give rise to, or explain, the results.
Journals vary in their approach to strengths and limitations sections: some are embedded paragraphs within the discussion section, while some mandate separate section headings. Keep in mind that every study has strengths and limitations. Candidly reporting yours helps readers to correctly interpret your research findings.
The next element of the discussion is a summary of the potential impacts and applications of the research. Should these results be used to optimally design an intervention? Does the work have implications for clinical protocols or public policy? These considerations will help the reader to further grasp the possible impacts of the presented work.
Finally, the discussion should conclude with specific suggestions for future work. Here, you have an opportunity to illuminate specific gaps in the literature that compel further study. Avoid the phrase “future research is necessary” because the recommendation is too general to be helpful to readers. Instead, provide substantive and specific recommendations for future studies. Table 4 provides common discussion section pitfalls and recommendations for addressing them.
Follow the Journal’s Author Guidelines
After you select a target journal, identify the journal’s author guidelines to guide the formatting of your manuscript and references. Author guidelines will often (but not always) include instructions for titles, cover letters, and other components of a manuscript submission. Read the guidelines carefully. If you do not follow the guidelines, your article will be sent back to you.
Finally, do not submit your paper to more than one journal at a time. Even if this is not explicitly stated in the author guidelines of your target journal, it is considered inappropriate and unprofessional.
Your title should invite readers to continue reading beyond the first page [ 4 , 5 ]. It should be informative and interesting. Consider describing the independent and dependent variables, the population and setting, the study design, the timing, and even the main result in your title. Because the focus of the paper can change as you write and revise, we recommend you wait until you have finished writing your paper before composing the title.
Be sure that the title is useful for potential readers searching for your topic. The keywords you select should complement those in your title to maximize the likelihood that a researcher will find your paper through a database search. Avoid using abbreviations in your title unless they are very well known, such as SNP, because it is more likely that someone will use a complete word rather than an abbreviation as a search term to help readers find your paper.
After you have written a complete draft, use the checklist (Fig. 3 ) below to guide your revisions and editing. Additional resources are available on writing the abstract and citing references [ 5 ]. When you feel that your work is ready, ask a trusted colleague or two to read the work and provide informal feedback. The box below provides a checklist that summarizes the key points offered in this article.

Checklist for manuscript quality
Data Availability
Michalek AM (2014) Down the rabbit hole…advice to reviewers. J Cancer Educ 29:4–5
Article Google Scholar
International Committee of Medical Journal Editors. Defining the role of authors and contributors: who is an author? http://www.icmje.org/recommendations/browse/roles-and-responsibilities/defining-the-role-of-authosrs-and-contributors.html . Accessed 15 January, 2020
Vetto JT (2014) Short and sweet: a short course on concise medical writing. J Cancer Educ 29(1):194–195
Brett M, Kording K (2017) Ten simple rules for structuring papers. PLoS ComputBiol. https://doi.org/10.1371/journal.pcbi.1005619
Lang TA (2017) Writing a better research article. J Public Health Emerg. https://doi.org/10.21037/jphe.2017.11.06
Download references
Acknowledgments
Ella August is grateful to the Sustainable Sciences Institute for mentoring her in training researchers on writing and publishing their research.
Code Availability
Not applicable.
Author information
Authors and affiliations.
Department of Maternal and Child Health, University of North Carolina Gillings School of Global Public Health, 135 Dauer Dr, 27599, Chapel Hill, NC, USA
Clara Busse & Ella August
Department of Epidemiology, University of Michigan School of Public Health, 1415 Washington Heights, Ann Arbor, MI, 48109-2029, USA
Ella August
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Ella August .
Ethics declarations
Conflicts of interests.
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
(PDF 362 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Busse, C., August, E. How to Write and Publish a Research Paper for a Peer-Reviewed Journal. J Canc Educ 36 , 909–913 (2021). https://doi.org/10.1007/s13187-020-01751-z
Download citation
Published : 30 April 2020
Issue Date : October 2021
DOI : https://doi.org/10.1007/s13187-020-01751-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Manuscripts
- Scientific writing
- Find a journal
- Publish with us
- Track your research
Reference management. Clean and simple.
The top list of academic search engines

1. Google Scholar
4. science.gov, 5. semantic scholar, 6. baidu scholar, get the most out of academic search engines, frequently asked questions about academic search engines, related articles.
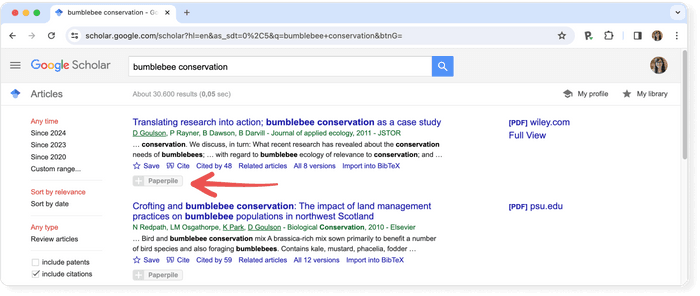
Academic search engines have become the number one resource to turn to in order to find research papers and other scholarly sources. While classic academic databases like Web of Science and Scopus are locked behind paywalls, Google Scholar and others can be accessed free of charge. In order to help you get your research done fast, we have compiled the top list of free academic search engines.
Google Scholar is the clear number one when it comes to academic search engines. It's the power of Google searches applied to research papers and patents. It not only lets you find research papers for all academic disciplines for free but also often provides links to full-text PDF files.
- Coverage: approx. 200 million articles
- Abstracts: only a snippet of the abstract is available
- Related articles: ✔
- References: ✔
- Cited by: ✔
- Links to full text: ✔
- Export formats: APA, MLA, Chicago, Harvard, Vancouver, RIS, BibTeX

BASE is hosted at Bielefeld University in Germany. That is also where its name stems from (Bielefeld Academic Search Engine).
- Coverage: approx. 136 million articles (contains duplicates)
- Abstracts: ✔
- Related articles: ✘
- References: ✘
- Cited by: ✘
- Export formats: RIS, BibTeX

CORE is an academic search engine dedicated to open-access research papers. For each search result, a link to the full-text PDF or full-text web page is provided.
- Coverage: approx. 136 million articles
- Links to full text: ✔ (all articles in CORE are open access)
- Export formats: BibTeX

Science.gov is a fantastic resource as it bundles and offers free access to search results from more than 15 U.S. federal agencies. There is no need anymore to query all those resources separately!
- Coverage: approx. 200 million articles and reports
- Links to full text: ✔ (available for some databases)
- Export formats: APA, MLA, RIS, BibTeX (available for some databases)

Semantic Scholar is the new kid on the block. Its mission is to provide more relevant and impactful search results using AI-powered algorithms that find hidden connections and links between research topics.
- Coverage: approx. 40 million articles
- Export formats: APA, MLA, Chicago, BibTeX

Although Baidu Scholar's interface is in Chinese, its index contains research papers in English as well as Chinese.
- Coverage: no detailed statistics available, approx. 100 million articles
- Abstracts: only snippets of the abstract are available
- Export formats: APA, MLA, RIS, BibTeX

RefSeek searches more than one billion documents from academic and organizational websites. Its clean interface makes it especially easy to use for students and new researchers.
- Coverage: no detailed statistics available, approx. 1 billion documents
- Abstracts: only snippets of the article are available
- Export formats: not available

Consider using a reference manager like Paperpile to save, organize, and cite your references. Paperpile integrates with Google Scholar and many popular databases, so you can save references and PDFs directly to your library using the Paperpile buttons:
Google Scholar is an academic search engine, and it is the clear number one when it comes to academic search engines. It's the power of Google searches applied to research papers and patents. It not only let's you find research papers for all academic disciplines for free, but also often provides links to full text PDF file.
Semantic Scholar is a free, AI-powered research tool for scientific literature developed at the Allen Institute for AI. Sematic Scholar was publicly released in 2015 and uses advances in natural language processing to provide summaries for scholarly papers.
BASE , as its name suggest is an academic search engine. It is hosted at Bielefeld University in Germany and that's where it name stems from (Bielefeld Academic Search Engine).
CORE is an academic search engine dedicated to open access research papers. For each search result a link to the full text PDF or full text web page is provided.
Science.gov is a fantastic resource as it bundles and offers free access to search results from more than 15 U.S. federal agencies. There is no need any more to query all those resources separately!

A free, AI-powered research tool for scientific literature
- Neil McWilliam
- Epistemology
New & Improved API for Developers
Introducing semantic reader in beta.
Stay Connected With Semantic Scholar Sign Up What Is Semantic Scholar? Semantic Scholar is a free, AI-powered research tool for scientific literature, based at the Allen Institute for AI.

English dominates scientific research – here’s how we can fix it, and why it matters

Científica titular del Centro de Ciencias Humanas y Sociales (CCHS - CSIC), Centro de Ciencias Humanas y Sociales (CCHS - CSIC)
Disclosure statement
Elea Giménez Toledo does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.
Consejo Superior de Investigaciones Científicas provides funding as a founding partner of The Conversation ES.
View all partners
It is often remarked that Spanish should be more widely spoken or understood in the scientific community given its number of speakers around the world, a figure the Instituto Cervantes places at almost 600 million .
However, millions of speakers do not necessarily grant a language strength in academia. This has to be cultivated on a scientific, political and cultural level, with sustained efforts from many institutions and specialists.
The scientific community should communicate in as many languages as possible
By some estimates, as much as 98% of the world’s scientific research is published in English , while only around 18% of the world’s population speaks it. This makes it essential to publish in other languages if we are to bring scientific research to society at large.
The value of multilingualism in science has been highlighted by numerous high profile organisations, with public declarations and statements on the matter from the European Charter for Researchers , the Helsinki Initiative on Multiligualism , the Unesco Recommendation on Open Science , the OPERAS Multiligualism White Paper , the Latin American Forum on Research Assessment , the COARA Agreement on Reforming Research Assessment , and the Declaration of the 5th Meeting of Minsters and Scientific Authorities of Ibero-American Countries . These organisations all agree on one thing: all languages have value in scientific communication.
As the last of these declarations points out, locally, regionally and nationally relevant research is constantly being published in languages other than English. This research has an economic, social and cultural impact on its surrounding environment, as when scientific knowledge is disseminated it filters through to non-academic professionals, thus creating a broader culture of knowledge sharing.
Greater diversity also enables fluid dialogue among academics who share the same language, or who speak and understand multiple languages. In Ibero-America, for example, Spanish and Portuguese can often be mutually understood by non-native speakers, allowing them to share the scientific stage. The same happens in Spain with the majority of its co-official languages .
Read more: Non-native English speaking scientists work much harder just to keep up, global research reveals
No hierarchies, no categories
Too often, scientific research in any language other than English is automatically seen as second tier, with little consideration for the quality of the work itself.
This harmful prejudice ignores the work of those involved, especially in the humanities and social sciences. It also profoundly undermines the global academic community’s ability to share knowledge with society.
By defending and preserving multilingualism, the scientific community brings research closer to those who need it. Failing to pursue this aim means that academia cannot develop or expand its audience. We have to work carefully, systematically and consistently in every language available to us.
Read more: Prestigious journals make it hard for scientists who don't speak English to get published. And we all lose out
The logistics of strengthening linguistic diversity in science
Making a language stronger in academia is a complex process. It does not happen spontaneously, and requires careful coordination and planning. Efforts have to come from public and private institutions, the media, and other cultural outlets, as well as from politicians, science diplomacy , and researchers themselves.
Many of these elements have to work in harmony, as demonstrated by the Spanish National Research Council’s work in ES CIENCIA , a project which seeks to unite scientific and and political efforts.
Academic publishing and AI models: a new challenge
The global academic environment is changing as a result the digital transition and new models of open access. Research into publishers of scientific content in other languages will be essential to understanding this shift. One thing is clear though: making scientific content produced in a particular language visible and searchable online is crucial to ensuring its strength.
In the case of academic books, the transition to open access has barely begun , especially in the commercial publishing sector, which releases around 80% of scientific books in Spain. As with online publishing, a clear understanding will make it possible to design policies and models that account for the different ways of disseminating scientific research, including those that communicate locally and in other languages. Greater linguistic diversity in book publishing can also allow us to properly recognise the work done by publishers in sharing research among non-English speakers.
Read more: Removing author fees can help open access journals make research available to everyone
Making publications, datasets, and other non-linguistic research results easy to find is another vital element, which requires both scientific and technical support. The same applies to expanding the corpus of scientific literature in Spanish and other languages, especially since this feeds into generative artificial intelligence models.
If linguistically diverse scientific content is not incorporated into AI systems, they will spread information that is incomplete, biased or misleading: a recent Spanish government report on the state of Spanish and co-official languages points out that 90% of the text currently fed into AI is written in English.
Deep study of terminology is essential
Research into terminology is of the utmost importance in preventing the use of improvised, imprecise language or unintelligible jargon. It can also bring huge benefits for the quality of both human and machine translations, specialised language teaching, and the indexing and organisation of large volumes of documents.
Terminology work in Spanish is being carried out today thanks to the processing of large language corpuses by AI and researchers in the TeresIA project, a joint effort coordinated by the Spanish National Research Council. However, 15 years of ups and downs were needed to to get such a project off the ground in Spanish.
The Basque Country, Catalonia and Galicia, on the other hand, have worked intensively and systematically on their respective languages. They have not only tackled terminology as a public language policy issue, but have also been committed to established terminology projects for a long time.
Multiligualism is a global issue
This need for broader diversity also applies to Ibero-America as a whole, where efforts are being coordinated to promote Spanish and Portuguese in academia, notably by the Ibero-American General Secretariat and the Mexican National Council of Humanities, Sciences and Technologies .
While this is sorely needed, we cannot promote the region’s two most widely spoken languages and also ignore its diversity of indigenous and co-official languages. These are also involved in the production of knowledge, and are a vehicle for the transfer of scientific information, as demonstrated by efforts in Spain.
Each country has its own unique role to play in promoting greater linguistic diversity in scientific communication. If this can be achieved, the strength of Iberian languages – and all languages, for that matter – in academia will not be at the mercy of well intentioned but sporadic efforts. It will, instead, be the result of the scientific community’s commitment to a culture of knowledge sharing.
This article was originally published in Spanish
- Scientific publishing
- Multilingualism
- The Conversation Europe
Biocloud Project Manager - Australian Biocommons
Director, Defence and Security
Opportunities with the new CIEHF
School of Social Sciences – Public Policy and International Relations opportunities
Deputy Editor - Technology

- Developing a Research Question
by acburton | Mar 22, 2024 | Resources for Students , Writing Resources
Selecting your research question and creating a clear goal and structure for your writing can be challenging – whether you are doing it for the first time or if you’ve done it many times before. It can be especially difficult when your research question starts to look and feel a little different somewhere between your first and final draft. Don’t panic! It’s normal for your research question to change a little (or even quite a bit) as you move through and engage with the writing process. Anticipating this can remind you to stay on track while you work and that it’ll be okay even if the literature takes you in a different direction.
What Makes an Effective Research Question?
The most effective research question will usually be a critical thinking question and should use “how” or “why” to ensure it can move beyond a yes/no or one-word type of answer. Consider how your research question can aim to reveal something new, fill in a gap, even if small, and contribute to the field in a meaningful way; How might the proposed project move knowledge forward about a particular place or process? This should be specific and achievable!
The CEWC’s Grad Writing Consultant Tariq says, “I definitely concentrated on those aspects of what I saw in the field where I believed there was an opportunity to move the discipline forward.”
General Tips
Do your research.
Utilize the librarians at your university and take the time to research your topic first. Try looking at very general sources to get an idea of what could be interesting to you before you move to more academic articles that support your rough idea of the topic. It is important that research is grounded in what you see or experience regarding the topic you have chosen and what is already known in the literature. Spend time researching articles, books, etc. that supports your thesis. Once you have a number of sources that you know support what you want to write about, formulate a research question that serves as the interrogative form of your thesis statement.
Grad Writing Consultant Deni advises, “Delineate your intervention in the literature (i.e., be strategic about the literature you discuss and clear about your contributions to it).”
Start Broadly…. then Narrow Your Topic Down to Something Manageable
When brainstorming your research question, let your mind veer toward connections or associations that you might have already considered or that seem to make sense and consider if new research terms, language or concepts come to mind that may be interesting or exciting for you as a researcher. Sometimes testing out a research question while doing some preliminary researching is also useful to see if the language you are using or the direction you are heading toward is fruitful when trying to search strategically in academic databases. Be prepared to focus on a specific area of a broad topic.
Writing Consultant Jessie recommends outlining: “I think some rough outlining with a research question in mind can be helpful for me. I’ll have a research question and maybe a working thesis that I feel may be my claim to the research question based on some preliminary materials, brainstorming, etc.” — Jessie, CEWC Writing Consultant
Try an Exercise
In the earliest phase of brainstorming, try an exercise suggested by CEWC Writing Specialist, Percival! While it is normally used in classroom or workshop settings, this exercise can easily be modified for someone working alone. The flow of the activity, if done within a group setting, is 1) someone starts with an idea, 2) three other people share their idea, and 3) the starting person picks two of these new ideas they like best and combines their original idea with those. The activity then begins again with the idea that was not chosen. The solo version of this exercise substitutes a ‘word bank,’ created using words, topics, or ideas similar to your broad, overarching theme. Pick two words or phrases from your word bank, combine it with your original idea or topic, and ‘start again’ with two different words. This serves as a replacement for different people’s suggestions. Ideas for your ‘word bank’ can range from vague prompts about mapping or webbing (e.g., where your topic falls within the discipline and others like it), to more specific concepts that come from tracing the history of an idea (its past, present, future) or mapping the idea’s related ideas, influences, etc. Care for a physics analogy? There is a particle (your topic) that you can describe, a wave that the particle traces, and a field that the particle is mapped on.
Get Feedback and Affirm Your Confidence!
Creating a few different versions of your research question (they may be the same topic/issue/theme or differ slightly) can be useful during this process. Sharing these with trusted friends, colleagues, mentors, (or tutors!) and having conversations about your questions and ideas with other people can help you decide which version you may feel most confident or interested in. Ask colleagues and mentors to share their research questions with you to get a lot of examples. Once you have done the work of developing an effective research question, do not forget to affirm your confidence! Based on your working thesis, think about how you might organize your chapters or paragraphs and what resources you have for supporting this structure and organization. This can help boost your confidence that the research question you have created is effective and fruitful.
Be Open to Change
Remember, your research question may change from your first to final draft. For questions along the way, make an appointment with the Writing Center. We are here to help you develop an effective and engaging research question and build the foundation for a solid research paper!
Example 1: In my field developing a research question involves navigating the relationship between 1) what one sees/experiences at their field site and 2) what is already known in the literature. During my preliminary research, I found that the financial value of land was often a matter of precisely these cultural factors. So, my research question ended up being: How do the social and material qualities of land entangle with processes of financialization in the city of Lahore. Regarding point #1, this question was absolutely informed by what I saw in the field. But regarding point #2, the question was also heavily shaped by the literature. – Tariq
Example 2: A research question should not be a yes/no question like “Is pollution bad?”; but an open-ended question where the answer has to be supported with reasons and explanation. The question also has to be narrowed down to a specific topic—using the same example as before—”Is pollution bad?” can be revised to “How does pollution affect people?” I would encourage students to be more specific then; e.g., what area of pollution do you want to talk about: water, air, plastic, climate change… what type of people or demographic can we focus on? …how does this affect marginalized communities, minorities, or specific areas in California? After researching and deciding on a focus, your question might sound something like: How does government policy affect water pollution and how does it affect the marginalized communities in the state of California? -Janella
Our Newest Resources!
- Transitioning to Long-form Writing
- Integrating Direct Quotations into Your Writing
- Nurturing a Growth Mindset to Overcome Writing Challenges and Develop Confidence in College Level Writing
- An Introduction to Paraphrasing, Summarizing, and Quoting
Additional Resources
- Graduate Writing Consultants
- Instructor Resources
- Student Resources
- Quick Guides and Handouts
- Self-Guided and Directed Learning Activities
- MyU : For Students, Faculty, and Staff
CS&E Colloquium: Co-Designing Algorithms and Hardware for Efficient Machine Learning (ML): Advancing the Democratization of ML
The computer science colloquium takes place on Mondays and Fridays from 11:15 a.m. - 12:15 p.m. This week's speaker, Caiwen Ding ( University of Connecticut ), will be giving a talk titled, "Co-Designing Algorithms and Hardware for Efficient Machine Learning (ML): Advancing the Democratization of ML".
The rapid deployment of ML has witnessed various challenges such as prolonged computation and high memory footprint on systems. In this talk, we will present several ML acceleration frameworks through algorithm-hardware co-design on various computing platforms. The first part presents a fine-grained crossbar-based ML accelerator. Instead of attempting to map the trained positive/negative weights afterwards, our key principle is to proactively ensure that all weights in the same column of a crossbar have the same sign, to reduce area. We divide the crossbar into sub-arrays, providing a unique opportunity for input zero-bit skipping. Next, we focus on co-designing Transformer architecture, and introduce on-the-fly attention and attention-aware pruning to significantly reduce runtime latency. Then, we will focus on co-design graph neural network training. To explore training sparsity and assist explainable ML, we propose a hardware friendly MaxK nonlinearity, and tailor a GPU kernel. Our methods outperform the state-of-the-arts on different tasks. Finally, we will discuss today's challenges related to secure edge AI and large language models (LLMs)-aided agile hardware design, and outline our research plans aimed at addressing these issues.
Caiwen Ding is an assistant professor in the School of Computing at the University of Connecticut (UConn). He received his Ph.D. degree from Northeastern University, Boston, in 2019, supervised by Prof. Yanzhi Wang. His research interests mainly include efficient embedded and high-performance systems for machine learning, machine learning for hardware design, and efficient privacy-preserving machine learning. His work has been published in high-impact venues (e.g., DAC, ICCAD, ASPLOS, ISCA, MICRO, HPCA, SC, FPGA, Oakland, NeurIPS, ICCV, IJCAI, AAAI, ACL, EMNLP). He is a recipient of the 2024 NSF CAREER Award, Amazon Research Award, and CISCO Research Award. He received the best paper nomination at 2018 DATE and 2021 DATE, the best paper award at the DL-Hardware Co-Design for AI Acceleration (DCAA) workshop at 2023 AAAI, outstanding student paper award at 2023 HPEC, publicity paper at 2022 DAC, and the 2021 Excellence in Teaching Award from UConn Provost. His team won first place in accuracy and fourth place overall at the 2022 TinyML Design Contest at ICCAD. He was ranked among Stanford’s World’s Top 2% Scientists in 2023. His research has been mainly funded by NSF, DOE, DOT, USDA, SRC, and multiple industrial sponsors.

Keller Hall 3-180
- Future undergraduate students
- Future transfer students
- Future graduate students
- Future international students
- Diversity and Inclusion Opportunities
- Learn abroad
- Living Learning Communities
- Mentor programs
- Programs for women
- Student groups
- Visit, Apply & Next Steps
- Information for current students
- Departments and majors overview
- Departments
- Undergraduate majors
- Graduate programs
- Integrated Degree Programs
- Additional degree-granting programs
- Online learning
- Academic Advising overview
- Academic Advising FAQ
- Academic Advising Blog
- Appointments and drop-ins
- Academic support
- Commencement
- Four-year plans
- Honors advising
- Policies, procedures, and forms
- Career Services overview
- Resumes and cover letters
- Jobs and internships
- Interviews and job offers
- CSE Career Fair
- Major and career exploration
- Graduate school
- Collegiate Life overview
- Scholarships
- Diversity & Inclusivity Alliance
- Anderson Student Innovation Labs
- Information for alumni
- Get engaged with CSE
- Upcoming events
- CSE Alumni Society Board
- Alumni volunteer interest form
- Golden Medallion Society Reunion
- 50-Year Reunion
- Alumni honors and awards
- Outstanding Achievement
- Alumni Service
- Distinguished Leadership
- Honorary Doctorate Degrees
- Nobel Laureates
- Alumni resources
- Alumni career resources
- Alumni news outlets
- CSE branded clothing
- International alumni resources
- Inventing Tomorrow magazine
- Update your info
- CSE giving overview
- Why give to CSE?
- College priorities
- Give online now
- External relations
- Giving priorities
- Donor stories
- Impact of giving
- Ways to give to CSE
- Matching gifts
- CSE directories
- Invest in your company and the future
- Recruit our students
- Connect with researchers
- K-12 initiatives
- Diversity initiatives
- Research news
- Give to CSE
- CSE priorities
- Corporate relations
- Information for faculty and staff
- Administrative offices overview
- Office of the Dean
- Academic affairs
- Finance and Operations
- Communications
- Human resources
- Undergraduate programs and student services
- CSE Committees
- CSE policies overview
- Academic policies
- Faculty hiring and tenure policies
- Finance policies and information
- Graduate education policies
- Human resources policies
- Research policies
- Research overview
- Research centers and facilities
- Research proposal submission process
- Research safety
- Award-winning CSE faculty
- National academies
- University awards
- Honorary professorships
- Collegiate awards
- Other CSE honors and awards
- Staff awards
- Performance Management Process
- Work. With Flexibility in CSE
- K-12 outreach overview
- Summer camps
- Outreach events
- Enrichment programs
- Field trips and tours
- CSE K-12 Virtual Classroom Resources
- Educator development
- Sponsor an event

Consumer Reports tests paper towels — Are name brands best?
( CONSUMER REPORTS ) — Are name-brand paper towels worth the extra money? Consumer Reports can tell you. Its testers just spent weeks putting six popular paper towel brands — including Bounty, Brawny, and Scott through a series of pick-up, strength, and absorbency tests to reveal which brand comes out on top.
Sometimes, a paper towel is the only tool for the job. They’re not always the best option for the environment, but there are just some messes, like kid’s and pet’s messes, that you don’t want to clean up with a reusable paper towel.
For quickly cleaning up spills, you want a single sheet to hold as much liquid as possible, so testers calculated the absorbency of each paper towel.
Testers also measured strength by slowly adding weighted test pellets into a cup held up by just a single wet paper towel until the paper towel gave out. The more and longer it can hold, the stronger it is.
A machine helped testers evaluate scrubbing strength.The best paper towels scrubbed a piece of sandpaper for about 15 cycles before breaking down; the worst struggled after just six cycles.
And – apologies in advance – CR’s dedicated tester even simulated vomit with a concoction of chunky oatmeal and dehydrated vegetables to see how well each paper towel could pick up the mess.
CR also checked to see how fast each sheet ripped from its roll and whether or not a paper towel could be reused. The testers evaluated the price both per roll and per sheet.
The winner? A name synonymous with paper towels for almost 60 years — Bounty — “The quicker picker upper,” had the highest overall score, but it comes at a price. Bounty was the most expensive brand tested. CR says Brawny could be a good alternative if you’re trying to save a few dollars and don’t want to lose out on performance.
All the paper towels in CR’s tests could be reused after light use. But paper towels aren’t recyclable. For routine cleaning, CR recommends reusable paper towels and microfiber cloths, which you can wash and reuse.
For the latest news, weather, sports, and streaming video, head to ABC4 Utah.

Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 26 March 2024
Predicting and improving complex beer flavor through machine learning
- Michiel Schreurs ORCID: orcid.org/0000-0002-9449-5619 1 , 2 , 3 na1 ,
- Supinya Piampongsant 1 , 2 , 3 na1 ,
- Miguel Roncoroni ORCID: orcid.org/0000-0001-7461-1427 1 , 2 , 3 na1 ,
- Lloyd Cool ORCID: orcid.org/0000-0001-9936-3124 1 , 2 , 3 , 4 ,
- Beatriz Herrera-Malaver ORCID: orcid.org/0000-0002-5096-9974 1 , 2 , 3 ,
- Christophe Vanderaa ORCID: orcid.org/0000-0001-7443-5427 4 ,
- Florian A. Theßeling 1 , 2 , 3 ,
- Łukasz Kreft ORCID: orcid.org/0000-0001-7620-4657 5 ,
- Alexander Botzki ORCID: orcid.org/0000-0001-6691-4233 5 ,
- Philippe Malcorps 6 ,
- Luk Daenen 6 ,
- Tom Wenseleers ORCID: orcid.org/0000-0002-1434-861X 4 &
- Kevin J. Verstrepen ORCID: orcid.org/0000-0002-3077-6219 1 , 2 , 3
Nature Communications volume 15 , Article number: 2368 ( 2024 ) Cite this article
36k Accesses
741 Altmetric
Metrics details
- Chemical engineering
- Gas chromatography
- Machine learning
- Metabolomics
- Taste receptors
The perception and appreciation of food flavor depends on many interacting chemical compounds and external factors, and therefore proves challenging to understand and predict. Here, we combine extensive chemical and sensory analyses of 250 different beers to train machine learning models that allow predicting flavor and consumer appreciation. For each beer, we measure over 200 chemical properties, perform quantitative descriptive sensory analysis with a trained tasting panel and map data from over 180,000 consumer reviews to train 10 different machine learning models. The best-performing algorithm, Gradient Boosting, yields models that significantly outperform predictions based on conventional statistics and accurately predict complex food features and consumer appreciation from chemical profiles. Model dissection allows identifying specific and unexpected compounds as drivers of beer flavor and appreciation. Adding these compounds results in variants of commercial alcoholic and non-alcoholic beers with improved consumer appreciation. Together, our study reveals how big data and machine learning uncover complex links between food chemistry, flavor and consumer perception, and lays the foundation to develop novel, tailored foods with superior flavors.
Similar content being viewed by others

BitterSweet: Building machine learning models for predicting the bitter and sweet taste of small molecules
Rudraksh Tuwani, Somin Wadhwa & Ganesh Bagler

Sensory lexicon and aroma volatiles analysis of brewing malt
Xiaoxia Su, Miao Yu, … Tianyi Du

Predicting odor from molecular structure: a multi-label classification approach
Kushagra Saini & Venkatnarayan Ramanathan
Introduction
Predicting and understanding food perception and appreciation is one of the major challenges in food science. Accurate modeling of food flavor and appreciation could yield important opportunities for both producers and consumers, including quality control, product fingerprinting, counterfeit detection, spoilage detection, and the development of new products and product combinations (food pairing) 1 , 2 , 3 , 4 , 5 , 6 . Accurate models for flavor and consumer appreciation would contribute greatly to our scientific understanding of how humans perceive and appreciate flavor. Moreover, accurate predictive models would also facilitate and standardize existing food assessment methods and could supplement or replace assessments by trained and consumer tasting panels, which are variable, expensive and time-consuming 7 , 8 , 9 . Lastly, apart from providing objective, quantitative, accurate and contextual information that can help producers, models can also guide consumers in understanding their personal preferences 10 .
Despite the myriad of applications, predicting food flavor and appreciation from its chemical properties remains a largely elusive goal in sensory science, especially for complex food and beverages 11 , 12 . A key obstacle is the immense number of flavor-active chemicals underlying food flavor. Flavor compounds can vary widely in chemical structure and concentration, making them technically challenging and labor-intensive to quantify, even in the face of innovations in metabolomics, such as non-targeted metabolic fingerprinting 13 , 14 . Moreover, sensory analysis is perhaps even more complicated. Flavor perception is highly complex, resulting from hundreds of different molecules interacting at the physiochemical and sensorial level. Sensory perception is often non-linear, characterized by complex and concentration-dependent synergistic and antagonistic effects 15 , 16 , 17 , 18 , 19 , 20 , 21 that are further convoluted by the genetics, environment, culture and psychology of consumers 22 , 23 , 24 . Perceived flavor is therefore difficult to measure, with problems of sensitivity, accuracy, and reproducibility that can only be resolved by gathering sufficiently large datasets 25 . Trained tasting panels are considered the prime source of quality sensory data, but require meticulous training, are low throughput and high cost. Public databases containing consumer reviews of food products could provide a valuable alternative, especially for studying appreciation scores, which do not require formal training 25 . Public databases offer the advantage of amassing large amounts of data, increasing the statistical power to identify potential drivers of appreciation. However, public datasets suffer from biases, including a bias in the volunteers that contribute to the database, as well as confounding factors such as price, cult status and psychological conformity towards previous ratings of the product.
Classical multivariate statistics and machine learning methods have been used to predict flavor of specific compounds by, for example, linking structural properties of a compound to its potential biological activities or linking concentrations of specific compounds to sensory profiles 1 , 26 . Importantly, most previous studies focused on predicting organoleptic properties of single compounds (often based on their chemical structure) 27 , 28 , 29 , 30 , 31 , 32 , 33 , thus ignoring the fact that these compounds are present in a complex matrix in food or beverages and excluding complex interactions between compounds. Moreover, the classical statistics commonly used in sensory science 34 , 35 , 36 , 37 , 38 , 39 require a large sample size and sufficient variance amongst predictors to create accurate models. They are not fit for studying an extensive set of hundreds of interacting flavor compounds, since they are sensitive to outliers, have a high tendency to overfit and are less suited for non-linear and discontinuous relationships 40 .
In this study, we combine extensive chemical analyses and sensory data of a set of different commercial beers with machine learning approaches to develop models that predict taste, smell, mouthfeel and appreciation from compound concentrations. Beer is particularly suited to model the relationship between chemistry, flavor and appreciation. First, beer is a complex product, consisting of thousands of flavor compounds that partake in complex sensory interactions 41 , 42 , 43 . This chemical diversity arises from the raw materials (malt, yeast, hops, water and spices) and biochemical conversions during the brewing process (kilning, mashing, boiling, fermentation, maturation and aging) 44 , 45 . Second, the advent of the internet saw beer consumers embrace online review platforms, such as RateBeer (ZX Ventures, Anheuser-Busch InBev SA/NV) and BeerAdvocate (Next Glass, inc.). In this way, the beer community provides massive data sets of beer flavor and appreciation scores, creating extraordinarily large sensory databases to complement the analyses of our professional sensory panel. Specifically, we characterize over 200 chemical properties of 250 commercial beers, spread across 22 beer styles, and link these to the descriptive sensory profiling data of a 16-person in-house trained tasting panel and data acquired from over 180,000 public consumer reviews. These unique and extensive datasets enable us to train a suite of machine learning models to predict flavor and appreciation from a beer’s chemical profile. Dissection of the best-performing models allows us to pinpoint specific compounds as potential drivers of beer flavor and appreciation. Follow-up experiments confirm the importance of these compounds and ultimately allow us to significantly improve the flavor and appreciation of selected commercial beers. Together, our study represents a significant step towards understanding complex flavors and reinforces the value of machine learning to develop and refine complex foods. In this way, it represents a stepping stone for further computer-aided food engineering applications 46 .
To generate a comprehensive dataset on beer flavor, we selected 250 commercial Belgian beers across 22 different beer styles (Supplementary Fig. S1 ). Beers with ≤ 4.2% alcohol by volume (ABV) were classified as non-alcoholic and low-alcoholic. Blonds and Tripels constitute a significant portion of the dataset (12.4% and 11.2%, respectively) reflecting their presence on the Belgian beer market and the heterogeneity of beers within these styles. By contrast, lager beers are less diverse and dominated by a handful of brands. Rare styles such as Brut or Faro make up only a small fraction of the dataset (2% and 1%, respectively) because fewer of these beers are produced and because they are dominated by distinct characteristics in terms of flavor and chemical composition.
Extensive analysis identifies relationships between chemical compounds in beer
For each beer, we measured 226 different chemical properties, including common brewing parameters such as alcohol content, iso-alpha acids, pH, sugar concentration 47 , and over 200 flavor compounds (Methods, Supplementary Table S1 ). A large portion (37.2%) are terpenoids arising from hopping, responsible for herbal and fruity flavors 16 , 48 . A second major category are yeast metabolites, such as esters and alcohols, that result in fruity and solvent notes 48 , 49 , 50 . Other measured compounds are primarily derived from malt, or other microbes such as non- Saccharomyces yeasts and bacteria (‘wild flora’). Compounds that arise from spices or staling are labeled under ‘Others’. Five attributes (caloric value, total acids and total ester, hop aroma and sulfur compounds) are calculated from multiple individually measured compounds.
As a first step in identifying relationships between chemical properties, we determined correlations between the concentrations of the compounds (Fig. 1 , upper panel, Supplementary Data 1 and 2 , and Supplementary Fig. S2 . For the sake of clarity, only a subset of the measured compounds is shown in Fig. 1 ). Compounds of the same origin typically show a positive correlation, while absence of correlation hints at parameters varying independently. For example, the hop aroma compounds citronellol, and alpha-terpineol show moderate correlations with each other (Spearman’s rho=0.39 and 0.57), but not with the bittering hop component iso-alpha acids (Spearman’s rho=0.16 and −0.07). This illustrates how brewers can independently modify hop aroma and bitterness by selecting hop varieties and dosage time. If hops are added early in the boiling phase, chemical conversions increase bitterness while aromas evaporate, conversely, late addition of hops preserves aroma but limits bitterness 51 . Similarly, hop-derived iso-alpha acids show a strong anti-correlation with lactic acid and acetic acid, likely reflecting growth inhibition of lactic acid and acetic acid bacteria, or the consequent use of fewer hops in sour beer styles, such as West Flanders ales and Fruit beers, that rely on these bacteria for their distinct flavors 52 . Finally, yeast-derived esters (ethyl acetate, ethyl decanoate, ethyl hexanoate, ethyl octanoate) and alcohols (ethanol, isoamyl alcohol, isobutanol, and glycerol), correlate with Spearman coefficients above 0.5, suggesting that these secondary metabolites are correlated with the yeast genetic background and/or fermentation parameters and may be difficult to influence individually, although the choice of yeast strain may offer some control 53 .

Spearman rank correlations are shown. Descriptors are grouped according to their origin (malt (blue), hops (green), yeast (red), wild flora (yellow), Others (black)), and sensory aspect (aroma, taste, palate, and overall appreciation). Please note that for the chemical compounds, for the sake of clarity, only a subset of the total number of measured compounds is shown, with an emphasis on the key compounds for each source. For more details, see the main text and Methods section. Chemical data can be found in Supplementary Data 1 , correlations between all chemical compounds are depicted in Supplementary Fig. S2 and correlation values can be found in Supplementary Data 2 . See Supplementary Data 4 for sensory panel assessments and Supplementary Data 5 for correlation values between all sensory descriptors.
Interestingly, different beer styles show distinct patterns for some flavor compounds (Supplementary Fig. S3 ). These observations agree with expectations for key beer styles, and serve as a control for our measurements. For instance, Stouts generally show high values for color (darker), while hoppy beers contain elevated levels of iso-alpha acids, compounds associated with bitter hop taste. Acetic and lactic acid are not prevalent in most beers, with notable exceptions such as Kriek, Lambic, Faro, West Flanders ales and Flanders Old Brown, which use acid-producing bacteria ( Lactobacillus and Pediococcus ) or unconventional yeast ( Brettanomyces ) 54 , 55 . Glycerol, ethanol and esters show similar distributions across all beer styles, reflecting their common origin as products of yeast metabolism during fermentation 45 , 53 . Finally, low/no-alcohol beers contain low concentrations of glycerol and esters. This is in line with the production process for most of the low/no-alcohol beers in our dataset, which are produced through limiting fermentation or by stripping away alcohol via evaporation or dialysis, with both methods having the unintended side-effect of reducing the amount of flavor compounds in the final beer 56 , 57 .
Besides expected associations, our data also reveals less trivial associations between beer styles and specific parameters. For example, geraniol and citronellol, two monoterpenoids responsible for citrus, floral and rose flavors and characteristic of Citra hops, are found in relatively high amounts in Christmas, Saison, and Brett/co-fermented beers, where they may originate from terpenoid-rich spices such as coriander seeds instead of hops 58 .
Tasting panel assessments reveal sensorial relationships in beer
To assess the sensory profile of each beer, a trained tasting panel evaluated each of the 250 beers for 50 sensory attributes, including different hop, malt and yeast flavors, off-flavors and spices. Panelists used a tasting sheet (Supplementary Data 3 ) to score the different attributes. Panel consistency was evaluated by repeating 12 samples across different sessions and performing ANOVA. In 95% of cases no significant difference was found across sessions ( p > 0.05), indicating good panel consistency (Supplementary Table S2 ).
Aroma and taste perception reported by the trained panel are often linked (Fig. 1 , bottom left panel and Supplementary Data 4 and 5 ), with high correlations between hops aroma and taste (Spearman’s rho=0.83). Bitter taste was found to correlate with hop aroma and taste in general (Spearman’s rho=0.80 and 0.69), and particularly with “grassy” noble hops (Spearman’s rho=0.75). Barnyard flavor, most often associated with sour beers, is identified together with stale hops (Spearman’s rho=0.97) that are used in these beers. Lactic and acetic acid, which often co-occur, are correlated (Spearman’s rho=0.66). Interestingly, sweetness and bitterness are anti-correlated (Spearman’s rho = −0.48), confirming the hypothesis that they mask each other 59 , 60 . Beer body is highly correlated with alcohol (Spearman’s rho = 0.79), and overall appreciation is found to correlate with multiple aspects that describe beer mouthfeel (alcohol, carbonation; Spearman’s rho= 0.32, 0.39), as well as with hop and ester aroma intensity (Spearman’s rho=0.39 and 0.35).
Similar to the chemical analyses, sensorial analyses confirmed typical features of specific beer styles (Supplementary Fig. S4 ). For example, sour beers (Faro, Flanders Old Brown, Fruit beer, Kriek, Lambic, West Flanders ale) were rated acidic, with flavors of both acetic and lactic acid. Hoppy beers were found to be bitter and showed hop-associated aromas like citrus and tropical fruit. Malt taste is most detected among scotch, stout/porters, and strong ales, while low/no-alcohol beers, which often have a reputation for being ‘worty’ (reminiscent of unfermented, sweet malt extract) appear in the middle. Unsurprisingly, hop aromas are most strongly detected among hoppy beers. Like its chemical counterpart (Supplementary Fig. S3 ), acidity shows a right-skewed distribution, with the most acidic beers being Krieks, Lambics, and West Flanders ales.
Tasting panel assessments of specific flavors correlate with chemical composition
We find that the concentrations of several chemical compounds strongly correlate with specific aroma or taste, as evaluated by the tasting panel (Fig. 2 , Supplementary Fig. S5 , Supplementary Data 6 ). In some cases, these correlations confirm expectations and serve as a useful control for data quality. For example, iso-alpha acids, the bittering compounds in hops, strongly correlate with bitterness (Spearman’s rho=0.68), while ethanol and glycerol correlate with tasters’ perceptions of alcohol and body, the mouthfeel sensation of fullness (Spearman’s rho=0.82/0.62 and 0.72/0.57 respectively) and darker color from roasted malts is a good indication of malt perception (Spearman’s rho=0.54).

Heatmap colors indicate Spearman’s Rho. Axes are organized according to sensory categories (aroma, taste, mouthfeel, overall), chemical categories and chemical sources in beer (malt (blue), hops (green), yeast (red), wild flora (yellow), Others (black)). See Supplementary Data 6 for all correlation values.
Interestingly, for some relationships between chemical compounds and perceived flavor, correlations are weaker than expected. For example, the rose-smelling phenethyl acetate only weakly correlates with floral aroma. This hints at more complex relationships and interactions between compounds and suggests a need for a more complex model than simple correlations. Lastly, we uncovered unexpected correlations. For instance, the esters ethyl decanoate and ethyl octanoate appear to correlate slightly with hop perception and bitterness, possibly due to their fruity flavor. Iron is anti-correlated with hop aromas and bitterness, most likely because it is also anti-correlated with iso-alpha acids. This could be a sign of metal chelation of hop acids 61 , given that our analyses measure unbound hop acids and total iron content, or could result from the higher iron content in dark and Fruit beers, which typically have less hoppy and bitter flavors 62 .
Public consumer reviews complement expert panel data
To complement and expand the sensory data of our trained tasting panel, we collected 180,000 reviews of our 250 beers from the online consumer review platform RateBeer. This provided numerical scores for beer appearance, aroma, taste, palate, overall quality as well as the average overall score.
Public datasets are known to suffer from biases, such as price, cult status and psychological conformity towards previous ratings of a product. For example, prices correlate with appreciation scores for these online consumer reviews (rho=0.49, Supplementary Fig. S6 ), but not for our trained tasting panel (rho=0.19). This suggests that prices affect consumer appreciation, which has been reported in wine 63 , while blind tastings are unaffected. Moreover, we observe that some beer styles, like lagers and non-alcoholic beers, generally receive lower scores, reflecting that online reviewers are mostly beer aficionados with a preference for specialty beers over lager beers. In general, we find a modest correlation between our trained panel’s overall appreciation score and the online consumer appreciation scores (Fig. 3 , rho=0.29). Apart from the aforementioned biases in the online datasets, serving temperature, sample freshness and surroundings, which are all tightly controlled during the tasting panel sessions, can vary tremendously across online consumers and can further contribute to (among others, appreciation) differences between the two categories of tasters. Importantly, in contrast to the overall appreciation scores, for many sensory aspects the results from the professional panel correlated well with results obtained from RateBeer reviews. Correlations were highest for features that are relatively easy to recognize even for untrained tasters, like bitterness, sweetness, alcohol and malt aroma (Fig. 3 and below).

RateBeer text mining results can be found in Supplementary Data 7 . Rho values shown are Spearman correlation values, with asterisks indicating significant correlations ( p < 0.05, two-sided). All p values were smaller than 0.001, except for Esters aroma (0.0553), Esters taste (0.3275), Esters aroma—banana (0.0019), Coriander (0.0508) and Diacetyl (0.0134).
Besides collecting consumer appreciation from these online reviews, we developed automated text analysis tools to gather additional data from review texts (Supplementary Data 7 ). Processing review texts on the RateBeer database yielded comparable results to the scores given by the trained panel for many common sensory aspects, including acidity, bitterness, sweetness, alcohol, malt, and hop tastes (Fig. 3 ). This is in line with what would be expected, since these attributes require less training for accurate assessment and are less influenced by environmental factors such as temperature, serving glass and odors in the environment. Consumer reviews also correlate well with our trained panel for 4-vinyl guaiacol, a compound associated with a very characteristic aroma. By contrast, correlations for more specific aromas like ester, coriander or diacetyl are underrepresented in the online reviews, underscoring the importance of using a trained tasting panel and standardized tasting sheets with explicit factors to be scored for evaluating specific aspects of a beer. Taken together, our results suggest that public reviews are trustworthy for some, but not all, flavor features and can complement or substitute taste panel data for these sensory aspects.
Models can predict beer sensory profiles from chemical data
The rich datasets of chemical analyses, tasting panel assessments and public reviews gathered in the first part of this study provided us with a unique opportunity to develop predictive models that link chemical data to sensorial features. Given the complexity of beer flavor, basic statistical tools such as correlations or linear regression may not always be the most suitable for making accurate predictions. Instead, we applied different machine learning models that can model both simple linear and complex interactive relationships. Specifically, we constructed a set of regression models to predict (a) trained panel scores for beer flavor and quality and (b) public reviews’ appreciation scores from beer chemical profiles. We trained and tested 10 different models (Methods), 3 linear regression-based models (simple linear regression with first-order interactions (LR), lasso regression with first-order interactions (Lasso), partial least squares regressor (PLSR)), 5 decision tree models (AdaBoost regressor (ABR), extra trees (ET), gradient boosting regressor (GBR), random forest (RF) and XGBoost regressor (XGBR)), 1 support vector regression (SVR), and 1 artificial neural network (ANN) model.
To compare the performance of our machine learning models, the dataset was randomly split into a training and test set, stratified by beer style. After a model was trained on data in the training set, its performance was evaluated on its ability to predict the test dataset obtained from multi-output models (based on the coefficient of determination, see Methods). Additionally, individual-attribute models were ranked per descriptor and the average rank was calculated, as proposed by Korneva et al. 64 . Importantly, both ways of evaluating the models’ performance agreed in general. Performance of the different models varied (Table 1 ). It should be noted that all models perform better at predicting RateBeer results than results from our trained tasting panel. One reason could be that sensory data is inherently variable, and this variability is averaged out with the large number of public reviews from RateBeer. Additionally, all tree-based models perform better at predicting taste than aroma. Linear models (LR) performed particularly poorly, with negative R 2 values, due to severe overfitting (training set R 2 = 1). Overfitting is a common issue in linear models with many parameters and limited samples, especially with interaction terms further amplifying the number of parameters. L1 regularization (Lasso) successfully overcomes this overfitting, out-competing multiple tree-based models on the RateBeer dataset. Similarly, the dimensionality reduction of PLSR avoids overfitting and improves performance, to some extent. Still, tree-based models (ABR, ET, GBR, RF and XGBR) show the best performance, out-competing the linear models (LR, Lasso, PLSR) commonly used in sensory science 65 .
GBR models showed the best overall performance in predicting sensory responses from chemical information, with R 2 values up to 0.75 depending on the predicted sensory feature (Supplementary Table S4 ). The GBR models predict consumer appreciation (RateBeer) better than our trained panel’s appreciation (R 2 value of 0.67 compared to R 2 value of 0.09) (Supplementary Table S3 and Supplementary Table S4 ). ANN models showed intermediate performance, likely because neural networks typically perform best with larger datasets 66 . The SVR shows intermediate performance, mostly due to the weak predictions of specific attributes that lower the overall performance (Supplementary Table S4 ).
Model dissection identifies specific, unexpected compounds as drivers of consumer appreciation
Next, we leveraged our models to infer important contributors to sensory perception and consumer appreciation. Consumer preference is a crucial sensory aspects, because a product that shows low consumer appreciation scores often does not succeed commercially 25 . Additionally, the requirement for a large number of representative evaluators makes consumer trials one of the more costly and time-consuming aspects of product development. Hence, a model for predicting chemical drivers of overall appreciation would be a welcome addition to the available toolbox for food development and optimization.
Since GBR models on our RateBeer dataset showed the best overall performance, we focused on these models. Specifically, we used two approaches to identify important contributors. First, rankings of the most important predictors for each sensorial trait in the GBR models were obtained based on impurity-based feature importance (mean decrease in impurity). High-ranked parameters were hypothesized to be either the true causal chemical properties underlying the trait, to correlate with the actual causal properties, or to take part in sensory interactions affecting the trait 67 (Fig. 4A ). In a second approach, we used SHAP 68 to determine which parameters contributed most to the model for making predictions of consumer appreciation (Fig. 4B ). SHAP calculates parameter contributions to model predictions on a per-sample basis, which can be aggregated into an importance score.

A The impurity-based feature importance (mean deviance in impurity, MDI) calculated from the Gradient Boosting Regression (GBR) model predicting RateBeer appreciation scores. The top 15 highest ranked chemical properties are shown. B SHAP summary plot for the top 15 parameters contributing to our GBR model. Each point on the graph represents a sample from our dataset. The color represents the concentration of that parameter, with bluer colors representing low values and redder colors representing higher values. Greater absolute values on the horizontal axis indicate a higher impact of the parameter on the prediction of the model. C Spearman correlations between the 15 most important chemical properties and consumer overall appreciation. Numbers indicate the Spearman Rho correlation coefficient, and the rank of this correlation compared to all other correlations. The top 15 important compounds were determined using SHAP (panel B).
Both approaches identified ethyl acetate as the most predictive parameter for beer appreciation (Fig. 4 ). Ethyl acetate is the most abundant ester in beer with a typical ‘fruity’, ‘solvent’ and ‘alcoholic’ flavor, but is often considered less important than other esters like isoamyl acetate. The second most important parameter identified by SHAP is ethanol, the most abundant beer compound after water. Apart from directly contributing to beer flavor and mouthfeel, ethanol drastically influences the physical properties of beer, dictating how easily volatile compounds escape the beer matrix to contribute to beer aroma 69 . Importantly, it should also be noted that the importance of ethanol for appreciation is likely inflated by the very low appreciation scores of non-alcoholic beers (Supplementary Fig. S4 ). Despite not often being considered a driver of beer appreciation, protein level also ranks highly in both approaches, possibly due to its effect on mouthfeel and body 70 . Lactic acid, which contributes to the tart taste of sour beers, is the fourth most important parameter identified by SHAP, possibly due to the generally high appreciation of sour beers in our dataset.
Interestingly, some of the most important predictive parameters for our model are not well-established as beer flavors or are even commonly regarded as being negative for beer quality. For example, our models identify methanethiol and ethyl phenyl acetate, an ester commonly linked to beer staling 71 , as a key factor contributing to beer appreciation. Although there is no doubt that high concentrations of these compounds are considered unpleasant, the positive effects of modest concentrations are not yet known 72 , 73 .
To compare our approach to conventional statistics, we evaluated how well the 15 most important SHAP-derived parameters correlate with consumer appreciation (Fig. 4C ). Interestingly, only 6 of the properties derived by SHAP rank amongst the top 15 most correlated parameters. For some chemical compounds, the correlations are so low that they would have likely been considered unimportant. For example, lactic acid, the fourth most important parameter, shows a bimodal distribution for appreciation, with sour beers forming a separate cluster, that is missed entirely by the Spearman correlation. Additionally, the correlation plots reveal outliers, emphasizing the need for robust analysis tools. Together, this highlights the need for alternative models, like the Gradient Boosting model, that better grasp the complexity of (beer) flavor.
Finally, to observe the relationships between these chemical properties and their predicted targets, partial dependence plots were constructed for the six most important predictors of consumer appreciation 74 , 75 , 76 (Supplementary Fig. S7 ). One-way partial dependence plots show how a change in concentration affects the predicted appreciation. These plots reveal an important limitation of our models: appreciation predictions remain constant at ever-increasing concentrations. This implies that once a threshold concentration is reached, further increasing the concentration does not affect appreciation. This is false, as it is well-documented that certain compounds become unpleasant at high concentrations, including ethyl acetate (‘nail polish’) 77 and methanethiol (‘sulfury’ and ‘rotten cabbage’) 78 . The inability of our models to grasp that flavor compounds have optimal levels, above which they become negative, is a consequence of working with commercial beer brands where (off-)flavors are rarely too high to negatively impact the product. The two-way partial dependence plots show how changing the concentration of two compounds influences predicted appreciation, visualizing their interactions (Supplementary Fig. S7 ). In our case, the top 5 parameters are dominated by additive or synergistic interactions, with high concentrations for both compounds resulting in the highest predicted appreciation.
To assess the robustness of our best-performing models and model predictions, we performed 100 iterations of the GBR, RF and ET models. In general, all iterations of the models yielded similar performance (Supplementary Fig. S8 ). Moreover, the main predictors (including the top predictors ethanol and ethyl acetate) remained virtually the same, especially for GBR and RF. For the iterations of the ET model, we did observe more variation in the top predictors, which is likely a consequence of the model’s inherent random architecture in combination with co-correlations between certain predictors. However, even in this case, several of the top predictors (ethanol and ethyl acetate) remain unchanged, although their rank in importance changes (Supplementary Fig. S8 ).
Next, we investigated if a combination of RateBeer and trained panel data into one consolidated dataset would lead to stronger models, under the hypothesis that such a model would suffer less from bias in the datasets. A GBR model was trained to predict appreciation on the combined dataset. This model underperformed compared to the RateBeer model, both in the native case and when including a dataset identifier (R 2 = 0.67, 0.26 and 0.42 respectively). For the latter, the dataset identifier is the most important feature (Supplementary Fig. S9 ), while most of the feature importance remains unchanged, with ethyl acetate and ethanol ranking highest, like in the original model trained only on RateBeer data. It seems that the large variation in the panel dataset introduces noise, weakening the models’ performances and reliability. In addition, it seems reasonable to assume that both datasets are fundamentally different, with the panel dataset obtained by blind tastings by a trained professional panel.
Lastly, we evaluated whether beer style identifiers would further enhance the model’s performance. A GBR model was trained with parameters that explicitly encoded the styles of the samples. This did not improve model performance (R2 = 0.66 with style information vs R2 = 0.67). The most important chemical features are consistent with the model trained without style information (eg. ethanol and ethyl acetate), and with the exception of the most preferred (strong ale) and least preferred (low/no-alcohol) styles, none of the styles were among the most important features (Supplementary Fig. S9 , Supplementary Table S5 and S6 ). This is likely due to a combination of style-specific chemical signatures, such as iso-alpha acids and lactic acid, that implicitly convey style information to the original models, as well as the low number of samples belonging to some styles, making it difficult for the model to learn style-specific patterns. Moreover, beer styles are not rigorously defined, with some styles overlapping in features and some beers being misattributed to a specific style, all of which leads to more noise in models that use style parameters.
Model validation
To test if our predictive models give insight into beer appreciation, we set up experiments aimed at improving existing commercial beers. We specifically selected overall appreciation as the trait to be examined because of its complexity and commercial relevance. Beer flavor comprises a complex bouquet rather than single aromas and tastes 53 . Hence, adding a single compound to the extent that a difference is noticeable may lead to an unbalanced, artificial flavor. Therefore, we evaluated the effect of combinations of compounds. Because Blond beers represent the most extensive style in our dataset, we selected a beer from this style as the starting material for these experiments (Beer 64 in Supplementary Data 1 ).
In the first set of experiments, we adjusted the concentrations of compounds that made up the most important predictors of overall appreciation (ethyl acetate, ethanol, lactic acid, ethyl phenyl acetate) together with correlated compounds (ethyl hexanoate, isoamyl acetate, glycerol), bringing them up to 95 th percentile ethanol-normalized concentrations (Methods) within the Blond group (‘Spiked’ concentration in Fig. 5A ). Compared to controls, the spiked beers were found to have significantly improved overall appreciation among trained panelists, with panelist noting increased intensity of ester flavors, sweetness, alcohol, and body fullness (Fig. 5B ). To disentangle the contribution of ethanol to these results, a second experiment was performed without the addition of ethanol. This resulted in a similar outcome, including increased perception of alcohol and overall appreciation.

Adding the top chemical compounds, identified as best predictors of appreciation by our model, into poorly appreciated beers results in increased appreciation from our trained panel. Results of sensory tests between base beers and those spiked with compounds identified as the best predictors by the model. A Blond and Non/Low-alcohol (0.0% ABV) base beers were brought up to 95th-percentile ethanol-normalized concentrations within each style. B For each sensory attribute, tasters indicated the more intense sample and selected the sample they preferred. The numbers above the bars correspond to the p values that indicate significant changes in perceived flavor (two-sided binomial test: alpha 0.05, n = 20 or 13).
In a last experiment, we tested whether using the model’s predictions can boost the appreciation of a non-alcoholic beer (beer 223 in Supplementary Data 1 ). Again, the addition of a mixture of predicted compounds (omitting ethanol, in this case) resulted in a significant increase in appreciation, body, ester flavor and sweetness.
Predicting flavor and consumer appreciation from chemical composition is one of the ultimate goals of sensory science. A reliable, systematic and unbiased way to link chemical profiles to flavor and food appreciation would be a significant asset to the food and beverage industry. Such tools would substantially aid in quality control and recipe development, offer an efficient and cost-effective alternative to pilot studies and consumer trials and would ultimately allow food manufacturers to produce superior, tailor-made products that better meet the demands of specific consumer groups more efficiently.
A limited set of studies have previously tried, to varying degrees of success, to predict beer flavor and beer popularity based on (a limited set of) chemical compounds and flavors 79 , 80 . Current sensitive, high-throughput technologies allow measuring an unprecedented number of chemical compounds and properties in a large set of samples, yielding a dataset that can train models that help close the gaps between chemistry and flavor, even for a complex natural product like beer. To our knowledge, no previous research gathered data at this scale (250 samples, 226 chemical parameters, 50 sensory attributes and 5 consumer scores) to disentangle and validate the chemical aspects driving beer preference using various machine-learning techniques. We find that modern machine learning models outperform conventional statistical tools, such as correlations and linear models, and can successfully predict flavor appreciation from chemical composition. This could be attributed to the natural incorporation of interactions and non-linear or discontinuous effects in machine learning models, which are not easily grasped by the linear model architecture. While linear models and partial least squares regression represent the most widespread statistical approaches in sensory science, in part because they allow interpretation 65 , 81 , 82 , modern machine learning methods allow for building better predictive models while preserving the possibility to dissect and exploit the underlying patterns. Of the 10 different models we trained, tree-based models, such as our best performing GBR, showed the best overall performance in predicting sensory responses from chemical information, outcompeting artificial neural networks. This agrees with previous reports for models trained on tabular data 83 . Our results are in line with the findings of Colantonio et al. who also identified the gradient boosting architecture as performing best at predicting appreciation and flavor (of tomatoes and blueberries, in their specific study) 26 . Importantly, besides our larger experimental scale, we were able to directly confirm our models’ predictions in vivo.
Our study confirms that flavor compound concentration does not always correlate with perception, suggesting complex interactions that are often missed by more conventional statistics and simple models. Specifically, we find that tree-based algorithms may perform best in developing models that link complex food chemistry with aroma. Furthermore, we show that massive datasets of untrained consumer reviews provide a valuable source of data, that can complement or even replace trained tasting panels, especially for appreciation and basic flavors, such as sweetness and bitterness. This holds despite biases that are known to occur in such datasets, such as price or conformity bias. Moreover, GBR models predict taste better than aroma. This is likely because taste (e.g. bitterness) often directly relates to the corresponding chemical measurements (e.g., iso-alpha acids), whereas such a link is less clear for aromas, which often result from the interplay between multiple volatile compounds. We also find that our models are best at predicting acidity and alcohol, likely because there is a direct relation between the measured chemical compounds (acids and ethanol) and the corresponding perceived sensorial attribute (acidity and alcohol), and because even untrained consumers are generally able to recognize these flavors and aromas.
The predictions of our final models, trained on review data, hold even for blind tastings with small groups of trained tasters, as demonstrated by our ability to validate specific compounds as drivers of beer flavor and appreciation. Since adding a single compound to the extent of a noticeable difference may result in an unbalanced flavor profile, we specifically tested our identified key drivers as a combination of compounds. While this approach does not allow us to validate if a particular single compound would affect flavor and/or appreciation, our experiments do show that this combination of compounds increases consumer appreciation.
It is important to stress that, while it represents an important step forward, our approach still has several major limitations. A key weakness of the GBR model architecture is that amongst co-correlating variables, the largest main effect is consistently preferred for model building. As a result, co-correlating variables often have artificially low importance scores, both for impurity and SHAP-based methods, like we observed in the comparison to the more randomized Extra Trees models. This implies that chemicals identified as key drivers of a specific sensory feature by GBR might not be the true causative compounds, but rather co-correlate with the actual causative chemical. For example, the high importance of ethyl acetate could be (partially) attributed to the total ester content, ethanol or ethyl hexanoate (rho=0.77, rho=0.72 and rho=0.68), while ethyl phenylacetate could hide the importance of prenyl isobutyrate and ethyl benzoate (rho=0.77 and rho=0.76). Expanding our GBR model to include beer style as a parameter did not yield additional power or insight. This is likely due to style-specific chemical signatures, such as iso-alpha acids and lactic acid, that implicitly convey style information to the original model, as well as the smaller sample size per style, limiting the power to uncover style-specific patterns. This can be partly attributed to the curse of dimensionality, where the high number of parameters results in the models mainly incorporating single parameter effects, rather than complex interactions such as style-dependent effects 67 . A larger number of samples may overcome some of these limitations and offer more insight into style-specific effects. On the other hand, beer style is not a rigid scientific classification, and beers within one style often differ a lot, which further complicates the analysis of style as a model factor.
Our study is limited to beers from Belgian breweries. Although these beers cover a large portion of the beer styles available globally, some beer styles and consumer patterns may be missing, while other features might be overrepresented. For example, many Belgian ales exhibit yeast-driven flavor profiles, which is reflected in the chemical drivers of appreciation discovered by this study. In future work, expanding the scope to include diverse markets and beer styles could lead to the identification of even more drivers of appreciation and better models for special niche products that were not present in our beer set.
In addition to inherent limitations of GBR models, there are also some limitations associated with studying food aroma. Even if our chemical analyses measured most of the known aroma compounds, the total number of flavor compounds in complex foods like beer is still larger than the subset we were able to measure in this study. For example, hop-derived thiols, that influence flavor at very low concentrations, are notoriously difficult to measure in a high-throughput experiment. Moreover, consumer perception remains subjective and prone to biases that are difficult to avoid. It is also important to stress that the models are still immature and that more extensive datasets will be crucial for developing more complete models in the future. Besides more samples and parameters, our dataset does not include any demographic information about the tasters. Including such data could lead to better models that grasp external factors like age and culture. Another limitation is that our set of beers consists of high-quality end-products and lacks beers that are unfit for sale, which limits the current model in accurately predicting products that are appreciated very badly. Finally, while models could be readily applied in quality control, their use in sensory science and product development is restrained by their inability to discern causal relationships. Given that the models cannot distinguish compounds that genuinely drive consumer perception from those that merely correlate, validation experiments are essential to identify true causative compounds.
Despite the inherent limitations, dissection of our models enabled us to pinpoint specific molecules as potential drivers of beer aroma and consumer appreciation, including compounds that were unexpected and would not have been identified using standard approaches. Important drivers of beer appreciation uncovered by our models include protein levels, ethyl acetate, ethyl phenyl acetate and lactic acid. Currently, many brewers already use lactic acid to acidify their brewing water and ensure optimal pH for enzymatic activity during the mashing process. Our results suggest that adding lactic acid can also improve beer appreciation, although its individual effect remains to be tested. Interestingly, ethanol appears to be unnecessary to improve beer appreciation, both for blond beer and alcohol-free beer. Given the growing consumer interest in alcohol-free beer, with a predicted annual market growth of >7% 84 , it is relevant for brewers to know what compounds can further increase consumer appreciation of these beers. Hence, our model may readily provide avenues to further improve the flavor and consumer appreciation of both alcoholic and non-alcoholic beers, which is generally considered one of the key challenges for future beer production.
Whereas we see a direct implementation of our results for the development of superior alcohol-free beverages and other food products, our study can also serve as a stepping stone for the development of novel alcohol-containing beverages. We want to echo the growing body of scientific evidence for the negative effects of alcohol consumption, both on the individual level by the mutagenic, teratogenic and carcinogenic effects of ethanol 85 , 86 , as well as the burden on society caused by alcohol abuse and addiction. We encourage the use of our results for the production of healthier, tastier products, including novel and improved beverages with lower alcohol contents. Furthermore, we strongly discourage the use of these technologies to improve the appreciation or addictive properties of harmful substances.
The present work demonstrates that despite some important remaining hurdles, combining the latest developments in chemical analyses, sensory analysis and modern machine learning methods offers exciting avenues for food chemistry and engineering. Soon, these tools may provide solutions in quality control and recipe development, as well as new approaches to sensory science and flavor research.
Beer selection
250 commercial Belgian beers were selected to cover the broad diversity of beer styles and corresponding diversity in chemical composition and aroma. See Supplementary Fig. S1 .
Chemical dataset
Sample preparation.
Beers within their expiration date were purchased from commercial retailers. Samples were prepared in biological duplicates at room temperature, unless explicitly stated otherwise. Bottle pressure was measured with a manual pressure device (Steinfurth Mess-Systeme GmbH) and used to calculate CO 2 concentration. The beer was poured through two filter papers (Macherey-Nagel, 500713032 MN 713 ¼) to remove carbon dioxide and prevent spontaneous foaming. Samples were then prepared for measurements by targeted Headspace-Gas Chromatography-Flame Ionization Detector/Flame Photometric Detector (HS-GC-FID/FPD), Headspace-Solid Phase Microextraction-Gas Chromatography-Mass Spectrometry (HS-SPME-GC-MS), colorimetric analysis, enzymatic analysis, Near-Infrared (NIR) analysis, as described in the sections below. The mean values of biological duplicates are reported for each compound.
HS-GC-FID/FPD
HS-GC-FID/FPD (Shimadzu GC 2010 Plus) was used to measure higher alcohols, acetaldehyde, esters, 4-vinyl guaicol, and sulfur compounds. Each measurement comprised 5 ml of sample pipetted into a 20 ml glass vial containing 1.75 g NaCl (VWR, 27810.295). 100 µl of 2-heptanol (Sigma-Aldrich, H3003) (internal standard) solution in ethanol (Fisher Chemical, E/0650DF/C17) was added for a final concentration of 2.44 mg/L. Samples were flushed with nitrogen for 10 s, sealed with a silicone septum, stored at −80 °C and analyzed in batches of 20.
The GC was equipped with a DB-WAXetr column (length, 30 m; internal diameter, 0.32 mm; layer thickness, 0.50 µm; Agilent Technologies, Santa Clara, CA, USA) to the FID and an HP-5 column (length, 30 m; internal diameter, 0.25 mm; layer thickness, 0.25 µm; Agilent Technologies, Santa Clara, CA, USA) to the FPD. N 2 was used as the carrier gas. Samples were incubated for 20 min at 70 °C in the headspace autosampler (Flow rate, 35 cm/s; Injection volume, 1000 µL; Injection mode, split; Combi PAL autosampler, CTC analytics, Switzerland). The injector, FID and FPD temperatures were kept at 250 °C. The GC oven temperature was first held at 50 °C for 5 min and then allowed to rise to 80 °C at a rate of 5 °C/min, followed by a second ramp of 4 °C/min until 200 °C kept for 3 min and a final ramp of (4 °C/min) until 230 °C for 1 min. Results were analyzed with the GCSolution software version 2.4 (Shimadzu, Kyoto, Japan). The GC was calibrated with a 5% EtOH solution (VWR International) containing the volatiles under study (Supplementary Table S7 ).
HS-SPME-GC-MS
HS-SPME-GC-MS (Shimadzu GCMS-QP-2010 Ultra) was used to measure additional volatile compounds, mainly comprising terpenoids and esters. Samples were analyzed by HS-SPME using a triphase DVB/Carboxen/PDMS 50/30 μm SPME fiber (Supelco Co., Bellefonte, PA, USA) followed by gas chromatography (Thermo Fisher Scientific Trace 1300 series, USA) coupled to a mass spectrometer (Thermo Fisher Scientific ISQ series MS) equipped with a TriPlus RSH autosampler. 5 ml of degassed beer sample was placed in 20 ml vials containing 1.75 g NaCl (VWR, 27810.295). 5 µl internal standard mix was added, containing 2-heptanol (1 g/L) (Sigma-Aldrich, H3003), 4-fluorobenzaldehyde (1 g/L) (Sigma-Aldrich, 128376), 2,3-hexanedione (1 g/L) (Sigma-Aldrich, 144169) and guaiacol (1 g/L) (Sigma-Aldrich, W253200) in ethanol (Fisher Chemical, E/0650DF/C17). Each sample was incubated at 60 °C in the autosampler oven with constant agitation. After 5 min equilibration, the SPME fiber was exposed to the sample headspace for 30 min. The compounds trapped on the fiber were thermally desorbed in the injection port of the chromatograph by heating the fiber for 15 min at 270 °C.
The GC-MS was equipped with a low polarity RXi-5Sil MS column (length, 20 m; internal diameter, 0.18 mm; layer thickness, 0.18 µm; Restek, Bellefonte, PA, USA). Injection was performed in splitless mode at 320 °C, a split flow of 9 ml/min, a purge flow of 5 ml/min and an open valve time of 3 min. To obtain a pulsed injection, a programmed gas flow was used whereby the helium gas flow was set at 2.7 mL/min for 0.1 min, followed by a decrease in flow of 20 ml/min to the normal 0.9 mL/min. The temperature was first held at 30 °C for 3 min and then allowed to rise to 80 °C at a rate of 7 °C/min, followed by a second ramp of 2 °C/min till 125 °C and a final ramp of 8 °C/min with a final temperature of 270 °C.
Mass acquisition range was 33 to 550 amu at a scan rate of 5 scans/s. Electron impact ionization energy was 70 eV. The interface and ion source were kept at 275 °C and 250 °C, respectively. A mix of linear n-alkanes (from C7 to C40, Supelco Co.) was injected into the GC-MS under identical conditions to serve as external retention index markers. Identification and quantification of the compounds were performed using an in-house developed R script as described in Goelen et al. and Reher et al. 87 , 88 (for package information, see Supplementary Table S8 ). Briefly, chromatograms were analyzed using AMDIS (v2.71) 89 to separate overlapping peaks and obtain pure compound spectra. The NIST MS Search software (v2.0 g) in combination with the NIST2017, FFNSC3 and Adams4 libraries were used to manually identify the empirical spectra, taking into account the expected retention time. After background subtraction and correcting for retention time shifts between samples run on different days based on alkane ladders, compound elution profiles were extracted and integrated using a file with 284 target compounds of interest, which were either recovered in our identified AMDIS list of spectra or were known to occur in beer. Compound elution profiles were estimated for every peak in every chromatogram over a time-restricted window using weighted non-negative least square analysis after which peak areas were integrated 87 , 88 . Batch effect correction was performed by normalizing against the most stable internal standard compound, 4-fluorobenzaldehyde. Out of all 284 target compounds that were analyzed, 167 were visually judged to have reliable elution profiles and were used for final analysis.
Discrete photometric and enzymatic analysis
Discrete photometric and enzymatic analysis (Thermo Scientific TM Gallery TM Plus Beermaster Discrete Analyzer) was used to measure acetic acid, ammonia, beta-glucan, iso-alpha acids, color, sugars, glycerol, iron, pH, protein, and sulfite. 2 ml of sample volume was used for the analyses. Information regarding the reagents and standard solutions used for analyses and calibrations is included in Supplementary Table S7 and Supplementary Table S9 .
NIR analyses
NIR analysis (Anton Paar Alcolyzer Beer ME System) was used to measure ethanol. Measurements comprised 50 ml of sample, and a 10% EtOH solution was used for calibration.
Correlation calculations
Pairwise Spearman Rank correlations were calculated between all chemical properties.
Sensory dataset
Trained panel.
Our trained tasting panel consisted of volunteers who gave prior verbal informed consent. All compounds used for the validation experiment were of food-grade quality. The tasting sessions were approved by the Social and Societal Ethics Committee of the KU Leuven (G-2022-5677-R2(MAR)). All online reviewers agreed to the Terms and Conditions of the RateBeer website.
Sensory analysis was performed according to the American Society of Brewing Chemists (ASBC) Sensory Analysis Methods 90 . 30 volunteers were screened through a series of triangle tests. The sixteen most sensitive and consistent tasters were retained as taste panel members. The resulting panel was diverse in age [22–42, mean: 29], sex [56% male] and nationality [7 different countries]. The panel developed a consensus vocabulary to describe beer aroma, taste and mouthfeel. Panelists were trained to identify and score 50 different attributes, using a 7-point scale to rate attributes’ intensity. The scoring sheet is included as Supplementary Data 3 . Sensory assessments took place between 10–12 a.m. The beers were served in black-colored glasses. Per session, between 5 and 12 beers of the same style were tasted at 12 °C to 16 °C. Two reference beers were added to each set and indicated as ‘Reference 1 & 2’, allowing panel members to calibrate their ratings. Not all panelists were present at every tasting. Scores were scaled by standard deviation and mean-centered per taster. Values are represented as z-scores and clustered by Euclidean distance. Pairwise Spearman correlations were calculated between taste and aroma sensory attributes. Panel consistency was evaluated by repeating samples on different sessions and performing ANOVA to identify differences, using the ‘stats’ package (v4.2.2) in R (for package information, see Supplementary Table S8 ).
Online reviews from a public database
The ‘scrapy’ package in Python (v3.6) (for package information, see Supplementary Table S8 ). was used to collect 232,288 online reviews (mean=922, min=6, max=5343) from RateBeer, an online beer review database. Each review entry comprised 5 numerical scores (appearance, aroma, taste, palate and overall quality) and an optional review text. The total number of reviews per reviewer was collected separately. Numerical scores were scaled and centered per rater, and mean scores were calculated per beer.
For the review texts, the language was estimated using the packages ‘langdetect’ and ‘langid’ in Python. Reviews that were classified as English by both packages were kept. Reviewers with fewer than 100 entries overall were discarded. 181,025 reviews from >6000 reviewers from >40 countries remained. Text processing was done using the ‘nltk’ package in Python. Texts were corrected for slang and misspellings; proper nouns and rare words that are relevant to the beer context were specified and kept as-is (‘Chimay’,’Lambic’, etc.). A dictionary of semantically similar sensorial terms, for example ‘floral’ and ‘flower’, was created and collapsed together into one term. Words were stemmed and lemmatized to avoid identifying words such as ‘acid’ and ‘acidity’ as separate terms. Numbers and punctuation were removed.
Sentences from up to 50 randomly chosen reviews per beer were manually categorized according to the aspect of beer they describe (appearance, aroma, taste, palate, overall quality—not to be confused with the 5 numerical scores described above) or flagged as irrelevant if they contained no useful information. If a beer contained fewer than 50 reviews, all reviews were manually classified. This labeled data set was used to train a model that classified the rest of the sentences for all beers 91 . Sentences describing taste and aroma were extracted, and term frequency–inverse document frequency (TFIDF) was implemented to calculate enrichment scores for sensorial words per beer.
The sex of the tasting subject was not considered when building our sensory database. Instead, results from different panelists were averaged, both for our trained panel (56% male, 44% female) and the RateBeer reviews (70% male, 30% female for RateBeer as a whole).
Beer price collection and processing
Beer prices were collected from the following stores: Colruyt, Delhaize, Total Wine, BeerHawk, The Belgian Beer Shop, The Belgian Shop, and Beer of Belgium. Where applicable, prices were converted to Euros and normalized per liter. Spearman correlations were calculated between these prices and mean overall appreciation scores from RateBeer and the taste panel, respectively.
Pairwise Spearman Rank correlations were calculated between all sensory properties.
Machine learning models
Predictive modeling of sensory profiles from chemical data.
Regression models were constructed to predict (a) trained panel scores for beer flavors and quality from beer chemical profiles and (b) public reviews’ appreciation scores from beer chemical profiles. Z-scores were used to represent sensory attributes in both data sets. Chemical properties with log-normal distributions (Shapiro-Wilk test, p < 0.05 ) were log-transformed. Missing chemical measurements (0.1% of all data) were replaced with mean values per attribute. Observations from 250 beers were randomly separated into a training set (70%, 175 beers) and a test set (30%, 75 beers), stratified per beer style. Chemical measurements (p = 231) were normalized based on the training set average and standard deviation. In total, three linear regression-based models: linear regression with first-order interaction terms (LR), lasso regression with first-order interaction terms (Lasso) and partial least squares regression (PLSR); five decision tree models, Adaboost regressor (ABR), Extra Trees (ET), Gradient Boosting regressor (GBR), Random Forest (RF) and XGBoost regressor (XGBR); one support vector machine model (SVR) and one artificial neural network model (ANN) were trained. The models were implemented using the ‘scikit-learn’ package (v1.2.2) and ‘xgboost’ package (v1.7.3) in Python (v3.9.16). Models were trained, and hyperparameters optimized, using five-fold cross-validated grid search with the coefficient of determination (R 2 ) as the evaluation metric. The ANN (scikit-learn’s MLPRegressor) was optimized using Bayesian Tree-Structured Parzen Estimator optimization with the ‘Optuna’ Python package (v3.2.0). Individual models were trained per attribute, and a multi-output model was trained on all attributes simultaneously.
Model dissection
GBR was found to outperform other methods, resulting in models with the highest average R 2 values in both trained panel and public review data sets. Impurity-based rankings of the most important predictors for each predicted sensorial trait were obtained using the ‘scikit-learn’ package. To observe the relationships between these chemical properties and their predicted targets, partial dependence plots (PDP) were constructed for the six most important predictors of consumer appreciation 74 , 75 .
The ‘SHAP’ package in Python (v0.41.0) was implemented to provide an alternative ranking of predictor importance and to visualize the predictors’ effects as a function of their concentration 68 .
Validation of causal chemical properties
To validate the effects of the most important model features on predicted sensory attributes, beers were spiked with the chemical compounds identified by the models and descriptive sensory analyses were carried out according to the American Society of Brewing Chemists (ASBC) protocol 90 .
Compound spiking was done 30 min before tasting. Compounds were spiked into fresh beer bottles, that were immediately resealed and inverted three times. Fresh bottles of beer were opened for the same duration, resealed, and inverted thrice, to serve as controls. Pairs of spiked samples and controls were served simultaneously, chilled and in dark glasses as outlined in the Trained panel section above. Tasters were instructed to select the glass with the higher flavor intensity for each attribute (directional difference test 92 ) and to select the glass they prefer.
The final concentration after spiking was equal to the within-style average, after normalizing by ethanol concentration. This was done to ensure balanced flavor profiles in the final spiked beer. The same methods were applied to improve a non-alcoholic beer. Compounds were the following: ethyl acetate (Merck KGaA, W241415), ethyl hexanoate (Merck KGaA, W243906), isoamyl acetate (Merck KGaA, W205508), phenethyl acetate (Merck KGaA, W285706), ethanol (96%, Colruyt), glycerol (Merck KGaA, W252506), lactic acid (Merck KGaA, 261106).
Significant differences in preference or perceived intensity were determined by performing the two-sided binomial test on each attribute.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data that support the findings of this work are available in the Supplementary Data files and have been deposited to Zenodo under accession code 10653704 93 . The RateBeer scores data are under restricted access, they are not publicly available as they are property of RateBeer (ZX Ventures, USA). Access can be obtained from the authors upon reasonable request and with permission of RateBeer (ZX Ventures, USA). Source data are provided with this paper.
Code availability
The code for training the machine learning models, analyzing the models, and generating the figures has been deposited to Zenodo under accession code 10653704 93 .
Tieman, D. et al. A chemical genetic roadmap to improved tomato flavor. Science 355 , 391–394 (2017).
Article ADS CAS PubMed Google Scholar
Plutowska, B. & Wardencki, W. Application of gas chromatography–olfactometry (GC–O) in analysis and quality assessment of alcoholic beverages – A review. Food Chem. 107 , 449–463 (2008).
Article CAS Google Scholar
Legin, A., Rudnitskaya, A., Seleznev, B. & Vlasov, Y. Electronic tongue for quality assessment of ethanol, vodka and eau-de-vie. Anal. Chim. Acta 534 , 129–135 (2005).
Loutfi, A., Coradeschi, S., Mani, G. K., Shankar, P. & Rayappan, J. B. B. Electronic noses for food quality: A review. J. Food Eng. 144 , 103–111 (2015).
Ahn, Y.-Y., Ahnert, S. E., Bagrow, J. P. & Barabási, A.-L. Flavor network and the principles of food pairing. Sci. Rep. 1 , 196 (2011).
Article CAS PubMed PubMed Central Google Scholar
Bartoshuk, L. M. & Klee, H. J. Better fruits and vegetables through sensory analysis. Curr. Biol. 23 , R374–R378 (2013).
Article CAS PubMed Google Scholar
Piggott, J. R. Design questions in sensory and consumer science. Food Qual. Prefer. 3293 , 217–220 (1995).
Article Google Scholar
Kermit, M. & Lengard, V. Assessing the performance of a sensory panel-panellist monitoring and tracking. J. Chemom. 19 , 154–161 (2005).
Cook, D. J., Hollowood, T. A., Linforth, R. S. T. & Taylor, A. J. Correlating instrumental measurements of texture and flavour release with human perception. Int. J. Food Sci. Technol. 40 , 631–641 (2005).
Chinchanachokchai, S., Thontirawong, P. & Chinchanachokchai, P. A tale of two recommender systems: The moderating role of consumer expertise on artificial intelligence based product recommendations. J. Retail. Consum. Serv. 61 , 1–12 (2021).
Ross, C. F. Sensory science at the human-machine interface. Trends Food Sci. Technol. 20 , 63–72 (2009).
Chambers, E. IV & Koppel, K. Associations of volatile compounds with sensory aroma and flavor: The complex nature of flavor. Molecules 18 , 4887–4905 (2013).
Pinu, F. R. Metabolomics—The new frontier in food safety and quality research. Food Res. Int. 72 , 80–81 (2015).
Danezis, G. P., Tsagkaris, A. S., Brusic, V. & Georgiou, C. A. Food authentication: state of the art and prospects. Curr. Opin. Food Sci. 10 , 22–31 (2016).
Shepherd, G. M. Smell images and the flavour system in the human brain. Nature 444 , 316–321 (2006).
Meilgaard, M. C. Prediction of flavor differences between beers from their chemical composition. J. Agric. Food Chem. 30 , 1009–1017 (1982).
Xu, L. et al. Widespread receptor-driven modulation in peripheral olfactory coding. Science 368 , eaaz5390 (2020).
Kupferschmidt, K. Following the flavor. Science 340 , 808–809 (2013).
Billesbølle, C. B. et al. Structural basis of odorant recognition by a human odorant receptor. Nature 615 , 742–749 (2023).
Article ADS PubMed PubMed Central Google Scholar
Smith, B. Perspective: Complexities of flavour. Nature 486 , S6–S6 (2012).
Pfister, P. et al. Odorant receptor inhibition is fundamental to odor encoding. Curr. Biol. 30 , 2574–2587 (2020).
Moskowitz, H. W., Kumaraiah, V., Sharma, K. N., Jacobs, H. L. & Sharma, S. D. Cross-cultural differences in simple taste preferences. Science 190 , 1217–1218 (1975).
Eriksson, N. et al. A genetic variant near olfactory receptor genes influences cilantro preference. Flavour 1 , 22 (2012).
Ferdenzi, C. et al. Variability of affective responses to odors: Culture, gender, and olfactory knowledge. Chem. Senses 38 , 175–186 (2013).
Article PubMed Google Scholar
Lawless, H. T. & Heymann, H. Sensory evaluation of food: Principles and practices. (Springer, New York, NY). https://doi.org/10.1007/978-1-4419-6488-5 (2010).
Colantonio, V. et al. Metabolomic selection for enhanced fruit flavor. Proc. Natl. Acad. Sci. 119 , e2115865119 (2022).
Fritz, F., Preissner, R. & Banerjee, P. VirtualTaste: a web server for the prediction of organoleptic properties of chemical compounds. Nucleic Acids Res 49 , W679–W684 (2021).
Tuwani, R., Wadhwa, S. & Bagler, G. BitterSweet: Building machine learning models for predicting the bitter and sweet taste of small molecules. Sci. Rep. 9 , 1–13 (2019).
Dagan-Wiener, A. et al. Bitter or not? BitterPredict, a tool for predicting taste from chemical structure. Sci. Rep. 7 , 1–13 (2017).
Pallante, L. et al. Toward a general and interpretable umami taste predictor using a multi-objective machine learning approach. Sci. Rep. 12 , 1–11 (2022).
Malavolta, M. et al. A survey on computational taste predictors. Eur. Food Res. Technol. 248 , 2215–2235 (2022).
Lee, B. K. et al. A principal odor map unifies diverse tasks in olfactory perception. Science 381 , 999–1006 (2023).
Mayhew, E. J. et al. Transport features predict if a molecule is odorous. Proc. Natl. Acad. Sci. 119 , e2116576119 (2022).
Niu, Y. et al. Sensory evaluation of the synergism among ester odorants in light aroma-type liquor by odor threshold, aroma intensity and flash GC electronic nose. Food Res. Int. 113 , 102–114 (2018).
Yu, P., Low, M. Y. & Zhou, W. Design of experiments and regression modelling in food flavour and sensory analysis: A review. Trends Food Sci. Technol. 71 , 202–215 (2018).
Oladokun, O. et al. The impact of hop bitter acid and polyphenol profiles on the perceived bitterness of beer. Food Chem. 205 , 212–220 (2016).
Linforth, R., Cabannes, M., Hewson, L., Yang, N. & Taylor, A. Effect of fat content on flavor delivery during consumption: An in vivo model. J. Agric. Food Chem. 58 , 6905–6911 (2010).
Guo, S., Na Jom, K. & Ge, Y. Influence of roasting condition on flavor profile of sunflower seeds: A flavoromics approach. Sci. Rep. 9 , 11295 (2019).
Ren, Q. et al. The changes of microbial community and flavor compound in the fermentation process of Chinese rice wine using Fagopyrum tataricum grain as feedstock. Sci. Rep. 9 , 3365 (2019).
Hastie, T., Friedman, J. & Tibshirani, R. The Elements of Statistical Learning. (Springer, New York, NY). https://doi.org/10.1007/978-0-387-21606-5 (2001).
Dietz, C., Cook, D., Huismann, M., Wilson, C. & Ford, R. The multisensory perception of hop essential oil: a review. J. Inst. Brew. 126 , 320–342 (2020).
CAS Google Scholar
Roncoroni, Miguel & Verstrepen, Kevin Joan. Belgian Beer: Tested and Tasted. (Lannoo, 2018).
Meilgaard, M. Flavor chemistry of beer: Part II: Flavor and threshold of 239 aroma volatiles. in (1975).
Bokulich, N. A. & Bamforth, C. W. The microbiology of malting and brewing. Microbiol. Mol. Biol. Rev. MMBR 77 , 157–172 (2013).
Dzialo, M. C., Park, R., Steensels, J., Lievens, B. & Verstrepen, K. J. Physiology, ecology and industrial applications of aroma formation in yeast. FEMS Microbiol. Rev. 41 , S95–S128 (2017).
Article PubMed PubMed Central Google Scholar
Datta, A. et al. Computer-aided food engineering. Nat. Food 3 , 894–904 (2022).
American Society of Brewing Chemists. Beer Methods. (American Society of Brewing Chemists, St. Paul, MN, U.S.A.).
Olaniran, A. O., Hiralal, L., Mokoena, M. P. & Pillay, B. Flavour-active volatile compounds in beer: production, regulation and control. J. Inst. Brew. 123 , 13–23 (2017).
Verstrepen, K. J. et al. Flavor-active esters: Adding fruitiness to beer. J. Biosci. Bioeng. 96 , 110–118 (2003).
Meilgaard, M. C. Flavour chemistry of beer. part I: flavour interaction between principal volatiles. Master Brew. Assoc. Am. Tech. Q 12 , 107–117 (1975).
Briggs, D. E., Boulton, C. A., Brookes, P. A. & Stevens, R. Brewing 227–254. (Woodhead Publishing). https://doi.org/10.1533/9781855739062.227 (2004).
Bossaert, S., Crauwels, S., De Rouck, G. & Lievens, B. The power of sour - A review: Old traditions, new opportunities. BrewingScience 72 , 78–88 (2019).
Google Scholar
Verstrepen, K. J. et al. Flavor active esters: Adding fruitiness to beer. J. Biosci. Bioeng. 96 , 110–118 (2003).
Snauwaert, I. et al. Microbial diversity and metabolite composition of Belgian red-brown acidic ales. Int. J. Food Microbiol. 221 , 1–11 (2016).
Spitaels, F. et al. The microbial diversity of traditional spontaneously fermented lambic beer. PLoS ONE 9 , e95384 (2014).
Blanco, C. A., Andrés-Iglesias, C. & Montero, O. Low-alcohol Beers: Flavor Compounds, Defects, and Improvement Strategies. Crit. Rev. Food Sci. Nutr. 56 , 1379–1388 (2016).
Jackowski, M. & Trusek, A. Non-Alcohol. beer Prod. – Overv. 20 , 32–38 (2018).
Takoi, K. et al. The contribution of geraniol metabolism to the citrus flavour of beer: Synergy of geraniol and β-citronellol under coexistence with excess linalool. J. Inst. Brew. 116 , 251–260 (2010).
Kroeze, J. H. & Bartoshuk, L. M. Bitterness suppression as revealed by split-tongue taste stimulation in humans. Physiol. Behav. 35 , 779–783 (1985).
Mennella, J. A. et al. A spoonful of sugar helps the medicine go down”: Bitter masking bysucrose among children and adults. Chem. Senses 40 , 17–25 (2015).
Wietstock, P., Kunz, T., Perreira, F. & Methner, F.-J. Metal chelation behavior of hop acids in buffered model systems. BrewingScience 69 , 56–63 (2016).
Sancho, D., Blanco, C. A., Caballero, I. & Pascual, A. Free iron in pale, dark and alcohol-free commercial lager beers. J. Sci. Food Agric. 91 , 1142–1147 (2011).
Rodrigues, H. & Parr, W. V. Contribution of cross-cultural studies to understanding wine appreciation: A review. Food Res. Int. 115 , 251–258 (2019).
Korneva, E. & Blockeel, H. Towards better evaluation of multi-target regression models. in ECML PKDD 2020 Workshops (eds. Koprinska, I. et al.) 353–362 (Springer International Publishing, Cham, 2020). https://doi.org/10.1007/978-3-030-65965-3_23 .
Gastón Ares. Mathematical and Statistical Methods in Food Science and Technology. (Wiley, 2013).
Grinsztajn, L., Oyallon, E. & Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? Preprint at http://arxiv.org/abs/2207.08815 (2022).
Gries, S. T. Statistics for Linguistics with R: A Practical Introduction. in Statistics for Linguistics with R (De Gruyter Mouton, 2021). https://doi.org/10.1515/9783110718256 .
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2 , 56–67 (2020).
Ickes, C. M. & Cadwallader, K. R. Effects of ethanol on flavor perception in alcoholic beverages. Chemosens. Percept. 10 , 119–134 (2017).
Kato, M. et al. Influence of high molecular weight polypeptides on the mouthfeel of commercial beer. J. Inst. Brew. 127 , 27–40 (2021).
Wauters, R. et al. Novel Saccharomyces cerevisiae variants slow down the accumulation of staling aldehydes and improve beer shelf-life. Food Chem. 398 , 1–11 (2023).
Li, H., Jia, S. & Zhang, W. Rapid determination of low-level sulfur compounds in beer by headspace gas chromatography with a pulsed flame photometric detector. J. Am. Soc. Brew. Chem. 66 , 188–191 (2008).
Dercksen, A., Laurens, J., Torline, P., Axcell, B. C. & Rohwer, E. Quantitative analysis of volatile sulfur compounds in beer using a membrane extraction interface. J. Am. Soc. Brew. Chem. 54 , 228–233 (1996).
Molnar, C. Interpretable Machine Learning: A Guide for Making Black-Box Models Interpretable. (2020).
Zhao, Q. & Hastie, T. Causal interpretations of black-box models. J. Bus. Econ. Stat. Publ. Am. Stat. Assoc. 39 , 272–281 (2019).
Article MathSciNet Google Scholar
Hastie, T., Tibshirani, R. & Friedman, J. The Elements of Statistical Learning. (Springer, 2019).
Labrado, D. et al. Identification by NMR of key compounds present in beer distillates and residual phases after dealcoholization by vacuum distillation. J. Sci. Food Agric. 100 , 3971–3978 (2020).
Lusk, L. T., Kay, S. B., Porubcan, A. & Ryder, D. S. Key olfactory cues for beer oxidation. J. Am. Soc. Brew. Chem. 70 , 257–261 (2012).
Gonzalez Viejo, C., Torrico, D. D., Dunshea, F. R. & Fuentes, S. Development of artificial neural network models to assess beer acceptability based on sensory properties using a robotic pourer: A comparative model approach to achieve an artificial intelligence system. Beverages 5 , 33 (2019).
Gonzalez Viejo, C., Fuentes, S., Torrico, D. D., Godbole, A. & Dunshea, F. R. Chemical characterization of aromas in beer and their effect on consumers liking. Food Chem. 293 , 479–485 (2019).
Gilbert, J. L. et al. Identifying breeding priorities for blueberry flavor using biochemical, sensory, and genotype by environment analyses. PLOS ONE 10 , 1–21 (2015).
Goulet, C. et al. Role of an esterase in flavor volatile variation within the tomato clade. Proc. Natl. Acad. Sci. 109 , 19009–19014 (2012).
Article ADS CAS PubMed PubMed Central Google Scholar
Borisov, V. et al. Deep Neural Networks and Tabular Data: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 1–21 https://doi.org/10.1109/TNNLS.2022.3229161 (2022).
Statista. Statista Consumer Market Outlook: Beer - Worldwide.
Seitz, H. K. & Stickel, F. Molecular mechanisms of alcoholmediated carcinogenesis. Nat. Rev. Cancer 7 , 599–612 (2007).
Voordeckers, K. et al. Ethanol exposure increases mutation rate through error-prone polymerases. Nat. Commun. 11 , 3664 (2020).
Goelen, T. et al. Bacterial phylogeny predicts volatile organic compound composition and olfactory response of an aphid parasitoid. Oikos 129 , 1415–1428 (2020).
Article ADS Google Scholar
Reher, T. et al. Evaluation of hop (Humulus lupulus) as a repellent for the management of Drosophila suzukii. Crop Prot. 124 , 104839 (2019).
Stein, S. E. An integrated method for spectrum extraction and compound identification from gas chromatography/mass spectrometry data. J. Am. Soc. Mass Spectrom. 10 , 770–781 (1999).
American Society of Brewing Chemists. Sensory Analysis Methods. (American Society of Brewing Chemists, St. Paul, MN, U.S.A., 1992).
McAuley, J., Leskovec, J. & Jurafsky, D. Learning Attitudes and Attributes from Multi-Aspect Reviews. Preprint at https://doi.org/10.48550/arXiv.1210.3926 (2012).
Meilgaard, M. C., Carr, B. T. & Carr, B. T. Sensory Evaluation Techniques. (CRC Press, Boca Raton). https://doi.org/10.1201/b16452 (2014).
Schreurs, M. et al. Data from: Predicting and improving complex beer flavor through machine learning. Zenodo https://doi.org/10.5281/zenodo.10653704 (2024).
Download references
Acknowledgements
We thank all lab members for their discussions and thank all tasting panel members for their contributions. Special thanks go out to Dr. Karin Voordeckers for her tremendous help in proofreading and improving the manuscript. M.S. was supported by a Baillet-Latour fellowship, L.C. acknowledges financial support from KU Leuven (C16/17/006), F.A.T. was supported by a PhD fellowship from FWO (1S08821N). Research in the lab of K.J.V. is supported by KU Leuven, FWO, VIB, VLAIO and the Brewing Science Serves Health Fund. Research in the lab of T.W. is supported by FWO (G.0A51.15) and KU Leuven (C16/17/006).
Author information
These authors contributed equally: Michiel Schreurs, Supinya Piampongsant, Miguel Roncoroni.
Authors and Affiliations
VIB—KU Leuven Center for Microbiology, Gaston Geenslaan 1, B-3001, Leuven, Belgium
Michiel Schreurs, Supinya Piampongsant, Miguel Roncoroni, Lloyd Cool, Beatriz Herrera-Malaver, Florian A. Theßeling & Kevin J. Verstrepen
CMPG Laboratory of Genetics and Genomics, KU Leuven, Gaston Geenslaan 1, B-3001, Leuven, Belgium
Leuven Institute for Beer Research (LIBR), Gaston Geenslaan 1, B-3001, Leuven, Belgium
Laboratory of Socioecology and Social Evolution, KU Leuven, Naamsestraat 59, B-3000, Leuven, Belgium
Lloyd Cool, Christophe Vanderaa & Tom Wenseleers
VIB Bioinformatics Core, VIB, Rijvisschestraat 120, B-9052, Ghent, Belgium
Łukasz Kreft & Alexander Botzki
AB InBev SA/NV, Brouwerijplein 1, B-3000, Leuven, Belgium
Philippe Malcorps & Luk Daenen
You can also search for this author in PubMed Google Scholar
Contributions
S.P., M.S. and K.J.V. conceived the experiments. S.P., M.S. and K.J.V. designed the experiments. S.P., M.S., M.R., B.H. and F.A.T. performed the experiments. S.P., M.S., L.C., C.V., L.K., A.B., P.M., L.D., T.W. and K.J.V. contributed analysis ideas. S.P., M.S., L.C., C.V., T.W. and K.J.V. analyzed the data. All authors contributed to writing the manuscript.
Corresponding author
Correspondence to Kevin J. Verstrepen .
Ethics declarations
Competing interests.
K.J.V. is affiliated with bar.on. The other authors declare no competing interests.
Peer review
Peer review information.
Nature Communications thanks Florian Bauer, Andrew John Macintosh and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information, peer review file, description of additional supplementary files, supplementary data 1, supplementary data 2, supplementary data 3, supplementary data 4, supplementary data 5, supplementary data 6, supplementary data 7, reporting summary, source data, source data, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Schreurs, M., Piampongsant, S., Roncoroni, M. et al. Predicting and improving complex beer flavor through machine learning. Nat Commun 15 , 2368 (2024). https://doi.org/10.1038/s41467-024-46346-0
Download citation
Received : 30 October 2023
Accepted : 21 February 2024
Published : 26 March 2024
DOI : https://doi.org/10.1038/s41467-024-46346-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Translational Research newsletter — top stories in biotechnology, drug discovery and pharma.

Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
- Research paper
- Research Paper Format | APA, MLA, & Chicago Templates
Research Paper Format | APA, MLA, & Chicago Templates
Published on November 19, 2022 by Jack Caulfield . Revised on January 20, 2023.
The formatting of a research paper is different depending on which style guide you’re following. In addition to citations , APA, MLA, and Chicago provide format guidelines for things like font choices, page layout, format of headings and the format of the reference page.
Scribbr offers free Microsoft Word templates for the most common formats. Simply download and get started on your paper.
APA | MLA | Chicago author-date | Chicago notes & bibliography
- Generate an automatic table of contents
- Generate a list of tables and figures
- Ensure consistent paragraph formatting
- Insert page numbering
Instantly correct all language mistakes in your text
Upload your document to correct all your mistakes in minutes

Table of contents
Formatting an apa paper, formatting an mla paper, formatting a chicago paper, frequently asked questions about research paper formatting.
The main guidelines for formatting a paper in APA Style are as follows:
- Use a standard font like 12 pt Times New Roman or 11 pt Arial.
- Set 1 inch page margins.
- Apply double line spacing.
- If submitting for publication, insert a APA running head on every page.
- Indent every new paragraph ½ inch.
Watch the video below for a quick guide to setting up the format in Google Docs.
The image below shows how to format an APA Style title page for a student paper.

Running head
If you are submitting a paper for publication, APA requires you to include a running head on each page. The image below shows you how this should be formatted.

For student papers, no running head is required unless you have been instructed to include one.
APA provides guidelines for formatting up to five levels of heading within your paper. Level 1 headings are the most general, level 5 the most specific.

Reference page
APA Style citation requires (author-date) APA in-text citations throughout the text and an APA Style reference page at the end. The image below shows how the reference page should be formatted.

Note that the format of reference entries is different depending on the source type. You can easily create your citations and reference list using the free APA Citation Generator.
Generate APA citations for free
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

The main guidelines for writing an MLA style paper are as follows:
- Use an easily readable font like 12 pt Times New Roman.
- Use title case capitalization for headings .
Check out the video below to see how to set up the format in Google Docs.
On the first page of an MLA paper, a heading appears above your title, featuring some key information:
- Your full name
- Your instructor’s or supervisor’s name
- The course name or number
- The due date of the assignment

Page header
A header appears at the top of each page in your paper, including your surname and the page number.

Works Cited page
MLA in-text citations appear wherever you refer to a source in your text. The MLA Works Cited page appears at the end of your text, listing all the sources used. It is formatted as shown below.

You can easily create your MLA citations and save your Works Cited list with the free MLA Citation Generator.
Generate MLA citations for free
The main guidelines for writing a paper in Chicago style (also known as Turabian style) are:
- Use a standard font like 12 pt Times New Roman.
- Use 1 inch margins or larger.
- Place page numbers in the top right or bottom center.

Chicago doesn’t require a title page , but if you want to include one, Turabian (based on Chicago) presents some guidelines. Lay out the title page as shown below.

Bibliography or reference list
Chicago offers two citation styles : author-date citations plus a reference list, or footnote citations plus a bibliography. Choose one style or the other and use it consistently.
The reference list or bibliography appears at the end of the paper. Both styles present this page similarly in terms of formatting, as shown below.

To format a paper in APA Style , follow these guidelines:
- Use a standard font like 12 pt Times New Roman or 11 pt Arial
- Set 1 inch page margins
- Apply double line spacing
- Include a title page
- If submitting for publication, insert a running head on every page
- Indent every new paragraph ½ inch
- Apply APA heading styles
- Cite your sources with APA in-text citations
- List all sources cited on a reference page at the end
The main guidelines for formatting a paper in MLA style are as follows:
- Use an easily readable font like 12 pt Times New Roman
- Include a four-line MLA heading on the first page
- Center the paper’s title
- Use title case capitalization for headings
- Cite your sources with MLA in-text citations
- List all sources cited on a Works Cited page at the end
The main guidelines for formatting a paper in Chicago style are to:
- Use a standard font like 12 pt Times New Roman
- Use 1 inch margins or larger
- Place page numbers in the top right or bottom center
- Cite your sources with author-date citations or Chicago footnotes
- Include a bibliography or reference list
To automatically generate accurate Chicago references, you can use Scribbr’s free Chicago reference generator .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Caulfield, J. (2023, January 20). Research Paper Format | APA, MLA, & Chicago Templates. Scribbr. Retrieved March 25, 2024, from https://www.scribbr.com/research-paper/research-paper-format/
Is this article helpful?

Jack Caulfield
Other students also liked, apa format for academic papers and essays, mla format for academic papers and essays, chicago style format for papers | requirements & examples, "i thought ai proofreading was useless but..".
I've been using Scribbr for years now and I know it's a service that won't disappoint. It does a good job spotting mistakes”
- Skip to main content
- Keyboard shortcuts for audio player
Your Health
- Treatments & Tests
- Health Inc.
- Public Health
Watching a solar eclipse without the right filters can cause eye damage. Here's why

Nell Greenfieldboyce

A woman watches an annular solar eclipse on October 14, 2023 using special solar filter glasses at the National Autonomous University of Mexico. Carlos Tischler/ Eyepix Group/Future Publishing via Getty Images hide caption
A woman watches an annular solar eclipse on October 14, 2023 using special solar filter glasses at the National Autonomous University of Mexico.
On April 8, as millions of people try to watch a solar eclipse sweep over North America, eye doctors across the United States will be on high alert.
That's because, while a solar eclipse is a stunning celestial event, it can also be dangerous. Looking at any part of the exposed sun without the right kind of protection can permanently injure the eye's light-sensitive retina.
And if past eclipses are prologue, it's likely that some eclipse-gazers will show up at doctors' offices with significant eye damage.

For April's eclipse, going from 'meh' to 'OMG' might mean just driving across town
In 2017, during the solar eclipse seen across the United States, that happened to multiple people despite abundant media coverage about the danger of looking at the sun when it is anything less than fully and completely covered by the moon.
In New York City, for example, one young woman came to the New York Eye and Ear Infirmary of Mount Sinai, complaining of blurred and distorted vision.
She had peeked up at the crescent sun without eyewear at first, then looked at it longer while wearing what she thought were appropriate eclipse glasses.

Everything you need to know about solar eclipse glasses before April 8
"But the problem was she was handed glasses from someone else," says ophthalmologist Avnish Deobhakta , so she didn't know if the eyewear really met safety standards .
Doctors found a permanent, crescent-shaped wound on her retina; there's no treatment for that kind of injury, which is similar to the kind of light-induced damage caused by pointing a laser into the eye.
Other eclipse-related eye injuries were reported in California and Utah .
Given that more than 150 million people directly viewed either a partial eclipse or a total solar eclipse, however, the number who suffered eye problems may seem relatively small.

Plan to watch the eclipse from a wild mountain summit? Be ready for harsh conditions
"We've got less than 100 cases across Canada and the U.S.," says Ralph Chou , an eclipse eye safety expert with the University of Waterloo in Canada.
But no one knows for sure how many people damaged their eyes in 2017, he says, because not every case gets written up for a medical journal, and people may not seek help for less severe vision troubles.
"A lot of them, if they actually happened, were probably relatively minor and, you know, they resolved on their own within weeks or months," says Chou, who says that about half of those who experience significant blurring on the day after an eclipse will recover almost completely.
Some of that recovery may just be the brain learning to compensate and "fill in" the blanks, says Deobhakta, who notes that "there's two eyes, and often there's asymmetric injury. Your brain kind of gets used to it."

The eclipse gives astronomy clubs an opportunity to shine
He notes that there are ways to enjoy the eclipse without looking up at all; everyday household objects like colanders allow you to create pinhole projectors that let you watch an image of the sun becoming more and more crescent-shaped.
"My advice is to not look at the sun, because you may not realize that it is affecting your retina. It does not hurt. It doesn't burn at the time. It's not as if you feel it," says Deobhakta.
If you do choose to look up at the sun when it is partially eclipsed, says Deobhakta, "make sure you really are sure that you have the standard glasses that have the right filters."
The American Astronomical Society has a list of vetted suppliers .

Will you be celebrating the solar eclipse? NPR wants to hear from you
If you still have reliable eclipse viewers from 2017 that are in good condition, those should still work fine, says Chou.
He notes that eclipse viewers usually have a "best by" date on them, but that is to satisfy European regulations related to personal protective equipment.
"It's essentially meaningless because the filters do not age," says Chou. "If you've taken good care of the viewers from 2017, they haven't been crushed or folded or whatever to damage the mountings, then they're perfectly safe to use for this eclipse."
Despite the warnings, some people try to glimpse the partially-eclipsed sun without eye protection, thinking that a quick look won't cause any harm. While an initial glance at the sun may not cause lasting damage, says Chou, repeated peeks do add up.
"At some point, you may tip yourself over the critical threshold," says Chou. "Unfortunately, you don't realize that until far too late."
The eye damage only becomes apparent hours after it occurs. Typically, people wake up the morning after observing an eclipse and see a spot of extreme fuzziness in the center of their field of vision.
There is one time when it's safe to look up at the sun with the naked eye, experts say, and that's when the sun is totally covered by the moon.
This eclipse phase is only visible from the so-called " path of totality ," a stretch of land from Texas to Maine. And the experience of totality doesn't last long — up to four and a half minutes or so, depending on your location.
When the sun is 100% obscured, the sky abruptly darkens and the once-bright sun becomes a dark circle surrounded by a ghostly white ring called the corona.
If people wear super-dark eclipse eyewear during these dramatic moments, they'll miss the whole show.
"People get so concerned to not hurt their eyes, which of course is super important, that they don't take their glasses off when the moon completely covers the sun," says Laura Peticolas , a space physicist at Sonoma State University. "And then they're like, 'I never saw the corona.'"
So knowing when to take the glasses off, and when to put them on, is key.
Chou says that in the last moments before the sun gets totally covered, the thin crescent of the bright sun breaks into discrete points of bright light. These are called " Baily's beads ," and they are the last bits of light from the disk of the sun shining through the valleys on the edge of the moon.
"And as they go out, their disappearance is a signal that it is now safe to remove the filters and look at the sun without a protective filter," he explains.
As soon as the sun starts to re-emerge, the glasses need to immediately go back on.
"It is possible to observe the eclipse in perfect safety," says Chou, who has seen 19 total solar eclipses.
He encourages people to go out and enjoy an event that won't happen again in the United States until 2044, even as he realizes that some people will be too fearful of eye damage.
"I recognize that there are going to be people who just don't trust the science and just don't trust the public service announcements and are just going to ignore the eclipse as much as they can," says Chou. "It's an unfortunate thing."
- eclipse glasses
- eclipse 2024
- total solar eclipse
- total eclipse
- Opthalmology
We've detected unusual activity from your computer network
To continue, please click the box below to let us know you're not a robot.
Why did this happen?
Please make sure your browser supports JavaScript and cookies and that you are not blocking them from loading. For more information you can review our Terms of Service and Cookie Policy .
For inquiries related to this message please contact our support team and provide the reference ID below.
We use cookies to understand how you use our site and to improve your experience. This includes personalizing content and advertising. To learn more, click here . By continuing to use our site, you accept our use of cookies, revised Privacy Policy and Terms of Service .
New to Zacks? Get started here.
Member Sign In
Don't Know Your Password?
- Zacks #1 Rank
- Zacks Industry Rank
- Zacks Sector Rank
- Equity Research
- Mutual Funds
- Mutual Fund Screener
- ETF Screener
- Earnings Calendar
- Earnings Releases
- Earnings ESP
- Earnings ESP Filter
- Stock Screener
- Premium Screens
- Basic Screens
- Research Wizard
- Personal Finance
- Money Managing
- Real Estate
- Retirement Planning
- Tax Information
- My Portfolio
- Create Portfolio
- Style Scores
- Testimonials
- Zacks.com Tutorial
Services Overview
- Zacks Ultimate
- Zacks Investor Collection
- Zacks Premium
Investor Services
- ETF Investor
- Home Run Investor
- Income Investor
- Stocks Under $10
- Value Investor
- Top 10 Stocks
Other Services
- Method for Trading
- Zacks Confidential
Trading Services
- Black Box Trader
- Counterstrike
- Headline Trader
- Insider Trader
- Large-Cap Trader
- Options Trader
- Short Sell List
- Surprise Trader
- Alternative Energy
You are being directed to ZacksTrade, a division of LBMZ Securities and licensed broker-dealer. ZacksTrade and Zacks.com are separate companies. The web link between the two companies is not a solicitation or offer to invest in a particular security or type of security. ZacksTrade does not endorse or adopt any particular investment strategy, any analyst opinion/rating/report or any approach to evaluating individual securities.
If you wish to go to ZacksTrade, click OK . If you do not, click Cancel.
Image: Bigstock
International Paper (IP) Makes Takeover Offer for DS Smith
International Paper Company ( IP Quick Quote IP - Free Report ) has confirmed that it has made an all-equity proposal to acquire the entire issued share capital of DS Smith ( DITHF Quick Quote DITHF - Free Report ) , valuing the British paper and packaging company at £5.7 billion ($7.2 billion). This move aligns with International Paper's strategy to bolster its corrugated packaging business in Europe. However, it has potentially sparked the possibility of a bidding war as Mondi Plc ( MONDY Quick Quote MONDY - Free Report ) recently signaled interest in acquiring DS Smith for £5.1 billion. Per International Paper’s proposal, DS Smith shareholders would receive 0.1285 shares in International Paper for each DS Smith share held. This will result in DS Smith shareholders owning approximately 33.8% of the combined entity. Based on International Paper’s closing share price of $40.85 on Mar 25, 2024, the offer translates to £4.15 ($5.24) per share. It represents a 48% premium to DS Smith’s share price of £2.81 on Feb 7, 2024. Notably, on Feb 8, Mondi confirmed that it is in the early stages of considering a possible all-share combination with DS Smith. Based on Mondi’s closing share price of £13.81 per share on Feb 7, 2024, the proposal implies a value of £3.73 per DS Smith share and offers a premium of 33% to DS Smith’s closing share price of £2.81 per share on Feb 7. Mondi shareholders would own 54% and DS Smith shareholders would own the remaining 46% of the combined group. DS Smith is a leading provider of sustainable packaging solutions, paper products and recycling services worldwide. It has a workforce of around 30,000 people in more than 30 countries. The combination of International Paper and DS Smith would establish a global leader in sustainable packaging solutions that is well-positioned in attractive and growing markets. It will have a significantly stronger corrugated packaging business in Europe equipped with broader customer offerings. The combination will create the opportunity to integrate both the companies’ mill and box networks and optimize the supply chains in Europe and the United States. It will leverage the market expertise of two experienced and innovative management teams to enhance innovation, solutions and sustainability products for customers. The merger is expected to drive significant synergies including higher integration, commercial and operational improvements, and economies of scale across sourcing, supply chain and administration.
Price Performance
International Paper’s shares have gained 10.3% in the past year compared with the industry ’s 38.2% increase.

Zacks Rank & Stock to Consider
International Paper currently carries a Zacks Rank #3 (Hold). A better-ranked stock from the basic materials space is Ecolab Inc. ( ECL Quick Quote ECL - Free Report ) , which sports a Zacks Rank #1 (Strong Buy) at present. You can see the complete list of today’s Zacks #1 Rank stocks here . The Zacks Consensus Estimate for Ecolab’s 2024 earnings is pegged at $6.39 per share, indicating an increase of 22.7% from the prior year’s reported number. It has an average trailing four-quarter earnings surprise of 1.7%. ECL shares have gained 43% in a year.
See More Zacks Research for These Tickers
Normally $25 each - click below to receive one report free:.
Ecolab Inc. (ECL) - free report >>
International Paper Company (IP) - free report >>
D S SMITH (DITHF) - free report >>
MONDI PLC UNS (MONDY) - free report >>
Published in
This file is used for Yahoo remarketing pixel add
Due to inactivity, you will be signed out in approximately:
IMAGES
VIDEO
COMMENTS
Journal Top 100 - 2022. This collection highlights our most downloaded* research papers published in 2022. Featuring authors from around the world, these papers highlight valuable research from an ...
Here at Science we love ranking things, so we were thrilled with this list of the top 100 most-cited scientific papers, courtesy of Nature.Surprisingly absent are many of the landmark discoveries you might expect, such as the discovery of DNA's double helix structure. Instead, most of these influential manuscripts are slightly more utilitarian in nature.
Journal Top 100. This collection highlights our most downloaded* research papers published in 2021. Featuring authors from around the world, these papers highlight valuable research from an ...
Google Scholar provides a simple way to broadly search for scholarly literature. Search across a wide variety of disciplines and sources: articles, theses, books, abstracts and court opinions.
Students with high emotional intelligence get better grades and score higher on standardized tests, according to the research presented in this article in Psychological Bulletin (Vol. 146, No. 2). Researchers analyzed data from 158 studies representing more than 42,529 students—ranging in age from elementary school to college—from 27 countries.
Modeling and development of technology for smelting a complex alloy (ligature) Fe-Si-Mn-Al from manganese-containing briquettes and high-ash coals. Assylbek Nurumgaliyev. Talgat Zhuniskaliyev ...
113 Great Research Paper Topics. One of the hardest parts of writing a research paper can be just finding a good topic to write about. Fortunately we've done the hard work for you and have compiled a list of 113 interesting research paper topics. They've been organized into ten categories and cover a wide range of subjects so you can easily ...
2021 Best Paper Awards. The NSR 2021 Best Paper Awards recognizes the best papers published in the recent years in National Science Review. The Editorial Board have selected the below papers as winners of the 2021 Best Paper Awards highlighting their significant contributions to research measured against achievement and potential impact.
Develop a thesis statement. Create a research paper outline. Write a first draft of the research paper. Write the introduction. Write a compelling body of text. Write the conclusion. The second draft. The revision process. Research paper checklist.
3. U-Net: Research Paper: U-Net: Convolutional Networks for Biomedical Image Segmentation Authors: Olaf Ronneberger, Philipp Fischer, and Thomas Brox Summary: The task of segmenting involves categorizing similar parts of an image into a cluster. All the identical classes are classified and segmented into a particular entity.
Definition: Research Paper is a written document that presents the author's original research, analysis, and interpretation of a specific topic or issue. It is typically based on Empirical Evidence, and may involve qualitative or quantitative research methods, or a combination of both. The purpose of a research paper is to contribute new ...
Table of contents. Step 1: Introduce your topic. Step 2: Describe the background. Step 3: Establish your research problem. Step 4: Specify your objective (s) Step 5: Map out your paper. Research paper introduction examples. Frequently asked questions about the research paper introduction.
Communicating research findings is an essential step in the research process. Often, peer-reviewed journals are the forum for such communication, yet many researchers are never taught how to write a publishable scientific paper. In this article, we explain the basic structure of a scientific paper and describe the information that should be included in each section. We also identify common ...
Get 30 days free. 1. Google Scholar. Google Scholar is the clear number one when it comes to academic search engines. It's the power of Google searches applied to research papers and patents. It not only lets you find research papers for all academic disciplines for free but also often provides links to full-text PDF files.
2. JSTOR. For journal articles, books, images, and even primary sources, JSTOR ranks among the best online resources for academic research. JSTOR's collection spans 75 disciplines, with strengths in the humanities and social sciences. The academic research database includes complete runs of over 2,800 journals.
Step 4: Create a Research Paper Outline. Outlining is a key part of crafting an effective essay. Your research paper outline should include a rough introduction to the topic, a thesis statement, supporting details for each main idea, and a brief conclusion. You can outline in whatever way feels most comfortable for you.
Find the research you need | With 160+ million publications, 1+ million questions, and 25+ million researchers, this is where everyone can access science
Semantic Reader is an augmented reader with the potential to revolutionize scientific reading by making it more accessible and richly contextual. Try it for select papers. Semantic Scholar uses groundbreaking AI and engineering to understand the semantics of scientific literature to help Scholars discover relevant research.
Access 160+ million publications and connect with 25+ million researchers. Join for free and gain visibility by uploading your research.
This research has an economic, social and cultural impact on its surrounding environment, as when scientific knowledge is disseminated it filters through to non-academic professionals, thus ...
Step 4: Create a research design. The research design is a practical framework for answering your research questions. It involves making decisions about the type of data you need, the methods you'll use to collect and analyze it, and the location and timescale of your research. There are often many possible paths you can take to answering ...
The Writing Center 193 Science Library Irvine, CA 92697-5695 (949)-824-8949 [email protected]
He is a recipient of the 2024 NSF CAREER Award, Amazon Research Award, and CISCO Research Award. He received the best paper nomination at 2018 DATE and 2021 DATE, the best paper award at the DL-Hardware Co-Design for AI Acceleration (DCAA) workshop at 2023 AAAI, outstanding student paper award at 2023 HPEC, publicity paper at 2022 DAC, and the ...
A machine helped testers evaluate scrubbing strength.The best paper towels scrubbed a piece of sandpaper for about 15 cycles before breaking down; the worst struggled after just six cycles.
Research in the lab of K.J.V. is supported by KU Leuven, FWO, VIB, VLAIO and the Brewing Science Serves Health Fund. Research in the lab of T.W. is supported by FWO (G.0A51.15) and KU Leuven (C16 ...
Powering a new era of computing, NVIDIA today announced that the NVIDIA Blackwell platform has arrived — enabling organizations everywhere to build and run real-time generative AI on trillion-parameter large language models at up to 25x less cost and energy consumption than its predecessor.
Formatting an MLA paper. The main guidelines for writing an MLA style paper are as follows: Use an easily readable font like 12 pt Times New Roman. Set 1 inch page margins. Apply double line spacing. Indent every new paragraph ½ inch. Use title case capitalization for headings.
When the April 8 solar eclipse draws eyes upward, having proper solar filters and solar eclipse glasses is essential to avoid potentially permanent eye damage, doctors say.
Gain a complete range of research solutions integrated with the world's most valuable market news, data and financial tools.
International Paper (IP) makes an all-stock offer for British paper and packaging company, DS Smith, valued at 5.72 billion pounds ($7.22 billion).