- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2023 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support

How to Write a Great Hypothesis
Hypothesis Format, Examples, and Tips
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "hypothesis questions psychology")
Amy Morin, LCSW, is a psychotherapist and international bestselling author. Her books, including "13 Things Mentally Strong People Don't Do," have been translated into more than 40 languages. Her TEDx talk, "The Secret of Becoming Mentally Strong," is one of the most viewed talks of all time.
:max_bytes(150000):strip_icc():format(webp)/VW-MIND-Amy-2b338105f1ee493f94d7e333e410fa76.jpg "hypothesis questions psychology")
Verywell / Alex Dos Diaz
- The Scientific Method
Hypothesis Format
Falsifiability of a hypothesis, operational definitions, types of hypotheses, hypotheses examples.
- Collecting Data
Frequently Asked Questions
A hypothesis is a tentative statement about the relationship between two or more variables. It is a specific, testable prediction about what you expect to happen in a study.
One hypothesis example would be a study designed to look at the relationship between sleep deprivation and test performance might have a hypothesis that states: "This study is designed to assess the hypothesis that sleep-deprived people will perform worse on a test than individuals who are not sleep-deprived."
This article explores how a hypothesis is used in psychology research, how to write a good hypothesis, and the different types of hypotheses you might use.
The Hypothesis in the Scientific Method
In the scientific method , whether it involves research in psychology, biology, or some other area, a hypothesis represents what the researchers think will happen in an experiment. The scientific method involves the following steps:
- Forming a question
- Performing background research
- Creating a hypothesis
- Designing an experiment
- Collecting data
- Analyzing the results
- Drawing conclusions
- Communicating the results
The hypothesis is a prediction, but it involves more than a guess. Most of the time, the hypothesis begins with a question which is then explored through background research. It is only at this point that researchers begin to develop a testable hypothesis. Unless you are creating an exploratory study, your hypothesis should always explain what you expect to happen.
In a study exploring the effects of a particular drug, the hypothesis might be that researchers expect the drug to have some type of effect on the symptoms of a specific illness. In psychology, the hypothesis might focus on how a certain aspect of the environment might influence a particular behavior.
Remember, a hypothesis does not have to be correct. While the hypothesis predicts what the researchers expect to see, the goal of the research is to determine whether this guess is right or wrong. When conducting an experiment, researchers might explore a number of factors to determine which ones might contribute to the ultimate outcome.
In many cases, researchers may find that the results of an experiment do not support the original hypothesis. When writing up these results, the researchers might suggest other options that should be explored in future studies.
In many cases, researchers might draw a hypothesis from a specific theory or build on previous research. For example, prior research has shown that stress can impact the immune system. So a researcher might hypothesize: "People with high-stress levels will be more likely to contract a common cold after being exposed to the virus than people who have low-stress levels."
In other instances, researchers might look at commonly held beliefs or folk wisdom. "Birds of a feather flock together" is one example of folk wisdom that a psychologist might try to investigate. The researcher might pose a specific hypothesis that "People tend to select romantic partners who are similar to them in interests and educational level."
Elements of a Good Hypothesis
So how do you write a good hypothesis? When trying to come up with a hypothesis for your research or experiments, ask yourself the following questions:
- Is your hypothesis based on your research on a topic?
- Can your hypothesis be tested?
- Does your hypothesis include independent and dependent variables?
Before you come up with a specific hypothesis, spend some time doing background research. Once you have completed a literature review, start thinking about potential questions you still have. Pay attention to the discussion section in the journal articles you read . Many authors will suggest questions that still need to be explored.
To form a hypothesis, you should take these steps:
- Collect as many observations about a topic or problem as you can.
- Evaluate these observations and look for possible causes of the problem.
- Create a list of possible explanations that you might want to explore.
- After you have developed some possible hypotheses, think of ways that you could confirm or disprove each hypothesis through experimentation. This is known as falsifiability.
In the scientific method , falsifiability is an important part of any valid hypothesis. In order to test a claim scientifically, it must be possible that the claim could be proven false.
Students sometimes confuse the idea of falsifiability with the idea that it means that something is false, which is not the case. What falsifiability means is that if something was false, then it is possible to demonstrate that it is false.
One of the hallmarks of pseudoscience is that it makes claims that cannot be refuted or proven false.
A variable is a factor or element that can be changed and manipulated in ways that are observable and measurable. However, the researcher must also define how the variable will be manipulated and measured in the study.
For example, a researcher might operationally define the variable " test anxiety " as the results of a self-report measure of anxiety experienced during an exam. A "study habits" variable might be defined by the amount of studying that actually occurs as measured by time.
These precise descriptions are important because many things can be measured in a number of different ways. One of the basic principles of any type of scientific research is that the results must be replicable. By clearly detailing the specifics of how the variables were measured and manipulated, other researchers can better understand the results and repeat the study if needed.
Some variables are more difficult than others to define. How would you operationally define a variable such as aggression ? For obvious ethical reasons, researchers cannot create a situation in which a person behaves aggressively toward others.
In order to measure this variable, the researcher must devise a measurement that assesses aggressive behavior without harming other people. In this situation, the researcher might utilize a simulated task to measure aggressiveness.
Hypothesis Checklist
- Does your hypothesis focus on something that you can actually test?
- Does your hypothesis include both an independent and dependent variable?
- Can you manipulate the variables?
- Can your hypothesis be tested without violating ethical standards?
The hypothesis you use will depend on what you are investigating and hoping to find. Some of the main types of hypotheses that you might use include:
- Simple hypothesis : This type of hypothesis suggests that there is a relationship between one independent variable and one dependent variable.
- Complex hypothesis : This type of hypothesis suggests a relationship between three or more variables, such as two independent variables and a dependent variable.
- Null hypothesis : This hypothesis suggests no relationship exists between two or more variables.
- Alternative hypothesis : This hypothesis states the opposite of the null hypothesis.
- Statistical hypothesis : This hypothesis uses statistical analysis to evaluate a representative sample of the population and then generalizes the findings to the larger group.
- Logical hypothesis : This hypothesis assumes a relationship between variables without collecting data or evidence.
A hypothesis often follows a basic format of "If {this happens} then {this will happen}." One way to structure your hypothesis is to describe what will happen to the dependent variable if you change the independent variable .
The basic format might be: "If {these changes are made to a certain independent variable}, then we will observe {a change in a specific dependent variable}."
A few examples of simple hypotheses:
- "Students who eat breakfast will perform better on a math exam than students who do not eat breakfast."
- Complex hypothesis: "Students who experience test anxiety before an English exam will get lower scores than students who do not experience test anxiety."
- "Motorists who talk on the phone while driving will be more likely to make errors on a driving course than those who do not talk on the phone."
Examples of a complex hypothesis include:
- "People with high-sugar diets and sedentary activity levels are more likely to develop depression."
- "Younger people who are regularly exposed to green, outdoor areas have better subjective well-being than older adults who have limited exposure to green spaces."
Examples of a null hypothesis include:
- "Children who receive a new reading intervention will have scores different than students who do not receive the intervention."
- "There will be no difference in scores on a memory recall task between children and adults."
Examples of an alternative hypothesis:
- "Children who receive a new reading intervention will perform better than students who did not receive the intervention."
- "Adults will perform better on a memory task than children."
Collecting Data on Your Hypothesis
Once a researcher has formed a testable hypothesis, the next step is to select a research design and start collecting data. The research method depends largely on exactly what they are studying. There are two basic types of research methods: descriptive research and experimental research.
Descriptive Research Methods
Descriptive research such as case studies , naturalistic observations , and surveys are often used when it would be impossible or difficult to conduct an experiment . These methods are best used to describe different aspects of a behavior or psychological phenomenon.
Once a researcher has collected data using descriptive methods, a correlational study can then be used to look at how the variables are related. This type of research method might be used to investigate a hypothesis that is difficult to test experimentally.
Experimental Research Methods
Experimental methods are used to demonstrate causal relationships between variables. In an experiment, the researcher systematically manipulates a variable of interest (known as the independent variable) and measures the effect on another variable (known as the dependent variable).
Unlike correlational studies, which can only be used to determine if there is a relationship between two variables, experimental methods can be used to determine the actual nature of the relationship—whether changes in one variable actually cause another to change.
A Word From Verywell
The hypothesis is a critical part of any scientific exploration. It represents what researchers expect to find in a study or experiment. In situations where the hypothesis is unsupported by the research, the research still has value. Such research helps us better understand how different aspects of the natural world relate to one another. It also helps us develop new hypotheses that can then be tested in the future.
Some examples of how to write a hypothesis include:
- "Staying up late will lead to worse test performance the next day."
- "People who consume one apple each day will visit the doctor fewer times each year."
- "Breaking study sessions up into three 20-minute sessions will lead to better test results than a single 60-minute study session."
The four parts of a hypothesis are:
- The research question
- The independent variable (IV)
- The dependent variable (DV)
- The proposed relationship between the IV and DV
Castillo M. The scientific method: a need for something better? . AJNR Am J Neuroradiol. 2013;34(9):1669-71. doi:10.3174/ajnr.A3401
Nevid J. Psychology: Concepts and Applications. Wadworth, 2013.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- How to Write a Strong Hypothesis | Steps & Examples
How to Write a Strong Hypothesis | Steps & Examples
Published on May 6, 2022 by Shona McCombes . Revised on November 20, 2023.
A hypothesis is a statement that can be tested by scientific research. If you want to test a relationship between two or more variables, you need to write hypotheses before you start your experiment or data collection .
Example: Hypothesis
Daily apple consumption leads to fewer doctor’s visits.
Table of contents
What is a hypothesis, developing a hypothesis (with example), hypothesis examples, other interesting articles, frequently asked questions about writing hypotheses.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess – it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Variables in hypotheses
Hypotheses propose a relationship between two or more types of variables .
- An independent variable is something the researcher changes or controls.
- A dependent variable is something the researcher observes and measures.
If there are any control variables , extraneous variables , or confounding variables , be sure to jot those down as you go to minimize the chances that research bias will affect your results.
In this example, the independent variable is exposure to the sun – the assumed cause . The dependent variable is the level of happiness – the assumed effect .
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
Step 1. Ask a question
Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project.
Step 2. Do some preliminary research
Your initial answer to the question should be based on what is already known about the topic. Look for theories and previous studies to help you form educated assumptions about what your research will find.
At this stage, you might construct a conceptual framework to ensure that you’re embarking on a relevant topic . This can also help you identify which variables you will study and what you think the relationships are between them. Sometimes, you’ll have to operationalize more complex constructs.
Step 3. Formulate your hypothesis
Now you should have some idea of what you expect to find. Write your initial answer to the question in a clear, concise sentence.
4. Refine your hypothesis
You need to make sure your hypothesis is specific and testable. There are various ways of phrasing a hypothesis, but all the terms you use should have clear definitions, and the hypothesis should contain:
- The relevant variables
- The specific group being studied
- The predicted outcome of the experiment or analysis
5. Phrase your hypothesis in three ways
To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
In academic research, hypotheses are more commonly phrased in terms of correlations or effects, where you directly state the predicted relationship between variables.
If you are comparing two groups, the hypothesis can state what difference you expect to find between them.
6. Write a null hypothesis
If your research involves statistical hypothesis testing , you will also have to write a null hypothesis . The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0 , while the alternative hypothesis is H 1 or H a .
- H 0 : The number of lectures attended by first-year students has no effect on their final exam scores.
- H 1 : The number of lectures attended by first-year students has a positive effect on their final exam scores.
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
Prevent plagiarism. Run a free check.
A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, November 20). How to Write a Strong Hypothesis | Steps & Examples. Scribbr. Retrieved April 2, 2024, from https://www.scribbr.com/methodology/hypothesis/
Is this article helpful?

Shona McCombes
Other students also liked, construct validity | definition, types, & examples, what is a conceptual framework | tips & examples, operationalization | a guide with examples, pros & cons, unlimited academic ai-proofreading.
✔ Document error-free in 5minutes ✔ Unlimited document corrections ✔ Specialized in correcting academic texts

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Overview of the Scientific Method
Learning Objectives
- Distinguish between a theory and a hypothesis.
- Discover how theories are used to generate hypotheses and how the results of studies can be used to further inform theories.
- Understand the characteristics of a good hypothesis.
Theories and Hypotheses
Before describing how to develop a hypothesis, it is important to distinguish between a theory and a hypothesis. A theory is a coherent explanation or interpretation of one or more phenomena. Although theories can take a variety of forms, one thing they have in common is that they go beyond the phenomena they explain by including variables, structures, processes, functions, or organizing principles that have not been observed directly. Consider, for example, Zajonc’s theory of social facilitation and social inhibition (1965) [1] . He proposed that being watched by others while performing a task creates a general state of physiological arousal, which increases the likelihood of the dominant (most likely) response. So for highly practiced tasks, being watched increases the tendency to make correct responses, but for relatively unpracticed tasks, being watched increases the tendency to make incorrect responses. Notice that this theory—which has come to be called drive theory—provides an explanation of both social facilitation and social inhibition that goes beyond the phenomena themselves by including concepts such as “arousal” and “dominant response,” along with processes such as the effect of arousal on the dominant response.
Outside of science, referring to an idea as a theory often implies that it is untested—perhaps no more than a wild guess. In science, however, the term theory has no such implication. A theory is simply an explanation or interpretation of a set of phenomena. It can be untested, but it can also be extensively tested, well supported, and accepted as an accurate description of the world by the scientific community. The theory of evolution by natural selection, for example, is a theory because it is an explanation of the diversity of life on earth—not because it is untested or unsupported by scientific research. On the contrary, the evidence for this theory is overwhelmingly positive and nearly all scientists accept its basic assumptions as accurate. Similarly, the “germ theory” of disease is a theory because it is an explanation of the origin of various diseases, not because there is any doubt that many diseases are caused by microorganisms that infect the body.
A hypothesis , on the other hand, is a specific prediction about a new phenomenon that should be observed if a particular theory is accurate. It is an explanation that relies on just a few key concepts. Hypotheses are often specific predictions about what will happen in a particular study. They are developed by considering existing evidence and using reasoning to infer what will happen in the specific context of interest. Hypotheses are often but not always derived from theories. So a hypothesis is often a prediction based on a theory but some hypotheses are a-theoretical and only after a set of observations have been made, is a theory developed. This is because theories are broad in nature and they explain larger bodies of data. So if our research question is really original then we may need to collect some data and make some observations before we can develop a broader theory.
Theories and hypotheses always have this if-then relationship. “ If drive theory is correct, then cockroaches should run through a straight runway faster, and a branching runway more slowly, when other cockroaches are present.” Although hypotheses are usually expressed as statements, they can always be rephrased as questions. “Do cockroaches run through a straight runway faster when other cockroaches are present?” Thus deriving hypotheses from theories is an excellent way of generating interesting research questions.
But how do researchers derive hypotheses from theories? One way is to generate a research question using the techniques discussed in this chapter and then ask whether any theory implies an answer to that question. For example, you might wonder whether expressive writing about positive experiences improves health as much as expressive writing about traumatic experiences. Although this question is an interesting one on its own, you might then ask whether the habituation theory—the idea that expressive writing causes people to habituate to negative thoughts and feelings—implies an answer. In this case, it seems clear that if the habituation theory is correct, then expressive writing about positive experiences should not be effective because it would not cause people to habituate to negative thoughts and feelings. A second way to derive hypotheses from theories is to focus on some component of the theory that has not yet been directly observed. For example, a researcher could focus on the process of habituation—perhaps hypothesizing that people should show fewer signs of emotional distress with each new writing session.
Among the very best hypotheses are those that distinguish between competing theories. For example, Norbert Schwarz and his colleagues considered two theories of how people make judgments about themselves, such as how assertive they are (Schwarz et al., 1991) [2] . Both theories held that such judgments are based on relevant examples that people bring to mind. However, one theory was that people base their judgments on the number of examples they bring to mind and the other was that people base their judgments on how easily they bring those examples to mind. To test these theories, the researchers asked people to recall either six times when they were assertive (which is easy for most people) or 12 times (which is difficult for most people). Then they asked them to judge their own assertiveness. Note that the number-of-examples theory implies that people who recalled 12 examples should judge themselves to be more assertive because they recalled more examples, but the ease-of-examples theory implies that participants who recalled six examples should judge themselves as more assertive because recalling the examples was easier. Thus the two theories made opposite predictions so that only one of the predictions could be confirmed. The surprising result was that participants who recalled fewer examples judged themselves to be more assertive—providing particularly convincing evidence in favor of the ease-of-retrieval theory over the number-of-examples theory.
Theory Testing
The primary way that scientific researchers use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). Researchers begin with a set of phenomena and either construct a theory to explain or interpret them or choose an existing theory to work with. They then make a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researchers then conduct an empirical study to test the hypothesis. Finally, they reevaluate the theory in light of the new results and revise it if necessary. This process is usually conceptualized as a cycle because the researchers can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 2.3 shows, this approach meshes nicely with the model of scientific research in psychology presented earlier in the textbook—creating a more detailed model of “theoretically motivated” or “theory-driven” research.
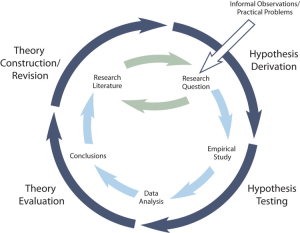
As an example, let us consider Zajonc’s research on social facilitation and inhibition. He started with a somewhat contradictory pattern of results from the research literature. He then constructed his drive theory, according to which being watched by others while performing a task causes physiological arousal, which increases an organism’s tendency to make the dominant response. This theory predicts social facilitation for well-learned tasks and social inhibition for poorly learned tasks. He now had a theory that organized previous results in a meaningful way—but he still needed to test it. He hypothesized that if his theory was correct, he should observe that the presence of others improves performance in a simple laboratory task but inhibits performance in a difficult version of the very same laboratory task. To test this hypothesis, one of the studies he conducted used cockroaches as subjects (Zajonc, Heingartner, & Herman, 1969) [3] . The cockroaches ran either down a straight runway (an easy task for a cockroach) or through a cross-shaped maze (a difficult task for a cockroach) to escape into a dark chamber when a light was shined on them. They did this either while alone or in the presence of other cockroaches in clear plastic “audience boxes.” Zajonc found that cockroaches in the straight runway reached their goal more quickly in the presence of other cockroaches, but cockroaches in the cross-shaped maze reached their goal more slowly when they were in the presence of other cockroaches. Thus he confirmed his hypothesis and provided support for his drive theory. (Zajonc also showed that drive theory existed in humans [Zajonc & Sales, 1966] [4] in many other studies afterward).
Incorporating Theory into Your Research
When you write your research report or plan your presentation, be aware that there are two basic ways that researchers usually include theory. The first is to raise a research question, answer that question by conducting a new study, and then offer one or more theories (usually more) to explain or interpret the results. This format works well for applied research questions and for research questions that existing theories do not address. The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
To use theories in your research will not only give you guidance in coming up with experiment ideas and possible projects, but it lends legitimacy to your work. Psychologists have been interested in a variety of human behaviors and have developed many theories along the way. Using established theories will help you break new ground as a researcher, not limit you from developing your own ideas.
Characteristics of a Good Hypothesis
There are three general characteristics of a good hypothesis. First, a good hypothesis must be testable and falsifiable . We must be able to test the hypothesis using the methods of science and if you’ll recall Popper’s falsifiability criterion, it must be possible to gather evidence that will disconfirm the hypothesis if it is indeed false. Second, a good hypothesis must be logical. As described above, hypotheses are more than just a random guess. Hypotheses should be informed by previous theories or observations and logical reasoning. Typically, we begin with a broad and general theory and use deductive reasoning to generate a more specific hypothesis to test based on that theory. Occasionally, however, when there is no theory to inform our hypothesis, we use inductive reasoning which involves using specific observations or research findings to form a more general hypothesis. Finally, the hypothesis should be positive. That is, the hypothesis should make a positive statement about the existence of a relationship or effect, rather than a statement that a relationship or effect does not exist. As scientists, we don’t set out to show that relationships do not exist or that effects do not occur so our hypotheses should not be worded in a way to suggest that an effect or relationship does not exist. The nature of science is to assume that something does not exist and then seek to find evidence to prove this wrong, to show that it really does exist. That may seem backward to you but that is the nature of the scientific method. The underlying reason for this is beyond the scope of this chapter but it has to do with statistical theory.
- Zajonc, R. B. (1965). Social facilitation. Science, 149 , 269–274 ↵
- Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality and Social Psychology, 61 , 195–202. ↵
- Zajonc, R. B., Heingartner, A., & Herman, E. M. (1969). Social enhancement and impairment of performance in the cockroach. Journal of Personality and Social Psychology, 13 , 83–92. ↵
- Zajonc, R.B. & Sales, S.M. (1966). Social facilitation of dominant and subordinate responses. Journal of Experimental Social Psychology, 2 , 160-168. ↵
A coherent explanation or interpretation of one or more phenomena.
A specific prediction about a new phenomenon that should be observed if a particular theory is accurate.
A cyclical process of theory development, starting with an observed phenomenon, then developing or using a theory to make a specific prediction of what should happen if that theory is correct, testing that prediction, refining the theory in light of the findings, and using that refined theory to develop new hypotheses, and so on.
The ability to test the hypothesis using the methods of science and the possibility to gather evidence that will disconfirm the hypothesis if it is indeed false.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Developing a Hypothesis
Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton
Learning Objectives
- Distinguish between a theory and a hypothesis.
- Discover how theories are used to generate hypotheses and how the results of studies can be used to further inform theories.
- Understand the characteristics of a good hypothesis.
Theories and Hypotheses
Before describing how to develop a hypothesis, it is important to distinguish between a theory and a hypothesis. A theory is a coherent explanation or interpretation of one or more phenomena. Although theories can take a variety of forms, one thing they have in common is that they go beyond the phenomena they explain by including variables, structures, processes, functions, or organizing principles that have not been observed directly. Consider, for example, Zajonc’s theory of social facilitation and social inhibition (1965) [1] . He proposed that being watched by others while performing a task creates a general state of physiological arousal, which increases the likelihood of the dominant (most likely) response. So for highly practiced tasks, being watched increases the tendency to make correct responses, but for relatively unpracticed tasks, being watched increases the tendency to make incorrect responses. Notice that this theory—which has come to be called drive theory—provides an explanation of both social facilitation and social inhibition that goes beyond the phenomena themselves by including concepts such as “arousal” and “dominant response,” along with processes such as the effect of arousal on the dominant response.
Outside of science, referring to an idea as a theory often implies that it is untested—perhaps no more than a wild guess. In science, however, the term theory has no such implication. A theory is simply an explanation or interpretation of a set of phenomena. It can be untested, but it can also be extensively tested, well supported, and accepted as an accurate description of the world by the scientific community. The theory of evolution by natural selection, for example, is a theory because it is an explanation of the diversity of life on earth—not because it is untested or unsupported by scientific research. On the contrary, the evidence for this theory is overwhelmingly positive and nearly all scientists accept its basic assumptions as accurate. Similarly, the “germ theory” of disease is a theory because it is an explanation of the origin of various diseases, not because there is any doubt that many diseases are caused by microorganisms that infect the body.
A hypothesis , on the other hand, is a specific prediction about a new phenomenon that should be observed if a particular theory is accurate. It is an explanation that relies on just a few key concepts. Hypotheses are often specific predictions about what will happen in a particular study. They are developed by considering existing evidence and using reasoning to infer what will happen in the specific context of interest. Hypotheses are often but not always derived from theories. So a hypothesis is often a prediction based on a theory but some hypotheses are a-theoretical and only after a set of observations have been made, is a theory developed. This is because theories are broad in nature and they explain larger bodies of data. So if our research question is really original then we may need to collect some data and make some observations before we can develop a broader theory.
Theories and hypotheses always have this if-then relationship. “ If drive theory is correct, then cockroaches should run through a straight runway faster, and a branching runway more slowly, when other cockroaches are present.” Although hypotheses are usually expressed as statements, they can always be rephrased as questions. “Do cockroaches run through a straight runway faster when other cockroaches are present?” Thus deriving hypotheses from theories is an excellent way of generating interesting research questions.
But how do researchers derive hypotheses from theories? One way is to generate a research question using the techniques discussed in this chapter and then ask whether any theory implies an answer to that question. For example, you might wonder whether expressive writing about positive experiences improves health as much as expressive writing about traumatic experiences. Although this question is an interesting one on its own, you might then ask whether the habituation theory—the idea that expressive writing causes people to habituate to negative thoughts and feelings—implies an answer. In this case, it seems clear that if the habituation theory is correct, then expressive writing about positive experiences should not be effective because it would not cause people to habituate to negative thoughts and feelings. A second way to derive hypotheses from theories is to focus on some component of the theory that has not yet been directly observed. For example, a researcher could focus on the process of habituation—perhaps hypothesizing that people should show fewer signs of emotional distress with each new writing session.
Among the very best hypotheses are those that distinguish between competing theories. For example, Norbert Schwarz and his colleagues considered two theories of how people make judgments about themselves, such as how assertive they are (Schwarz et al., 1991) [2] . Both theories held that such judgments are based on relevant examples that people bring to mind. However, one theory was that people base their judgments on the number of examples they bring to mind and the other was that people base their judgments on how easily they bring those examples to mind. To test these theories, the researchers asked people to recall either six times when they were assertive (which is easy for most people) or 12 times (which is difficult for most people). Then they asked them to judge their own assertiveness. Note that the number-of-examples theory implies that people who recalled 12 examples should judge themselves to be more assertive because they recalled more examples, but the ease-of-examples theory implies that participants who recalled six examples should judge themselves as more assertive because recalling the examples was easier. Thus the two theories made opposite predictions so that only one of the predictions could be confirmed. The surprising result was that participants who recalled fewer examples judged themselves to be more assertive—providing particularly convincing evidence in favor of the ease-of-retrieval theory over the number-of-examples theory.
Theory Testing
The primary way that scientific researchers use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). Researchers begin with a set of phenomena and either construct a theory to explain or interpret them or choose an existing theory to work with. They then make a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researchers then conduct an empirical study to test the hypothesis. Finally, they reevaluate the theory in light of the new results and revise it if necessary. This process is usually conceptualized as a cycle because the researchers can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 2.3 shows, this approach meshes nicely with the model of scientific research in psychology presented earlier in the textbook—creating a more detailed model of “theoretically motivated” or “theory-driven” research.
As an example, let us consider Zajonc’s research on social facilitation and inhibition. He started with a somewhat contradictory pattern of results from the research literature. He then constructed his drive theory, according to which being watched by others while performing a task causes physiological arousal, which increases an organism’s tendency to make the dominant response. This theory predicts social facilitation for well-learned tasks and social inhibition for poorly learned tasks. He now had a theory that organized previous results in a meaningful way—but he still needed to test it. He hypothesized that if his theory was correct, he should observe that the presence of others improves performance in a simple laboratory task but inhibits performance in a difficult version of the very same laboratory task. To test this hypothesis, one of the studies he conducted used cockroaches as subjects (Zajonc, Heingartner, & Herman, 1969) [3] . The cockroaches ran either down a straight runway (an easy task for a cockroach) or through a cross-shaped maze (a difficult task for a cockroach) to escape into a dark chamber when a light was shined on them. They did this either while alone or in the presence of other cockroaches in clear plastic “audience boxes.” Zajonc found that cockroaches in the straight runway reached their goal more quickly in the presence of other cockroaches, but cockroaches in the cross-shaped maze reached their goal more slowly when they were in the presence of other cockroaches. Thus he confirmed his hypothesis and provided support for his drive theory. (Zajonc also showed that drive theory existed in humans [Zajonc & Sales, 1966] [4] in many other studies afterward).
Incorporating Theory into Your Research
When you write your research report or plan your presentation, be aware that there are two basic ways that researchers usually include theory. The first is to raise a research question, answer that question by conducting a new study, and then offer one or more theories (usually more) to explain or interpret the results. This format works well for applied research questions and for research questions that existing theories do not address. The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
To use theories in your research will not only give you guidance in coming up with experiment ideas and possible projects, but it lends legitimacy to your work. Psychologists have been interested in a variety of human behaviors and have developed many theories along the way. Using established theories will help you break new ground as a researcher, not limit you from developing your own ideas.
Characteristics of a Good Hypothesis
There are three general characteristics of a good hypothesis. First, a good hypothesis must be testable and falsifiable . We must be able to test the hypothesis using the methods of science and if you’ll recall Popper’s falsifiability criterion, it must be possible to gather evidence that will disconfirm the hypothesis if it is indeed false. Second, a good hypothesis must be logical. As described above, hypotheses are more than just a random guess. Hypotheses should be informed by previous theories or observations and logical reasoning. Typically, we begin with a broad and general theory and use deductive reasoning to generate a more specific hypothesis to test based on that theory. Occasionally, however, when there is no theory to inform our hypothesis, we use inductive reasoning which involves using specific observations or research findings to form a more general hypothesis. Finally, the hypothesis should be positive. That is, the hypothesis should make a positive statement about the existence of a relationship or effect, rather than a statement that a relationship or effect does not exist. As scientists, we don’t set out to show that relationships do not exist or that effects do not occur so our hypotheses should not be worded in a way to suggest that an effect or relationship does not exist. The nature of science is to assume that something does not exist and then seek to find evidence to prove this wrong, to show that it really does exist. That may seem backward to you but that is the nature of the scientific method. The underlying reason for this is beyond the scope of this chapter but it has to do with statistical theory.
- Zajonc, R. B. (1965). Social facilitation. Science, 149 , 269–274 ↵
- Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality and Social Psychology, 61 , 195–202. ↵
- Zajonc, R. B., Heingartner, A., & Herman, E. M. (1969). Social enhancement and impairment of performance in the cockroach. Journal of Personality and Social Psychology, 13 , 83–92. ↵
- Zajonc, R.B. & Sales, S.M. (1966). Social facilitation of dominant and subordinate responses. Journal of Experimental Social Psychology, 2 , 160-168. ↵
A coherent explanation or interpretation of one or more phenomena.
A specific prediction about a new phenomenon that should be observed if a particular theory is accurate.
A cyclical process of theory development, starting with an observed phenomenon, then developing or using a theory to make a specific prediction of what should happen if that theory is correct, testing that prediction, refining the theory in light of the findings, and using that refined theory to develop new hypotheses, and so on.
The ability to test the hypothesis using the methods of science and the possibility to gather evidence that will disconfirm the hypothesis if it is indeed false.
Developing a Hypothesis Copyright © 2022 by Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
2.4 Developing a Hypothesis
Learning objectives.
- Distinguish between a theory and a hypothesis.
- Discover how theories are used to generate hypotheses and how the results of studies can be used to further inform theories.
- Understand the characteristics of a good hypothesis.
Theories and Hypotheses
Before describing how to develop a hypothesis it is imporant to distinguish betwee a theory and a hypothesis. A theory is a coherent explanation or interpretation of one or more phenomena. Although theories can take a variety of forms, one thing they have in common is that they go beyond the phenomena they explain by including variables, structures, processes, functions, or organizing principles that have not been observed directly. Consider, for example, Zajonc’s theory of social facilitation and social inhibition. He proposed that being watched by others while performing a task creates a general state of physiological arousal, which increases the likelihood of the dominant (most likely) response. So for highly practiced tasks, being watched increases the tendency to make correct responses, but for relatively unpracticed tasks, being watched increases the tendency to make incorrect responses. Notice that this theory—which has come to be called drive theory—provides an explanation of both social facilitation and social inhibition that goes beyond the phenomena themselves by including concepts such as “arousal” and “dominant response,” along with processes such as the effect of arousal on the dominant response.
Outside of science, referring to an idea as a theory often implies that it is untested—perhaps no more than a wild guess. In science, however, the term theory has no such implication. A theory is simply an explanation or interpretation of a set of phenomena. It can be untested, but it can also be extensively tested, well supported, and accepted as an accurate description of the world by the scientific community. The theory of evolution by natural selection, for example, is a theory because it is an explanation of the diversity of life on earth—not because it is untested or unsupported by scientific research. On the contrary, the evidence for this theory is overwhelmingly positive and nearly all scientists accept its basic assumptions as accurate. Similarly, the “germ theory” of disease is a theory because it is an explanation of the origin of various diseases, not because there is any doubt that many diseases are caused by microorganisms that infect the body.
A hypothesis , on the other hand, is a specific prediction about a new phenomenon that should be observed if a particular theory is accurate. It is an explanation that relies on just a few key concepts. Hypotheses are often specific predictions about what will happen in a particular study. They are developed by considering existing evidence and using reasoning to infer what will happen in the specific context of interest. Hypotheses are often but not always derived from theories. So a hypothesis is often a prediction based on a theory but some hypotheses are a-theoretical and only after a set of observations have been made, is a theory developed. This is because theories are broad in nature and they explain larger bodies of data. So if our research question is really original then we may need to collect some data and make some observation before we can develop a broader theory.
Theories and hypotheses always have this if-then relationship. “ If drive theory is correct, then cockroaches should run through a straight runway faster, and a branching runway more slowly, when other cockroaches are present.” Although hypotheses are usually expressed as statements, they can always be rephrased as questions. “Do cockroaches run through a straight runway faster when other cockroaches are present?” Thus deriving hypotheses from theories is an excellent way of generating interesting research questions.
But how do researchers derive hypotheses from theories? One way is to generate a research question using the techniques discussed in this chapter and then ask whether any theory implies an answer to that question. For example, you might wonder whether expressive writing about positive experiences improves health as much as expressive writing about traumatic experiences. Although this question is an interesting one on its own, you might then ask whether the habituation theory—the idea that expressive writing causes people to habituate to negative thoughts and feelings—implies an answer. In this case, it seems clear that if the habituation theory is correct, then expressive writing about positive experiences should not be effective because it would not cause people to habituate to negative thoughts and feelings. A second way to derive hypotheses from theories is to focus on some component of the theory that has not yet been directly observed. For example, a researcher could focus on the process of habituation—perhaps hypothesizing that people should show fewer signs of emotional distress with each new writing session.
Among the very best hypotheses are those that distinguish between competing theories. For example, Norbert Schwarz and his colleagues considered two theories of how people make judgments about themselves, such as how assertive they are (Schwarz et al., 1991) [1] . Both theories held that such judgments are based on relevant examples that people bring to mind. However, one theory was that people base their judgments on the number of examples they bring to mind and the other was that people base their judgments on how easily they bring those examples to mind. To test these theories, the researchers asked people to recall either six times when they were assertive (which is easy for most people) or 12 times (which is difficult for most people). Then they asked them to judge their own assertiveness. Note that the number-of-examples theory implies that people who recalled 12 examples should judge themselves to be more assertive because they recalled more examples, but the ease-of-examples theory implies that participants who recalled six examples should judge themselves as more assertive because recalling the examples was easier. Thus the two theories made opposite predictions so that only one of the predictions could be confirmed. The surprising result was that participants who recalled fewer examples judged themselves to be more assertive—providing particularly convincing evidence in favor of the ease-of-retrieval theory over the number-of-examples theory.
Theory Testing
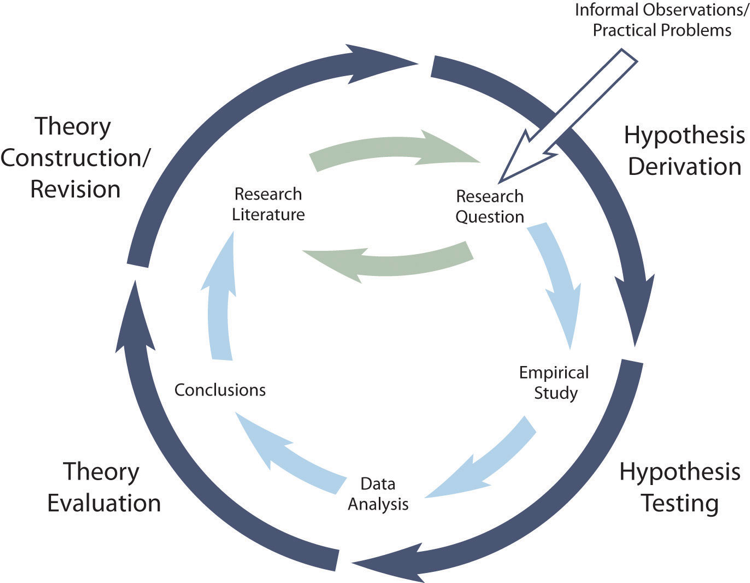
The primary way that scientific researchers use theories is sometimes called the hypothetico-deductive method (although this term is much more likely to be used by philosophers of science than by scientists themselves). A researcher begins with a set of phenomena and either constructs a theory to explain or interpret them or chooses an existing theory to work with. He or she then makes a prediction about some new phenomenon that should be observed if the theory is correct. Again, this prediction is called a hypothesis. The researcher then conducts an empirical study to test the hypothesis. Finally, he or she reevaluates the theory in light of the new results and revises it if necessary. This process is usually conceptualized as a cycle because the researcher can then derive a new hypothesis from the revised theory, conduct a new empirical study to test the hypothesis, and so on. As Figure 2.2 shows, this approach meshes nicely with the model of scientific research in psychology presented earlier in the textbook—creating a more detailed model of “theoretically motivated” or “theory-driven” research.

Figure 2.2 Hypothetico-Deductive Method Combined With the General Model of Scientific Research in Psychology Together they form a model of theoretically motivated research.
As an example, let us consider Zajonc’s research on social facilitation and inhibition. He started with a somewhat contradictory pattern of results from the research literature. He then constructed his drive theory, according to which being watched by others while performing a task causes physiological arousal, which increases an organism’s tendency to make the dominant response. This theory predicts social facilitation for well-learned tasks and social inhibition for poorly learned tasks. He now had a theory that organized previous results in a meaningful way—but he still needed to test it. He hypothesized that if his theory was correct, he should observe that the presence of others improves performance in a simple laboratory task but inhibits performance in a difficult version of the very same laboratory task. To test this hypothesis, one of the studies he conducted used cockroaches as subjects (Zajonc, Heingartner, & Herman, 1969) [2] . The cockroaches ran either down a straight runway (an easy task for a cockroach) or through a cross-shaped maze (a difficult task for a cockroach) to escape into a dark chamber when a light was shined on them. They did this either while alone or in the presence of other cockroaches in clear plastic “audience boxes.” Zajonc found that cockroaches in the straight runway reached their goal more quickly in the presence of other cockroaches, but cockroaches in the cross-shaped maze reached their goal more slowly when they were in the presence of other cockroaches. Thus he confirmed his hypothesis and provided support for his drive theory. (Zajonc also showed that drive theory existed in humans (Zajonc & Sales, 1966) [3] in many other studies afterward).
Incorporating Theory into Your Research
When you write your research report or plan your presentation, be aware that there are two basic ways that researchers usually include theory. The first is to raise a research question, answer that question by conducting a new study, and then offer one or more theories (usually more) to explain or interpret the results. This format works well for applied research questions and for research questions that existing theories do not address. The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with a hypothesis derived from a different theory.
To use theories in your research will not only give you guidance in coming up with experiment ideas and possible projects, but it lends legitimacy to your work. Psychologists have been interested in a variety of human behaviors and have developed many theories along the way. Using established theories will help you break new ground as a researcher, not limit you from developing your own ideas.
Characteristics of a Good Hypothesis
There are three general characteristics of a good hypothesis. First, a good hypothesis must be testable and falsifiable . We must be able to test the hypothesis using the methods of science and if you’ll recall Popper’s falsifiability criterion, it must be possible to gather evidence that will disconfirm the hypothesis if it is indeed false. Second, a good hypothesis must be logical. As described above, hypotheses are more than just a random guess. Hypotheses should be informed by previous theories or observations and logical reasoning. Typically, we begin with a broad and general theory and use deductive reasoning to generate a more specific hypothesis to test based on that theory. Occasionally, however, when there is no theory to inform our hypothesis, we use inductive reasoning which involves using specific observations or research findings to form a more general hypothesis. Finally, the hypothesis should be positive. That is, the hypothesis should make a positive statement about the existence of a relationship or effect, rather than a statement that a relationship or effect does not exist. As scientists, we don’t set out to show that relationships do not exist or that effects do not occur so our hypotheses should not be worded in a way to suggest that an effect or relationship does not exist. The nature of science is to assume that something does not exist and then seek to find evidence to prove this wrong, to show that really it does exist. That may seem backward to you but that is the nature of the scientific method. The underlying reason for this is beyond the scope of this chapter but it has to do with statistical theory.
Key Takeaways
- A theory is broad in nature and explains larger bodies of data. A hypothesis is more specific and makes a prediction about the outcome of a particular study.
- Working with theories is not “icing on the cake.” It is a basic ingredient of psychological research.
- Like other scientists, psychologists use the hypothetico-deductive method. They construct theories to explain or interpret phenomena (or work with existing theories), derive hypotheses from their theories, test the hypotheses, and then reevaluate the theories in light of the new results.
- Practice: Find a recent empirical research report in a professional journal. Read the introduction and highlight in different colors descriptions of theories and hypotheses.
- Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality and Social Psychology, 61 , 195–202. ↵
- Zajonc, R. B., Heingartner, A., & Herman, E. M. (1969). Social enhancement and impairment of performance in the cockroach. Journal of Personality and Social Psychology, 13 , 83–92. ↵
- Zajonc, R.B. & Sales, S.M. (1966). Social facilitation of dominant and subordinate responses. Journal of Experimental Social Psychology, 2 , 160-168. ↵

Share This Book
- Increase Font Size

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- J Korean Med Sci
- v.37(16); 2022 Apr 25
A Practical Guide to Writing Quantitative and Qualitative Research Questions and Hypotheses in Scholarly Articles
Edward barroga.
1 Department of General Education, Graduate School of Nursing Science, St. Luke’s International University, Tokyo, Japan.
Glafera Janet Matanguihan
2 Department of Biological Sciences, Messiah University, Mechanicsburg, PA, USA.
The development of research questions and the subsequent hypotheses are prerequisites to defining the main research purpose and specific objectives of a study. Consequently, these objectives determine the study design and research outcome. The development of research questions is a process based on knowledge of current trends, cutting-edge studies, and technological advances in the research field. Excellent research questions are focused and require a comprehensive literature search and in-depth understanding of the problem being investigated. Initially, research questions may be written as descriptive questions which could be developed into inferential questions. These questions must be specific and concise to provide a clear foundation for developing hypotheses. Hypotheses are more formal predictions about the research outcomes. These specify the possible results that may or may not be expected regarding the relationship between groups. Thus, research questions and hypotheses clarify the main purpose and specific objectives of the study, which in turn dictate the design of the study, its direction, and outcome. Studies developed from good research questions and hypotheses will have trustworthy outcomes with wide-ranging social and health implications.
INTRODUCTION
Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses. 1 , 2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results. 3 , 4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the inception of novel studies and the ethical testing of ideas. 5 , 6
It is crucial to have knowledge of both quantitative and qualitative research 2 as both types of research involve writing research questions and hypotheses. 7 However, these crucial elements of research are sometimes overlooked; if not overlooked, then framed without the forethought and meticulous attention it needs. Planning and careful consideration are needed when developing quantitative or qualitative research, particularly when conceptualizing research questions and hypotheses. 4
There is a continuing need to support researchers in the creation of innovative research questions and hypotheses, as well as for journal articles that carefully review these elements. 1 When research questions and hypotheses are not carefully thought of, unethical studies and poor outcomes usually ensue. Carefully formulated research questions and hypotheses define well-founded objectives, which in turn determine the appropriate design, course, and outcome of the study. This article then aims to discuss in detail the various aspects of crafting research questions and hypotheses, with the goal of guiding researchers as they develop their own. Examples from the authors and peer-reviewed scientific articles in the healthcare field are provided to illustrate key points.
DEFINITIONS AND RELATIONSHIP OF RESEARCH QUESTIONS AND HYPOTHESES
A research question is what a study aims to answer after data analysis and interpretation. The answer is written in length in the discussion section of the paper. Thus, the research question gives a preview of the different parts and variables of the study meant to address the problem posed in the research question. 1 An excellent research question clarifies the research writing while facilitating understanding of the research topic, objective, scope, and limitations of the study. 5
On the other hand, a research hypothesis is an educated statement of an expected outcome. This statement is based on background research and current knowledge. 8 , 9 The research hypothesis makes a specific prediction about a new phenomenon 10 or a formal statement on the expected relationship between an independent variable and a dependent variable. 3 , 11 It provides a tentative answer to the research question to be tested or explored. 4
Hypotheses employ reasoning to predict a theory-based outcome. 10 These can also be developed from theories by focusing on components of theories that have not yet been observed. 10 The validity of hypotheses is often based on the testability of the prediction made in a reproducible experiment. 8
Conversely, hypotheses can also be rephrased as research questions. Several hypotheses based on existing theories and knowledge may be needed to answer a research question. Developing ethical research questions and hypotheses creates a research design that has logical relationships among variables. These relationships serve as a solid foundation for the conduct of the study. 4 , 11 Haphazardly constructed research questions can result in poorly formulated hypotheses and improper study designs, leading to unreliable results. Thus, the formulations of relevant research questions and verifiable hypotheses are crucial when beginning research. 12
CHARACTERISTICS OF GOOD RESEARCH QUESTIONS AND HYPOTHESES
Excellent research questions are specific and focused. These integrate collective data and observations to confirm or refute the subsequent hypotheses. Well-constructed hypotheses are based on previous reports and verify the research context. These are realistic, in-depth, sufficiently complex, and reproducible. More importantly, these hypotheses can be addressed and tested. 13
There are several characteristics of well-developed hypotheses. Good hypotheses are 1) empirically testable 7 , 10 , 11 , 13 ; 2) backed by preliminary evidence 9 ; 3) testable by ethical research 7 , 9 ; 4) based on original ideas 9 ; 5) have evidenced-based logical reasoning 10 ; and 6) can be predicted. 11 Good hypotheses can infer ethical and positive implications, indicating the presence of a relationship or effect relevant to the research theme. 7 , 11 These are initially developed from a general theory and branch into specific hypotheses by deductive reasoning. In the absence of a theory to base the hypotheses, inductive reasoning based on specific observations or findings form more general hypotheses. 10
TYPES OF RESEARCH QUESTIONS AND HYPOTHESES
Research questions and hypotheses are developed according to the type of research, which can be broadly classified into quantitative and qualitative research. We provide a summary of the types of research questions and hypotheses under quantitative and qualitative research categories in Table 1 .
Research questions in quantitative research
In quantitative research, research questions inquire about the relationships among variables being investigated and are usually framed at the start of the study. These are precise and typically linked to the subject population, dependent and independent variables, and research design. 1 Research questions may also attempt to describe the behavior of a population in relation to one or more variables, or describe the characteristics of variables to be measured ( descriptive research questions ). 1 , 5 , 14 These questions may also aim to discover differences between groups within the context of an outcome variable ( comparative research questions ), 1 , 5 , 14 or elucidate trends and interactions among variables ( relationship research questions ). 1 , 5 We provide examples of descriptive, comparative, and relationship research questions in quantitative research in Table 2 .
Hypotheses in quantitative research
In quantitative research, hypotheses predict the expected relationships among variables. 15 Relationships among variables that can be predicted include 1) between a single dependent variable and a single independent variable ( simple hypothesis ) or 2) between two or more independent and dependent variables ( complex hypothesis ). 4 , 11 Hypotheses may also specify the expected direction to be followed and imply an intellectual commitment to a particular outcome ( directional hypothesis ) 4 . On the other hand, hypotheses may not predict the exact direction and are used in the absence of a theory, or when findings contradict previous studies ( non-directional hypothesis ). 4 In addition, hypotheses can 1) define interdependency between variables ( associative hypothesis ), 4 2) propose an effect on the dependent variable from manipulation of the independent variable ( causal hypothesis ), 4 3) state a negative relationship between two variables ( null hypothesis ), 4 , 11 , 15 4) replace the working hypothesis if rejected ( alternative hypothesis ), 15 explain the relationship of phenomena to possibly generate a theory ( working hypothesis ), 11 5) involve quantifiable variables that can be tested statistically ( statistical hypothesis ), 11 6) or express a relationship whose interlinks can be verified logically ( logical hypothesis ). 11 We provide examples of simple, complex, directional, non-directional, associative, causal, null, alternative, working, statistical, and logical hypotheses in quantitative research, as well as the definition of quantitative hypothesis-testing research in Table 3 .
Research questions in qualitative research
Unlike research questions in quantitative research, research questions in qualitative research are usually continuously reviewed and reformulated. The central question and associated subquestions are stated more than the hypotheses. 15 The central question broadly explores a complex set of factors surrounding the central phenomenon, aiming to present the varied perspectives of participants. 15
There are varied goals for which qualitative research questions are developed. These questions can function in several ways, such as to 1) identify and describe existing conditions ( contextual research question s); 2) describe a phenomenon ( descriptive research questions ); 3) assess the effectiveness of existing methods, protocols, theories, or procedures ( evaluation research questions ); 4) examine a phenomenon or analyze the reasons or relationships between subjects or phenomena ( explanatory research questions ); or 5) focus on unknown aspects of a particular topic ( exploratory research questions ). 5 In addition, some qualitative research questions provide new ideas for the development of theories and actions ( generative research questions ) or advance specific ideologies of a position ( ideological research questions ). 1 Other qualitative research questions may build on a body of existing literature and become working guidelines ( ethnographic research questions ). Research questions may also be broadly stated without specific reference to the existing literature or a typology of questions ( phenomenological research questions ), may be directed towards generating a theory of some process ( grounded theory questions ), or may address a description of the case and the emerging themes ( qualitative case study questions ). 15 We provide examples of contextual, descriptive, evaluation, explanatory, exploratory, generative, ideological, ethnographic, phenomenological, grounded theory, and qualitative case study research questions in qualitative research in Table 4 , and the definition of qualitative hypothesis-generating research in Table 5 .
Qualitative studies usually pose at least one central research question and several subquestions starting with How or What . These research questions use exploratory verbs such as explore or describe . These also focus on one central phenomenon of interest, and may mention the participants and research site. 15
Hypotheses in qualitative research
Hypotheses in qualitative research are stated in the form of a clear statement concerning the problem to be investigated. Unlike in quantitative research where hypotheses are usually developed to be tested, qualitative research can lead to both hypothesis-testing and hypothesis-generating outcomes. 2 When studies require both quantitative and qualitative research questions, this suggests an integrative process between both research methods wherein a single mixed-methods research question can be developed. 1
FRAMEWORKS FOR DEVELOPING RESEARCH QUESTIONS AND HYPOTHESES
Research questions followed by hypotheses should be developed before the start of the study. 1 , 12 , 14 It is crucial to develop feasible research questions on a topic that is interesting to both the researcher and the scientific community. This can be achieved by a meticulous review of previous and current studies to establish a novel topic. Specific areas are subsequently focused on to generate ethical research questions. The relevance of the research questions is evaluated in terms of clarity of the resulting data, specificity of the methodology, objectivity of the outcome, depth of the research, and impact of the study. 1 , 5 These aspects constitute the FINER criteria (i.e., Feasible, Interesting, Novel, Ethical, and Relevant). 1 Clarity and effectiveness are achieved if research questions meet the FINER criteria. In addition to the FINER criteria, Ratan et al. described focus, complexity, novelty, feasibility, and measurability for evaluating the effectiveness of research questions. 14
The PICOT and PEO frameworks are also used when developing research questions. 1 The following elements are addressed in these frameworks, PICOT: P-population/patients/problem, I-intervention or indicator being studied, C-comparison group, O-outcome of interest, and T-timeframe of the study; PEO: P-population being studied, E-exposure to preexisting conditions, and O-outcome of interest. 1 Research questions are also considered good if these meet the “FINERMAPS” framework: Feasible, Interesting, Novel, Ethical, Relevant, Manageable, Appropriate, Potential value/publishable, and Systematic. 14
As we indicated earlier, research questions and hypotheses that are not carefully formulated result in unethical studies or poor outcomes. To illustrate this, we provide some examples of ambiguous research question and hypotheses that result in unclear and weak research objectives in quantitative research ( Table 6 ) 16 and qualitative research ( Table 7 ) 17 , and how to transform these ambiguous research question(s) and hypothesis(es) into clear and good statements.
a These statements were composed for comparison and illustrative purposes only.
b These statements are direct quotes from Higashihara and Horiuchi. 16
a This statement is a direct quote from Shimoda et al. 17
The other statements were composed for comparison and illustrative purposes only.
CONSTRUCTING RESEARCH QUESTIONS AND HYPOTHESES
To construct effective research questions and hypotheses, it is very important to 1) clarify the background and 2) identify the research problem at the outset of the research, within a specific timeframe. 9 Then, 3) review or conduct preliminary research to collect all available knowledge about the possible research questions by studying theories and previous studies. 18 Afterwards, 4) construct research questions to investigate the research problem. Identify variables to be accessed from the research questions 4 and make operational definitions of constructs from the research problem and questions. Thereafter, 5) construct specific deductive or inductive predictions in the form of hypotheses. 4 Finally, 6) state the study aims . This general flow for constructing effective research questions and hypotheses prior to conducting research is shown in Fig. 1 .

Research questions are used more frequently in qualitative research than objectives or hypotheses. 3 These questions seek to discover, understand, explore or describe experiences by asking “What” or “How.” The questions are open-ended to elicit a description rather than to relate variables or compare groups. The questions are continually reviewed, reformulated, and changed during the qualitative study. 3 Research questions are also used more frequently in survey projects than hypotheses in experiments in quantitative research to compare variables and their relationships.
Hypotheses are constructed based on the variables identified and as an if-then statement, following the template, ‘If a specific action is taken, then a certain outcome is expected.’ At this stage, some ideas regarding expectations from the research to be conducted must be drawn. 18 Then, the variables to be manipulated (independent) and influenced (dependent) are defined. 4 Thereafter, the hypothesis is stated and refined, and reproducible data tailored to the hypothesis are identified, collected, and analyzed. 4 The hypotheses must be testable and specific, 18 and should describe the variables and their relationships, the specific group being studied, and the predicted research outcome. 18 Hypotheses construction involves a testable proposition to be deduced from theory, and independent and dependent variables to be separated and measured separately. 3 Therefore, good hypotheses must be based on good research questions constructed at the start of a study or trial. 12
In summary, research questions are constructed after establishing the background of the study. Hypotheses are then developed based on the research questions. Thus, it is crucial to have excellent research questions to generate superior hypotheses. In turn, these would determine the research objectives and the design of the study, and ultimately, the outcome of the research. 12 Algorithms for building research questions and hypotheses are shown in Fig. 2 for quantitative research and in Fig. 3 for qualitative research.

EXAMPLES OF RESEARCH QUESTIONS FROM PUBLISHED ARTICLES
- EXAMPLE 1. Descriptive research question (quantitative research)
- - Presents research variables to be assessed (distinct phenotypes and subphenotypes)
- “BACKGROUND: Since COVID-19 was identified, its clinical and biological heterogeneity has been recognized. Identifying COVID-19 phenotypes might help guide basic, clinical, and translational research efforts.
- RESEARCH QUESTION: Does the clinical spectrum of patients with COVID-19 contain distinct phenotypes and subphenotypes? ” 19
- EXAMPLE 2. Relationship research question (quantitative research)
- - Shows interactions between dependent variable (static postural control) and independent variable (peripheral visual field loss)
- “Background: Integration of visual, vestibular, and proprioceptive sensations contributes to postural control. People with peripheral visual field loss have serious postural instability. However, the directional specificity of postural stability and sensory reweighting caused by gradual peripheral visual field loss remain unclear.
- Research question: What are the effects of peripheral visual field loss on static postural control ?” 20
- EXAMPLE 3. Comparative research question (quantitative research)
- - Clarifies the difference among groups with an outcome variable (patients enrolled in COMPERA with moderate PH or severe PH in COPD) and another group without the outcome variable (patients with idiopathic pulmonary arterial hypertension (IPAH))
- “BACKGROUND: Pulmonary hypertension (PH) in COPD is a poorly investigated clinical condition.
- RESEARCH QUESTION: Which factors determine the outcome of PH in COPD?
- STUDY DESIGN AND METHODS: We analyzed the characteristics and outcome of patients enrolled in the Comparative, Prospective Registry of Newly Initiated Therapies for Pulmonary Hypertension (COMPERA) with moderate or severe PH in COPD as defined during the 6th PH World Symposium who received medical therapy for PH and compared them with patients with idiopathic pulmonary arterial hypertension (IPAH) .” 21
- EXAMPLE 4. Exploratory research question (qualitative research)
- - Explores areas that have not been fully investigated (perspectives of families and children who receive care in clinic-based child obesity treatment) to have a deeper understanding of the research problem
- “Problem: Interventions for children with obesity lead to only modest improvements in BMI and long-term outcomes, and data are limited on the perspectives of families of children with obesity in clinic-based treatment. This scoping review seeks to answer the question: What is known about the perspectives of families and children who receive care in clinic-based child obesity treatment? This review aims to explore the scope of perspectives reported by families of children with obesity who have received individualized outpatient clinic-based obesity treatment.” 22
- EXAMPLE 5. Relationship research question (quantitative research)
- - Defines interactions between dependent variable (use of ankle strategies) and independent variable (changes in muscle tone)
- “Background: To maintain an upright standing posture against external disturbances, the human body mainly employs two types of postural control strategies: “ankle strategy” and “hip strategy.” While it has been reported that the magnitude of the disturbance alters the use of postural control strategies, it has not been elucidated how the level of muscle tone, one of the crucial parameters of bodily function, determines the use of each strategy. We have previously confirmed using forward dynamics simulations of human musculoskeletal models that an increased muscle tone promotes the use of ankle strategies. The objective of the present study was to experimentally evaluate a hypothesis: an increased muscle tone promotes the use of ankle strategies. Research question: Do changes in the muscle tone affect the use of ankle strategies ?” 23
EXAMPLES OF HYPOTHESES IN PUBLISHED ARTICLES
- EXAMPLE 1. Working hypothesis (quantitative research)
- - A hypothesis that is initially accepted for further research to produce a feasible theory
- “As fever may have benefit in shortening the duration of viral illness, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response when taken during the early stages of COVID-19 illness .” 24
- “In conclusion, it is plausible to hypothesize that the antipyretic efficacy of ibuprofen may be hindering the benefits of a fever response . The difference in perceived safety of these agents in COVID-19 illness could be related to the more potent efficacy to reduce fever with ibuprofen compared to acetaminophen. Compelling data on the benefit of fever warrant further research and review to determine when to treat or withhold ibuprofen for early stage fever for COVID-19 and other related viral illnesses .” 24
- EXAMPLE 2. Exploratory hypothesis (qualitative research)
- - Explores particular areas deeper to clarify subjective experience and develop a formal hypothesis potentially testable in a future quantitative approach
- “We hypothesized that when thinking about a past experience of help-seeking, a self distancing prompt would cause increased help-seeking intentions and more favorable help-seeking outcome expectations .” 25
- “Conclusion
- Although a priori hypotheses were not supported, further research is warranted as results indicate the potential for using self-distancing approaches to increasing help-seeking among some people with depressive symptomatology.” 25
- EXAMPLE 3. Hypothesis-generating research to establish a framework for hypothesis testing (qualitative research)
- “We hypothesize that compassionate care is beneficial for patients (better outcomes), healthcare systems and payers (lower costs), and healthcare providers (lower burnout). ” 26
- Compassionomics is the branch of knowledge and scientific study of the effects of compassionate healthcare. Our main hypotheses are that compassionate healthcare is beneficial for (1) patients, by improving clinical outcomes, (2) healthcare systems and payers, by supporting financial sustainability, and (3) HCPs, by lowering burnout and promoting resilience and well-being. The purpose of this paper is to establish a scientific framework for testing the hypotheses above . If these hypotheses are confirmed through rigorous research, compassionomics will belong in the science of evidence-based medicine, with major implications for all healthcare domains.” 26
- EXAMPLE 4. Statistical hypothesis (quantitative research)
- - An assumption is made about the relationship among several population characteristics ( gender differences in sociodemographic and clinical characteristics of adults with ADHD ). Validity is tested by statistical experiment or analysis ( chi-square test, Students t-test, and logistic regression analysis)
- “Our research investigated gender differences in sociodemographic and clinical characteristics of adults with ADHD in a Japanese clinical sample. Due to unique Japanese cultural ideals and expectations of women's behavior that are in opposition to ADHD symptoms, we hypothesized that women with ADHD experience more difficulties and present more dysfunctions than men . We tested the following hypotheses: first, women with ADHD have more comorbidities than men with ADHD; second, women with ADHD experience more social hardships than men, such as having less full-time employment and being more likely to be divorced.” 27
- “Statistical Analysis
- ( text omitted ) Between-gender comparisons were made using the chi-squared test for categorical variables and Students t-test for continuous variables…( text omitted ). A logistic regression analysis was performed for employment status, marital status, and comorbidity to evaluate the independent effects of gender on these dependent variables.” 27
EXAMPLES OF HYPOTHESIS AS WRITTEN IN PUBLISHED ARTICLES IN RELATION TO OTHER PARTS
- EXAMPLE 1. Background, hypotheses, and aims are provided
- “Pregnant women need skilled care during pregnancy and childbirth, but that skilled care is often delayed in some countries …( text omitted ). The focused antenatal care (FANC) model of WHO recommends that nurses provide information or counseling to all pregnant women …( text omitted ). Job aids are visual support materials that provide the right kind of information using graphics and words in a simple and yet effective manner. When nurses are not highly trained or have many work details to attend to, these job aids can serve as a content reminder for the nurses and can be used for educating their patients (Jennings, Yebadokpo, Affo, & Agbogbe, 2010) ( text omitted ). Importantly, additional evidence is needed to confirm how job aids can further improve the quality of ANC counseling by health workers in maternal care …( text omitted )” 28
- “ This has led us to hypothesize that the quality of ANC counseling would be better if supported by job aids. Consequently, a better quality of ANC counseling is expected to produce higher levels of awareness concerning the danger signs of pregnancy and a more favorable impression of the caring behavior of nurses .” 28
- “This study aimed to examine the differences in the responses of pregnant women to a job aid-supported intervention during ANC visit in terms of 1) their understanding of the danger signs of pregnancy and 2) their impression of the caring behaviors of nurses to pregnant women in rural Tanzania.” 28
- EXAMPLE 2. Background, hypotheses, and aims are provided
- “We conducted a two-arm randomized controlled trial (RCT) to evaluate and compare changes in salivary cortisol and oxytocin levels of first-time pregnant women between experimental and control groups. The women in the experimental group touched and held an infant for 30 min (experimental intervention protocol), whereas those in the control group watched a DVD movie of an infant (control intervention protocol). The primary outcome was salivary cortisol level and the secondary outcome was salivary oxytocin level.” 29
- “ We hypothesize that at 30 min after touching and holding an infant, the salivary cortisol level will significantly decrease and the salivary oxytocin level will increase in the experimental group compared with the control group .” 29
- EXAMPLE 3. Background, aim, and hypothesis are provided
- “In countries where the maternal mortality ratio remains high, antenatal education to increase Birth Preparedness and Complication Readiness (BPCR) is considered one of the top priorities [1]. BPCR includes birth plans during the antenatal period, such as the birthplace, birth attendant, transportation, health facility for complications, expenses, and birth materials, as well as family coordination to achieve such birth plans. In Tanzania, although increasing, only about half of all pregnant women attend an antenatal clinic more than four times [4]. Moreover, the information provided during antenatal care (ANC) is insufficient. In the resource-poor settings, antenatal group education is a potential approach because of the limited time for individual counseling at antenatal clinics.” 30
- “This study aimed to evaluate an antenatal group education program among pregnant women and their families with respect to birth-preparedness and maternal and infant outcomes in rural villages of Tanzania.” 30
- “ The study hypothesis was if Tanzanian pregnant women and their families received a family-oriented antenatal group education, they would (1) have a higher level of BPCR, (2) attend antenatal clinic four or more times, (3) give birth in a health facility, (4) have less complications of women at birth, and (5) have less complications and deaths of infants than those who did not receive the education .” 30
Research questions and hypotheses are crucial components to any type of research, whether quantitative or qualitative. These questions should be developed at the very beginning of the study. Excellent research questions lead to superior hypotheses, which, like a compass, set the direction of research, and can often determine the successful conduct of the study. Many research studies have floundered because the development of research questions and subsequent hypotheses was not given the thought and meticulous attention needed. The development of research questions and hypotheses is an iterative process based on extensive knowledge of the literature and insightful grasp of the knowledge gap. Focused, concise, and specific research questions provide a strong foundation for constructing hypotheses which serve as formal predictions about the research outcomes. Research questions and hypotheses are crucial elements of research that should not be overlooked. They should be carefully thought of and constructed when planning research. This avoids unethical studies and poor outcomes by defining well-founded objectives that determine the design, course, and outcome of the study.
Disclosure: The authors have no potential conflicts of interest to disclose.
Author Contributions:
- Conceptualization: Barroga E, Matanguihan GJ.
- Methodology: Barroga E, Matanguihan GJ.
- Writing - original draft: Barroga E, Matanguihan GJ.
- Writing - review & editing: Barroga E, Matanguihan GJ.

Aims And Hypotheses, Directional And Non-Directional
March 7, 2021 - paper 2 psychology in context | research methods.
- Back to Paper 2 - Research Methods
In Psychology, hypotheses are predictions made by the researcher about the outcome of a study. The research can chose to make a specific prediction about what they feel will happen in their research (a directional hypothesis) or they can make a ‘general,’ ‘less specific’ prediction about the outcome of their research (a non-directional hypothesis). The type of prediction that a researcher makes is usually dependent on whether or not any previous research has also investigated their research aim.
Variables Recap:
The independent variable (IV) is the variable that psychologists manipulate/change to see if changing this variable has an effect on the depen dent variable (DV).
The dependent variable (DV) is the variable that the psychologists measures (to see if the IV has had an effect).
It is important that the only variable that is changed in research is the independent variable (IV), all other variables have to be kept constant across the control condition and the experimental conditions. Only then will researchers be able to observe the true effects of just the independent variable (IV) on the dependent variable (DV).
Research/Experimental Aim(S):

An aim is a clear and precise statement of the purpose of the study. It is a statement of why a research study is taking place. This should include what is being studied and what the study is trying to achieve. (e.g. “This study aims to investigate the effects of alcohol on reaction times”.
It is important that aims created in research are realistic and ethical.
Hypotheses:
This is a testable statement that predicts what the researcher expects to happen in their research. The research study itself is therefore a means of testing whether or not the hypothesis is supported by the findings. If the findings do support the hypothesis then the hypothesis can be retained (i.e., accepted), but if not, then it must be rejected.
Three Different Hypotheses:

We're not around right now. But you can send us an email and we'll get back to you, asap.
Start typing and press Enter to search
Cookie Policy - Terms and Conditions - Privacy Policy
6 Hypothesis Examples in Psychology
The hypothesis is one of the most important steps of psychological research. Hypothesis refers to an assumption or the temporary statement made by the researcher before the execution of the experiment, regarding the possible outcome of that experiment. A hypothesis can be tested through various scientific and statistical tools. It is a logical guess based on previous knowledge and investigations related to the problem under investigation. In this article, we’ll learn about the significance of the hypothesis, the sources of the hypothesis, and the various examples of the hypothesis.
Sources of Hypothesis
The formulation of a good hypothesis is not an easy task. One needs to take care of the various crucial steps to get an accurate hypothesis. The hypothesis formulation demands both the creativity of the researcher and his/her years of experience. The researcher needs to use critical thinking to avoid committing any errors such as choosing the wrong hypothesis. Although the hypothesis is considered the first step before further investigations such as data collection for the experiment, the hypothesis formulation also requires some amount of data collection. The data collection for the hypothesis formulation refers to the review of literature related to the concerned topic, and understanding of the previous research on the related topic. Following are some of the main sources of the hypothesis that may help the researcher to formulate a good hypothesis.
- Reviewing the similar studies and literature related to a similar problem.
- Examining the available data concerned with the problem.
- Discussing the problem with the colleagues, or the professional researchers about the problem under investigation.
- Thorough research and investigation by conducting field interviews or surveys on the people that are directly concerned with the problem under investigation.
- Sometimes ‘institution’ of the well known and experienced researcher is also considered as a good source of the hypothesis formulation.
Real Life Hypothesis Examples
1. null hypothesis and alternative hypothesis examples.
Every research problem-solving procedure begins with the formulation of the null hypothesis and the alternative hypothesis. The alternative hypothesis assumes the existence of the relationship between the variables under study, while the null hypothesis denies the relationship between the variables under study. Following are examples of the null hypothesis and the alternative hypothesis based on the research problem.
Research Problem: What is the benefit of eating an apple daily on your health?
Alternative Hypothesis: Eating an apple daily reduces the chances of visiting the doctor.
Null Hypothesis : Eating an apple daily does not impact the frequency of visiting the doctor.
Research Problem: What is the impact of spending a lot of time on mobiles on the attention span of teenagers.
Alternative Problem: Spending time on the mobiles and attention span have a negative correlation.
Null Hypothesis: There does not exist any correlation between the use of mobile by teenagers on their attention span.
Research Problem: What is the impact of providing flexible working hours to the employees on the job satisfaction level.
Alternative Hypothesis : Employees who get the option of flexible working hours have better job satisfaction than the employees who don’t get the option of flexible working hours.
Null Hypothesis: There is no association between providing flexible working hours and job satisfaction.
2. Simple Hypothesis Examples
The hypothesis that includes only one independent variable (predictor variable) and one dependent variable (outcome variable) is termed the simple hypothesis. For example, the children are more likely to get clinical depression if their parents had also suffered from the clinical depression. Here, the independent variable is the parents suffering from clinical depression and the dependent or the outcome variable is the clinical depression observed in their child/children. Other examples of the simple hypothesis are given below,
- If the management provides the official snack breaks to the employees, the employees are less likely to take the off-site breaks. Here, providing snack breaks is the independent variable and the employees are less likely to take the off-site break is the dependent variable.
3. Complex Hypothesis Examples
If the hypothesis includes more than one independent (predictor variable) or more than one dependent variable (outcome variable) it is known as the complex hypothesis. For example, clinical depression in children is associated with a family clinical depression history and a stressful and hectic lifestyle. In this case, there are two independent variables, i.e., family history of clinical depression and hectic and stressful lifestyle, and one dependent variable, i.e., clinical depression. Following are some more examples of the complex hypothesis,
4. Logical Hypothesis Examples
If there are not many pieces of evidence and studies related to the concerned problem, then the researcher can take the help of the general logic to formulate the hypothesis. The logical hypothesis is proved true through various logic. For example, if the researcher wants to prove that the animal needs water for its survival, then this can be logically verified through the logic that ‘living beings can not survive without the water.’ Following are some more examples of logical hypotheses,
- Tia is not good at maths, hence she will not choose the accounting sector as her career.
- If there is a correlation between skin cancer and ultraviolet rays, then the people who are more exposed to the ultraviolet rays are more prone to skin cancer.
- The beings belonging to the different planets can not breathe in the earth’s atmosphere.
- The creatures living in the sea use anaerobic respiration as those living outside the sea use aerobic respiration.
5. Empirical Hypothesis Examples
The empirical hypothesis comes into existence when the statement is being tested by conducting various experiments. This hypothesis is not just an idea or notion, instead, it refers to the statement that undergoes various trials and errors, and various extraneous variables can impact the result. The trials and errors provide a set of results that can be testable over time. Following are the examples of the empirical hypothesis,
- The hungry cat will quickly reach the endpoint through the maze, if food is placed at the endpoint then the cat is not hungry.
- The people who consume vitamin c have more glowing skin than the people who consume vitamin E.
- Hair growth is faster after the consumption of Vitamin E than vitamin K.
- Plants will grow faster with fertilizer X than with fertilizer Y.
6. Statistical Hypothesis Examples
The statements that can be proven true by using the various statistical tools are considered the statistical hypothesis. The researcher uses statistical data about an area or the group in the analysis of the statistical hypothesis. For example, if you study the IQ level of the women belonging to nation X, it would be practically impossible to measure the IQ level of each woman belonging to nation X. Here, statistical methods come to the rescue. The researcher can choose the sample population, i.e., women belonging to the different states or provinces of the nation X, and conduct the statistical tests on this sample population to get the average IQ of the women belonging to the nation X. Following are the examples of the statistical hypothesis.
- 30 per cent of the women belonging to the nation X are working.
- 50 per cent of the people living in the savannah are above the age of 70 years.
- 45 per cent of the poor people in the United States are uneducated.
Significance of Hypothesis
A hypothesis is very crucial in experimental research as it aims to predict any particular outcome of the experiment. Hypothesis plays an important role in guiding the researchers to focus on the concerned area of research only. However, the hypothesis is not required by all researchers. The type of research that seeks for finding facts, i.e., historical research, does not need the formulation of the hypothesis. In the historical research, the researchers look for the pieces of evidence related to the human life, the history of a particular area, or the occurrence of any event, this means that the researcher does not have a strong basis to make an assumption in these types of researches, hence hypothesis is not needed in this case. As stated by Hillway (1964)
When fact-finding alone is the aim of the study, a hypothesis is not required.”
The hypothesis may not be an important part of the descriptive or historical studies, but it is a crucial part for the experimental researchers. Following are some of the points that show the importance of formulating a hypothesis before conducting the experiment.
- Hypothesis provides a tentative statement about the outcome of the experiment that can be validated and tested. It helps the researcher to directly focus on the problem under investigation by collecting the relevant data according to the variables mentioned in the hypothesis.
- Hypothesis facilitates a direction to the experimental research. It helps the researcher in analysing what is relevant for the study and what’s not. It prevents the researcher’s time as he does not need to waste time on reviewing the irrelevant research and literature, and also prevents the researcher from collecting the irrelevant data.
- Hypothesis helps the researcher in choosing the appropriate sample, statistical tests to conduct, variables to be studied and the research methodology. The hypothesis also helps the study from being generalised as it focuses on the limited and exact problem under investigation.
- Hypothesis act as a framework for deducing the outcomes of the experiment. The researcher can easily test the different hypotheses for understanding the interaction among the various variables involved in the study. On this basis of the results obtained from the testing of various hypotheses, the researcher can formulate the final meaningful report.
Related Posts
4 Virtue Ethics Examples in Real Life
Gaslighting Behavior
6 Real Life Examples Of Game Theory
22 Altruism Examples in Animals
7 Examples of Classical Conditioning in Everyday life
8 Egoistic Altruism Examples
Add comment cancel reply.

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Overview of the Scientific Method
11 Designing a Research Study
Learning objectives.
- Define the concept of a variable, distinguish quantitative from categorical variables, and give examples of variables that might be of interest to psychologists.
- Explain the difference between a population and a sample.
- Distinguish between experimental and non-experimental research.
- Distinguish between lab studies, field studies, and field experiments.
Identifying and Defining the Variables and Population
Variables and operational definitions.
Part of generating a hypothesis involves identifying the variables that you want to study and operationally defining those variables so that they can be measured. Research questions in psychology are about variables. A variable is a quantity or quality that varies across people or situations. For example, the height of the students enrolled in a university course is a variable because it varies from student to student. The chosen major of the students is also a variable as long as not everyone in the class has declared the same major. Almost everything in our world varies and as such thinking of examples of constants (things that don’t vary) is far more difficult. A rare example of a constant is the speed of light. Variables can be either quantitative or categorical. A quantitative variable is a quantity, such as height, that is typically measured by assigning a number to each individual. Other examples of quantitative variables include people’s level of talkativeness, how depressed they are, and the number of siblings they have. A categorical variable is a quality, such as chosen major, and is typically measured by assigning a category label to each individual (e.g., Psychology, English, Nursing, etc.). Other examples include people’s nationality, their occupation, and whether they are receiving psychotherapy.
After the researcher generates their hypothesis and selects the variables they want to manipulate and measure, the researcher needs to find ways to actually measure the variables of interest. This requires an operational definition —a definition of the variable in terms of precisely how it is to be measured. Most variables that researchers are interested in studying cannot be directly observed or measured and this poses a problem because empiricism (observation) is at the heart of the scientific method. Operationally defining a variable involves taking an abstract construct like depression that cannot be directly observed and transforming it into something that can be directly observed and measured. Most variables can be operationally defined in many different ways. For example, depression can be operationally defined as people’s scores on a paper-and-pencil depression scale such as the Beck Depression Inventory, the number of depressive symptoms they are experiencing, or whether they have been diagnosed with major depressive disorder. Researchers are wise to choose an operational definition that has been used extensively in the research literature.
Sampling and Measurement
In addition to identifying which variables to manipulate and measure, and operationally defining those variables, researchers need to identify the population of interest. Researchers in psychology are usually interested in drawing conclusions about some very large group of people. This is called the population . It could be all American teenagers, children with autism, professional athletes, or even just human beings—depending on the interests and goals of the researcher. But they usually study only a small subset or sample of the population. For example, a researcher might measure the talkativeness of a few hundred university students with the intention of drawing conclusions about the talkativeness of men and women in general. It is important, therefore, for researchers to use a representative sample—one that is similar to the population in important respects.
One method of obtaining a sample is simple random sampling , in which every member of the population has an equal chance of being selected for the sample. For example, a pollster could start with a list of all the registered voters in a city (the population), randomly select 100 of them from the list (the sample), and ask those 100 whom they intend to vote for. Unfortunately, random sampling is difficult or impossible in most psychological research because the populations are less clearly defined than the registered voters in a city. How could a researcher give all American teenagers or all children with autism an equal chance of being selected for a sample? The most common alternative to random sampling is convenience sampling , in which the sample consists of individuals who happen to be nearby and willing to participate (such as introductory psychology students). Of course, the obvious problem with convenience sampling is that the sample might not be representative of the population and therefore it may be less appropriate to generalize the results from the sample to that population.
Experimental vs. Non-Experimental Research
The next step a researcher must take is to decide which type of approach they will use to collect the data. As you will learn in your research methods course there are many different approaches to research that can be divided in many different ways. One of the most fundamental distinctions is between experimental and non-experimental research.
Experimental Research
Researchers who want to test hypotheses about causal relationships between variables (i.e., their goal is to explain) need to use an experimental method. This is because the experimental method is the only method that allows us to determine causal relationships. Using the experimental approach, researchers first manipulate one or more variables while attempting to control extraneous variables, and then they measure how the manipulated variables affect participants’ responses.
The terms independent variable and dependent variable are used in the context of experimental research. The independent variable is the variable the experimenter manipulates (it is the presumed cause) and the dependent variable is the variable the experimenter measures (it is the presumed effect).
Extraneous variables are any variable other than the dependent variable. Confounds are a specific type of extraneous variable that systematically varies along with the variables under investigation and therefore provides an alternative explanation for the results. When researchers design an experiment they need to ensure that they control for confounds; they need to ensure that extraneous variables don’t become confounding variables because in order to make a causal conclusion they need to make sure alternative explanations for the results have been ruled out.
As an example, if we manipulate the lighting in the room and examine the effects of that manipulation on workers’ productivity, then the lighting conditions (bright lights vs. dim lights) would be considered the independent variable and the workers’ productivity would be considered the dependent variable. If the bright lights are noisy then that noise would be a confound since the noise would be present whenever the lights are bright and the noise would be absent when the lights are dim. If noise is varying systematically with light then we wouldn’t know if a difference in worker productivity across the two lighting conditions is due to noise or light. So confounds are bad, they disrupt our ability to make causal conclusions about the nature of the relationship between variables. However, if there is noise in the room both when the lights are on and when the lights are off then noise is merely an extraneous variable (it is a variable other than the independent or dependent variable) and we don’t worry much about extraneous variables. This is because unless a variable varies systematically with the manipulated independent variable it cannot be a competing explanation for the results.
Non-Experimental Research
Researchers who are simply interested in describing characteristics of people, describing relationships between variables, and using those relationships to make predictions can use non-experimental research. Using the non-experimental approach, the researcher simply measures variables as they naturally occur, but they do not manipulate them. For instance, if I just measured the number of traffic fatalities in America last year that involved the use of a cell phone but I did not actually manipulate cell phone use then this would be categorized as non-experimental research. Alternatively, if I stood at a busy intersection and recorded drivers’ genders and whether or not they were using a cell phone when they passed through the intersection to see whether men or women are more likely to use a cell phone when driving, then this would be non-experimental research. It is important to point out that non-experimental does not mean nonscientific. Non-experimental research is scientific in nature. It can be used to fulfill two of the three goals of science (to describe and to predict). However, unlike with experimental research, we cannot make causal conclusions using this method; we cannot say that one variable causes another variable using this method.
Laboratory vs. Field Research
The next major distinction between research methods is between laboratory and field studies. A laboratory study is a study that is conducted in the laboratory environment. In contrast, a field study is a study that is conducted in the real-world, in a natural environment.
Laboratory experiments typically have high internal validity . Internal validity refers to the degree to which we can confidently infer a causal relationship between variables. When we conduct an experimental study in a laboratory environment we have very high internal validity because we manipulate one variable while controlling all other outside extraneous variables. When we manipulate an independent variable and observe an effect on a dependent variable and we control for everything else so that the only difference between our experimental groups or conditions is the one manipulated variable then we can be quite confident that it is the independent variable that is causing the change in the dependent variable. In contrast, because field studies are conducted in the real-world, the experimenter typically has less control over the environment and potential extraneous variables, and this decreases internal validity, making it less appropriate to arrive at causal conclusions.
But there is typically a trade-off between internal and external validity. External validity simply refers to the degree to which we can generalize the findings to other circumstances or settings, like the real-world environment. When internal validity is high, external validity tends to be low; and when internal validity is low, external validity tends to be high. So laboratory studies are typically low in external validity, while field studies are typically high in external validity. Since field studies are conducted in the real-world environment it is far more appropriate to generalize the findings to that real-world environment than when the research is conducted in the more artificial sterile laboratory.
Finally, there are field studies which are non-experimental in nature because nothing is manipulated. But there are also field experiment s where an independent variable is manipulated in a natural setting and extraneous variables are controlled. Depending on their overall quality and the level of control of extraneous variables, such field experiments can have high external and high internal validity.
A quantity or quality that varies across people or situations.
A quantity, such as height, that is typically measured by assigning a number to each individual.
A variable that represents a characteristic of an individual, such as chosen major, and is typically measured by assigning each individual's response to one of several categories (e.g., Psychology, English, Nursing, Engineering, etc.).
A definition of the variable in terms of precisely how it is to be measured.
A large group of people about whom researchers in psychology are usually interested in drawing conclusions, and from whom the sample is drawn.
A smaller portion of the population the researcher would like to study.
A common method of non-probability sampling in which the sample consists of individuals who happen to be easily available and willing to participate (such as introductory psychology students).
The variable the experimenter manipulates.
The variable the experimenter measures (it is the presumed effect).
Any variable other than the dependent and independent variable.
A specific type of extraneous variable that systematically varies along with the variables under investigation and therefore provides an alternative explanation for the results.
A study that is conducted in the laboratory environment.
A study that is conducted in a "real world" environment outside the laboratory.
Refers to the degree to which we can confidently infer a causal relationship between variables.
Refers to the degree to which we can generalize the findings to other circumstances or settings, like the real-world environment.
A type of field study where an independent variable is manipulated in a natural setting and extraneous variables are controlled as much as possible.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Research Methods In Psychology
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
Research methods in psychology are systematic procedures used to observe, describe, predict, and explain behavior and mental processes. They include experiments, surveys, case studies, and naturalistic observations, ensuring data collection is objective and reliable to understand and explain psychological phenomena.

Hypotheses are statements about the prediction of the results, that can be verified or disproved by some investigation.
There are four types of hypotheses :
- Null Hypotheses (H0 ) – these predict that no difference will be found in the results between the conditions. Typically these are written ‘There will be no difference…’
- Alternative Hypotheses (Ha or H1) – these predict that there will be a significant difference in the results between the two conditions. This is also known as the experimental hypothesis.
- One-tailed (directional) hypotheses – these state the specific direction the researcher expects the results to move in, e.g. higher, lower, more, less. In a correlation study, the predicted direction of the correlation can be either positive or negative.
- Two-tailed (non-directional) hypotheses – these state that a difference will be found between the conditions of the independent variable but does not state the direction of a difference or relationship. Typically these are always written ‘There will be a difference ….’
All research has an alternative hypothesis (either a one-tailed or two-tailed) and a corresponding null hypothesis.
Once the research is conducted and results are found, psychologists must accept one hypothesis and reject the other.
So, if a difference is found, the Psychologist would accept the alternative hypothesis and reject the null. The opposite applies if no difference is found.
Sampling techniques
Sampling is the process of selecting a representative group from the population under study.

A sample is the participants you select from a target population (the group you are interested in) to make generalizations about.
Representative means the extent to which a sample mirrors a researcher’s target population and reflects its characteristics.
Generalisability means the extent to which their findings can be applied to the larger population of which their sample was a part.
- Volunteer sample : where participants pick themselves through newspaper adverts, noticeboards or online.
- Opportunity sampling : also known as convenience sampling , uses people who are available at the time the study is carried out and willing to take part. It is based on convenience.
- Random sampling : when every person in the target population has an equal chance of being selected. An example of random sampling would be picking names out of a hat.
- Systematic sampling : when a system is used to select participants. Picking every Nth person from all possible participants. N = the number of people in the research population / the number of people needed for the sample.
- Stratified sampling : when you identify the subgroups and select participants in proportion to their occurrences.
- Snowball sampling : when researchers find a few participants, and then ask them to find participants themselves and so on.
- Quota sampling : when researchers will be told to ensure the sample fits certain quotas, for example they might be told to find 90 participants, with 30 of them being unemployed.
Experiments always have an independent and dependent variable .
- The independent variable is the one the experimenter manipulates (the thing that changes between the conditions the participants are placed into). It is assumed to have a direct effect on the dependent variable.
- The dependent variable is the thing being measured, or the results of the experiment.

Operationalization of variables means making them measurable/quantifiable. We must use operationalization to ensure that variables are in a form that can be easily tested.
For instance, we can’t really measure ‘happiness’, but we can measure how many times a person smiles within a two-hour period.
By operationalizing variables, we make it easy for someone else to replicate our research. Remember, this is important because we can check if our findings are reliable.
Extraneous variables are all variables which are not independent variable but could affect the results of the experiment.
It can be a natural characteristic of the participant, such as intelligence levels, gender, or age for example, or it could be a situational feature of the environment such as lighting or noise.
Demand characteristics are a type of extraneous variable that occurs if the participants work out the aims of the research study, they may begin to behave in a certain way.
For example, in Milgram’s research , critics argued that participants worked out that the shocks were not real and they administered them as they thought this was what was required of them.
Extraneous variables must be controlled so that they do not affect (confound) the results.
Randomly allocating participants to their conditions or using a matched pairs experimental design can help to reduce participant variables.
Situational variables are controlled by using standardized procedures, ensuring every participant in a given condition is treated in the same way
Experimental Design
Experimental design refers to how participants are allocated to each condition of the independent variable, such as a control or experimental group.
- Independent design ( between-groups design ): each participant is selected for only one group. With the independent design, the most common way of deciding which participants go into which group is by means of randomization.
- Matched participants design : each participant is selected for only one group, but the participants in the two groups are matched for some relevant factor or factors (e.g. ability; sex; age).
- Repeated measures design ( within groups) : each participant appears in both groups, so that there are exactly the same participants in each group.
- The main problem with the repeated measures design is that there may well be order effects. Their experiences during the experiment may change the participants in various ways.
- They may perform better when they appear in the second group because they have gained useful information about the experiment or about the task. On the other hand, they may perform less well on the second occasion because of tiredness or boredom.
- Counterbalancing is the best way of preventing order effects from disrupting the findings of an experiment, and involves ensuring that each condition is equally likely to be used first and second by the participants.
If we wish to compare two groups with respect to a given independent variable, it is essential to make sure that the two groups do not differ in any other important way.
Experimental Methods
All experimental methods involve an iv (independent variable) and dv (dependent variable)..
- Field experiments are conducted in the everyday (natural) environment of the participants. The experimenter still manipulates the IV, but in a real-life setting. It may be possible to control extraneous variables, though such control is more difficult than in a lab experiment.
- Natural experiments are when a naturally occurring IV is investigated that isn’t deliberately manipulated, it exists anyway. Participants are not randomly allocated, and the natural event may only occur rarely.
Case studies are in-depth investigations of a person, group, event, or community. It uses information from a range of sources, such as from the person concerned and also from their family and friends.
Many techniques may be used such as interviews, psychological tests, observations and experiments. Case studies are generally longitudinal: in other words, they follow the individual or group over an extended period of time.
Case studies are widely used in psychology and among the best-known ones carried out were by Sigmund Freud . He conducted very detailed investigations into the private lives of his patients in an attempt to both understand and help them overcome their illnesses.
Case studies provide rich qualitative data and have high levels of ecological validity. However, it is difficult to generalize from individual cases as each one has unique characteristics.
Correlational Studies
Correlation means association; it is a measure of the extent to which two variables are related. One of the variables can be regarded as the predictor variable with the other one as the outcome variable.
Correlational studies typically involve obtaining two different measures from a group of participants, and then assessing the degree of association between the measures.
The predictor variable can be seen as occurring before the outcome variable in some sense. It is called the predictor variable, because it forms the basis for predicting the value of the outcome variable.
Relationships between variables can be displayed on a graph or as a numerical score called a correlation coefficient.

- If an increase in one variable tends to be associated with an increase in the other, then this is known as a positive correlation .
- If an increase in one variable tends to be associated with a decrease in the other, then this is known as a negative correlation .
- A zero correlation occurs when there is no relationship between variables.
After looking at the scattergraph, if we want to be sure that a significant relationship does exist between the two variables, a statistical test of correlation can be conducted, such as Spearman’s rho.
The test will give us a score, called a correlation coefficient . This is a value between 0 and 1, and the closer to 1 the score is, the stronger the relationship between the variables. This value can be both positive e.g. 0.63, or negative -0.63.

A correlation between variables, however, does not automatically mean that the change in one variable is the cause of the change in the values of the other variable. A correlation only shows if there is a relationship between variables.
Correlation does not always prove causation, as a third variable may be involved.

Interview Methods
Interviews are commonly divided into two types: structured and unstructured.
A fixed, predetermined set of questions is put to every participant in the same order and in the same way.
Responses are recorded on a questionnaire, and the researcher presets the order and wording of questions, and sometimes the range of alternative answers.
The interviewer stays within their role and maintains social distance from the interviewee.
There are no set questions, and the participant can raise whatever topics he/she feels are relevant and ask them in their own way. Questions are posed about participants’ answers to the subject
Unstructured interviews are most useful in qualitative research to analyze attitudes and values.
Though they rarely provide a valid basis for generalization, their main advantage is that they enable the researcher to probe social actors’ subjective point of view.
Questionnaire Method
Questionnaires can be thought of as a kind of written interview. They can be carried out face to face, by telephone, or post.
The choice of questions is important because of the need to avoid bias or ambiguity in the questions, ‘leading’ the respondent or causing offense.
- Open questions are designed to encourage a full, meaningful answer using the subject’s own knowledge and feelings. They provide insights into feelings, opinions, and understanding. Example: “How do you feel about that situation?”
- Closed questions can be answered with a simple “yes” or “no” or specific information, limiting the depth of response. They are useful for gathering specific facts or confirming details. Example: “Do you feel anxious in crowds?”
Its other practical advantages are that it is cheaper than face-to-face interviews and can be used to contact many respondents scattered over a wide area relatively quickly.
Observations
There are different types of observation methods :
- Covert observation is where the researcher doesn’t tell the participants they are being observed until after the study is complete. There could be ethical problems or deception and consent with this particular observation method.
- Overt observation is where a researcher tells the participants they are being observed and what they are being observed for.
- Controlled : behavior is observed under controlled laboratory conditions (e.g., Bandura’s Bobo doll study).
- Natural : Here, spontaneous behavior is recorded in a natural setting.
- Participant : Here, the observer has direct contact with the group of people they are observing. The researcher becomes a member of the group they are researching.
- Non-participant (aka “fly on the wall): The researcher does not have direct contact with the people being observed. The observation of participants’ behavior is from a distance
Pilot Study
A pilot study is a small scale preliminary study conducted in order to evaluate the feasibility of the key s teps in a future, full-scale project.
A pilot study is an initial run-through of the procedures to be used in an investigation; it involves selecting a few people and trying out the study on them. It is possible to save time, and in some cases, money, by identifying any flaws in the procedures designed by the researcher.
A pilot study can help the researcher spot any ambiguities (i.e. unusual things) or confusion in the information given to participants or problems with the task devised.
Sometimes the task is too hard, and the researcher may get a floor effect, because none of the participants can score at all or can complete the task – all performances are low.
The opposite effect is a ceiling effect, when the task is so easy that all achieve virtually full marks or top performances and are “hitting the ceiling”.
Research Design
In cross-sectional research , a researcher compares multiple segments of the population at the same time
Sometimes, we want to see how people change over time, as in studies of human development and lifespan. Longitudinal research is a research design in which data-gathering is administered repeatedly over an extended period of time.
In cohort studies , the participants must share a common factor or characteristic such as age, demographic, or occupation. A cohort study is a type of longitudinal study in which researchers monitor and observe a chosen population over an extended period.
Triangulation means using more than one research method to improve the study’s validity.
Reliability
Reliability is a measure of consistency, if a particular measurement is repeated and the same result is obtained then it is described as being reliable.
- Test-retest reliability : assessing the same person on two different occasions which shows the extent to which the test produces the same answers.
- Inter-observer reliability : the extent to which there is an agreement between two or more observers.
Meta-Analysis
A meta-analysis is a systematic review that involves identifying an aim and then searching for research studies that have addressed similar aims/hypotheses.
This is done by looking through various databases, and then decisions are made about what studies are to be included/excluded.
Strengths: Increases the conclusions’ validity as they’re based on a wider range.
Weaknesses: Research designs in studies can vary, so they are not truly comparable.
Peer Review
A researcher submits an article to a journal. The choice of the journal may be determined by the journal’s audience or prestige.
The journal selects two or more appropriate experts (psychologists working in a similar field) to peer review the article without payment. The peer reviewers assess: the methods and designs used, originality of the findings, the validity of the original research findings and its content, structure and language.
Feedback from the reviewer determines whether the article is accepted. The article may be: Accepted as it is, accepted with revisions, sent back to the author to revise and re-submit or rejected without the possibility of submission.
The editor makes the final decision whether to accept or reject the research report based on the reviewers comments/ recommendations.
Peer review is important because it prevent faulty data from entering the public domain, it provides a way of checking the validity of findings and the quality of the methodology and is used to assess the research rating of university departments.
Peer reviews may be an ideal, whereas in practice there are lots of problems. For example, it slows publication down and may prevent unusual, new work being published. Some reviewers might use it as an opportunity to prevent competing researchers from publishing work.
Some people doubt whether peer review can really prevent the publication of fraudulent research.
The advent of the internet means that a lot of research and academic comment is being published without official peer reviews than before, though systems are evolving on the internet where everyone really has a chance to offer their opinions and police the quality of research.
Types of Data
- Quantitative data is numerical data e.g. reaction time or number of mistakes. It represents how much or how long, how many there are of something. A tally of behavioral categories and closed questions in a questionnaire collect quantitative data.
- Qualitative data is virtually any type of information that can be observed and recorded that is not numerical in nature and can be in the form of written or verbal communication. Open questions in questionnaires and accounts from observational studies collect qualitative data.
- Primary data is first-hand data collected for the purpose of the investigation.
- Secondary data is information that has been collected by someone other than the person who is conducting the research e.g. taken from journals, books or articles.
Validity means how well a piece of research actually measures what it sets out to, or how well it reflects the reality it claims to represent.
Validity is whether the observed effect is genuine and represents what is actually out there in the world.
- Concurrent validity is the extent to which a psychological measure relates to an existing similar measure and obtains close results. For example, a new intelligence test compared to an established test.
- Face validity : does the test measure what it’s supposed to measure ‘on the face of it’. This is done by ‘eyeballing’ the measuring or by passing it to an expert to check.
- Ecological validit y is the extent to which findings from a research study can be generalized to other settings / real life.
- Temporal validity is the extent to which findings from a research study can be generalized to other historical times.
Features of Science
- Paradigm – A set of shared assumptions and agreed methods within a scientific discipline.
- Paradigm shift – The result of the scientific revolution: a significant change in the dominant unifying theory within a scientific discipline.
- Objectivity – When all sources of personal bias are minimised so not to distort or influence the research process.
- Empirical method – Scientific approaches that are based on the gathering of evidence through direct observation and experience.
- Replicability – The extent to which scientific procedures and findings can be repeated by other researchers.
- Falsifiability – The principle that a theory cannot be considered scientific unless it admits the possibility of being proved untrue.
Statistical Testing
A significant result is one where there is a low probability that chance factors were responsible for any observed difference, correlation, or association in the variables tested.
If our test is significant, we can reject our null hypothesis and accept our alternative hypothesis.
If our test is not significant, we can accept our null hypothesis and reject our alternative hypothesis. A null hypothesis is a statement of no effect.
In Psychology, we use p < 0.05 (as it strikes a balance between making a type I and II error) but p < 0.01 is used in tests that could cause harm like introducing a new drug.
A type I error is when the null hypothesis is rejected when it should have been accepted (happens when a lenient significance level is used, an error of optimism).
A type II error is when the null hypothesis is accepted when it should have been rejected (happens when a stringent significance level is used, an error of pessimism).
Ethical Issues
- Informed consent is when participants are able to make an informed judgment about whether to take part. It causes them to guess the aims of the study and change their behavior.
- To deal with it, we can gain presumptive consent or ask them to formally indicate their agreement to participate but it may invalidate the purpose of the study and it is not guaranteed that the participants would understand.
- Deception should only be used when it is approved by an ethics committee, as it involves deliberately misleading or withholding information. Participants should be fully debriefed after the study but debriefing can’t turn the clock back.
- All participants should be informed at the beginning that they have the right to withdraw if they ever feel distressed or uncomfortable.
- It causes bias as the ones that stayed are obedient and some may not withdraw as they may have been given incentives or feel like they’re spoiling the study. Researchers can offer the right to withdraw data after participation.
- Participants should all have protection from harm . The researcher should avoid risks greater than those experienced in everyday life and they should stop the study if any harm is suspected. However, the harm may not be apparent at the time of the study.
- Confidentiality concerns the communication of personal information. The researchers should not record any names but use numbers or false names though it may not be possible as it is sometimes possible to work out who the researchers were.
Asking the right questions about the psychology of human inquiry: Nine open challenges
- Theoretical Review
- Published: 04 June 2018
- Volume 26 , pages 1548–1587, ( 2019 )
Cite this article
- Anna Coenen 1 ,
- Jonathan D. Nelson 2 , 3 &
- Todd M. Gureckis 1
17k Accesses
43 Citations
10 Altmetric
Explore all metrics
The ability to act on the world with the goal of gaining information is core to human adaptability and intelligence. Perhaps the most successful and influential account of such abilities is the Optimal Experiment Design (OED) hypothesis, which argues that humans intuitively perform experiments on the world similar to the way an effective scientist plans an experiment. The widespread application of this theory within many areas of psychology calls for a critical evaluation of the theory’s core claims. Despite many successes, we argue that the OED hypothesis remains lacking as a theory of human inquiry and that research in the area often fails to confront some of the most interesting and important questions. In this critical review, we raise and discuss nine open questions about the psychology of human inquiry.
Similar content being viewed by others

Rethinking the role of theory in exploratory experimentation
David Colaço
The Turing Test is a Thought Experiment
Bernardo Gonçalves
Putting the ‘Experiment’ back into the ‘Thought Experiment’
Lorenzo Sartori
Avoid common mistakes on your manuscript.
Introduction
The ability to ask questions, collect information, and actively explore one’s environment is a powerful tool for learning about the world. How do people decide which information to collect in any given situation? One influential idea is that information-seeking or inquiry behaviors are akin to scientific experiments . According to this metaphor, a child shaking a new toy, a student asking a question, or a person trying out their first smartphone, can all be compared to a scientist conducting a carefully designed experiment to test their hypotheses (Gopnik, 1996 ; Montessori, 1912 ; Siegel et al., 2014 ). The core assumption in this work is that people optimize their queries to achieve their learning goals in the most efficient manner possible.
To model everyday inquiry as scientific experimentation, psychologists have been inspired by the concept of “optimal experiment design” (OED) from the statistics literature (Fedorov, 1972 ; Good, 1950 ; Lindley, 1956 ). OED is a general statistical framework that quantifies the value of a possible experiment with respect to the experimenter’s beliefs and learning goals and can help researchers plan informative experiments. The psychological claim is that humans perform “intuitive experiments” that optimize the information gained from their action in a similar way. Within psychology, the OED hypothesis has been applied in many different areas including question asking, exploratory behavior, causal learning, hypothesis testing, and active perception (for overviews, see Gureckis & Markant, 2012 ; J. D. Nelson, 2005 ; Schulz, 2012b ).
It is easy to see why this metaphor is attractive to psychologists. Not only does the OED hypothesis offer an elegant mathematical framework to understand and predict information-seeking behaviors, it also offers a flattering perspective on human abilities by suggesting that everyone is, on some level, an intuitive scientist. However, the status of OED as the dominant formal framework for studying human inquiry calls for a critical evaluation of its explanatory merits.
This paper addresses two overarching issues concerning the current use of OED as a psychological theory. First, existing OED models rely on a wealth of non-trivial assumptions concerning a learner’s prior knowledge, beliefs, cognitive capacities, and goals. Our analysis critically examines these assumptions and lays out future research directions for how to better constrain these choices. Second, some forms of human inquiry cannot be easily expressed in terms of the OED formalism. For example, inquiry does not always start with an explicit hypothesis space, and it is not always possible to compute the expected value of a question. To that end, we highlight research questions that lie outside the realm of the OED framework and that are currently neglected by the focus on inquiry as scientific hypothesis testing.
Our hope is that this paper will serve both as a critical comment on the limits of the OED hypothesis within psychology and a roadmap of some of the hardest but most interesting psychological questions about human inquiry. The main part of the paper takes the form of laying out nine questions about inquiry. For each question, we review the current literature on the topic, examine how past work has dealt with particular challenges, and suggest promising future directions for work within and outside the OED framework. Before turning to these nine key questions, we review the origin and core principles of the OED hypothesis, and its history within psychology. We then consider how best to evaluate the past successes of the framework.
Human inquiry as optimal experiments
The metaphor of intuitive human inquiry as scientific experimentation dates to the 1960s. This early work compared people’s hypothesis testing to philosophical norms of scientific experimentation, and most prominently to principles of falsification (Popper, 1968 ). Falsification turns out to be a relatively poor description of human behavior, however, and is now widely rejected as an explanatory model (Klayman & Ha, 1989 ; Klayman, 1995 ; Nickerson, 1998 ; Wason, 1960 ). In contrast, the OED framework, which was inspired by Bayesian norms of experiment design from statistics (Horwich, 1982 ), has a number of successes as a predictive theory and is gaining in popularity among psychologists.
The origins and use of OED models
OED methods were originally developed as statistical tools to help researchers plan more informative scientific experiments (Good, 1950 ; Fedorov, 1972 ; Lindley, 1956 ). The idea is to create some formal measure of the “goodness” of a particular experiment with respect to the possible hypotheses that the experimenter has in mind. Using this normative measure, researchers can then choose an experiment that is most conducive to discriminating among the possible hypotheses. This is an alternative to experiments that are intuitively designed by researchers themselves but that might not be optimally informative. For example, a cognitive scientist studying human memory might choose different delay intervals for a recall test following study. Parameters like these are typically set using intuition (e.g., to cover a broad range of values). An OED method might instead output specific time intervals that have the best chance to differentiate competing theories (e.g., a power law or exponential forgetting function, see Myung & Pitt, 2009 ). The advantage of the OED method is that seemingly arbitrary design choices are made based on principled analyses of the researcher’s current knowledge about possible hypotheses (or models).
Starting from a problem or situation that the experimenter (or human learner) is attempting to understand, most OED models are based on the following components (see below for more mathematical detail):
A set of hypotheses (e.g., statistical models or range of parameter values) the experimenter or learner wants to discriminate among;
A set of experiments or questions that the experimenter or learner can choose from (e.g., parameters of a design or types of conditions);
A model of the data that each experiment or question could produce, given the experimenter’s current knowledge;
A measure of the value of these outcomes with respect to the hypotheses (e.g., the difference in model likelihood, or confidence about parameter values).
Together, these components enable a researcher to compute an “expected value” of every possible experiment, and choose the experiment that maximizes this value. This involves a preposterior analysis (Raiffa & Schlaifer, 1961 ), during which experimenters have to simulate the potential outcomes of every experiment and compute how helpful each of these outcomes would be for achieving their goal.
OED methods have been used by experimenters to improve parameter estimation and model comparison. For example, psychologists have used them to discriminate different memory models (Cavagnaro, Myung, Pitt, & Kujala, 2010 ; Myung & Pitt, 2009 ), to compare models of temporal discounting (Cavagnaro, Aranovich, Mcclure, Pitt, & Myung, 2014 ), to improve teaching tools for concept learning (Rafferty, Zaharia, & Griffiths, 2014 ), to fit psychophysical functions (Kim, Pitt, Lu, Steyvers, & Myung, 2014 ), and even to discriminate between different models of human inquiry (Nelson et al., 2010 ).
Aside from scientific applications, OED concepts are also widely used in machine learning to develop algorithms that rely on active learning . Such algorithms have the capacity to self-select their training data in order to learn more efficiently (Mackay, 1992 ; Murphy, 2001 ; Settles, 2010 ). For example, they can decide when to ask a human to provide a label of an unclassified training instance (e.g., a document). Active learning is especially useful when it is costly or time-consuming to obtain such corrective feedback.
OED modeling in psychology
Somewhat separately from these applied domains, researchers in psychology have used the OED formalism as a theory or hypothesis about human inquiry behavior. OED models have been used to explain how young children ask questions or play with an unfamiliar toy (Bonawitz et al., 2010 ; Cook, Goodman, & Schulz, 2011 ; Gopnik, 2009 ; McCormack, Bramley, Frosch, Patrick, & Lagnado, 2016 ; Nelson et al., 2014 ; Ruggeri & Lombrozo, 2015 ; Schulz, Gopnik, & Glymour, 2007 ), how people ask about object names in order to help them classify future objects (Markant & Gureckis, 2014 ; Nelson et al., 2010 ; Nelson, Tenenbaum, & Movellan, 2001 ), and how people plan interventions on causal systems to understand how variables are causally related to one another (Bramley, Lagnado, & Speekenbrink, 2015 ; Steyvers, Tenenbaum, Wagenmakers, & Blum, 2003 ). They can also model how learners would search an environment to discover the position of objects in space (Gureckis & Markant, 2009 ; Markant & Gureckis, 2012 ), and where they would move their eyes to maximize the information learned about a visual scene (Najemik & Geisler 2005 , 2009 ). Figure 1 illustrates how these basic components of the OED framework might map onto an everyday scenario facing a human learner.

An overview of human inquiry from the perspective of OED theories. Such theories begin with an ambiguous situation that provokes an inquiry goal. For example, the learner might wonder why the cat is in a bag. In thinking about how to best obtain the answer, the learner is assumed to consider alternative hypotheses about the explanation. Next, the learner evaluates possible actions or questions they could ask. Such questions are evaluated largely on how informative the answers to the questions would be. Finally, a question is chosen and the learner updates their belief based on the answer. OED theories capture the information processing elements within the thought bubbles
What is common to all these approaches is the claim that the mind operates, at least indirectly, to optimize the amount of information available from the environment just as OED methods optimize the information value of experiments. It is the broad application and success of this theory that makes it both interesting and worthy of critical evaluation. We will start our discussion of the OED framework by laying out its principles in more mathematical detail.
Formal specification of OED models
An OED model is a mathematical way to quantify the expected value of a question , query, or experiment for serving a learner’s goals. The basic approach is related to expected utility models of economic decision making, but uses utilities that are informational in nature, rather than costs and benefits of correct or incorrect decisions. Importantly, OED models are designed to not depend on which hypotheses a researcher personally favors or dislikes. OED models define the expected utility of a question as the average utility of that question’s possible answers. Formally, a question Q = { a 1 , a 2 ,... a m } is a random variable with possible answers a 1 , a 2 ,... a m . The expected utility of that question, E U ( Q ), is defined as the average utility that will be obtained once its answer is known, i.e.: \(EU(Q)={\sum }_{a_j \in Q}P(Q=a_j)U(Q=a_j)\) .
Utility can be any function that measures a learner’s progress towards achieving their goal of inquiry, which could be pure information gathering, planning a choice, or making a judgment. The learner’s goal is often to identify the correct hypothesis. The possible hypotheses (or states of the world) are defined by a random variable H = h 1 , h 2 ,... h n . Many OED utility functions are based on the prior and possible posterior probabilities of each hypothesis h ∈ H , and on how the distribution of probabilities would change according to each possible answer that could be obtained.
For concise notation in this paper, rather than writing out both the random variable and the value that it takes, we will specify the value that the random variable takes. For instance, suppose we wish to denote the probability that a specific question Q , if asked, would result the specific answer a . Rather than writing P ( Q = a ), we will write P ( a ). It is important to emphasize that a specific answer a is associated with a specific question Q . Or suppose we wish to denote the probability of a specific hypothesis h , given that question Q has been asked and that answer a has been obtained. Rather than writing P ( H = h | Q = a ), we will simply write P ( h | a ). Thus, the expected utility (usefulness) of a question Q can be concisely written as
A learner is typically faced with a set of possible questions { Q }. (The curly braces denote that we are referring to a set of questions, Q 1 , Q 2 , Q 3 ,..., each of which is a random variable, rather than to a specific single question.) To determine the optimal question, a learner has to calculate the expected utility of each possible individual question by simulating the possible answers of each question, calculating the usefulness of each answer, and weighting each possible answer’s usefulness as in Eq. 1 .
One of the most prominent OED usefulness functions is the expected value of a learner’s gain in information or reduction in uncertainty (Austerweil & Griffiths, 2011 ; Cavagnaro, Myung, Pitt, & Kujala, 2010 ; Lindley, 1956 ; Najemnik & Geisler, 2005 ; Nelson et al., 2014 ; Oaksford & Chater, 1994 ). A common metric of uncertainty is Shannon entropy, although alternative ways of measuring the value of an outcome will also be discussed below. The information gain of a particular answer, a , to question Q , is the difference between the prior and the posterior entropy:
The prior Shannon entropy is
and the posterior entropy is
where the posterior probability of each particular hypothesis h is derived using Bayes’ ( 1763 ) rule:
The combination of Eqs. 1 and 2 yields the Expected Information Gain (EIG) of a query, E U I G ( Q ).
How psychologists develop OED models of inquiry
To illustrate how the key components of the OED framework can be mapped onto different experiment paradigms in psychology, consider the list of examples in Table 1 . What is impressive about this list is the broad range of human behaviors that have been modeled by way of the OED hypothesis. While this table gives a cursory impression, in the following section we review in detail three example studies that use OED to model hypothesis testing, causal learning, and children’s exploratory play. We particularly aim to highlight what types of conclusions theorists have drawn from their models and behavioral findings.
Example 1: Logical hypothesis testing
In the most well-known psychological application of OED, Oaksford and Chater ( 1994 ) revisit the classic Wason card selection experiment (Wason, 1966 ). The experiment tests whether people are able to logically test hypotheses by falsifying them, that is, by checking that there are no counter examples to a logical rule. Participants are asked to test for a simple conditional rule involving a set of four cards. The four cards are labeled “A”, “K”, “2”, or “7” and participants are asked to test if “cards with a vowel on one side have an even number on the other side” (a rule of the form, if p, then q ). The dependent measure is which of the four cards participants turn over. (Participants are allowed to select all, none, or any subset of the four cards.) An often-replicated pattern of results is that most people select the “A” ( p ) card, many choose the “2” ( q ) card and few choose the “7” ( not-q ) card. This pattern of preferences violates the logical norms, which dictate that one needs to test “A” ( p ) and “7” ( not-q ), but not “2” ( q ). The “7” card ( not-q ) card is crucial, because it could potentially be a counterexample if it had a vowel on the other side.
To explain the discrepancy between people’s choices and reasoning norms, Oaksford and Chater ( 1994 ) interpret the task as a problem of inductive inference (how does a learner anticipate to change their beliefs based on data), rather than as checking for violation of a logical rule. Oaksford and Chater propose that people choose queries to reduce their uncertainty about two hypotheses: The dependence hypothesis specifies that the logical rule holds perfectly. The independence hypothesis specifies that the letters (A vs K) are assigned independently of the numbers (2 and 3) on the other side of the cards. Oaksford and Chater compute the expected information gain (see Eq. 2 above) for each query (card). The model assigns values to different queries (each of the four cards that can be turned over) and considers possible outcomes from these queries (observing a vowel, consonant, even number, or odd number). In the model, Oaksford and Chater further assume that the “A” and the “2” are rare , that is, learners do not expect many cards to have either vowels or even numbers on them. Given these assumptions, it turns out that the expected information gain from testing “2” is actually greater than that of testing “7”, which matches the pattern of behavior often found in this task.
In this article, Oaksford and Chater ( 1994 ) apply OED methods as part of a rational analysis of the card selection task (Anderson, 1990 ) that uses an optimal model to capture people’s behavior given some additional assumptions, but without any commitment to a particular set of cognitive processes that underlie this behavior. Regarding the actual implementation of the computation, the authors note that “The reason that people conform to our analysis of the selection task might be due to innate constraints or learning, rather than sophisticated probabilistic calculation.” (Oaksford & Chater, 1994 , p. 628). This is an example of a successful OED analysis that does not involve any algorithmic or implementational claim. Oaksford and Chater’s model also illustrates how researchers in the rational analysis framework have often adopted assumptions that make human behavior seem reasonable, rather than looking for deviations from a particular set of logic- or other norm-based assumptions of how people should behave.
Example 2: Causal learning
Another type of inquiry that has been modeled with OED norms is causal intervention learning. Steyvers, Tenenbaum, Wagenmakers, and Blum ( 2003 ) used expected information gain to predict which variables participants would manipulate to figure out the underlying causal relationships. In their experiment, participants first spent some time passively observing the behavior of a causal network of mind-reading aliens. The aliens’ thoughts were depicted as strings of letters appearing over their heads. Participants were told to figure out which aliens could read which other aliens’ minds (which resulted in them thinking the same thought as the one they were reading from). After the observation phase, participants gave an initial guess about how they thought the aliens were causally connected. Then, they were asked to make an intervention by inserting a thought into one of the aliens’ heads and observing the thoughts of the other aliens.
Again, the authors modeled these choices using an OED model based on expected information gain, which aims to reduce the uncertainty about possible causal structure hypotheses. Here, queries corresponded to the different aliens that could have a thought inserted, and outcomes corresponded to all possible ways in which the other aliens could change their thoughts as a consequence. The hypothesis space contained possible causal structures that described how the aliens were connected (i.e., who could read whose mind). The authors considered a number of implementations of the OED model that differed with respect to the space of hypotheses. An unconstrained version of the model, which considered all possible causal structures connecting the aliens, was not a good fit to people’s choices. However, a more constrained version, which assumed that people were only comparing their top hypothesis to its own subgraphs (i.e., graphs containing a subset of the edges of the most likely graph) and an unconnected graph, fit the human data well.
The authors concluded that “people bring to bear inferential techniques not so different from those common in scientific practice... they choose targets that can be expected to provide the most diagnostic test of the hypotheses they initially formed through passive observation.” Steyvers et al., ( 2003 , p. 486). Unlike the previous example, this conclusion suggests that people actually implement the underlying computations associated with the OED model. This interpretation is also common in work on OED models of inquiry.
Example 3: Exploratory play
Finally, consider an example from the developmental literature on children’s capacities for inquiry. Cook, Goodman, and Schulz ( 2011 ) gave preschoolers different information about the causal properties of toys (beads) and examined their subsequent behavior during exploratory play. Children were either shown that all beads were causally effective (they could turn on a machine and make it play music) or that only some beads are effective (some could not turn on the machine). Subsequently, children were given a new set of two beads that were attached to each other. Children who had learned that only some beads are effective proceeded to take apart the two new beads and test them with the machine individually. By contrast, children who had previously learned that all beads worked rarely bothered to check the new beads individually.
This behavior can also be modeled with expected information gain, by assuming that learners are choosing between three possible queries (testing both beads, testing the first bead, and testing the second bead) and anticipating one of two outcomes (the machine turning on or not). The experimenter’s demonstration is designed to set children’s hypotheses about the new pair of connected beads. Children in the all-beads-work condition only have a single hypothesis (both beads work), while those in the some-beads-work condition have four (both work, one works, the other works, neither works). To reduce their uncertainty about these hypotheses, the model predicts that the beads must be tested in isolation, which matches the behavioral data.
This example illustrates a trend in the developmental literature to draw analogies between children and scientists. Without making concrete algorithmic claims, Cook, Goodman, and Schulz ( 2011 ) interpret their findings as evidence that even young children optimize information gain during inquiry in a scientific manner, and conclude that “these results tighten the analogy to science that has motivated contemporary theories of cognitive development” (Cook et al., 2011 , p. 348).
These three examples illustrate not only different psychological applications of OED models but also the different types of explanatory claims that OED analyses have supported, ranging from the computational-level observation that people behave as if they optimize informational value (in Oaksford & Chater, 1994 ) to the more ambitious idea that people, like scientists, actually implement OED computational principles to some degree (in Steyvers et al., 2003 ). Although the actual explanatory claims may vary significantly from study to study, a common thread remains the tight analogy between empirical science and human information-seeking.
It should be noted that the history of psychology also offers examples of researchers using the OED framework to support the opposite claim that human information-seeking does not follow rational and scientific principles. For example, some studies in the heuristics and biases tradition (Kahneman, Slovic, & Tversky, 1982 ) highlighted ways in which human judgments deviate from OED norms (Baron, Beattie, & Hershey, 1988 ; Skov & Sherman, 1986 ; Slowiaczek, Klayman, Sherman, & Skov, 1992 ). Similarly, prior to the Bayesian approach used by Oaksford and Chater ( 1996 ), research on logical rule learning showed many discrepancies between OED principles and human behavior (Klayman & Ha, 1987 ; Klayman, 1995 ; Wason, 1960 ). Despite this history, the people-as-scientists metaphor has by far outweighed these accounts in recent years.
Merits of the OED hypothesis
The OED approach has greatly contributed to the study of human inquiry. Perhaps most saliently, it has provided a computationally precise approach to some very open-ended aspects of human behavior. In addition, the OED hypothesis provides a theoretical account of diverse information-seeking behaviors, ranging from visual search to question asking. In doing so, it also builds a theoretical bridge to models of a wide array of other cognitive processes, which, on the surface, bear little or no resemblance to information search. For example, Information Gain and related principles have been used in models of receptive properties of visual neurons (Ruderman, 1994 ; Ullman, Vidal-Naquet, & Sali, 2002 )and auditory neurons (Lewicki, 2002 ). They are also key components of recent models of visual saliency, which predict human eye movements as a function of image properties (Borji & Itti, 2013 ; Itti & Baldi, 2005 ; Itti & Baldi, 2006 ; Zhang, Tong, Marks, Shan, & Cottrell, 2008 ). They also connect to Friston and colleagues’ (e.g., 2009 , 2017 ) free energy principles, which posit that all neuronal activity is aimed at minimizing uncertainty (or maximizing information).
Finally, the close connections between OED models in psychology and formal methods in mathematics, physics, statistics, and epistemology make it straightforward for psychological theory to benefit from advancements in those areas. For example, research in computer science on computationally efficient active learning machines has inspired new theoretical approaches to inquiry behavior in humans (Markant, Settles, & Gureckis, 2015 ; Rothe et al., 2016 ).
Limitations of the OED hypothesis
Despite its successes, this article critically examines some of the basic elements of the OED research approach. Our critique springs from two main points, which, at first glance, may seem contradictory. On the one hand, applications of the OED framework in psychology often rely on a wealth of non-trivial assumptions about a learner’s cognitive capacities and goals. There is a risk that this makes the models too flexible to generate testable predictions. On the other hand, we will argue that the framework is in some cases not rich enough to capture the broad types of inquiry behavior exhibited by humans. These later cases are particularly important because, as OED gains in popularity as a theoretical framework, there is a risk that important aspects of behavior are being overlooked.
Elaborating on the first point, the three example studies reviewed above demonstrate a frequent research approach that is shared by many applications of the OED hypothesis within psychology. First, it is assumed that people inquire about the world around them in order to maximize gain in knowledge. Second, this assumption is instantiated as a specific OED model which assigns values to different questions, queries, or actions in a particular task. Finally, additional assumptions about cognitive processes (hypotheses, priors, etc.) may be added to the model to improve its fit.
Importantly, this research strategy does not set out to directly test the core claims of the OED hypothesis. For some researchers the framework provides a set of starting assumptions and novel psychological insights are more likely to emerge from modifications of a model’s peripheral components that get adjusted in the light of behavioral data. For instance, in Oaksford and Chater’s ( 1994 ) analysis of the card selection task the model fits behavior under the assumption that events ( p and q ) occur rarely. Similarly, Steyvers et al.’s ( 2003 ) best-fitting rational test model relies on a very restricted space of causal graph hypotheses. It is common for OED models to rely on very specific assumptions, but less common for researchers to treat these assumptions as discoveries in their own right. The rarity prior in Oaksford and Chater ( 1994 ) is an exception in this respect and provides a good example of integration between OED models and their assumptions. The rarity assumption is implicated in other hypothesis testing research, has normative support from the Bayesian literature, and it has generated a number of follow-up studies that systematically manipulate it and find that behavior changes accordingly (McKenzie, Ferreira, Mikkelsen, McDermott, & Skrable, 2001 ; Oaksford & Chater, 1996 ; Oaksford, Chater, Grainger, & Larkin, 1997 ). In general, however, it is rare for OED applications to examine and justify their auxiliary assumptions in such detail.
This general lack of integration between a formal framework and its assumptions about requisite cognitive components is a common criticism leveled against other classes of models, particularly Bayesian approaches for modeling higher-level cognition (Jones & Love, 2011 ; Marcus & Davis, 2013 ). Importantly, as both critics and defenders of Bayesian models have pointed out (see peer commentary on Jones & Love, 2011 ), this kind of criticism does not require rejecting the entire framework, but can be addressed by promoting greater efforts towards theory integration at different levels of explanation (e.g., computational, algorithmic, and ecological). The same holds for OED models of inquiry. Many of the current limitations of the framework could be overcome by moving beyond the mere metaphor of people as intuitive scientists and beginning to take the role of auxiliary assumptions seriously. This is the approach we advocate in some parts of this paper.
On the second point, there are also ways in which using the OED hypothesis as a starting assumption limits the kinds of behavior studied in the field. Recall that to make an inquiry problem amenable to an OED analysis, a researcher must quantify the set of hypotheses a learner considers, their prior beliefs over these hypotheses, the set of possible queries available to them, and their probability model for the outcome of each query. As we will note throughout this paper, there are many kinds of inquiry behaviors that would be difficult or impossible to express in those model terms, either because they are not based on the same components (e.g., inquiry in the absence of well-defined hypotheses), because of the computational complexity of applying OED, or because we do not yet know how to specify them computationally as part of a model (e.g., query types with computationally complex outcomes). Of course, no psychological theory is able to capture every single interesting cognitive phenomenon in a broad area like inquiry. However, we believe that it is important to pay close attention to the kinds of limits a theory imposes and make sure they do not lead to an overly narrow focus on a small set of questions that happen to be amenable to a particular analysis. Our review highlights the challenges of capturing important inquiry behaviors with OED and aims to encourage future research in these directions. We also highlight a number of questions that fall entirely outside of the purview of OED analyses, but that we believe deserve more attention in the study of human inquiry.
Nine questions about questioning
In the following sections we address what we think are some of the most interesting unresolved psychological questions about human inquiry. The criticism is built around the following nine questions about human inquiry:
How do people construct a set of hypotheses?
How do people generate a set of candidate queries?
What makes a “good” answer?
How do people generate and weight possible answers to their queries?
How does learning from answers affect query selection?
How do cognitive constraints influence inquiry strategies?
What triggers inquiry behaviors in the first place?
How does inquiry-driven learning influence what we learn?
What is the developmental trajectory of inquiry abilities?
Each section is designed to operate somewhat independently so readers are encouraged to read this article in a nonlinear fashion. In addition, at the beginning of certain sections that deal with variables or terms in the standard OED equations (i.e., Eqs. 1 - 5 ), we reprint the relevant equation and highlight the particular component of the OED framework that is discussed.
Question 1: How do people construct the space of hypotheses?
A crucial foundation for being able to use an OED model is the set of hypotheses or hypothesis space, H , that a learner considers. One reason is that the most common measure of information quality (Information Gain, Eq. 4 ) depends on changes in the entropy over the space of possible hypotheses:

The genesis of hypothesis spaces and priors in models of cognition is an issue that has been raised with respect to Bayesian models of cognition (Goodman, Frank, Griffiths, & Tenenbaum, 2015 ; Griffiths, Chater, Kemp, Perfors, & Tenenbaum, 2010 ; Jones & Love, 2011 ; Marcus & Davis, 2013 ), but plays out in particularly interesting ways in the OED framework.
What is a hypothesis or hypothesis space? Hypotheses often are thought of as reflecting different possibilities about the true state of the world (related to possible world semantics, Ginsberg & Smith, 1988 ). Hypothesis sets may contain discrete objects (like causal structures, category partitions, or even dynamic physics models, Battaglia, Hamrick, & Tenenbaum, 2013 ). Alternatively, a hypothesis space might reflect a distribution over continuous quantities (e.g., locations in space), or model parameters. The examples in this article often focus on discrete cases, since they tend to be more commonly used in OED models of higher-level cognition. However, the issues we raise also apply to some continuous hypothesis spaces.
How do current psychological applications of OED models define this hypothesis space? If the domain of inquiry is sufficiently well-defined, modelers often assume that learners consider an exhaustive set of hypotheses. For example, in categorization tasks the full set includes every possible partition of the space of objects into categories (Anderson, 1991 ; Markant & Gureckis, 2014 ; Meder & Nelson, 2012 ; Nelson, 2005 ). In causal learning scenarios, the hypotheses might be all possible (direct and acyclical) graphs (or possible parameterizations of graphs) that might explain the causal relationships between a number of variables (Bramley, Lagnado, & Speekenbrink, 2015 ; Murphy, 2001 ; Steyvers, Tenenbaum, Wagenmakers, & Blum, 2003 ). In a spatial search task, the hypothesis set could consist of all possible locations and orientations of an object (Markant & Gureckis, 2012 ; Najemnik & Geisler, 2005 ). This exhaustive approach can lead to the following three problems.
First, fully enumerated hypothesis spaces can be very large and complex, even in relatively simple tasks with a well-defined structure. For example, the number of possible partitions of objects into categories grows exponentially with the number of objects (Anderson, 1991 ; Berge, 1971 ). Similarly, the number of possible causal graph hypotheses increases rapidly with each additional variable (2 variables yield 3, 3 variables 25, 4 variables 543, and 5 variables 29281 possibilities). In real-world situations, the number of candidate category members and potential causal variables often far exceeds the situations used in psychological experiments, exacerbating the issue.
Given limited cognitive capacities, it seems unlikely that people can consider hundreds or thousands of discrete hypotheses and update their relative plausibility with every new piece of data. In fact, empirical studies often find that people appear to consider only a limited number of hypotheses in probabilistic reasoning tasks (Dougherty & Hunter, 2003a ). Hypothesis set size in some tasks also scales with working memory capacity (Dougherty & Hunter, 2003b ), which suggests that cognitive load could influence hypothesis set size. Some studies even argue that people consider only one hypothesis at a time in various learning and decision-making tasks (Bramley et al., 2015 ; Courville & Daw, 2007 ; Sanborn, Griffiths, & Navarro, 2010 ; Vul et al., 2014 ).
Another conceptual problem is that hypothesis sets are not always easy to define from the perspective of the modeler. Although it is sometimes obvious what belongs in a hypothesis set for a particular task, there are many cases in which it this is much less clear. For example, imagine a child shaking a new toy for the first time. What should we assume about her hypotheses, given that she has never seen a toy like this before? And how should she reduce her uncertainty about these hypotheses as efficiently as possible? Of course, it is possible that, based on prior experience with other toys, she is testing some high-level possibilities, for example whether or not the toy makes any noise when shaken. However, it is also possible that she chooses actions in line with more low-level principles of reducing prediction error about the outcome of her own motor actions. In that case, her hypothesis space might consist of a genzerative model that links actions, world states and percepts, and that can be used to quantify the expected surprise associated with self-generated actions (for such a general formulation of action as active inference, see Friston, 2009 ). Alternatively, the best model of this kind of behavior might not involve any hypotheses. Instead, the child’s behavior might be the outcome of some internal drive to explore and act on the world that is independent of particular beliefs or goals (Hoch et al., in review).
Confronting these conceptual and practical challenges is critical for models of inquiry. Here we address three possible approaches that have been used in recent research and discuss the merits of each. They include restricting hypothesis spaces, focusing on single hypotheses, and forming queries with no hypotheses whatsoever.
Curtailed hypothesis spaces
One solution to the combinatorial explosion of hypotheses is to select only a few hypotheses at a time and try to behave optimally given this subset. This is viable when it is possible to enumerate all hypotheses in principle , but the complexity of the full space is large and cognitive limitations forbid considering the whole set.
There is some evidence that people consider such pared down sets of hypotheses when seeking information. For example, Steyvers and colleagues’ 2003 causal intervention study, the best-fitting OED model was one that restricted the hypothesis set to a single working hypothesis (causal graph), as well as its “subgraphs” and a null model in which all variables were independent. Oaksford and Chater ( 1994 ) made a similar modeling assumption by considering only two possibilities about the world, one in which the conditional if p then q holds, and one in which p and q are entirely independent. However, there are many other logical relationships that could exist between them (e.g., the inverse conditional or a bi-conditional).
If some reduction of a hypothesis space provides a better account of human inquiry, an interesting question for the field becomes how to develop theories of this process. One approach is to model more directly the processes that might be used to construct a hypothesis set. Currently there are few such algorithmic theories, with the exception of a model called HyGene (Dougherty, Thomas, & Lange, 2010 ; Thomas, Dougherty, Sprenger, & Harbison, 2008 ). When encountering new data, HyGene generates hypotheses that have served as explanation for similar types of data in the past. Past data is retrieved from memory based on its similarity to the current data, and working memory capacity places an upper bound on the number of retrieved items. This subset of hypotheses is then evaluated with respect to the current data, and inconsistent hypotheses are ruled out. Since hypothesis generation in HyGene is based on memory retrieval processes, this approach would be particularly useful for modeling inquiry in domains where learners have a certain degree of prior knowledge (e.g., clinicians diagnosing diseases).
Alternatively, hypothesis spaces may be constructed on the basis of other processes. For example, comparison has been shown to promote relational abstraction, which in some cases might help bootstrap new types of hypotheses (Christie & Genter, 2010 ). According to this idea, comparison between two objects invokes a process of structural alignment where different features and relations of the objects are brought into correspondence with one another. In doing so, comparison has been shown to help focus people on shared relational structure, making these commonalities more salient for subsequent processing (e.g., similarity judgments). Thus, comparison might also help alter the hypothesis space considered for inquiry behaviors, by highlighting relational features.
One approach to formalize curtailed hypothesis generation comes from rational process models (also often simply referred to as sampling algorithms, see Bonawitz, Denison, Griffiths, & Gopnik, 2014 ; Courville & Daw, 2007 ; Denison, Bonawitz, Gopnik, & Griffiths, 2013 ; Gershman, Vul, & Tenenbaum, 2012 ; Sanborn et al., 2010 ; Vul et al., 2014 ). These models explain how a computationally limited organism can approximate Bayesian inference by making simplifying assumptions about how hypotheses are maintained and updated. Instead of representing the complete posterior probability distribution over possible hypotheses, the idea is that learners sample from this distribution, and thus only maintain a subset of hypotheses at any point in time. One feature of these models is that they can account for sequential dependencies during learning. For example, under certain parameterizations particle filter models yield hypotheses that are “sticky”, that is, that once considered will be maintained and only dropped when a learner encounters strong conflicting evidence (related to win-stay-lose-shift models of belief updating, Bonawitz, Denison, Gopnik, & Griffiths, 2014 ). This stickiness property matches human learning data in some tasks and is therefore considered an advantage of rational process models over “purely rational” models of hypothesis generation and belief updating (Bonawitz, Denison, Gopnik, & Griffiths, 2014 ; Bramley et al., 2015 ; Brown & Steyvers, 2009 ).
However, current sampling models lack a robust coupling of model terms and psychological processes. For example, it is unclear how the (re-)sampling of new hypotheses from the current posterior might be implemented. A promising direction is to integrate ideas from algorithmic models like HyGene that ground similar computations in mechanistic accounts of memory retrieval (Gershman & Daw, 2017 ; Shi, Griffiths, Feldman, & Sanborn, 2010 ).
Rational process models face another challenge. Much of their appeal is based on the fact that, under certain limiting conditions, they converge toward the true Bayesian posterior. Consequently, many have argued that they might bridge between optimal analyses and mechanistic accounts of behavior (Bonawitz, Denison, Griffiths, & Gopnik, 2014 ; Brown & Steyvers, 2009 ; Jones & Love, 2011 ; Sanborn et al., 2010 ). In reality, however, many of these algorithms require hundreds or thousands of samples in order to converge. Cognitive psychologists, on the other hand, often find that humans use considerably fewer samples, even as few as one (Vul et al., 2014 ), possibly because sampling incurs cognitive or metabolic costs. One skeptical interpretation of this work is that it implies that Bayesian inference is too costly for the brain. Also, if people sample stochastically, it should be rare that any single person acts optimally during inquiry (Chen, Ross, & Murphy, 2014 ). Instead, these theories predict that people will be optimal or unbiased on average (across people or situations). This property of sampling models, if correct, would suggest significant changes to the way OED models are evaluated. For instance, researchers would need to start quantifying optimality at a group level rather than for individuals (e.g., Mozer, Pashler, & Homaei, 2008 ) or based on data from repeatedly testing a participant on the same task. This may require larger experimental populations and new experiment designs.
Single-hypothesis queries
One common finding is that learners seem to seek information for a single hypothesis at a time. Although this can be seen as just a special (most extreme) case of curtailing hypothesis sets, single-hypothesis queries have rather unique characteristics and have motivated countless psychological experiments and models. Since OED models so fundamentally rely on a process of discrimination between competing hypotheses (see Fig. 1 ), single-hypothesis queries have been particularly difficult to explain.
For example, in Wason ( 1960 )’s “2-4-6” task, participants are asked to find out which numeric rule the experimenter is using, knowing only that the sequence “2-4-6” satisfies this rule. In this task, many participants immediately generate the working hypothesis that the rule is “even numbers increasing by 2” and proceed to test this rule with more positive examples, like “4-6-8” (Klayman and Ha, 1989 ; Wason, 1960 ). This has been called a positive testing strategy (PTS). Because it can yield suboptimal behaviors, it is also cited as an example of confirmation bias, that is, the tendency to verify one’s current beliefs instead of seeking and considering conflicting evidence (Klayman & Ha, 1987 ; 1989 ; Nickerson, 1998 ).
Single hypothesis use and the failure to consider alternatives have been observed in many areas of cognition besides information search. For example, during sequential learning people often only maintain a single hypothesis, which gets adapted with new evidence over time (Bramley et al., 2015 ; Gregg & Simon, 1967 ; Markant & Gureckis, 2014 ; Nosofsky & Palmeri, 1998 ; Trueswell, Medina, Hafri, & Gleitman, 2013 ). When dealing with objects that have uncertain category membership, people often base their inference on the most likely category, ignoring its alternative(s) (Malt, Ross, & Murphy, 1995 ; Murphy, Chen, & Ross, 2012 ; Ross & Murphy, 1996 ). During causal reasoning, people frequently make predictions based on single causes and neglect the possibility of alternatives (Fernbach, Darlow, & Sloman, 2010 ; Fernbach, Darlow, & Sloman, 2011 ; Hayes, Hawkins, & Newell, 2015 ).
The ubiquity of single hypothesis reasoning is not easily reconciled with the metaphor that people act like intuitive scientists, even after conceding that they are subject to cognitive limitations. Since model discrimination lies at the heart of the metaphor, it seems difficult to argue that single-hypothesis queries are the output of an optimal learner in the OED sense. However, it turns out that the PTS maximizes information under certain assumptions. For example, the PTS is optimal (in the OED sense) when hypotheses only have few positive instances, when instances only occur under a single hypothesis (during rule learning or categorization, see Navarro & Perfors, 2011 ; Oaksford & Chater, 1994 ; Thomas et al., 2008 ), or when hypotheses are deterministic (when predicting sequences; see Austerweil & Griffiths, 2011 ). Although this explanation cannot explain away all cases of single-hypothesis inquiry, it does raise the intriguing question of whether these factors actually influence whether people generate alternative hypotheses. For example, Hendrickson, Navarro, and Perfors ( 2016 ) manipulated the number of positive instances of a hypothesis and found that participants behaved in a less confirmatory fashion as hypothesis size increased. Similarly, Oaksford, Chater, Grainger, and Larkin ( 1997 ) manipulated people’s beliefs about the frequency of features associated with a hypothesis in the Wason card selection task (for example, participants were told that p and q both occurred often). People were more likely to try to falsify the rule when both features were common. These findings highlight how a learner’s prior beliefs about the structure of their environment impacts the hypotheses they generate, and the kinds of evidence they seek to test them (see also Coenen, Bramley, Ruggeri, & Gureckis, 2017 ).
Zero-hypotheses queries
The assumption that people make queries to test specific hypotheses is central to OED models of cognition. Yet many reasonable questions do not require any hypotheses at all. For example, upon visiting a city for the first time, you may ask your local friend “Where’s a good place to eat?”. This is an incredibly common kind of query that does not require considering any hypotheses beforehand. Another example of zero-hypothesis information gathering occurs in early childhood, when children exhibit unstructured, exploratory play (e.g., Hoch, Rachwani, & Adolph, in review). Although uncertainty about many aspects of their environment is presumably high, it is difficult to imagine that young children always represent hypotheses about what might happen as a consequence of their information seeking behaviors. These examples raise the question of how it is possible for a learner to quantify their uncertainty or notice a knowledge gap without hypotheses. We provide an in-depth discussion of constraints on zero-hypothesis queries in the next section that addresses how people generate questions in the first place.
A critical challenge for OED models is to explain the set of hypotheses that the learner considers. Although there is some recent work exploring how people reason with subsets of hypotheses, core psychological principles guiding this process have remained elusive and choices are sometimes made after experimental data have been collected. In addition, the OED framework does not easily apply to situations where learners 1.) consider the wrong hypotheses for the task, 2.) consider only one hypothesis, or 3.) do not consider hypotheses at all. These are not insurmountable challenges to the OED research program, especially in light of recent ideas about adaptive hypothesis sampling or online hypothesis space construction (Christie & Genter, 2010 ). However, these issues are critical to establishing the broader utility of the OED approach, outside of simple experimental tasks.
Question 2: How do people generate a set of candidate queries?
In standard use, an OED modeler computes the utility or informativeness of each possible query available in the task and the asks if people select the best option. For example, this could be which cards to turn over in the Wason selection task (see above) or where to fixate one’s eyes in a visual search task. However, what comprises the set of possible queries, { Q } = Q 1 , Q 2 ,..., that are available in any situation?

Consider, for instance, a young child asking a parent, “Can ducks fly?” Perhaps this is an informative question for the current situation, but there seems no limit to the number of questions that could be asked (e.g., “Do ducks sleep?”, “How many babies do ducks have?”, “Is the weight of a duck in kilograms less than ten times the square root of seven?”), even though only a subset might be relevant for any particular inferential goal. In order for OED principles to apply to this fairly typical situation, every possible question or query would need to be evaluated and compared to others. OED models currently provide no guidance on this process, ignoring almost completely how the set of questions or queries is constructed.
For OED to be applied to more general types of inquiry (such as asking questions using language), the framework must be able deal with the wide range of human questions. As we will argue below, the existing OED literature has tended to focus on relatively simple inquiry behaviors (e.g., turning over cards in a game, asking the category label of an object), which are more amenable to mathematical analysis. However, once one considers modeling the rich and sophisticated set of questions people can ask using natural language, computational issues become a significant challenge. Although this section focuses on question asking in natural language, the concern is not limited to the language domain. For example, interacting with a complex system (like the physical world) often requires us to construct novel actions or interventions (Bramley, Gerstenberg, & Tenenbaum, 2016 ) from a potentially unbounded space. When playing a new video game, for instance, a person might initially perform a wide range of complex actions to understand the game dynamics and physics. Each action sequence reveals information about the underlying system’s rules but is selected from a potentially large space of possible action sequences.
Searching for the right question
Many researchers have had the experience of sitting through the question portion of a talk and hearing a very clever question asked by an attendee. Often, we would not think to ask that question ourselves, but we immediately recognize it as informative and insightful. While in some cases we might attribute this to differences in knowledge (e.g., perhaps a colleague thinks about an analysis in a slightly different way) it also seems clear that coming up with a question is often a significant intellectual puzzle (Miyake & Norman, 1979 ).
Consider a recent study by Rothe et al., ( 2016 ). In Experiment 1 of the paper, participants played a game where they had to discover the shape and configuration of a set of hidden ships on a gameboard (similar to the children’s game Battleship). Rather than playing an entire game, participants were presented with partially uncovered gameboards (i.e., some of the tiles were uncovered, see Fig. 2 ) and then were given the opportunity to ask questions in natural language, which would be helpful for learning the true configuration of this gameboard (the only limitations were that questions had to be answerable with a single word and that multiple questions could not be combined). Example questions are “Where is the upper right corner of the blue object?”, “How long is the yellow object?”, or “How many tiles are not occupied by ships?”. Interestingly, while participants generated a wide variety of different questions, they rarely came up with questions that came even close to the highest expected information gain (EIG). This is somewhat surprising, because one assumption of the OED framework is that people will ask the most informative question in a given context. Given the simple setup of the task, this should be the same question for each participant in this game. Yet few subjects asked really clever and revealing questions. The modal participant asked much more mundane and only moderately informative questions.

Top : Example of the Battleship game. Hidden gameboards are created by randomly selecting ships of different sizes and orientations and placing them in a grid at random, non-overlapping locations. A context is defined as a partially unveiled gameboard ( center ). The goal of the learner is to identify the true gameboard by asking questions. Bottom : Task sequence from Rothe, Lake, & Gureckis ( 2016 ). Subjects first turned over individual tiles one by one following instructions of experimenter (clicking on the ?). Next they indicate the possible ship locations. Finally, people asked whatever question they wanted in natural language in order to best discover the underlying gameboard
Interestingly, although participants were not good at devising useful questions, they were highly skilled at recognizing good questions. In a follow-up experiment, participants were presented with the same set of ambiguous game situations and a list of potential questions derived from the questions asked in the previous study. Here people’s selections closely mirrored the predictions of OED models with people preferring the objectively most informative questions.
The Rothe et al. ( 2016 ) study highlights how the demands of generating questions “from scratch” may limit optimal information-seeking behavior. In general, this work helps to clarify the distinction between question generation and question evaluation (the latter being the primary emphasis of contemporary OED approaches). One future research topic raised by this work is how people formulate questions in a given context and how they search the large space of possible questions. While presently underexplored, these topics have natural solutions in computational or algorithmic approaches. For example, Rothe et al. (in prep) develop a question generating model that creates the semantic equivalents to human questions using a context-free grammar. This approach defines the basic semantic primitives of questions and rules for the composition of these primitives, then uses OED models as an objective function of a search process that explores the space of expressions within the grammar to find the optimal question.
An alternative approach would be to construct questions “bottom-up” from the current situation. For example, questions could be constructed around hypothetical propositions or facts that might hold in a given situation (e.g., the size of the red ship could be six) but that are currently unknown. In any event, increased emphasis on question-generation is likely to open up new avenues for empirical research and process-level models. In some cases, it might also help expand the range of situations that are addressable within the OED framework. For example, question asking behavior has long been of interest to educators (Graesser et al., 1993 ), and models that apply to more complex and realistic types of inquiry behaviors might have greater impact.
A mosaic of question types
The question of how to apply OED principles to more open-ended natural language question asking exposes more than just the issue of how this large space can be searched. Once one allows for broader sets of questions additional computational complexities are often encountered. Our intention here is not to provide an exhaustive taxonomy of different question types (placing questions or queries into categories may not be particularly meaningful), but to compare and contrast a few different types of queries to illustrate the computational issues at stake.
Label queries
As noted above, most information search studies give people the option of choosing from a set of narrowly defined query types. In categorization experiments, for instance, participants can typically only inquire about the category membership of unlabeled items (MacDonald and Frank, 2016 ; Markant & Gureckis, 2014 ; Markant et al., 2015 ). During spatial search the task is usually to query specific locations and learn what they contain (Gureckis & Markant, 2009 ; Markant & Gureckis, 2012 ; Najemnik & Geisler, 2005 ).
In machine learning, these types of queries are called “label queries” and, similar to psychological experiments, they constitute a large part of active machine learning research (Settles, 2010 ). During a label query, an oracle (knowledgeable human) is asked to produce the label or class of an unlabeled instance, which helps a classification algorithm learn over time (roughly, “What is the name of this?”). An appealing feature of label queries is that they intuitively match some real-world question asking scenarios. For example, children often learn by pointing out objects in the environment and having an adult label them. Vocabulary learning of a foreign language has a similar property.
The computational evaluation of label queries in an OED framework is relatively simple, assuming the learner has a well-defined hypothesis space (see Question 1 for why that might not be the case). For example, when encountering an animal that is either a cat or a dog, a child might point at it and ask “what is that?” Knowing that there are two possible answers (“cat” or “dog”), it is relatively easy to compute the sum in Eq. 1 (see Question 4).
Feature queries
Instead of requesting labels or examples, learners can also ask about the importance of entire features or dimensions of categories. For example, a naive learner might ask whether the ability to sing is an important feature for telling whether something is a bird. Unlike label queries, this type of question does not request the class membership of a single exemplar, but instead asks more generic information about the class. Such feature queries have proven to be successful in machine learning, in particular when human oracles are experts in a domain and can quickly help improve a classifier’s feature weights to accelerate learning (Raghavan, Madani, & Jones, 2006 ).
The distinction between item and feature queries holds psychological significance as well. For example, a growing literature in developmental psychology (see Question 9) explores information-gathering strategies in simple games such as “Guess Who?” or “20-questions”. When used as an experiment, the subject tries to identify a hidden object by asking a series of yes/no questions. There are two broad strategies commonly used by human participants in the game: hypothesis-scanning questions target a specific instance (e.g., “Is it Bill?”), whereas constraint-seeking questions ask about features that are present or absent across multiple objects (e.g., “Is the person wearing a hat?”). A classic finding in this literature is that younger children (aged 6) tend to ask more hypothesis-scanning questions, while older children (aged 11) and adults use more constraint-seeking questions (Mosher & Hornsby, 1966 ).
From a computational perspective, the informational value of some feature queries is easy to compute (e.g., the constraint-seeking feature questions in the “Guess Who?” game) and researchers have used OED models as a yardstick for human performance (Kachergis et al., 2016 ; Nelson et al., 2014 ; Ruggeri & Lombrozo, 2015 ). A more difficult problem arises when questioners do not yet know what the relevant features might be. For example, I might ask my friend who works in the tech industry what features are relevant for predicting the survival of a new startup. This question would help me narrow down the set of features that I might then proceed to ask more targeted questions about.
This issue is widely recognized in applied Machine Learning as the problem of “Feature Engineering” (Blum & Langley, 1997 ). When building a model in a new domain, the modeler first needs to figure out which features to use (or to build from other features or from raw data). This process often relies on human input from experts with domain knowledge, and it precedes the actual learning phase of the model. It is thus difficult to compute the informational value of this kind of feature query in a way that makes it comparable to other types of queries, even though it undoubtedly serves an important purpose when starting inquiry in a new domain.
Demonstration queries
Consider learning a complex skill like how to play “Chopsticks” on the piano. A skill is essentially a category under which some actions count as performing the skill and others do not. Taking a label query approach, the learner would play a random sequence of notes and then ask the teacher or oracle “Is that ‘Chopsticks‘?”, eventually learning how to perform the piece. An alternative strategy would be to request an example of a category (e.g., “What is an example performance of ‘Chopsticks‘?”). This type of active class selection or demonstration query provides a positive example of the category, which can be highly informative, especially early in learning (Lomasky et al., 2007 ). For example, one might want to ask to see a good or typical example of a category member (“What does a typical bird look like?”) before making queries about new exemplars or specific features. Similarly during causal structure discovery, one can often learn a lot about a system by seeing a demonstration of how it works before making a targeted intervention. The idea of demonstration queries has been considered for teaching motor skills to social robots, who can ask a human to demonstrate a full movement trajectory rather than providing feedback about the robot’s own attempts at a task (Cakmak & Thomaz, 2012 ). In humans, demonstration queries are particularly useful for learning new skills. Importantly, the usefulness of demonstration queries depends on the level of knowledge or expertise of the answerer, which means that they should be chosen more or less often based on the learner’s beliefs about the answerer. This is a topic we discuss in more detail in Question 6.
Demonstration queries are computationally complex. As noted above, OED models average across all potential answers to a question, but a question like “What does a cat look like?” could be answered by providing any reasonable example of the category (a cat photo, pointing at a cat, a drawing of a cat). For complex hypotheses or categories it does not seem possible for the naive question asker to simulate this set of potential answers via explicit pre-posterior analysis. It is thus hard to imagine how the OED framework could provide a satisfactory explanation of how people assess the usefulness of demonstration queries (“What does a cat look like?”), compared to, for example, label queries (“Is this a cat?”). Explaining how people choose demonstration queries, and when people deem a demonstration query to be more helpful than other queries, will likely require an understanding of people’s metareasoning about query-type selection.
The role of prior knowledge in question generation
So far, this section has highlighted the problem of modeling question types, and generating questions to serve particular goals of a learner. However, there exists a more fundamental puzzle about the way certain questions are generated. Consider the following examples.
What’s the English translation of the German term “Treppenwitz”?
Where do raccoons sleep?
What makes that object float in mid-air?
Why is that person wearing only purple?
What do you do for a living?
What these examples have in common is not that they expect particular types of answers (they could ask for features, events, labels, mechanisms, etc.), but that can be asked in the absence of any concrete hypotheses and may be triggered by context and prior knowledge alone. For a non-German speaker coming across the term “Treppenwitz” it not necessary to actually consider particular English translations. Simply knowing that most words or phrases can be translated between German and English is sufficient to know that there is information to be gained. Instead of concrete hypotheses, such questions can be generated if the questioner realizes that there exists some currently unknown fact that is knowable in principle. Since the number of unknown facts is infinite, there must be some way of constraining the questions to those that address specific “knowledge gaps” that can realistically be closed. To frame this puzzle in another way, consider how an artificial agent would have to be programmed to generate these questions in an appropriate situation. Perhaps asking for a translation of an unknown phrase would be the easiest to implement if the agent’s goal is to parse and translate sentences. But we are currently still very far away from developing artificial intelligence that spontaneously asks about raccoons’ sleeping places or questions people’s odd clothing choices in the same way a human might do on a walk through the forest or a stroll through the city.
We propose that the structure and content of current knowledge alone can act as a strong constraint on query generation in the absence of hypotheses. Abstract knowledge in the form of categories, schemata, or scripts, can play an important role in highlighting knowledge gaps (e.g., Bartlett & Burt, 1933 ; Mandler, 2014 ; Minsky, 1974 ). Knowing that raccoons are mammals, and that a broadly shared feature of members of the mammal category is the need to sleep, can help us identify a gap in our knowledge about raccoons. (In fact, this seems to be a common question. When the authors typed “where do raccoons” into a well-known search engine, “sleep?” was among the top suggested completions of the query.) Conversely, most people would be much less likely to spontaneously generate the question “where do raccoons get their nails done?”, because we have no prior knowledge to suggest that there even exists an answer to this question. Asking about the motivation behind a person’s odd clothing choices similarly requires prior knowledge. At the very least, one has to know that people generally act based on goals and intentions, and that an all-purple wardrobe is an unusual choice. Conventions or conversational scripts are another source of queries. For example, we learn that it is typical to ask for someone’s name, place of residence, or profession upon first meeting them. It is much less common to ask about a person’s preferred sleeping position, which might be similarly unknown, but is not part of the conventions that apply to small talk. Conventional sets of questions exist in many domains, which makes the task of generating questions much easier.
What types of knowledge constrain these types of queries? While some of them, for example social conventions, undoubtedly have to be learned, others may be more fundamental. Foundational knowledge, sometimes referred to as core knowledge (Carey & Spelke, 1996 ; Spelke & Kinzler, 2007 ), may constrain query generation already in early childhood, when specific world knowledge is still sparse. For example, we know that infants are endowed with a system of object representation involving spatio-temporal principles (such as cohesion, continuity, and support, Spelke & Kinzler, 2007 ). Furthermore, children as young as 2 years old make relatively sophisticated assumptions about causal relationships between objects (Gopnik et al., 2004 ). Such early knowledge can be leveraged to help find opportunities for inquiry. For example, it has been shown that children engage in more information seeking behaviors when their prior expectations about causal relationships or spatio-temporal principles are violated than when they are confirmed (Legare, 2012 ; Stahl & Feigenson, 2015 ). Upon seeing an object suspended in mid-air, children might therefore proceed to seek further information to explain the now apparent knowledge gap about how the object is supported (Stahl & Feigenson, 2015 ). Another kind of core knowledge that emerges early in life is the ability to represent animate beings as intentional agents (Spelke & Kinzler, 2007 ). Young children expect people, but not objects, to execute actions based on goals and plans (Meltzoff, 1995 ; Woodward, 1998 ). This means that, similar to adults, young children observing a person behave in an intentional but strange manner might become aware of a knowledge gap and try to find out what goals or intentions could explain this behavior.
Current models of inquiry assume that questions are generated to satisfy a particular set of inferential goals, by testing specific hypotheses about the world. However, the examples above illustrate the wide variety of questions that arise from knowledge gaps identified and are formulated in other ways. Given how common such questions are, future work on inquiry should devote more attention to query generation that goes beyond the hypothesis-testing framework. Knowledge-based queries also raise an entirely new set of computational challenges. Accounting for these questions will often require models of domain knowledge, structured representations, and fundamental beliefs about causality and intentionality. Most interesting is that these types of queries seem to fall outside the domain of OED models, as formulated to date, in that no alternative hypotheses need be considered, and the set of answers may not be explicitly enumerated.
Question 3: What makes a “good” answer?
In the OED framework, a question’s expected value is a weighted average of the value of each of its possible answers ( 1 ). In this sense, the value of answers is a more basic concept than the expected value of a question. However, what makes an answer to a query “good”? More formally:

The importance of this issue is reflected in a variety of scientific literatures. For example, psychologists and philosophers have discussed what counts as a good “explanation” of a phenomenon. Although there are differences in people’s preference for certain explanation types (e.g., the teleological or ontological distinction, Kelemen & Rosset, 2009 ; Lombrozo & Carey, 2006 ), this work does not usually involve computationally precise ways of evaluating the quality of answers (or explanations). Despite its foundational nature, in the OED framework there is very little research on how people evaluate an answer’s usefulness (but see, Rusconi, Marelli, D? Addario, Russo, & Cherubini, 2014 ).
To develop an initial intuition for answer quality, consider the following example dialogs. If a learner asks someone “Where exactly do you live?”, an answer including exact Global Positioning System (GPS) coordinates completely answers the question and removes any lingering doubt. In contrast, a more imprecise answer like “New York City” might leave uncertainty absent any other information. The point is that our intuition is that some answers (like the GPS) are better than others because they are more informative. The quality of an answer also depends on what the question asker already knows. Consider the following exchange:
What city were you born in?
New York City
Do you live in the same city you were born?
Which city do you live in?
Here, the final question-answer pair is identical to the one above but now the answer contains no new information.
These examples highlight a few key points about answers. A good answer is relevant to the given query and adds information above and beyond what is already known by the learner. Answers differ in quality based on the amount of information they provide, but it is possible for two answers to be equally good if they offer the same query-specific information (that is, it does not matter if one answer provides additional information that was not called for by the query). A major topic of research within the OED framework is determining a general-purpose, mathematically rigorous way of defining the quality of an answer to a question. The most common approach is to assume there is a type of utility associated with answers. In the remainder of this section, we will give a more detailed account of specific utility measures that OED models have used to quantify the quality of answers.
Determining the utility of answers
In the broadest sense, it is useful to distinguish between informational (or disinterested ) and situation-specific (or interested ) utility functions (Chater et al., 1998 ; Markant & Gureckis, 2012 ; Meder & Nelson, 2012 ). Pure information utility functions are based solely on probabilities and on how answers change probabilities. Situation-specific functions take into account that learners collect information for a specific purpose beyond pure knowledge gain (e.g., saving time, money, or cognitive resources Footnote 1 ). Both approaches reflect hypotheses about the overall goals and purpose of human inquiry, although the difference between them is not always clearly acknowledged in psychological literature.
Informational utility functions
Most OED models evaluate answers according to how they change a learner’s beliefs about possible hypotheses . These metrics are a thus a function of the learner’s prior belief before receiving an answer, P ( H ), and their posterior belief having received that answer to a their question P ( H | Q = a ), which in our shorthand notation can be written as P ( H | a ). (Recall that a denotes a particular individual answer to a particular question Q .) Information Gain, from Eqs. 1 and 2 , is one of the most popular functions used within psychology, but there exist a number of interesting alternatives, including impact (expected absolute belief change), diagnosticity, KL divergence, and probability gain (Nelson, 2005 ).
The differences between these measures may sometimes seem subtle, but comparing them more carefully raises interesting and fundamental questions. Consider the six scenarios depicted in Table 2 . Each scenario shows how the distribution of a learner’s belief about some parameter 𝜃 changes as a result of an answer to their query. The three rightmost columns show how three different utility measures evaluate the usefulness of this change in belief. (To keep things simple, we just focus on the sign of the model outputs. For in-depth comparison, see J. D. Nelson, 2005 ). The models are Information Gain (IG), Probability Gain (PG), and Kullback-Leibler divergence (KL). An answer’s probability gain is the reduction in probability of incorrect guess that the answer provides. Interestingly, it can be obtained by replacing Shannon Entropy, e n t ( H ), in Eqs. 1 and 2 with p F a l s e ( H ), also known as Bayes’s error:
Kullback-Leibler (KL) divergence is an alternative information-theoretic measure to Shannon entropy, which is useful in comparing two distributions (in this case, a posterior and prior). When evaluating the expected usefulness of a question, that is, E U ( Q ), KL divergence and Expected Information Gain (EIG) give exactly the same value, for every possible question, in every possible scenario (Oaksford & Chater, 1996 ). However, KL divergence and IG can make contradictory predictions when the usefulness of different specific answers, i.e., U ( a ), is evaluated, as the examples in Table 2 demonstrate. The KL-divergence resulting from an answer a given question Q is
For the first two situations in Table 2 , the three models agree that the answers’ values are positive. In both cases, the variance of the posterior has narrowed, implying that the learner is now more confident in the estimate of 𝜃 . Likewise in the third example, all models assign zero value to an answer that has not changed a learner’s beliefs at all. This scenario captures any situation in which a learner is told something they already know or that is irrelevant for answering their question.
Examples four to six show more divergent cases. In scenario four, a learner changes their belief about the value of 𝜃 but does not narrow their posterior. For example, imagine learning that your friend’s car is in fact a Toyota, not a Chevrolet as you previously assumed. This would change your estimate of the car’s costs without necessarily affecting your uncertainty around the precise value. The IG in this example is zero, since uncertainty does not change. The same holds for the probability of making a correct guess (PG), since the probability of the most likely hypothesis has stayed the same. This assessment runs counter to some intuitive definitions of what constitutes a good answer, since the learner has in fact changed their belief quite substantially. A measure like KL-divergence, which assigns positive value to this scenario, thus may be more in line with these intuitions.
Scenario 5 is even more puzzling. Here, the learner receives an answer that increases their uncertainty. This leads to negative IG and PG, although KL divergence is positive. (In fact, KL divergence is always positive unless prior and posterior are exactly the same.) Returning to the car example, this could happen upon learning that a friend’s car is either a Toyota or a Ford, having previously assumed that it was probably a Chevrolet. Now, you might end up being more uncertain about its cost than before. Again, this conclusion is somewhat at odds with the intuition that something was learned in this scenario even if the learner ended up more uncertain as a consequence.
Finally, scenario 6 shows that sometimes IG and PG make diverging predictions. Here, the learner has narrowed their posterior around the smaller peak, and has therefore reduced their overall uncertainty. However, the probability of the most likely hypothesis has stayed the same; thus, the answer has no value in terms of PG. As an example, imagine that you are trying to guess the breed of your friend’s dog and you are pretty sure it is a German shepherd. Finding out that it is not a Chihuahua because your friend is allergic to Chihuahuas might slightly change your hypothesis space about much less likely possibilities (and therefore lead to positive IG), but not at affect your high confidence regarding your top hypothesis (hence zero PG).
These examples demonstrate that assigning values to answers, even from a completely disinterested perspective (i.e. when one is only concerned with quantifying belief change), is not at all trivial. These examples raise some interesting psychological questions, such as how people treat answers with negative IG, or how they balance information and the probability of making a correct choice. An important area for future research will be to consider information gain based on other types of entropy metrics, and not only based on Shannon entropy. For instance, Crupi and Tentori ( 2014 ) discuss information gain based on quadratic (rather than Shannon) entropy. In fact, in mathematics, physics, and other domains, there are many different entropy models, several of which could be important in a descriptive theory of human behavior (Crupi et al., 2018 ). We will briefly return to these questions below, after discussing situation-specific utility functions.
Situation-Specific utility functions
According to situation-specific (“interested”) theories of information search, the utility of an answer (and therefore a query) depends on concrete goals of the learner, irrespective of or in addition to the goal of increasing information. Question-asking strategies that are based on situation-specific goals can yield strongly different predictions than disinterested models (Meder & Nelson, 2012 ). For example, consider a categorization task in which payoffs are asymmetric, such that correctly or incorrectly classifying items into different categories yields different costs or penalties. This could be the case during medical diagnosis, where there might be greater costs associated with misclassifying a potentially fatal condition than a benign one, which leads to asymmetrical decision thresholds for treatment (lower for the fatal condition). This asymmetry should also affect the medical tests that are administered. Tests that have the potential to change the treatment decision are more valuable than those that do not, irrespective of their pure informational value (Pauker & Kassirer, 1980 ). Cost-sensitive components also matter when learners have some pure information goals (e.g., to minimize Shannon entropy across possible hypotheses) but wish to simultaneously minimize time spent, cognitive demands, or number of queries made.
Interestingly, people are not always sensitive to costs of incorrect decisions (Baron & Hershey, 1988 ) and tend to make queries in line with pure information strategies, like probability gain or information gain on some tasks (Markant et al., 2015 ; Meder & Nelson, 2012 ). An interesting question for future work is to understand when and why this might be the case. A preference for disinterested search may be adaptive, for instance, if people expect to re-use information later on in a different task. This could be investigated by manipulating people’s beliefs about future re-usability to see how the use of disinterested versus interested question asking strategies changes. It is also possible that it is computationally intractable in some cases to assess situation-specific utilities. For example, Gureckis and Markant ( 2009 ) explored how even for a simple task this can require not only computing the utility of each individual answer, but also how information from that answer might influence a future decision-making policy. Computing this can be a significant computational burden. Finally, sometimes people only realize what the value of an answer is when they actually see it and process it. This would suggest that people might have to learn to adjust their inquiry strategy as they learn more about a given situation-specific utility function. This possibility calls for experiments that have people assess the value of both questions and of answers, in tandem, to test how the latter influences the former (also Question 5, on learning from answers).
Determining the value of an answer is no easy feat. Even when learners have a good probabilistic model of the task at hand, there are many different approaches to measure the utility of answers, many of which have some degree of plausibility. The lack of consensus on the ’right’ kind of answer utility poses an interesting challenge for OED models, all of which define a question’s expected usefulness as the probability-weighed average of its possible answers’ individual usefulness values. To address this challenge, we see several possible strategies.
First, there are a number of efforts to try to isolate domain-general principles of assigning values to answers. Using carefully designed experiments, this approach might ultimately reveal that some functions are simply a better match for human intuitions about answer utilities than others. One example is work by Nelson et al., ( 2010 ) that found that expected probability gain was the best-fitting psychological model among several candidates, including EIG, for information search behavior in a probabilistic classification task. Future studies will be required to explore more systematically if this finding holds in other domains as well.
Second, if no domain-general information metric can be found, then modeling inquiry in a new domain or task will require an understanding of how people assign value to received answers in that domain. Since this is such a fundamental building block of any OED model, it might be sensible to study the value of answers in isolation, before trying to build models of the expected usefulness of questions.
Question 4: How do people generate and weight possible answers to their queries?
OED models define the expected usefulness of a question as a probability-weighted average of the usefulness of each possible answer ( 1 ):

We have just discussed the problem of evaluating the utility of individual answers. An entirely different question is which answers people anticipate to begin with and what probabilities are assigned to them. For example, if you ask someone “Which city do you live in?”, an OED model requires you to consider each possible answer (“New York”, “Boston”, “Austin”, “Denver”, etc...) and to weight the utility of that answer by the probability of receiving it. If you know nothing else about an individual, the probabilities might be the base rates from the general population. However, if you meet a new colleague whom you know is a professor, cities with universities or colleges might be more probable. Importantly, the above equation assumes that the learner knows the possible answers a question might receive, and the probability of each of those answers. In real-world tasks, as well as in more complex experimental tasks, such as models of eye movements in visual search or of causal learning, models based on the OED framework must make a number of usually implicit assumptions about these variables.
What is a possible answer?
The OED framework treats question asking as following from the goal of obtaining information about something. As a psychological model, OED presumes that people know the possible answers and their probabilities. Returning to an earlier example, if someone asks “Where do raccoons sleep?” it seems nonsensical that the answer would be “blue,” improbable that the answer is “underwater,” and likely that the answer is “in a den”.
Surprisingly little research in psychology has attempted to understand what people expect as answers to different types of questions. Given the tight coupling between answers and questions implied by the OED framework, this could be a fertile research topic. For example, how do differences in how readily people consider different answers affect information seeking-behaviors? Some questions have rather obvious or simple answer spaces (e.g., a true/false question returns either of two answers). In addition, in some cases the possible answers to a question are basically the same as the hypothesis space. For example, for the question “What city do you live in?”, the possible hypotheses are cities, as are the answers. This suggests that issues about hypothesis generation discussed in Question 1 might hold relevance. The space of answers that people consider possible might strongly influence the value they assign to a question. Furthermore, the type of learning that happens after receiving an unexpected versus expected answer might be somewhat different (see Question 5). Despite the theoretical importance of these issues to the OED hypothesis, little research has addressed them.
Dealing with intractable answer spaces
As noted throughout this article, theories of inquiry based on OED principles share much in common with theories of decision making. This is particularly clear given that the value of a question depends on a “tree” of possible future outcomes similar to how in sequential choice theories the value of an action depends on a “tree” of later actions (see Fig. 3 ). However, as many authors in the decision-making literature have noted, it is computationally intractable to consider all possible future outcomes or scenarios (e.g., Huys et al., 2012 ; Sutton & Barto, 1988 ). A variety of methods have been proposed to approximate this vast search space of outcomes, two of which we briefly summarize here.

Top : A typical decision tree. The value of the current choice is often assumed to depend on the outcomes and available choices at later points in the tree. Bottom : Structure of OED models showing how the value of a question similarly depends future states (i.e., answers to the question)
Integration by Monte-Carlo sampling
The key to Monte-Carlo approximation (e.g., Guez, Silver, & Dayan, 2012 ) is the fact that the quality of a question is basically a weighted sum or integral (i.e., Eq. 1 ). One way to approximate this integral is to sum over a set of samples:
where a (1) ,..., a ( m ) are a set of m samples from the P ( a ) distribution. In the limit as m → ∞ , the approximation based on samples converges to the true value of EU found by weighting the value of each answer by its appropriate probability. Under the Monte Carlo approach, people might repeatedly mentally simulate different answers they could receive and evaluate the utility of each. Highly probable answers would be generated often whereas less probable answers might rarely be simulated. In the case where the number of answers is large, or where some answers are very unlikely this approximate sum may be more computationally efficient. In addition, when m is small certain biases might be introduced (e.g., rare answers are less likely to be sampled and thus less likely to enter into the evaluation of a question).
Integration by tree pruning
An alternative approach assumes explicit “tree pruning” where certain future paths of the decision tree are selectively ignored. For example, Huys et al., ( 2012 ) consider tree pruning in a sequential decision-making task. The basic idea is that rather than considering all possible paths of a decision tree unfolding from a particular choice (e.g., Fig. 3 , top), an agent might selectively drop certain paths. In the Huys et al. setting this including pruning sequential paths that likely lead to particular types of outcomes (e.g., punishment). An analogous strategy in the OED setting might mean removing from consideration answers for which P ( a ) falls below some threshold. While such ideas have yet to be tested in the inquiry literature, certain heuristic strategies should bias choices in specific ways. For example, it may be possible to experimentally detect a tendency to discard low probability answers with high information utility.
Integration by generalized means
A final approach considers alternative ways of computing P ( a ), and the possibility of averaging some function of answer utility values, rather than the raw answer utility values themselves. The General Theory of Means (Muliere and Parmigiani, 1993 ) provides a general mathematical framework. One extension of Eq. 1 is to use answer weights that are nonnegative and sum to 1, but which do not necessarily correspond to answer probabilities:
Defining expected utility in terms of answer weights, rather than answer probabilities, highlights that in the normative theoretical sense, there is a decision to make about what kind of weights to use (e.g., maximum entropy consistent with known constraints, or a minimax strategy, etc).
The basic constraint in the General Theory of Means framework is that the weights should be nonnegative and should sum to 1. For example, if the probability of some answers is well-understood, but the probability of other answers is not known, people might assign higher weight to answers with less-well-understood probabilities, other things being equal. The important points, theoretically, are: (1) from a normative standpoint, we seldom really know the answer probabilities and (2) from a descriptive standpoint, although answer weighting is central to OED models, we still lack a good understanding how people actually evaluate answer utilities.
The OED framework defines the value of a question as the probability-weighed average of the value of its individual answers. We have reason to suspect that this is not the full story, given that the probability of individual answers is not always knowable, that it is combinatorially difficult or impossible to integrate all possible answers in some circumstances, and that various heuristic strategies might be simpler. Proposals from the decision-making literature suggest some computationally feasible strategies to handle the combinatorics of evaluating all possible answers’ usefulness. Assessing how people weight individual answers is ripe for future research, as alternate proposals can be well-specified, and there has been virtually no research in this area to date.
Question 5: How does learning from answers affect query selection?
Like a scientist who considers what they could learn from possible outcomes of their experiments, an optimal question asker anticipates how an answer would change their current beliefs . For example, computing the expected new Shannon entropy in the EIG model entirely relies on the degree of belief change:

This aspect of question evaluation is a key idea behind the concept of preposterior analysis (Raiffa & Schlaifer, 1961 ) and lies at the heart of the OED approach.
Leaving aside the computational challenges of simulating all possible answers (see previous section), how people update their beliefs based on new data is one of the most fundamental (and contentious) questions in many areas of higher-level cognition, including language acquisition, categorization, stochastic learning, and judgments under uncertainty (e.g., Tenenbaum, Griffiths, & Kemp, 2006 ). Findings from this longstanding line of work can inform the study of inquiry in a number of ways, two of which will be discussed below. First, we will discuss how deviations from OED norms during inquiry can emerge from particular violations of inference norms. Second, we will show that inductive inference strategies are often heavily influenced by the current context and the identity and intentions of the person providing the information. Since a vast number of inquiry scenarios are embedded in some form of social or educational context, understanding this pragmatic aspect of inference is pivotal for a complete account of question-asking.
Inductive norm violations
There are many ways in which people deviate from (Bayesian) inductive principles when integrating new evidence with prior knowledge. Consider the following well-known examples.
It has been shown that in some situations people exhibit what is often called base-rate neglect (Doherty, Mynatt, Tweney, & Schiavo, 1979 ; Kahneman & Tversky, 1973 ). Base rate neglect is the tendency to evaluate the posterior probability of a hypothesis, P ( h | e ), mostly based on its ability to account for the new evidence, P ( e | h ), while largely ignoring its prior probability, P ( h ).
When evidence is presented sequentially, people often reveal the opposite phenomenon. That is, they assign too much weight on their initial beliefs and behave conservatively when updating these beliefs in light of new evidence (Edwards, 1968 ; Phillips & Edwards, 1966 ).
In other tasks, it has been shown that people exhibit a positivity bias. That is, they assign more weight to positive evidence (e.g., learning that something is true) compared to negative evidence (learning that something is false), even when both types of evidence are equally diagnostic (Hodgins & Zuckerman, 1993 ; Klayman, 1995 ).
There is ongoing debate on whether these phenomena count as biases and whether they can be explained based on people’s task-specific beliefs or preferences (Griffiths & Tenenbaum, 2006 ; Kahneman, Slovic, & Tversky, 1982 ; Krynski & Tenenbaum, 2007 ). What’s important for the present discussion is that they can have significant impact on the expected information value of possible questions. For example, base-rate neglect could lead people to ask questions about hypotheses that can be tested easily, even if the hypothesis in question is unlikely a priori. Among other things, this could lead to an unwarranted preference for medical tests with a high hit-rate, even if they produce many false positives (some authors would argue that frequent mammograms are an example for the tendency to seek such tests; see Elmore et al., 1998 ; Gigerenzer, Mata, & Frank, 2009 ). Conservatism during question asking could lead to a type of “question-asking myopia” whereby askers make a greater effort to test their initial hypotheses, instead of considering alternatives that appeared less likely in the beginning but are supported by incoming data. This could explain the finding that people who are asked to state their hypotheses early during a mock police investigation were subsequently more biased in their information-seeking strategies than those who were not asked to do so (O’Brien & Ellsworth, 2006 ). (The former group not only showed higher confidence in their initial hypothesis, but also sought more evidence for it, irrespective of the alternatives.) Overweighting positive evidence could lead to a preference for questions that people expect to yield “yes” answers. This possibility in particular could provide another explanation for people’s use of a positive testing strategy (discussed above, see also, Klayman & Ha, 1989 ; Wason, 1960 ).
These examples show that deviations from optimal induction principles and violations of inquiry norms can be intimately intertwined. However, even though the relationship between them has been pointed out before (Klayman & Ha, 1989 ; Nickerson, 1998 ), it is rare for psychologists to consider the two in tandem (but see Coenen & Gureckis, 2015 ).
Pragmatic and pedagogical reasoning
Human inquiry does not take place in a vacuum, nor are people’s questions typically directed at an anonymous oracle with unknown properties. Instead, many question-asking scenarios involve a social context that is shared between the questioner and the answerer. Furthermore, questioners usually have at least some expectations about the knowledge, beliefs, and intentions of answerers. This means that evaluating the usefulness of potential answers crucially depends on pragmatic and (in a teaching context) pedagogical considerations.
Shared context
Imagine that at the end of a meal your friend asks “Are you going to finish that?” Your interpretation and potential answer will be completely different if your friend is currently the host of a dinner party (they want to clear the table) or simply sharing a meal with you at a restaurant (they want to eat your food). It’s of course not a new insight that interpretations of language depend on our understanding of the shared context between speaker and listener (Grice, 1975 ; Lewis, 1969 ). However, recent advances in probabilistic pragmatics have made it possible to formalize them as part of a Bayesian inference framework (Frank & Goodman, 2012 ; Goodman & Stuhlmüller, 2013 ; Goodman & Frank, 2016 ), which can be integrated with other probabilistic models, including OED models. To illustrate the main idea behind a probabilistic model of pragmatic interpretation, consider the example in Fig. 4 from Goodman and Frank’s ( 2016 ) Rational Speech Act (RSA) model. Here, a speaker is referring to one of three friends and the listener has to infer which one. The listener does so by recursively simulating the speaker’s beliefs about their own beliefs, starting from a simplistic, “literal” (Lit) version of the listener who updates their beliefs about the world based on Bayes’ rule and a flat prior over referents. Based on this literal listener, the simulated speaker infers that the most informative way of pointing out the hat-wearing friend would have been to refer to the hat directly. Thus, the mention of glasses must refer to the hat-less friend with glasses. (Goodman & Frank, 2016 )

The RSA (rational speech act) framework models pragmatic reasoning as a recursive process. Figure adapted from Goodman and Frank ( 2016 )
A good demonstration of how this probabilistic pragmatic framework can be combined with OED comes from a study by Hawkins, Stuhlmüller, Degen, and Goodman ( 2015 ). They used the RSA model together with EIG to model people’s behavior in a guessing game. In this task, participants were assigned the roles of questioners and answerers. Questioners had the task of finding out the location of hidden objects (e.g., “find the poodle”) by directing questions at the answerers, who could see all of the objects (e.g., a poodle, a Dalmatian, a cat, etc.). Questioners were placed under a set of restrictions on the types of questions they could ask (e.g., must not ask about poodles, but may ask about Dalmatians or dogs) and answerers were equally aware of those restrictions. The study showed that questioners could come up with clever indirect questions (e.g., “where’s the dog?”) that were correctly interpreted by the answerers who then gave helpful answers (revealing the location of the poodle, not the Dalmatian). The authors found that both questioners and answerers were better captured by the combination of an RSA model and EIG than by a “pure” EIG model that just used the literal meaning of both questions and answers. This finding demonstrates that when learners try to anticipate the likelihood of different answers, they also take into account the context or state of the world that is shared with their counterpart.
Features of the teacher
Another important factor that affects what we learn from our questions is the intention and expertise of the person providing the answer. For example, we would expect to receive different answers from a knowledgeable and helpful teacher (Tenenbaum, 1999 ) than from someone who is uninformed or ill-intentioned. This difference between learning in pedagogical and non-pedagogical situations has recently been explored computationally and experimentally (Shafto, Goodman, & Griffiths, 2014 ; Shafto, Goodman, & Frank, 2012 ), showing that learners and teachers can make sophisticated inferences about each others’ minds in order to improve learners’ success. A good demonstration is learning from examples. In a teaching context, learners can usually expect examples to carry more information than just labels, since they expect teachers to choose particular examples that will help the learner generalize (Gweon, Tenenbaum, & Schulz, 2010 ; Tenenbaum & Griffiths, 2001 ; Xu & Tenenbaum, 2007 ). For example, teachers might provide prototypical examples of a category to allow the learner to pick up on the relevant features needed for future classification.
An important question for future research is how askers and answerers simulate the mental states of their counterpart and how many levels of recursive inference (“I think that they think that I think that they think, etc. ...”) are involved in this process. Recent work in probabilistic pragmatics has demonstrated individual variability in terms of levels of recursion (Franke & Degen, 2016 ). Given the evidence that even young children make pedagogical assumptions about teaching adults (Bonawitz et al., 2011 ; Kushnir, Wellman, & Gelman, 2008 ), another question concerns the developmental trajectory of these abilities and how world knowledge (what do people generally assume about one another in question asking scenarios?) and social reasoning (what are the intentions of this particular individual?) contribute and interact to shape the extremely sophisticated inferences that adults make about each other during inquiry.
Many OED models assume that learners anticipate how the answers to their queries will change their current beliefs. Here, we pointed out two important factors that may constrain this process and consequently affect how queries are chosen. First, given what we know about the plethora of inductive inference biases that people exhibit in other tasks, there is little reason to believe that anticipating future belief-change during inquiry should follow normative principles (Bayes’s Rule) in every respect. Thus, when there is reason to believe that people are anticipating future belief change (like OED models suggest), one has to take into account how biases in this process would affect potential biases during query selection. Second, when answers are provided by other people, as it is often the case during inquiry, learners’ inferences will be constrained by pragmatic and pedagogical considerations. Thus, to build realistic inquiry models, we need a better understanding of the psychological underpinnings of inferences in social contexts.
Question 6: How do cognitive constraints influence inquiry strategies?
Previous sections of this paper have pointed out that the OED framework, if interpreted in a mechanistic way, makes very ambitious computational demands that would indubitably exceed learners’ memory and processing limitations. In earlier sections we discussed the idea that learners may sometimes restrict their hypothesis space, sample from their posterior beliefs, or approximate the aggregation of answer utilities into a question utility. These ideas fall largely within the OED framework in the sense that they represent cognitively plausible but statistically principled approximations. However, another possibility is that people use an entirely different set of strategies that are not curtailed versions of OED models to balance the trade-off between computation, accuracy and ease of processing (Simon, 1976 ).
One inquiry strategy that has received a lot of attention in educational psychology is the principle of controlling variables (CV). A CV strategy says that learners design experiments by changing one experimental variable at a time and holding everything else constant. Besides the benefit of yielding unconfounded evidence, this strategy is considered desirable because it is relatively easy to use and teach (Case, 1974 ; Chen & Klahr, 1999 ), even though children do not often generate it spontaneously (Kuhn et al., 1995 ; Kuhn, Black, Keselman, & Kaplan, 2000 ). By focusing on only one variable at a time, it reduces the number of items to be held in working memory and also creates easily interpretable evidence (Klahr, Fay, & Dunbar, 1993 ; Tschirgi, 1980 ). Although CV is often treated as a normative strategy (Inhelder & Piaget, 1958 ), its effectiveness in an OED sense actually depends on very specific features of the system of variables at hand. For example, when there are many variables but very few of them have any effect on the outcome, it can be much more efficient to manipulate multiple variables at once, assuming that testing for the occurrence of the outcome is costly. However, adults often still test variables in isolation, even when testing multiple variables is more efficient (Coenen, Bramley, Ruggeri, & Gureckis, 2017 ). Empirically, these results may reflect the prominence of controlling variables in educational settings, or because people experience the CV strategy to effectively balance effectiveness and ease of use. The key point for the present purposes is that the CV strategy is not entirely equivalent to OED.
There are other ways in which people might trade off informativeness and computational tractability. Klayman and Ha ( 1987 ), Klayman and Ha ( 1989 ) found that participants often engage in a strategy they called limit testing . According to this approach, people restrict their hypothesis set to one focal hypothesis and seek confirmatory evidence for it. However, within that focal hypothesis people still test regions of higher uncertainty. For example, if a learner’s focal hypothesis in a rule testing task was that “countries in South America” satisfy the rule, they might test this hypothesis by asking about South American countries at geographical extremes (e.g., Venezuela and Uruguay), to make sure that the true hypothesis is not in fact smaller than the current one (e.g., “countries in South America that are South of the Equator”). This strategy allows learners to refine their beliefs while still engaging in positive testing, which violates OED norms in many circumstances (see Introduction). Like a controlling variables strategy, limit testing thus does not count as an “optimal” strategy without significant additional assumptions (Nelson et al., 2001 ). However, it might be a very reasonable approach given constraints of a learner’s ability to represent the full set of hypotheses.
Other examples include the idea that people can simply mentally compare two alternative hypotheses, look for places where they diverge, and then ask queries specifically about such diverging points. This process does not require enumerating all possible queries or answers, but it may be a reasonable heuristic in many cases. For example, when deciding between two hypotheses about the structure of a causal system, it is possible to choose which variables to manipulate by comparing the two structures and finding points where they differ (e.g., links that go in opposite directions). In fact, such a “link comparison” heuristic can sometimes closely mimic predictions from an EIG model (Coenen, Rehder, & Gureckis, 2015 ).
Finally, some inquiry behaviors might be selected via a reinforcement learning strategy where questions or actions that lead to positive outcomes are repeated (Sutton & Barto, 1988 ). For example, you might ask a speaker in a psychology talk “Did you consider individual differences in your study?” because in the past this has been a useful question to ask no matter the speaker or content. While this might lead to highly stereotyped and context-inappropriate questions, it is in fact possible to train sophisticated reinforcement learning agents to adapt question asking to particular circumstances based on intrinsic and extrinsic reward signals (Bachman, Sordoni, & Trischler, 2017 ). Importantly, the reinforcement learning approach arrives at the value of an action in an entirely different way than an OED model. Instead of prospectively evaluating possible answers and their impact on current beliefs, it relies on a history of past reinforcement. Depending on the specific assumptions, this approach may be discriminable from OED models, particularly during early learning of inquiry strategies.
Adaptive strategy selection
These alternative information-gathering strategies deserve consideration alongside OED not only as alternative theoretical frameworks (as for instance the reinforcement learning approach might represent) but also because they might represent cognitive strategies that trade off against more OED-consistent approaches in different situations. Following on this latter idea, what determines whether people follow an optimal OED norm or a heuristic that is easier to use, like controlling variables or limit testing? While determinants of strategy selection have been studied extensively in other domains, like decision making (Lieder et al., 2014 ; Marewski & Schooler, 2011 ; Otto, Raio, Chiang, Phelps, & Daw, 2013 ; Rieskamp & Otto, 2006 ), relatively little work addresses this question in the inquiry literature. One exception is a recent study by Coenen, Rehder, and Gureckis ( 2015 ), who investigated the use of an OED norm (EIG) and a simpler heuristic (positive testing strategy) in a causal inquiry task. Across multiple experiments, participants were asked to intervene on three-variable causal systems to determine which of two possible causal structures governed the behavior of each system (similar to Fig. 5 , top). Figure 5 (bottom) shows posterior inferences over the hyperparameter μ from a hierarchical Bayesian model of people’s intervention choices. This parameter measures the degree to which participants, on average, relied on an EIG strategy ( μ = 1), compared to a positive testing heuristic ( μ = 0), which cannot be explained as an approximation of EIG (see paper for full argument). The different distributions are posterior distributions of this parameter for different between-subject experiments that varied a number of task parameters. In the “Baseline” experiment, participants’ behavior was best described by a mixture of the two strategies. In subsequent experiments, however, behavior spanned a wide spectrum of strategy profiles. In the experiment corresponding to the rightmost distribution, labeled “EIG superior”, participants received an additional set of problems before completing the baseline task. These problems were specifically designed to penalize non-OED strategies (i.e. positive testing would yield completely uninformative outcomes most of the time, costing participants money). Having worked on these problems, participants were more likely to use EIG in the baseline part of the experiment, which indicates that, in principle, most people are able to implement the normative solutions if they learn that their performance would suffer severely otherwise. In contrast, in three experiments that added time pressure to the baseline task (see three leftmost distributions), participants’ behavior was much more in line with the positive testing heuristic. This indicates that the availability of cognitive resources can determine how people trade off the use of more complex OED norms and simpler inquiry heuristics.

Top : Examples of two possible causal graphs relating three nodes (variables). The nodes can take on one of two values (on or off). In the experiment, participants had to intervene on a similar system by setting the value of the nodes in order to determine which of two possible causal graphs actually described the operation of a unknown system. Bottom : Inferred posterior probability over hyperparameter μ in different experiments reported in Coenen, Rehder, and Gureckis ( 2015 ). μ captures the average strategy weight of participants in a causal intervention task. When μ = 1, behavior is completely captured by the OED norm Expected Information Gain (EIG), when μ = 0, it is best fit with a heuristic positive testing strategy (PTS). Values in-between correspond to mixed strategies
In a related example, Gureckis and Markant ( 2009 ) explored how people searched for information in a simple spatial game based on Battleship (see Fig. 2 ). They identified two distinct search “modes” as the task unfolded. At the beginning of the task when the hypothesis space was relatively unconstrained, people’s choices were less in accordance with specific OED predications and instead appeared more random and exploratory. These decisions were also made relatively quickly. However, at later points in the game, people seemed to behave more in line with OED predictions and their reaction times slowed significantly. This particularly happened in parts of the task where a small number of highly similar hypotheses became viable (i.e., situations where OED might be more computationally tractable). This suggests that even within the context of a single learning problem, people might shift between strategies that are more exploratory (i.e., less directed by specific hypothesis) and more focused on the disambiguation of specific alternative hypotheses.
There are many factors that have yet to be explored with respect to their impact on strategy selection during inquiry, including task difficulty, working memory capacity, fatigue, and stress. Research into these topics will allow the field to move beyond simple demonstrations of the OED principle and help explain and predict inquiry behavior in different environments and given particular circumstances of the learner. This topic is of practical importance because inquiry plays a crucial role in a number of high-stakes situations that happen under both external (e.g., time) and internal (e.g., stress) constraints, like emergency medical diagnosis or criminal investigations. Finally, this line of research also dovetails with a growing interest in cognitive science for models that take into account the cost of computation, and could contribute to the empirical basis for the development of these models (Hamrick, Smith, Griffiths, & Vul, 2015 ; Lieder et al., 2014 ; Vul et al., 2014 ).
Question 7: What triggers inquiry behaviors in the first place?
OED models describe how people query their environment to achieve some particular learning goal. The importance of such goals is made clear by the fact that in experiments designed to evaluate OED principles, participants are usually instructed on the goal of a task and are often incentivized by some monetary reward tied to achieving that goal. Similarly, in developmental studies, children are often explicitly asked to answer certain questions, solve a particular problem, or choose between a set of actions (e.g., play with toy A or toy B, see Bonawitz et al., 2010 ). However, many real-world information-seeking behaviors are generated in the absence of any explicit instruction, learning goal, or monetary incentive. What then inspires people to inquire about the world in the first place?
This is an extremely broad question and there are many possible answers. According to one approach, the well-specified goals that are typically used in OED experiments are representative of a more general information-maximizing “over-goal” that always accompanies people while navigating the world (e.g., Friston et al., 2015 ). This view is particularly well represented by research on children’s exploratory play, where the claim is often made that this behavior represents sophisticated forms of self-guided inquiry that arise spontaneously during unsupervised exploration (Schulz, 2012b ). For example, Cook et al., ( 2011 ), whose study is described in more detail above, argue that OED computations form an integral part of preschoolers’ self-guided behavior even in the absence of concrete goals:
“...many factors affect the optimal actions: prior knowledge and recent experience enter through the term P(H), while knowledge about possible actions and likely affordances enters through the term P(D—A, H). ... Our results suggest that children are sensitive to all of these factors and integrate them to guide exploratory play” (p. 348).
Under this view, the constraints of popular experimental paradigms simply help control for and standardize the behavior across participants, while still capturing the key aspects of self-motivated inquiry.
One objection to this view is that at any given moment there are many possible inquiry tasks a learner might decide to pursue. While reading this paper you might be tempted to take a break and read about the latest world news, track down the source of a strange sound you hear from the kitchen, or start learning a new instrument. All of these actions might reduce your uncertainty about the world in various ways, but it seems difficult to imagine how OED principles would help explain which task you choose to focus on.
An alternative view acknowledges these limitations of the OED framework and instead argues that OED applies specifically to inquiry devoted to some particular task “frame” (i.e., a setting in which certain hypotheses and actions become relevant). For example, a task frame might be a person in a foreign country trying to determine if the local custom involves tipping for service. The set of hypotheses relevant to this task deal specifically with the circumstances where people might be expected to tip (never, only for bar service, only for exceptional service, etc.), and do not include completely irrelevant hypotheses (e.g., how far away the moon is in kilometers). In psychology experiments, such tasks are made clear by the instructions, but in everyday settings a learner must chose a task before they engage in OED-like reasoning or learning strategies. This latter view seems somewhat more likely because absent a task frame the hypothesis generation issue (see Question 1) becomes even more insidious (imagine simultaneously enumerating hypotheses about events in the news, possible sources of noise in the kitchen, and strategies for improving your piano play). However, this leaves open the question of how people define these tasks or goals in the first place. Here we consider two elements to this selection: subgoal identification and intrinsic curiosity.
Subgoal construction
When learning it often makes sense to divide problems into individual components that can be tackled on their own. For example, if a learner’s broader goal is to find out which ships are hidden in which location during a game of Battleship (see Fig. 2 ), they might break down the problem into first approximating all the ships’ locations, and then determining their shapes. For example, Markant et al., ( 2015 ) describe an empirical task that led people to decompose a three-way categorization task into a series of two-way classification problems while learning via self-guided inquiry. This happened despite the fact that the overall goal was to learn all three categories.
Many learning problems have a hierarchical structure of over-goals and subgoals. Whereas OED norms make predictions about how to address each individual subgoal, they do not naturally capture the process of dividing a problem space into different subsets of goals.
Understanding how people identify subgoals while approaching a complex learning problem is difficult (although there exists efforts in the reinforcement learning literature to formalize this process, see e.g., Botvinick, Niv, & Barto, 2009 ). A full account of subgoal development would probably require knowing a person’s representation of the features of a problem and their preferences for the order of specific types of information.
However, there also exist cases in which goal partitions emerge not from an informational analysis of every individual problem, but via a learning process across many problems that yields a kind of “template” for asking questions in some domain. A college admissions interviewer might learn, for example, that in order to estimate the quality of a prospective student, it is a useful subgoal to find out what types of books they’ve read in high school. This may not be the most efficient subgoal to learn about each individual student (it is probably more useful for potential English majors than Physics applicants), but may lead to good enough outcomes on average. In many domains such templates do not even need to be learned, because they have been developed by others and can be taught easily. Consider for example the “Five Ws” (Who? What? When? Where? Why?) that serve as a template for question-asking subgoals in many different areas of inquiry and for many different types of over-goals (solving a crime, following a storyline, understanding the causal structure of an event, etc.). It would be interesting to study how such conventional templates influence people’s preferences for establishing hierarchies of goals, and how learned and conventional partitions trade-off or compete with the expected value of information, in particular tasks.
The subgoal/over-goal framework might provide a useful way for thinking about how OED principles might be selected in the first place. A learner might have a generic over-goal to “be an informed citizen” and this then leads to a variety of smaller inquiry tasks that help learn about the impact of proposed changes to tax policy or in the political maneuvering of various parties. Behaviors within these subgoals may look more like OED inquiry where alternative hypotheses are considered; by contrast, the over-goal is more nebulous and is not associated with enumerable hypotheses.
In sum, at least one piece of the puzzle for what triggers inquiry behavior is to consider how people select task frames. The subgoal idea may be an additional fruitful direction, because it makes clear how self-defined objectives might be constructed during learning.
Curiosity and intrinsic motivation
Of course, aside from specific goals, we might decide to spend more time learning about a topic or task frame simply because we are curious. While disinterested OED models (i.e., those with a value function that does not include internal or external costs) are agnostic about why learners seek out information, there is a longstanding parallel research tradition in psychology that studies the cognitive and neural bases of curiosity and intrinsic motivation. For example, it is well-known that children spontaneously explore objects with some level of complexity or uncertainty without any instruction to do so (Cook et al., 2011 ; Kidd, Piantadosi, & Aslin, 2012 ; Schulz & Bonawitz, 2007 ; Stahl & Feigenson, 2015 ). Meanwhile, adults care about the answers to otherwise useless trivia questions (Kang et al., 2009 ). Experiments have also shown that humans and other primates are even willing to sacrifice primary rewards (like water, money, and time) in exchange for information without obvious use (Blanchard, Hayden, & Bromberg-Martin, 2015 ; Kang et al., 2009 ; Marvin & Shohamy, 2016 ).
To exhaustively review this literature is beyond the scope of this paper, and would be largely redundant in light of recent review articles on the subject (Gottlieb, 2012 ; Gottlieb, Oudeyer, Lopes, & Baranes, 2013 ; Kidd & Hayden, 2015 ; Loewenstein, 1994 ; Oudeyer, Gottlieb, & Lopes, 2016 ). However, there are some particularly intriguing findings and theoretical developments in the curiosity literature that we think deserve attention by psychologists studying inquiry with OED models. In particular, they point out factors and mechanisms that add value to certain sources of information over others. These sources of value could potentially be integrated with OED models to yield more accurate predictions about how people choose subjects of inquiry.
To explain curiosity, researchers have traditionally suggested that it is a primary drive (perhaps as a consequence of some evolutionary process that favors information seekers), or an expression of some innate tendency for sense-making (Berlyne, 1966 ; Chater & Loewenstein, 2015 ; Loewenstein, 1994 ). Similarly, recent work has proposed that people seek information because it generates a type of intrinsic reward, similar to “classic” extrinsic rewards, like food or money (Blanchard, Hayden, & Bromberg-Martin, 2015 ; Marvin & Shohamy, 2016 ). In support of this claim, some studies have found activation in primates’ neural reward circuitry during information search that is similar to activation during other types of value-based choice (specifically, the primate data was collected in dopaminergic midbrain neurons Bromberg-Martin & Hikosaka, 2011 ; Redgrave & Gurney, 2006 ). Furthermore, a set of recent fMRI studies with humans has found correlations between people’s self-reported curiosity about trivia-questions and activation in areas of the brain involved in processing other rewards (Gruber, Gelman, & Ranganath, 2014 ; Kang et al., 2009 ).
What types of information can trigger such intrinsic reward signals? A key component of many theories of curiosity-driven learning is an inverse U-shaped relationship between a learner’s current knowledge and their expressed curiosity about some fact, domain, or stimulus (Kang et al., 2009 ; Kidd, Piantadosi, & Aslin, 2014 ; Kidd & Hayden, 2015 ; Loewenstein, 1994 ). This means that curiosity is often highest for domains or tasks in which people’s knowledge is at an intermediate level. This finding tallies with learning and memory research showing that items with intermediate difficulty are often learned most efficiently (Atkinson, 1972 ; Metcalfe & Kornell, 2003 ). Thus, asking questions about facts or relationships that are “just slightly beyond the individual’s current grasp” (Metcalfe & Kornell, 2003 ) might be an adaptive strategy that helps direct people’s attention to worthwhile opportunities for learning (Vygotsky, 1962 ). This suggests that intrinsic reward from information can stem from a learner’s expected learning progress, an idea which is already used to build algorithms in self-motivated robots (Oudeyer, Kaplan, & Hafner, 2007 ).
Another source of informational value is the anticipation of extrinsic rewards in the future that might come from obtaining information in the present. This was demonstrated empirically by Rich and Gureckis ( 2014 ), Rich and Gureckis ( 2017 ), who showed that people’s willingness to explore risky prospects increased with their expectation to encounter them again in the future. This instrumental motivation to explore may actually underlie many kinds of seemingly intrinsically motivated information-seeking behaviors, or at least play some part in shaping people’s motivation to seek information. For example, one might be intrinsically curious about the answer to a trivia question, but this effect could be enhanced if the question also pertains to one’s future goals (a trivia question about the capital cities in South America would have more appeal for someone who has to take a geography test next week).
While work on curiosity does not specifically focus on how people choose particular task frames and subgoals, it does identify factors that affect what kind of information people seek and offer some hints about why they do so in the first place. Future work is needed to disentangle when people seek information for instrumental (future extrinsic reward) or epistemic (knowledge progress) purposes, and what types of information have evolved to yield particularly strong intrinsic rewards.
Identifying the source of people’s thirst for information lies outside the realm of the OED framework. However, it also lies at the very core of what makes inquiry such a fundamental and fascinating human activity, and thus deserves further study. To arrive at a unified set of computational principles that underlie curiosity, motivation, and informational value will likely require overlapping efforts by cognitive psychologists, neuroscientists and developmental researchers (Kidd & Hayden, 2015 ). Furthermore, recent advances in reinforcement learning models of intrinsic motivation (Oudeyer et al., 2007 ; Oudeyer et al., 2016 ; Singh, Barto, & Chentanez, 2004 )may serve as an important inspiration for computationally informed theories.
Question 8: How does inquiry-driven learning influence what we learn?
The OED framework emphasizes effective or even optimal information gathering which, in turn, implies more effective learning. One of the major reasons that inquiry behavior is a topic of study is because it has implications for how best to structure learning experiences in classrooms and other learning environments. For example, in the machine learning literature, active information selection can be proven to reduce the number of training examples needed to reach a particular level of performance (Settles, 2010 ). However, a key question is if active inquiry reliably conveys the same advantages for human learners. In the following section we review existing work on this topic, first considering the relevant benefits of active over passive learning, and next considering the effect of the decision to stop gathering information on learning. Our core question here concerns when active learning improves learning outcomes and how knowledge acquired during active learning can deviate from underlying patterns in the environment.
Active versus passive learning
A number of studies have attempted to compare active and passive learning in simple, well controlled environments (Castro et al., 2008 ; Markant & Gureckis, 2014 ; Sim, Tanner, Alpert, & Xu, 2015 ). For example, Markant and Gureckis ( 2014 ) had participants learn to classify simple shapes into two categories. The experiment contrasted standard, passive learning against a self-directed learning condition. In the passive learning condition, an exemplar was presented on the screen and after the delay the category label of the item was provided. Across trials participants attempted to learn how to best classify new exemplars. In the active learning condition, participants could design the exemplars themselves on each trial, and received the category label of the designed item. The critical difference between these conditions is if the learner themselves controls which exemplar is presented (active learning) or if it is selected by the experimenter or some external process (passive learning). The study found that active learning led to faster acquisition of the category than passive learning. Furthermore, a third condition, in which yoked participants viewed the designed examples of the active group in a passive setting, showed significantly worse performance than the other groups. The results showed that allowing participants to control the selection process during learning improved outcomes (a process the authors referred to as the hypothesis-dependent sampling bias). This bias is the tendency of active learners to select information to evaluate the hypothesis they currently have in mind, which often does not transfer to other learners (such as the yoked condition) who have alternative hypotheses in mind (Markant & Gureckis, 2014 ). One study has since tested this idea with children (Sim, Tanner, Alpert, & Xu, 2015 ), while another has explored the boundaries of the effect (MacDonald & Frank, 2016 ; Markant, 2016 ).
A potential downside of selecting data based on one’s current hypotheses and goals is highlighted by an idea that Fiedler (2008) calls the “ultimate sampling dilemma” According to this idea, there are two main ways people obtain information from the world around them. The first is natural sampling , a learning process in which the ambient statistical patterns of the environment are experienced through mostly passive observation. Natural sampling is related to unsupervised learning (Gureckis & Love, 2003 ; Pothos & Chater, 2005 ) but focuses more on the data generating process (i.e., how examples are encountered) rather than the lack of supervision and corrective feedback. For example, by walking around a new city one might get a sense of the typical size of a car in the region. Artificial sampling refers to situations where learners intervene on the world to influence what they learn about (e.g., asking about the size of one particular brand of car), thereby interrupting the natural way that data is generated. The ultimate sampling dilemma points out that these two forms of learning can sometimes trade off with each other because they expose different aspects of the environment. As Fiedler (2008) points out, natural sampling is less likely to bias learners, because they are exposed to the true patterns in the world without altering them through their own behavior. This allows them to learn about natural variation in the world and enables them to gather information about typicality or frequency, for example. On the other hand, artificial sampling, for instance based on an OED model, can have the benefit of being much more efficient for answering a particular question or for seeking out exemplars that occur rarely but are highly informative. In those cases, learning only via natural sampling can require waiting a long time for these particularly informative or infrequent patterns to occur. Of course in some domains, such as causal reasoning, artificial sampling or active intervention is actually necessary for uncovering certain relationships in the environment (Pearl, 2009 ; Schulz, Kushnir, & Gopnik, 2007 ). As a result, some combination of natural and artificial sampling may be best for promoting more robust learning (MacDonald & Frank, 2016 ). The best way to do this is still up for debate, however, and there remain key questions about how other elements, such as the learners’ conception of a problem, influence learning.
By highlighting the benefits and potential pitfalls of artificial and natural sampling, the ultimate sampling dilemma quite naturally suggests how the tension between the two might be resolved. Since natural sampling helps build an accurate representation of the statistical properties of the world, it might be particularly beneficial for sampling environments that are novel and about which a learner lacks knowledge regarding the most important features or variables. Thus, natural sampling through passive observation forms a natural first step during inquiry in a novel domain, before being followed by more targeted hypothesis-driven inquiry. Of course, an important empirical question is if people are able to determine the best point at which to switch from one mode of questioning to the other (Tversky & Edwards, 1966 ).
Stopping rules
Besides choosing what to learn, people often face the question when to stop searching for information. This question is particularly relevant when reaching absolute certainty is unlikely or impossible and learners have to decide when their current level of information is “enough”. OED models (see Question 3) make predictions about when stopping becomes more desirable than making additional queries, but the problem can be formalized more broadly for scenarios in which the content of samples is trivial (i.e., problems that do not require an OED model to select particular queries). A common approach is to use principles of optimal control theory and dynamic programming (some of the work presented in this section takes this approach, see also Edwards, 1965 ; Ferguson, 1989 , 2012 ). In psychology, the stopping question has been approached in different ways. While some researchers have studied whether people collect too much or too little information given the cost structure of a task, others have looked at the impact of stopping decisions on subsequent beliefs and behaviors. Here, we will investigate the second question, as it reveals some subtle ways in which control during learning can affect our beliefs.
How stopping decisions shape our experience
A separate line of research investigated what effect (optimal) stopping strategies have on people’s experiences and beliefs about the world.
Stopping decisions can be the source of distorted views of people’s environment. For example, stopping rules can lead to asymmetric knowledge about different options if these options have valence of some sort (i.e. they can be rewarding or not). A good example is the so-called hot stove effect (Denrell & March, 2001 ). Loosely speaking, it is the tendency to underestimate the quality of novel or risky prospects that happen to yield low rewards early on and are subsequently avoided. Having a single bad experience at a new restaurant might deter customers from re-visiting and potentially correcting that bad impression in the future. Since some bad experiences happen to be exceptions, some restaurants end up being undervalued as a consequence. On the other hand, a coincidental positive experience will not lead to a corresponding over valuation because decision makers will likely revisit these restaurants to reap more benefits and eventually find out their “true” value via regression to the mean. If it turns out the initial good experience was an exception, customers will eventually realize this and correct their good impression. Similar effects have been observed in other tasks that involve choice-contingent information, like approach-avoid decisions (Rich & Gureckis, 2014 ), or situations in which access to feedback is asymmetric across prospects (Le Mens & Denrell, 2011 ).
This work demonstrates the potentially large impact that the seemingly innocuous decision of stopping search can have on how we perceive the world. By choosing to learn more about options that we think are rewarding and ignoring those that we suspect to be bad, we can end up with widely asymmetric beliefs. Such asymmetries can be the source of misconceptions with potentially problematic effects. On a social level, for example, they can produce and solidify stereotypes about people or whole social groups, or increase social conformity (Denrell & Le Mens, 2007 ). They can also lead to unnecessary risk-aversion and resistance to change (because good but variable prospects are more likely to yield low initial rewards), which can be harmful for both individuals and organizations in the long run. Future work should further investigate the impact of stopping decisions on people’s beliefs and judgments as well as determining methods of mitigating stopping-induced biases.
The results reviewed in this section highlight that optimal inquiry is not just a function of selecting the right queries to answer one’s questions in an OED sense. It also involves knowing the right time to switch between active and passive learning, realizing the right moment to terminate search, and being aware of the conditions under which our self-selected data was generated. While existing results primarily stem from the judgment and decision-making literature, these issues hold relevance for educators because they help to lay out expectations about when active inquiry will succeed or fail as a pedagogical strategy. Similarly, the problem of deciding when to stop searching for information is crucial for many inquiry tasks, like dividing up study time for different material that will appear on a quiz, asking questions in emergency situations when time is of the essence, or deciding when one has collected enough data to finally start writing a manuscript. Making the wrong stopping decisions in any of these scenarios can have unintended negative consequences and undo any benefits that carefully executed OED methods have accrued.
Question 9: What is the developmental trajectory of inquiry abilities?
The OED hypothesis has been particularly influential in work on children’s exploration and learning (Gopnik, 2012 ). To provide an extensive review of the large literature on children’s inquiry behavior is beyond the scope of this paper (see Gopnik & Wellman, 2012 ; Schulz, 2012b , for excellent summaries). However, it is important to consider a few of the developmental issues involved in inquiry skills, particularly when these touch on core concepts related to OED.
The child as optimal scientist
A growing number of studies suggest that even young children are surprisingly sophisticated at detecting opportunities to obtain useful information. For instance, Stahl and Feigenson ( 2015 ) showed infants objects, some of which moved in ways that violate physical laws (e.g., solid objects that appear to move through solid walls). Subsequently, infants were found to explore these objects preferentially, even going so far as to perform actions like banging them on the floor to test their solidity (see also Bonawitz, van Schijndel, Friel, & Schulz, 2012 ). Similarly, preschool aged children have been shown to devote more exploratory play to a toy after being shown confounded evidence for how it works (Schulz & Bonawitz, 2007 ; Cook et al., 2011 ; van Schijndel, Visser, van Bers, & Raijmakers, 2015 ). Children also seem to integrate subtle social cues to help guide their exploration, such as exploring more when an adult teacher provides uninformative instruction (Gweon, Palton, Konopka, & Schulz, 2014 ). Still further, some evidence suggests that children can effectively test simple causal hypotheses through interventions that maximize information (Kushnir & Gopnik, 2005 ; McCormack, Bramley, Frosch, Patrick, & Lagnado, 2016 ; Schulz, Gopnik, & Glymour, 2007 ).
Based on such findings, researchers have argued that children act in ways analogous to scientific experimentation (Schulz, 2012b ). Gopnik ( 2009 ) writes “When they play, children actively experiment on the world and they use the results of these experiments to change what they think.” (p. 244). In some areas of cognitive development these abilities are viewed as directly supporting the idea of the “child as an optimal scientist”. The core of this idea, and what brings it into alignment with OED, is that children’s prior knowledge, beliefs, and goals help to structure their information gathering behaviors.
While it is important and intriguing that young children show so many early signs of successful information gathering, not all of these behaviors need be thought of as following exclusively from OED principles. For example, a child might selectively play with a toy after being shown confounded evidence about how it works without considering alternative hypotheses about the causal structure (Schulz, 2012a ). Likewise, if exploration always follows violations in expectations, eventually learning will cease because most of the time (e.g., outside the lab) the world works in reliable and predictable ways (Schulz, 2015 ). As a result, it is important to keep in mind alternative views on children’s exploration. For example, Hoch, Rachwani, and Adolph (in review) describe how infants have seemingly haphazard exploration tendencies. Using head-mounted eyetrackers, these studies show that infants rarely move directly toward focal locations (toys placed in different areas of a room) while walking or crawling that they had previously fixated while stationary, as might be expected with goal directed exploration. In addition, they move around empty rooms just as much as ones filled with interesting and novel toys (Hoch et al., 2018 ). The opposing perspective offered by this work is that infants are not identifying possibilities for new information and strategically orienting toward them but instead engage in “high-variance” motor plans that discover information almost by serendipity.
The difference between these viewpoints reflects one of the key issues in evaluating the OED framework that we have raised throughout this article. It is possible that there is some set of goals and beliefs that makes the apparently haphazard behavior of infants in Hoch et al. (in review) make sense as an optimal information seeking strategy. However, it is also useful not to lose sight of questions about what might change and develop across childhood. As we have reviewed through this article, actually implementing OED-style computations is a complex cognitive ability requiring the coordination of hypotheses, actions, evidence, and learning. It is clear that precisely adhering to the OED framework (especially in messier, real-world environments) requires more than what young children have so far been shown to do. For example, after kids identify opportunities for knowledge gain, they also have to figure out the best way to get that knowledge, and (as reviewed below) that has proven difficult, especially in complicated situations.
In the following sections we review three key developmental issues related to OED. First, we consider how the issue raised in Question 1 (hypothesis generation) bears on developmental changes in inquiry behavior. Next we review evidence about inquiry in more formal classroom situations. Finally, we discuss children’s question asking, an important type of inquiry behavior available after acquiring language. Throughout we attempt to focus our review on how existing evidence bears on the core computations assumed by OED models and how components of this model might change over the course of development.
Explaining children’s variability via hypothesis sampling
One attempt to reconcile the view that children are optimal scientists but also seemingly random in their exploration is to acknowledge that children do not apply OED principles consistently or as well as adults, and instead exhibit more variable behavior (Cook, Goodman, & Schulz, 2011 ; Schulz, 2012b ). Children might simply enter the world with a broader hypothesis space, weaker priors, and/or fewer cognitive resources, which translates to seemingly noisy or more exploratory behavior (Bonawitz et al., 2014 ; Bonawitz et al., 2014 ; Denison, Bonawitz, Gopnik, & Griffiths, 2013 ; Gopnik & Wellman, 2012 ). Computationally, this might be consistent with approximate Bayesian inference by sampling hypotheses from the posterior, similar to the rational process models described under Question 1. In fact, Gopnik and colleagues have recently argued that the development of both internal (hypothesis sampling) and external (i.e., exploratory play, information generation actions) search may be akin to simulated annealing (Kirkpatrick, Gelatt, & Vecchi, 1983 ) where increasingly random and undirected search strategies in infancy slowly transition to more stable and structured patterns through to adulthood (Buchsbaum, Bridgers, Skolnick-Weisberg, & Gopnik, 2012 ). In some cases this can even lead younger learners to find solutions that evade adults by avoiding local minima (e.g., Gopnik, Griffiths, & Lucas, 2015 ).
Hypothesis sampling models can capture more or less variable behavior given different parameters (e.g., the number of samples taken) and thus provide one computational mechanism that naturally accommodates developmental change. Such an account might also accommodate the undirected exploration of Hoch et al. with the idea that the variability in the behavior is slowly “turned down” over the course of development Footnote 2 . Overall this approach seems promising as long as one keeps in mind the caveats raised about this approach under Question 1 above. For instance, sampling models so far tend to ignore deep integration with other cognitive processes (e.g., memory retrieval), and they also raise the question whether extremely variable behavior generated by such models can even be properly described as optimal in a way that captures the spirit of the child-as-scientist metaphor. In addition, applying such a model to explain the behavior of very young children can be very difficult because it is hard to identify what hypothesis space should be sampled (e.g. in Stahl and Feigenson ( 2015 ), what hypothesis spaces about the physical world do children consider?).
Nevertheless, this approach remains a fertile area for exploration. One obvious empirical prediction of this theory is that the major change in inquiry behavior across development does not necessarily manifest in absolute performance but in inter-subject variability. This suggests a slightly different focus for developmental research which is often framed in terms of when children achieve adult performance in a task. If children are optimal but noisy, the key issue should be characterizing changes in variability.
Inquiry in the science classroom
The concept of inquiry as a cognitive activity has been hugely influential in science education (Inhelder & Piaget, 1958 ; Chen & Klahr, 1999 ; Kuhn, Black, Keselman, & Kaplan, 2000 ). A key focus has been to teach general strategies for learning about causal structure (e.g., how variables such as water, fertilizer, or sunlight might influence the growth of a plant in a science lab, see Klahr et al., 1993 ). However, compared to the developmental literature reviewed above, the conclusion of much of this research is that children often struggle into early adolescence with learning and implementing such strategies. For instance, as reviewed in Question 6, children famously have trouble learning the principle of controlling variables (i.e., changing one thing at a time) and applying it spontaneously to new problems (Chen & Klahr, 1999 ; Klahr & Nigam, 2004 ). That is, without the right kinds of instruction, young children tend to want to change many things at once, rather than testing individual factors or variables of a causal system in isolation. One reason for this preference, identified by Kuhn, Black, Keselman, and Kaplan ( 2000 ), is that children often have not developed a metastrategic understanding of why controlling variables works and what different inferences are warranted by conducting a confounded versus a controlled experiment. Interestingly, recent analyses show that the control of variables is an effective, even optimal (in the OED sense) strategy, only given particular assumptions about the causal structure of the environment (Coenen, Bramley, Ruggeri, & Gureckis, 2017 ).
A related example stems from work on children’s causal reasoning. Bonawitz et al., ( 2010 ) presented young toddlers, preschoolers, and adults with a sequence of two events (first a block contacted a base of an object and then a toy connected to the base started spinning). The question was whether participants subsequently generated an intervention (moving the block to the base) to test if this event was causally related to the second one (i.e., the spinning toy). Unlike preschoolers and adults, toddlers did not perform this hypothesis test spontaneously, although they did come to anticipate the second event from the first. To successfully generate actions they required additional cues, like causal language used by the experimenter, or seeing direct contact between two objects (here, the two toys not separated by the base). The authors hypothesize that this failure to generate spontaneous interventions might be due to young children’s inability to recognize the relationship between prediction and causality, unless they are explicitly told or shown.
In sum, while the previous section provided evidence that seems to support the idea that children identify and explore in systematic ways, claims about the “child as intuitive scientist” remain complicated by the evidence that children struggle learning generalizable strategies of acquiring information that are most akin to the actual practice of science (e.g., control of variables). The question of how kids get from the well documented motivations and abilities that emerge in early childhood to the more complex abilities of older children, adults, and scientists remains an important contradiction in the field and is an important area for future work. This is particularly challenging because it is not clear what, in terms of computational components, actually fails when children do not show mastery of the control of variables. One hint is that it is sometimes easier for children to acquire the control of variables strategy for a particular domain or task than it is to identify how to properly transfer that strategy to a new domain or task. This suggest that aspects of problem solving and transfer may be relevant parts of the answer (Gick and Holyoak, 1983 ; Catrambone & Holyoak, 1989 ). In addition, the two examples described here point out that some type of metaknowledge about the value and purpose of “fair tests” is an important precursor for being able to reliably implement such strategies. As mentioned above, these issues currently fall somewhat outside the OED framework which deals primarily with information action selection within a defined goal and framework.
Children’s questions
The view of the child as an optimal (i.e., OED) scientist is further complicated by the literature on children’s question asking. As described in detail in Question 2, asking interesting and information questions using language is important over the course of cognitive development. Children are notorious question askers, and even young children seem to acquire question-like utterances within the first few entries in their vocabulary (e.g., “Eh?” or “Doh?” to mean “What is that?”) (Nelson, 1973 ). It has been hypothesized that these pseudo-words aid in the development of language acquisition by coordinating information requests between the child and caregiver.
However, it is unclear if children’s questions reflect any particular sense of optimality (Rothe et al., 2018 ). Part of the reason is that most of the education research on question asking in classrooms has focused on qualitative distinctions between good and bad questions (see Graesser et al., 1993 ; Graesser & Person, 1994 ; Chin & Brown, 2002 ). For example, studies might observe the types of questions students ask in a lecture or while reading some text as “deep” (e.g., why, why not, how, what-if, what-if-not) in contrast with “shallow” questions (e.g., who, what, when, where). Interestingly, the proportion of deep questions asked in a class correlate with students’ exam scores (see Graesser & Person, 1994 ). Such classification schemes are useful starting places but do not yet allow us to assess if this behavior is reflective of specific OED principles.
To that end, more controlled experimental tasks have shown robust developmental changes in children’s question asking behavior. One classic finding is that younger children (e.g., 7 to 8 years old) often use less efficient question-asking strategies while playing a “20 questions”/”Guess who?” game compared to older children (e.g., 9 to 11 years old) and adults (Mosher & Hornsby, 1966 ; Ruggeri & Lombrozo, 2015 ). Younger children have been shown to use very specific question asking strategies (e.g., “Is it Bill?” “Is it Sally?”) that potentially rule out one particular hypothesis at a time (sometimes called hypothesis-scanning questions). In contrast, older children and adults ask constraint-seeking question that can more effectively narrow down the hypothesis space (e.g., “Is your person wearing glasses?”, “Is your person a man?”). This suggests that designing sophisticated testing strategies that pertain to multiple hypotheses is another skill that develops over time. Whether this is due to limitations or changes in working memory capacity, informational goals, or beliefs about the value of evidence is still an open question.
At least some recent work has attempted to better understand these patterns. For example, Ruggeri, Lombrozo, Griffiths, and Xu ( 2015 ) found a developmental trend in the degree to which children’s questions matched the predictions of an OED models based on EIG. However, they explain that the apparent inefficiency in young children’s questions stems from younger children adopting inappropriate stopping rules (asking questions after they have already determined the correct answer, see Question 8 above). In addition, recent work that has attempted to unpack the contribution to various component cognitive processes to this ability (e.g., isolating the ability to ask questions from the need to update beliefs on the basis of the answers) has found a complex relationship between these issues even among young learners. For example, forcing children to explicitly update their hypothesis space with each new piece of evidence actually led them to ask more optimal questions than a condition where a computer interface tracked the evidence for them (which the authors interpret as a type of ”desirable difficulty” during learning, Kachergis, Rhodes, & Gureckis, 2017 ).
The studies reviewed in this section give a nuanced view of the development of inquiry skills. In some cases, even very young children seem remarkably successful at identifying opportunities for learning. However, it is also clear that children show difficulty in many places where they might be expected to succeed (e.g., in learning scientific inquiry skill directly, or in formulating informative questions). To better understand children’s inquiry behavior, more work is needed to unpack the individual components that contribute to it, such as children’s theories about the world, their cognitive capacities, and their understanding of their own actions as means to test theories.
Final thoughts
Our review poses the following question: Are we asking the right questions about human inquiry? Our synthesis offers two summary insights. First, the OED hypothesis has contributed a great deal of theoretical structure to the topic of human inquiry. Qualitative theories have been superseded by principled (and often parameter-free) models that often explain human behavior in some detail. OED models have been successful at providing explanations at different levels of processing including neural, perceptual and higher-level. Human inquiry is a very rich and open ended type of behavior, so the success of the theoretical framework across so many tasks or situations is remarkable. However, at the same time OED has rather severely limited the focus of research on human inquiry. Of course, constraining research questions and methods is a necessary (and desirable) function of a(ny) cognitive model or scientific paradigm, so we do not claim that finding limitations of OED constitutes a ground-breaking contribution in and of itself. However, being aware of how current theories constrain our thinking and critically reflecting on their merits is invaluable for the long-term progress of our field. In this respect we hopefully convinced at least some readers that the OED theories suffer from a number of particularly troubling blind spots. Some of the hardest questions about human inquiry, including the motivational impetus to acquire information about particular phenomena, are hard to accommodate within OED formalisms. Furthermore, the richer set of situations in which inquiry proceeds (e.g., natural language question asking) remain important gaps in our current understanding. These gaps matter because there is not currently a plausible way to account for these behaviors within the bounds of the OED framework and in many cases it is doubtful that there ever will be. In addition, these topics are exactly the situations that are most interesting to other aligned fields where inquiry is a basic concern. Perhaps the best illustration of the continued disconnect is the fact that the OED hypothesis has become a widely adopted and popular approach to study learning, but has had little or no impact on current thinking in education. Papers about OED models are almost never published in education journals. Certainly some elements of this can be chalked up to the different roles that formal models play in different fields. However, it also must be acknowledged that it still is difficult to apply OED models outside of the carefully constructed experimental contexts studied by psychologists.
The nine questions laid out in this paper hopefully offer a way forward. We have attempted to highlight what we see as the most exciting, difficult, and under-explored questions about human inquiry. As we suggest throughout this paper, answering these questions will likely require a number of different experimental paradigms and modeling approaches, many of which do not follow the classic structure of OED studies. Our hope is that there are enough ideas presented here that a graduate student might build a thesis around any one of the topics raised. Before concluding, we believe it is worthwhile to consider how answers to our questions could lead to progress in a number of domains beyond basic cognitive science.
One contribution of this article is to elucidate the set of constraints and prerequisites that surround people’s ability to effectively learn from self-directed inquiry and exploration. We argued that a solid understanding of these constraints and their developmental trajectory, as well as, ultimately, the development of computational models that incorporate these constraints will help apply cognitive science within educational contexts. What are some insights of future work that could benefit educational practices?
Take as an example the first question we raise in this paper, which challenges the assumption that people can represent all possible hypotheses about some learning domain. We suggested that future work should develop models of hypothesis generation that take into account constraints of the learner, for instance in terms of their memory processes or cognitive resources. Progress in this area could be directly applicable to the development of adaptive learning systems, which are growing in popularity both in schools (e.g., U.S. Department of Education, 2017 ) and as part of online learning tools that are used by the broader population. The success of adaptive learning systems crucially relies on being able to predict what information would be most useful to a user (e.g., what materials to train, re-train, and test them on). This, in turn, requires an accurate representation of their current hypothesis space. Integrating process-level theories of memory and resource constraints into models of hypothesis generation could thus lead to significant improvement of these technologies.
Another important line of research we highlight in this paper concerns the relationship between active learning and passive learning (e.g., in the discussion of the “ultimate sampling dilemma” in Question 8). We point out that the two modes of learning yield different benefits and thus work best in different situations, depending on the context and current knowledge of the learner. We hope that future work will develop models that can determine mixtures of those two modes of learning that optimize learning success in particular subject areas. Insights from these models could be used, for example, to design educational interventions in subjects that rely on combinations of teaching and experimentation (like many physical and life sciences).
Machine intelligence
OED computations already play an important role in the field of machine learning, where they are often used to design so-called active learning algorithms (Settles, 2010 ). Active learning is used to select particular unlabeled items (e.g., images, text, or speech) and have them labeled by a (human) oracle with the goal of improving classification of future items. We have discussed how human active learning can far exceed this particular situation, for example with a breadth of different query types and strategies that preserve computational tractability of even complex queries. Some types of queries aim to test concrete hypotheses (these are the “classic” OED questions), some seek out relevant meta-knowledge (feature queries), some address a particular knowledge gap, and some merely follow shared conventions (asking “How are you?”). Building a computational “repertoire” of these different query types could be especially valuable for the development of conversational machine intelligence, like chatbots and digital assistants, that can ask and answer questions in conversation with a human. Currently, these technologies tend to be limited to fairly narrow domains, beyond which they are unable to respond adequately to users’ questions. Over the past few years, Machine Learning researchers have started to develop models that generate or answer a broader array of questions, specifically about images (e.g., Jain, Zhang, & Schwing, 2017 ; Ren, Kiros, & Zemel, 2015 ). However, these algorithms work by training on large datasets of question-image pairs, and have no way of taking into account the context of any given conversation or features of the user (e.g., their current goal). Psychologically-inspired models that can adapt to changes in the subject, context, and goals of the conversation partner would thus be enormously helpful in making these tools more flexible and realistic.
Another point we raised above is the importance of pragmatics in question asking. To be helpful to one’s human counterpart and to draw the right conclusions from their answers requires at least a basic model of their knowledge and expectations, as well as the context of the conversation (e.g., is this polite small talk, or does this person want me to teach them something?). Recent work on human-robot interaction has demonstrated just how important it is that people perceive robots, with whom they collaborate on a joint task, as adapting to their actions (Fisac et al., 2016 ). It showed, for example, that a robot that acts optimally with respect to the task can be immensely frustrating to their human “partner” if the partner’s strategy happens to be suboptimal. Computational models of how humans interpret each other’s questions in a given context could be used to improve artificial agents in their ability to account for their conversation partner’s goals and constraints when answering and generating questions.
Experimental methods
What are the ramifications of our discussion for experimental methods used within psychology? We hope that the work we reviewed provides yet another set of examples for why it is informative to study people actively seeking information. Although this view is not new and has gained momentum over the past years, the vast majority of learning experiments still rely on paradigms in which subjects passively observe a sequence of stimuli preselected by the experimenter (Gureckis & Markant, 2012 ). This approach is desirable because it gives us experimental control over the information presented to participants, but it lacks one of the most crucial components of real-world learning, that is, the ability to change our environment, ask questions, and explore the world around us. Through the development of sophisticated modeling techniques, many of which are highlighted in this paper, researchers are now developing research methodologies that exploit the lack of experimental control, instead of sacrificing validity because of it. Beyond the OED framework, we have for example pointed to models of pragmatic reasoning, sequential sampling, tree search, or optimal stopping. All of these can provide windows into different aspects of inquiry and, taken together, we believe they make giving up some experimental control worthwhile.
Note that we use the term situation-specific to include both external and internal costs
However, Hoch (personal communication) reports no evidence of developmental trends in goal directed walking with age or experience within the age ranges her research has considered. Cole, Robinson, and Adolph ( 2016 ) found similar rates of goal-directed exploration in 13-month-old (novice walkers) and 19-month old (experienced walker) infants.
Anderson, J. R. (1990) The adaptive character of thought . Hillsdale: Erlbaum.
Google Scholar
Anderson, J. R. (1991). The adaptive nature of human categorization. Psychological Review , 98 (3), 409–429.
Atkinson, R. C. (1972). Optimizing the learning of a second-language vocabulary. Journal of Experimental Psychology , 96 (1), 124–129.
Austerweil, J., & Griffiths, T. (2011). Seeking confirmation is rational for deterministic hypotheses. Cognitive Science , 35 , 499–526.
Bachman, P., Sordoni, A., & Trischler, A. (2017). Towards information-seeking agents. In Iclr . arXiv: 1612.02605
Baron, J., Beattie, J., & Hershey, J. C. (1988). Heuristics and biases in diagnostic reasoning: Ii. congruence, information, and certainty. Organizational Behavior and Human Decision Processes , 42 (1), 88–110.
Baron, J., & Hershey, J. C. (1988). Outcome bias in decision evaluation. Journal of Personality and Social Psychology , 54 (4), 569–579.
PubMed Google Scholar
Bartlett, F. C., & Burt, C. (1933). Remembering: A study in experimental and social psychology. British Journal of Educational Psychology , 3 (2), 187–192.
Battaglia, P., Hamrick, J., & Tenenbaum, J. (2013). Simulation as an engine of physical scene understanding. Proceedings of the National Academy of Sciences , 110 (45), 18327–18332.
Bayes, T. (1763). An essay towards solving a problem in the doctrine of chance. Philosophical Transactions of the Royal Society of London , 53 , 370–418.
Berge, C. (1971) Principles of combinatorics . San Diego: Academic Press.
Berlyne, D. E. (1966). Curiosity and exploration. Science , 153 (3731), 25–33.
Blanchard, T. C., Hayden, B. Y., & Bromberg-Martin, E. S. (2015). Orbitofrontal cortex uses distinct codes for different choice attributes in decisions motivated by curiosity. Neuron , 85 (3), 602–614.
PubMed PubMed Central Google Scholar
Blum, A. L., & Langley, P. (1997). Selection of relevant features and examples in machine learning. Artificial Intelligence , 97 (1), 245–271.
Bonawitz, E. B., Ferranti, D., Saxe, R., Gopnik, A., Meltzoff, A. N., Woodward, J., & Schulz, L. (2010). Just do it? Investigating the gap between prediction and action in toddlers causal inferences. Cognition , 115 (1), 104–117.
Bonawitz, E. B., Shafto, P., Gweon, H., Goodman, N. D., Spelke, E., & Schulz, L. (2011). The double-edged sword of pedagogy: Instruction limits spontaneous exploration and discovery. Cognition , 120 (3), 322–330.
Bonawitz, E. B., van Schijndel, T. J., Friel, D., & Schulz, L. (2012). Children balance theories and evidence in exploration, explanation, and learning. Cognitive Psychology , 64 (4), 215–234.
Bonawitz, E. B., Denison, S., Gopnik, A., & Griffiths, T. L. (2014). Win-stay, Lose-Sample: A simple sequential algorithm for approximating Bayesian inference. Cognitive Psychology , 74 , 35–65.
Bonawitz, E. B., Denison, S., Griffiths, T. L., & Gopnik, A. (2014). Probabilistic models, learning algorithms, and response variability: sampling in cognitive development. Trends in Cognitive Sciences , 18 (10), 497–500.
Borji, A., & Itti, L. (2013). State-of-the-art in visual attention modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence , 35 (1), 185–207.
Botvinick, M. M., Niv, Y., & Barto, A. C. (2009). Hierarchically organized behavior and its neural foundations: A reinforcement learning perspective. Cognition , 113 (3), 262–280.
Bramley, N. R., Dayan, P., & Lagnado, D. A. (2015). Staying afloat on neuraths boat–heuristics for sequential causal learning. In D. C. Noelle, R. Dale, A. S. Warlaumont, J. Yoshimi, T. Matlock, C. D. Jennings, & P. P. Maglio (Eds.) Proceedings of the 37th annual conference of the Cognitive Science Society (pp. 262–267) .
Bramley, N. R., Gerstenberg, T., & Tenenbaum, J. B. (2016). Natural science: Active learning in dynamic physical microworlds. In A. Papafragou, D. Grodner, D. Mirman, & J. C. Trueswell (Eds.) Proceedings of the 38th annual meeting of the Cognitive Science Society (pp. 2567–2572) . Austin.
Bramley, N. R., Lagnado, D., & Speekenbrink, M. (2015). Conservative forgetful scholars - how people learn causal structure through sequences of interventions. Journal of Experimental Psychology: Learning, Memory, and Cognition , 41 (3), 708–731.
Bromberg-Martin, E. S., & Hikosaka, O. (2011). Lateral habenula neurons signal errors in the prediction of reward information. Nature Neuroscience , 14 (9), 1209–1216.
Brown, S. D., & Steyvers, M. (2009). Detecting and predicting changes. Cognitive Psychology , 58 (1), 49–67.
Buchsbaum, D., Bridgers, S., Skolnick-Weisberg, D., & Gopnik, A. (2012). The power of possibility: Causal learning, counterfactual reasoning, and pretend play. Philosophical Transactions of the Royal Society of London , 367 (1599), 2202–2212.
Cakmak, M., & Thomaz, A. L. (2012). Designing robot learners that ask good questions. In Proceedings of the seventh annual ACM/IEEE international conference on human–robot interaction (pp. 17–24) .
Carey, S., & Spelke, E. (1996). Science and core knowledge. Philosophy of Science , 63 (4), 515–533.
Case, R. (1974). Structures and strictures: Some functional limitations on the course of cognitive growth. Cognitive Psychology , 6 (4), 544–574.
Castro, R., Kalish, C., Nowak, R., Qian, R., Rogers, T., & Zhu, X. (2008) Human active learning. Advances in neural information processing systems Vol. 21. Cambridge: MIT Press.
Catrambone, R., & Holyoak, K. (1989). Overcoming contextual limitations on problem-solving transfer. Journal of Experimental Psychology: Learning, Memory, and Cognition , 15 (6), 1147–1156.
Cavagnaro, D. R., Myung, J. I., Pitt, M. A., & Kujala, J. V. (2010). Adaptive design optimization: A mutual information-based approach to model discrimination in cognitive science. Neural Computation , 22 (4), 887–905.
Cavagnaro, D. R., Aranovich, G. J., Mcclure, S. M., Pitt, M. A., & Myung, J. I. (2014). On the functional form of temporal discounting: An optimized adaptive test. Journal of Risk and Uncertainty , 52 (3), 233–254.
Chater, N., Crocker, M., & Pickering, M. (1998). The rational analysis of inquiry: The case of parsing. In M. Oaskford, & N. Chater (Eds.) Rational models of cognition (pp. 441–468) . Oxford: University Press.
Chater, N., & Loewenstein, G. (2015). The under-appreciated drive for sense-making. Journal of Economic Behavior & Organization , 15 (6), 1147–1156.
Chen, Z., & Klahr, D. (1999). All other things being equal: Acquisition and transfer of the control of variables strategy. Child Development , 70 (5), 1098–1120.
Chen, S. Y., Ross, B. H., & Murphy, G. L. (2014). Implicit and explicit processes in category-based induction: Is induction best when we don’t think? Journal of Experimental Psychology: General , 143 (1), 227–246.
Chin, C., & Brown, D. E. (2002). Student-generated questions: A meaningful aspect of learning in science. International Journal of Science Education , 24 (5), 521–549.
Christie, S., & Genter, D. (2010). Where hypotheses come from: Learning new relations by structural alignment. Journal of Cognition and Development , 11 , 356–373.
Coenen, A., Bramley, N. R., Ruggeri, A., & Gureckis, T. M. (2017). Beliefs about sparsity affect causal experimentation. In G. Gunzelmann, A. Howes, T. Tenbrink, & E. Davelaar (Eds.) Proceedings of the 39th annual conference of the Cognitive Science Society (pp. 1788–1793) . Austin.
Coenen, A., & Gureckis, T. M. (2015). Are biases when making causal interventions related to biases in belief updating? In R. D. Noelle, A. S. Warlaumont, J. Yoshimi, T. Matlock, C. D. Jennings, & P. P. Maglio (Eds.) Proceedings of the 37th annual conference of the Cognitive Science Society (pp. 411–416) . Austin: Cognitive Science Society.
Coenen, A., Rehder, B., & Gureckis, T. M. (2015). Strategies to intervene on causal systems are adaptively selected. Cognitive Psychology , 79 , 102–133.
Cole, W., Robinson, S., & Adolph, K. (2016). Bouts of steps: The organization of infant exploration. Developmental Psychobiology , 58 , 341–354.
Cook, C., Goodman, N. D., & Schulz, L. (2011). Where science starts: Spontaneous experiments in preschoolers exploratory play. Cognition , 120 (3), 341–349.
Courville, A. C., & Daw, N. D. (2007). The rat as particle filter. In Advances in neural information processing systems (pp. 369– 376) .
Crupi, V., & Tentori, K. (2014). State of the field: Measuring information and confirmation. Studies in History and Philosophy of Science , 47 , 81–90.
Crupi, V., Nelson, J., Meder, B., Cevolani, G., & Tentori, K. (2018). Generalized information theory meets human cognition: Introducing a unified framework to model uncertainty and information search. Cognitive Science , 42 (5), 1410–1456.
Denison, S., Bonawitz, E., Gopnik, A., & Griffiths, T. L. (2013). Rational variability in children’s causal inferences: The sampling hypothesis. Cognition , 126 (2), 285–300.
Denrell, J., & March, J. G. (2001). Adaptation as information restriction: The hot stove effect. Organization Science , 12 (5), 523–538.
Denrell, J., & Le Mens, G. (2007). Interdependent sampling and social influence. Psychological Review , 114 (2), 398–422.
Doherty, M. E., Mynatt, C. R., Tweney, R. D., & Schiavo, M. D. (1979). Pseudodiagnosticity. Acta Psychologica , 43 (2), 111–121.
Dougherty, M. R. P., & Hunter, J. (2003a). Probability judgment and subadditivity: The role of working memory capacity and constraining retrieval. Memory & Cognition , 31 (6), 968–982. https://doi.org/10.3758/BF03196449
Dougherty, M. R. P., & Hunter, J. E. (2003b). Hypothesis generation, probability judgment, and individual differences in working memory capacity. Acta Psychologica , 113 (3), 263–282. https://doi.org/10.1016/S0001-6918(03)00033-7
Dougherty, M. R. P., Thomas, R., & Lange, N. (2010). Toward an integrative theory of hypothesis generation, probability judgment, and hypothesis testing. Psychology of Learning and Motivation , 52 , 299–342.
Edwards, W. (1965). Optimal strategies for seeking information: Models for statistics, choice reaction times, and human information processing. Journal of Mathematical Psychology , 2 (2), 312–329.
Edwards, W. (1968). Conservatism in human information processing. In B. Kleinmuntz (Ed.) Formal Representation of Human Judgment (pp. 17–51) . New York: Wiley.
Elmore, J. G., Barton, M. B., Moceri, V. M., Polk, S., Arena, P. J., & Fletcher, S. W. (1998). Ten-year risk of false positive screening mammograms and clinical breast examinations. New England Journal of Medicine , 338 (16), 1089–1096.
Fedorov, V. V. (1972). Theory of optimal experiments. New York: Academic Press.
Ferguson, T. S. (1989). Who solved the secretary problem? Statistical Science , 4 (3), 282–289.
Ferguson, T. S. (2012). Optimal stopping and applications. Electronic Text. https://www.math.ucla.edu/~tom/Stopping/Contents.html
Fernbach, P. M., Darlow, A., & Sloman, S. A. (2010). Neglect of alternative causes in predictive but not diagnostic reasoning. Psychological Science , 21 (3), 329–336.
Fernbach, P. M., Darlow, A., & Sloman, S. A. (2011). When good evidence goes bad: The weak evidence effect in judgment and decision-making. Cognition , 119 (3), 459–467.
Fisac, J. F., Liu, C., Hamrick, J. B., Sastry, S., Hedrick, J. K., Griffiths, T. L., & Dragan, A. D. (2016). Generating plans that predict themselves. In Proceedings of WAFR .
Frank, M. C., & Goodman, N. D. (2012). Predicting pragmatic reasoning in language games. Science , 336 (6084), 998–998.
Franke, M., & Degen, J. (2016). Reasoning in reference games: Individual-vs. population-level probabilistic modeling. PloS one , 11 (5), e0154854.
Friston, K. (2009). The free-energy principle: A rough guide to the brain?. Trends in Cognitive Sciences , 13 (7), 293–301.
Friston, K., Rigoli, F., Ognibene, D., Mathys, C., Fitzgerald, T., & Pezzulo, G. (2015). Active inference and epistemic value. Cognitive Neuroscience , 6 (4), 187–214.
Friston, K., FitzGerald, T., Rigoli, F., Schwartenbeck, P., & Pezzulo, G. (2017). Active inference: A process theory. Neural Computation , 29 (1), 1–49.
Gershman, S., Vul, E., & Tenenbaum, J. B. (2012). Multistability and perceptual inference. Neural Computation , 24 (1), 1–24.
Gershman, S., & Daw, N. (2017). Reinforcement learning and episodic memory in humans and animals: An integrative framework. Annual Review of Psychology , 68 , 1–28.
Gick, M., & Holyoak, K. (1983). Schema induction and analogical transfer. Cognitive Psychology , 15 (1), 1–38.
Gigerenzer, G., Mata, J., & Frank, R. (2009). Public knowledge of benefits of breast and prostate cancer screening in Europe. Journal of the National Cancer Institute , 101 (17), 1216–1220.
Ginsberg, M., & Smith, D. (1988). Reasoning about action I: A possible worlds approach. Artificial Intelligence , 35 (2), 165–195.
Good, I. J. (1950) Probability and the weighting of evidence . New York: Charles Griffin.
Goodman, N. D., & Stuhlmüller, A. (2013). Knowledge and implicature: Modeling language understanding as social cognition. Topics in Cognitive Science , 5 (1), 173–184.
Goodman, N. D., Frank, M., Griffiths, T., & Tenenbaum, J. (2015). Relevant and robust. A response to Marcus and Davis. Psychological Science , 26 (4), 539–541.
Goodman, N. D., & Frank, M. C. (2016). Pragmatic language interpretation as probabilistic inference. Trends in Cognitive Sciences , 20 (11), 818–829.
Gopnik, A. (1996). The scientist as child. Philosophy of Science , 63 (4), 485–514.
Gopnik, A., Glymour, C., Sobel, D. M., Schulz, L., Kushnir, T., & Danks, D. (2004). A theory of causal learning in children: Causal maps and Bayes nets. Psychological Review , 111 (1), 3–32.
Gopnik, A. (2009). The philosophical baby: What children’s minds tell us about truth, love & the meaning of life. Random House.
Gopnik, A. (2012). Scientific thinking in young children: Theoretical advances, empirical research, and policy implications. Science , 337 (6102), 1623–1627.
Gopnik, A., & Wellman, H. M. (2012). Reconstructing constructivism: Causal models, Bayesian learning mechanisms, and the theory. Psychological Bulletin , 138 (6), 1085–1108.
Gopnik, A., Griffiths, T., & Lucas, C. (2015). When younger learners can be better (or at least more open-minded) than older ones. Current Directions in Psychological Science , 24 (2), 87–92.
Gottlieb, J. (2012). Attention, learning, and the value of information. Neuron , 76 (2), 281–295.
Gottlieb, J., Oudeyer, P. Y., Lopes, M., & Baranes, A. (2013). Information-seeking, curiosity, and attention: Computational and neural mechanisms. Trends in Cognitive Sciences , 17 (11), 585–593.
Graesser, A., Langston, M., & Bagget, W. (1993). Exploring information about concepts by asking questions. In G. Nakamura, R. Taraban, & D. Medin (Eds.) The psychology of learning and motivation: Categorization by humans and machines (Vol. 29, pp. 411–436). Academic Press.
Graesser, A., & Person, N. K. (1994). Question asking during tutoring. American Educational Research Journal , 31 (1), 104–137.
Gregg, L. W., & Simon, H. A. (1967). Process models and stochastic theories of simple concept formation. Journal of Mathematical Psychology , 4 (2), 246–276.
Grice, H. P. (1975). Logic and Conversation. Syntax and Semantics , 3, 41–58.
Griffiths, T. L., & Tenenbaum, J. B. (2006). Optimal predictions in everyday cognition. Psychological Science , 17 (9), 767–773.
Griffiths, T. L., Chater, N., Kemp, C., Perfors, A., & Tenenbaum, J. B. (2010). Probabilistic models of cognition: Exploring representations and inductive biases. Trends in Cognitive Sciences , 14 , 357–364.
Gruber, M. J., Gelman, B. D., & Ranganath, C. (2014). States of curiosity modulate hippocampus-dependent learning via the dopaminergic circuit. Neuron , 84 (2), 486–496.
Guez, A., Silver, D., & Dayan, P. (2012). Efficient Bayes-adaptive reinforcement learning using sample-based search. In Advances in neural information processing systems (pp. 1025–1033) .
Gureckis, T. M., & Love, B. C. (2003). Human unsupervised and supervised learning as a quantitative distinction. International Journal of Pattern Recognition and Artificial Intelligence , 17 , 885–901.
Gureckis, T. M., & Markant, D. B. (2009). Active learning strategies in a spatial concept learning game. In Proceedings of the 31st annual conference of the Cognitive Science Society (pp. 3145–3150) . Austin.
Gureckis, T. M., & Markant, D. B. (2012). Self-directed learning a cognitive and computational perspective. Perspectives on Psychological Science , 7 (5), 464–481.
Gweon, H., Tenenbaum, J. B., & Schulz, L. (2010). Infants consider both the sample and the sampling process in inductive generalization. Proceedings of the National Academy of Sciences , 107 (20), 9066–9071.
Gweon, H., Palton, H., Konopka, J., & Schulz, L. (2014). Sins of omission: Children selectively explore when teachers are under-informative. Cognition , 132 , 335–341.
Hamrick, J., Smith, K., Griffiths, T., & Vul, E. (2015). Think again? The amount of mental simulation tracks uncertainty in the outcome. In R. D. Noelle, A. S. Warlaumont, J. Yoshimi, T. Matlock, C. D. Jennings, & P. P. Maglio (Eds.) Proceedings of the 37th annual conference of the Cognitive Science Society (pp. 866–871) .
Hawkins, R. X., Stuhlmüller, A., Degen, J., & Goodman, N. D. (2015). Why do you ask? Good questions provoke informative answers. In R. D. Noelle, A. S. Warlaumont, J. Yoshimi, J. Yoshimi, J. Yoshimi, T. Matlock, C. D. Jennings, & P. P. Maglio (Eds.) Proceedings of the 37th annual conference of the Cognitive Science Society (pp. 878–883) . Austin: Cognitive Science Society.
Hayes, B. K., Hawkins, G. E., & Newell, B. R. (2015). Consider the alternative: The effects of causal knowledge on representing and using alternative hypotheses in judgments under uncertainty. Journal of Experimental Psychology: Learning, Memory, and Cognition , 42 (5), 723–739.
Hendrickson, A. T., Navarro, D. J., & Perfors, A. (2016). Sensitivity to hypothesis size during information search. Decision , 3 (1), 62–80.
Hoch, J., O’Grady, S., & Adolph, K. (2018). It’s the journey, not the destination: Locomotor exploration in infants. Developmental Science . https://doi.org/10.1111/desc.12740
Hoch, J., Rachwani, J., & Adolph, K. E. (in review). Why do infants move? Locomotor exploration in crawling and walking infants.
Hodgins, H. S., & Zuckerman, M. (1993). Beyond selecting information: Biases in spontaneous questions and resultant conclusions . Journal of Experimental Social Psychology , 29 (5), 387–407.
Horwich, P. (1982). Probability and evidence. CUP Archive.
Huys, Q. J. M., Eshel, N., O’Nions, E., Sheridan, L., Dayan, P., & Roiser, J. P. (2012). Bonsai trees in your head: How the Pavlovian system sculpts goal-directed choices by pruning decision trees. PLoS Computational Biology , 8 (3), e1002410.
Inhelder, B., & Piaget, J. (1958) The growth of logical thinking . New York: Basic Books.
Itti, L., & Baldi, P. (2005). A principled approach to detecting surprising events in video. In 2005. IEEE computer society conference on computer vision and pattern recognition (pp. 631–637) , Vol. 1.
Itti, L., & Baldi, P. (2006). Bayesian surprise attracts human attention. In B. Weiss, J. Schoelkopf, & Platt (Eds.) Advances in Neural Information Processing Systems (pp. 547–554) , Vol. 18.
Jain, U., Zhang, Z., & Schwing, A. (2017). Creativity: Generating diverse questions using variational autoencoders. arXiv: 1704.03493
Jones, M., & Love, B. C. (2011). Bayesian fundamentalism or enlightenment? On the explanatory status and theoretical contributions of Bayesian models of cognition. Behavioral and Brain Sciences , 34 (04), 169–188.
Kachergis, G., Rhodes, M., & Gureckis, T. M. (2016). Desirable difficulties in the development of active inquiry skills. In A. Papafragou, D. Grodner, & D. Mirman (Eds.) Proceedings of the 38th annual conference of the Cognitive Science Society (pp. 2477–2482) .
Kachergis, G., Rhodes, M., & Gureckis, T. (2017). Desirable difficulties in the development of active inquiry skills. Cognition , 166 , 407–417.
Kahneman, D., & Tversky, A. (1973). On the psychology of prediction. Psychological Review , 80 (4), 237–251.
Kahneman, D., Slovic, P., & Tversky, A. (1982) Judgment under uncertainty: Heuristics and biases . Cambridge: Cambridge University Press.
Kang, M. J., Hsu, M., Krajbich, I. M., Loewenstein, G., McClure, S. M., Wang, J. T.-y., & Camerer, C. F. (2009). The wick in the candle of learning epistemic curiosity activates reward circuitry and enhances memory. Psychological Science , 20 (8), 963–973.
Kelemen, D., & Rosset, E. (2009). The human function compunction: Teleological explanation in adults. Cognition , 111 (1), 138– 142.
Kidd, C., Piantadosi, S. T., & Aslin, R. N. (2012). The Goldilocks effect: Human infants allocate attention to visual sequences that are neither too simple nor too complex. PloS one , 7 (5), e36399.
Kidd, C., Piantadosi, S. T., & Aslin, R. N. (2014). The Goldilocks effect in infant auditory attention. Child Development , 85 (5), 1795–1804.
Kidd, C., & Hayden, B. Y. (2015). The psychology and neuroscience of curiosity. Neuron , 88 (3), 449–460.
Kim, W., Pitt, M. A., Lu, Z. L., Steyvers, M., & Myung, J. I. (2014). A hierarchical adaptive approach to optimal experimental design. Neural computation. Neural Computation , 26 (11), 2465–2492.
Kirkpatrick, S., Gelatt, C., & Vecchi, M. (1983). Optimization by simulated annealing. Science , 220 , 671–680.
Klahr, D., Fay, A. L., & Dunbar, K. (1993). Heuristics for scientific experimentation: A developmental study. Cognitive Psychology , 25 (1), 111–146.
Klahr, D., & Nigam, M. (2004). The equivalence of learning paths in early science instruction effects of direct instruction and discovery learning. Psychological Science , 15 (10), 661–667.
Klayman, J., & Ha, Y.-W. (1987). Confirmation, disconfirmation, and information in hypothesis testing. Psychological Review , 94 (2), 211–218.
Klayman, J., & Ha, Y.-W. (1989). Hypothesis testing in rule discovery: strategy, structure, and content. Journal of Experimental Psychology: Learning, Memory, and Cognition , 15 (4), 596–604.
Klayman, J. (1995). Varieties of confirmation bias. Psychology of Learning and Motivation , 32 , 385–418.
Krynski, T. R., & Tenenbaum, J. B. (2007). The role of causality in judgment under uncertainty. Journal of Experimental Psychology: General , 136 (3), 430–450.
Kuhn, D., Garcia-Mila, M., Zohar, A., Andersen, C., White, S. H., Klahr, D., & Carver, S. M. (1995). Strategies of knowledge acquisition. Monographs of the Society for Research in Child Development , 60 (4), i+iii+v-vi+ 1-157.
Kuhn, D., Black, J., Keselman, A., & Kaplan, D. (2000). The development of cognitive skills to support inquiry learning. Cognition and Instruction , 18 (4), 495–523.
Kushnir, T., & Gopnik, A. (2005). Young children infer causal strength from probabilities and interventions. Psychological Science , 16 (9), 678–683.
Kushnir, T., Wellman, H. M., & Gelman, S. A. (2008). The role of preschoolers’ social understanding in evaluating the informativeness of causal interventions. Cognition , 107 (3), 1084–1092.
Lagnado, D. A., & Sloman, S. (2004). The advantage of timely intervention. Journal of Experimental Psychology: Learning, Memory, and Cognition , 30 (4), 856–876.
Legare, C. H. (2012). Exploring explanation: Explaining inconsistent evidence informs exploratory, hypothesis-testing behavior in young children. Child Development , 83 (1), 173–185.
Le Mens, G., & Denrell, J. (2011). Rational learning and information sampling: on the “naivety” assumption in sampling explanations of judgment biases. Psychological Review , 118 (2), 379–392.
Lewicki, M. S. (2002). Efficient coding of natural sounds. Nature Neuroscience , 5 (4), 356–363.
Lewis, D. (1969) Convention: a philosophical study . Cambridge: Harvard University Press.
Lieder, F., Plunkett, D., Hamrick, J. B., Russell, S. J., Hay, N., & Griffiths, T. (2014). Algorithm selection by rational metareasoning as a model of human strategy selection. In Advances in neural information processing systems (pp. 2870–2878) .
Lindley, D. V. (1956). On a measure of the information provided by an experiment. The Annals of Mathematical Statistics , 27 (4), 986– 1005.
Loewenstein, G. (1994). The psychology of curiosity: A review and reinterpretation. Psychological Bulletin , 116 (1), 75–98.
Lomasky, R., Brodley, C. E., Aernecke, M., Walt, D., & Friedl, M. (2007). Active class selection. In Machine learning: ECML 2007 (pp. 640–647) . Berlin: Springer.
Lombrozo, T., & Carey, S. (2006). Functional explanation and the function of explanation. Cognition , 99 (2), 167–204.
MacDonald, K., & Frank, M. C. (2016). When does passive learning improve the effectiveness of active learning? In A. Papafragou, D. Grodner, D. Mirman, & J. Trueswell (Eds.) Proceedings of the 38th annual conference of the Cognitive Science Society (pp. 2459–2464) . Austin.
Mackay, D. (1992). Information-based objective functions for active data selection. Neural Computation , 4 , 590–604.
Malt, B. C., Ross, B. H., & Murphy, G. L. (1995). Predicting features for members of natural categories when categorization is uncertain. Journal of Experimental Psychology: Learning, Memory, and Cognition , 21 (3), 646–661.
Mandler, J. M. (2014). Stories, scripts, and scenes: Aspects of schema theory . Psychology Press.
Marcus, G. F., & Davis, E. (2013). How robust are probabilistic models of higher-level cognition? Psychological Science , 24 (12), 2351–2360.
Marewski, J. N., & Schooler, L. J. (2011). Cognitive niches: An ecological model of strategy selection. Psychological Review , 118 (3), 393–437.
Markant, D. B., & Gureckis, T. M. (2012). Does the utility of information influence sampling behavior? In N. Miyake, D. Peebles, & R. P. Cooper (Eds.) Proceedings of the 34th annual conference of the Cognitive Science Society (pp. 719–724) . Austin.
Markant, D. B., & Gureckis, T. M. (2014). Is it better to select or to receive? Learning via active and passive hypothesis testing. Journal of Experimental Psychology-General , 143 (1), 94–122.
Markant, D. B., Settles, B., & Gureckis, T. M. (2015). Self-directed learning favors local, rather than global, uncertainty. Cognitive Science , 40 (1), 100–120.
Markant, D. B. (2016). The impact of biased hypothesis generation on self-directed learning. In A. Papafragou, D. Grodner, D. Mirman, & J. Trueswell (Eds.) Proceedings of the 38th annual conference of the Cognitive Science Society (pp. 444–449) . Austin: Cognitive Science Society.
Marvin, C., & Shohamy, D. (2016). Curiosity and reward: Valence predicts choice and information prediction errors enhance learning. Journal of Experimental Psychology: General , 145 (3), 266–272.
McCormack, T., Bramley, N. R., Frosch, C., Patrick, F., & Lagnado, D. (2016). Children’s use of interventions to learn causal structure. Journal of Experimental Child Psychology , 141 , 1–22.
McKenzie, C. R., Ferreira, V. S., Mikkelsen, L. A., McDermott, K. J., & Skrable, R. P. (2001). Do conditional hypotheses target rare events? Organizational Behavior and Human Decision Processes , 85 (2), 291–309.
Meder, B., & Nelson, J. D. (2012). Information search with situation-specific reward functions. Judgment and Decision Making , 7 (2), 119–148.
Meltzoff, A. N. (1995). Understanding the intentions of others: Re-enactment of intended acts by 18-month-old children. Developmental Psychology , 31 (5), 838–850 .
Metcalfe, J., & Kornell, N. (2003). The dynamics of learning and allocation of study time to a region of proximal learning. Journal of Experimental Psychology: General , 132 (4), 530–542.
Minsky, M. (1974). A framework for representing knowledge. MIT-AI Laboratory Memo 306.
Miyake, N., & Norman, D. (1979). To ask a question one must know enough to know what is not known. Journal of Verbal Learning and Verbal Behavior , 18 , 357–364.
Montessori, M. (1912) The Montessori method . New York: Schocken.
Mosher, F. A., & Hornsby, J. R. (1966) Studies in cognitive growth . New York: Wiley.
Mozer, M., Pashler, H., & Homaei, H. (2008). Optimal predictions in everyday cognition: The wisdom of individuals or crowds? Cognitive Science , 32 (7), 1133–1147.
Muliere, P., & Parmigiani, G. (1993). Utility and means in the 1930s. Statistical Science , 8 (4), 421–432.
Murphy, K. P. (2001) Active learning of causal Bayes net structure . U.C. Berkeley: Technical Report, Department of Computer Science.
Murphy, G. L., Chen, S. Y., & Ross, B. H. (2012). Reasoning with uncertain categories. Thinking & Reasoning , 18 (1), 81–117.
Myung, J. I., & Pitt, M. A. (2009). Optimal experimental design for model discrimination. Psychological Review , 116 (3), 499–518.
Najemnik, J., & Geisler, W. S. (2009). Simple summation rule for optimal fixation selection in visual search. Vision Research , 49 , 1286–1294.
Najemnik, J., & Geisler, W. S. (2005). Optimal eye movement strategies in visual search. Nature , 434 (7031), 387–391.
Navarro, D. J., & Perfors, A. F. (2011). Hypothesis generation, sparse categories, and the positive test strategy. Psychological Review , 118 (1), 120–134.
Nelson, K. (1973). Structure and strategy in learning to talk. Monographs of the Society for Research in Child Development , 38 (1-2, Serial No. 149), 1–135.
Nelson, J. D., Tenenbaum, J. B., & Movellan, J. R. (2001). Active inference in concept learning. In J. D. Moore, & K. Stenning (Eds.) Proceedings of the 23rd conference of the Cognitive Science Society (pp. 692–697) . Austin.
Nelson, J. D. (2005). Finding useful questions: On Bayesian diagnosticity, probability, impact, and information gain. Psychological Review , 112 (4), 979–999.
Nelson, J. D., McKenzie, C. R., Cottrell, G. W., & Sejnowski, T. J. (2010). Experience matters: Information acquisition optimizes probability gain. Psychological Science , 21 (7), 960–969.
Nelson, J. D., Divjak, B., Gudmundsdottir, G., Martignon, L. F., & Meder, B. (2014). Children’s sequential information search is sensitive to environmental probabilities. Cognition , 130 (1), 74–80.
Nickerson, R. S. (1998). Confirmation bias: A ubiquitous phenomenon in many guises. Review of General Psychology , 2 (2), 175–220.
Nosofsky, R. M., & Palmeri, T. J. (1998). A rule-plus-exception model for classifying objects in continuous-dimension spaces. Psychonomic Bulletin & Review , 5 (3), 345–369.
Oaksford, M., & Chater, N. (1994). A rational analysis of the selection task as optimal data selection. Psychological Review , 101 (4), 608–631.
Oaksford, M., & Chater, N. (1996). Rational explanation of the selection task. Psychological Review , 103 (2), 381–391.
Oaksford, M., Chater, N., Grainger, B., & Larkin, J. (1997). Optimal data selection in the reduced array selection task (RAST). Journal of Experimental Psychology: Learning, Memory, and Cognition , 23 (2), 441–458.
O’Brien, B., & Ellsworth, P. C. (2006). Confirmation bias in criminal investigations. In 1st annual conference on empirical legal studies paper .
Otto, A. R., Raio, C. M., Chiang, A., Phelps, E. A., & Daw, N. D. (2013). Working-memory capacity protects model-based learning from stress. Proceedings of the National Academy of Sciences , 110 (52), 20941–20946.
Oudeyer, P. Y., Kaplan, F., & Hafner, V. V. (2007). Intrinsic motivation systems for autonomous mental development. IEEE Transactions on Evolutionary Computation , 11 (2), 265–286.
Oudeyer, P. Y., Gottlieb, J., & Lopes, M. (2016). Intrinsic motivation, curiosity, and learning: Theory and applications in educational technologies. Progress in Brain Research , 229 , 257–284.
Pauker, S. G., & Kassirer, J. P. (1980). The threshold approach to clinical decision making. New England Journal of Medicine , 302 , 1109–1117.
Pearl, J. (2009) Causality . Cambridge: Cambridge University Press.
Phillips, L. D., & Edwards, W. (1966). Conservatism in a simple probability inference task. Journal of Experimental Psychology , 72 (3), 346–354.
Popper, K. R. (1968). The logic of scientific discovery. Oxford: Basic Books.
Pothos, E., & Chater, N. (2005). Unsupervised categorization and category learning. The Quarterly Journal of Experimental Psychology , 58A (4), 733–752.
Rafferty, A. N., Zaharia, M., & Griffiths, T. L. (2014). Optimally designing games for behavioural research. Proceedings of the Royal Society A , 470 (2167), 20130828.
Raghavan, H., Madani, O., & Jones, R. (2006). Active learning with feedback on features and instances. The Journal of Machine Learning Research , 7 , 1655–1686.
Raiffa, H., & Schlaifer, R. O. (1961) Applied statistical decision theory . New York: Wiley.
Redgrave, P., & Gurney, K. (2006). The short-latency dopamine signal: A role in discovering novel actions?. Nature Reviews Neuroscience , 7 (12), 967–975.
Ren, M., Kiros, R., & Zemel, R. (2015). Exploring models and data for image question answering. In Advances in neural information processing systems (pp. 2953–2961).
Rich, A. S., & Gureckis, T. M. (2014). The value of approaching bad things. In P. Bello, M. Guarini, M. McShane, & B. Scassellati (Eds.) Proceedings of the 36th annual conference of the Cognitive Science Society (pp. 1281–1286) . Austin: Cognitive Science Society.
Rich, A. S., & Gureckis, T. M. (2017). Exploratory choice reflects the future value of information. Decision .
Rieskamp, J., & Otto, P. E. (2006). Ssl: A theory of how people learn to select strategies. Journal of Experimental Psychology: General , 135 (2), 207–236.
Ross, B. H., & Murphy, G. L. (1996). Category-based predictions: Influence of uncertainty and feature associations. Journal of Experimental Psychology: Learning, Memory, and Cognition , 22 (3), 736–753.
Rothe, A., Lake, B. M., & Gureckis, T. M. (2016). Asking and evaluating natural language questions. In A. Papafragou, D. Grodner, D. Mirman, & J. C. Trueswell (Eds.) Proceedings of the 38th annual conference of the Cognitive Science Society (pp. 2051–2056) . Austin: Cognitive Science Society.
Rothe, A., Lake, B., & Gureckis, T. (2018). Do people ask good questions? Computational Brain and Behavior 1, 69–89.
Ruderman, D. L. (1994). Designing receptive fields for highest fidelity. Network: Computation in Neural Systems , 5 (2), 147–155.
Ruggeri, A., & Lombrozo, T. (2015). Children adapt their questions to achieve efficient search. Cognition , 143 , 203–216.
Ruggeri, A., Lombrozo, T., Griffiths, T., & Xu, F. (2015). Children search for information as efficiently as adults, but seek additional confirmatory evidence. In D. C. Noelle, R. Dale, A. S. Warlaumont, J. Yoshimi, T. Matlock, C. D. Jennings, & P. P. Maglio (Eds.) Proceedings of the 37th annual meeting of the Cognitive Science Society (pp. 2039–2044) . Austin: Cognitive Science Society .
Rusconi, P., Marelli, M., D’Addario, M., Russo, S., & Cherubini, P. (2014). Evidence evaluation: Measure z corresponds to human utility judgments better than measure l and optimal-experimental-design models. Journal of Experimental Psychology: Learning, Memory, and Cognition , 40 (3), 703–723.
Sanborn, A. N., Griffiths, T. L., & Navarro, D. J. (2010). Rational approximations to rational models: Alternative algorithms for category learning. Psychological Review , 117 (4), 1144–1167.
Schulz, L., & Bonawitz, E. B. (2007). Serious fun: Preschoolers engage in more exploratory play when evidence is confounded. Developmental Psychology , 43 (4), 1045–1050.
Schulz, L., Gopnik, A., & Glymour, C. (2007). Preschool children learn about causal structure from conditional interventions. Developmental Science , 10 (3), 322–332.
Schulz, L., Kushnir, T., & Gopnik, A. (2007). Learning from doing: Interventions and causal inference. In A. Gopnik, & L. Schulz (Eds.) Causal learning: Psychology, philosophy, and computation . Oxford: University Press.
Schulz, L. (2012a). Finding new facts; Thinking new thoughts. Advances in Child Development and Behavior , 43 , 269–294.
Schulz, L. (2012b). The origins of inquiry: Inductive inference and exploration in early childhood. Trends in Cognitive Sciences , 16 (7), 382–389.
Schulz, L. (2015). Infants explore the unexpected. Science , 348 , 42–43.
Settles, B. (2010) Active learning literature survey . Madison: University of Wisconsin.
Shafto, P., Goodman, N. D., & Frank, M. C. (2012). Learning from others the consequences of psychological reasoning for human learning. Perspectives on Psychological Science , 7 (4), 341–351.
Shafto, P., Goodman, N. D., & Griffiths, T. L. (2014). A rational account of pedagogical reasoning: Teaching by, and learning from, examples. Cognitive Psychology , 71 , 55–89.
Shi, L., Griffiths, T., Feldman, N., & Sanborn, A. (2010). Exemplar models as a mechanism for performing Bayesian inference. Psychonomic Bulletin & Review , 17 (4), 443–464.
Siegel, M., Magin, R., Tenenbaum, J., & Schulz, L. (2014). Black boxes: Hypothesis testing via indirect perceptual evidence. In A. Papafragou, D. Grodner, D. Mirman, & J. Trueswell (Eds.) Proceedings of the 36th annual conference of the Cognitive Science Society (pp. 1425–1430) . Austin: Cognitive Science Society.
Sim, Z., Tanner, M., Alpert, N., & Xu, F. (2015). Children learn better when they select their own data. In D. C. Noelle, R. Dale, A. S. Warlaumont, J. Yoshimi, T. Matlock, C. D. Jennings, & P.P. Maglio (Eds.) Proceedings of the 37th annual meeting of the Cognitive Science Society (pp. 2194–2199) (pp. 2194–2199). Austin: Cognitive Science Society.
Simon, H. A. (1976). From substantive to procedural rationality. In 25 years of economic theory (pp. 65–86). Springer.
Singh, S. P., Barto, A. G., & Chentanez, N. (2004). Intrinsically motivated reinforcement learning (pp. 1281–1288). In NIPS , Vol. 17.
Skov, R. B., & Sherman, S. J. (1986). Information-gathering processes: Diagnosticity, hypothesis-confirmatory strategies, and perceived hypothesis confirmation. Journal of Experimental Social Psychology , 22 (2), 93–121.
Slowiaczek, L. M., Klayman, J., Sherman, S. J., & Skov, R. B. (1992). Information selection and use in hypothesis testing: What is a good question, and what is a good answer? Memory & Cognition , 20 (4), 392–405.
Spelke, E. S., & Kinzler, K. D. (2007). Core knowledge. Developmental Science , 10 (1), 89–96.
Stahl, A. E., & Feigenson, L. (2015). Observing the unexpected enhances infants learning and exploration. Science , 348 (6230), 91–94.
Steyvers, M., Tenenbaum, J. B., Wagenmakers, E. J., & Blum, B. (2003). Inferring causal networks from observations and interventions. Cognitive Science , 27 (3), 453–489.
Sutton, R. S., & Barto, A. G. (1988) Reinforcement learning: An introduction . Cambridge: MIT Press.
Tenenbaum, J. B. (1999) A bayesian framework for concept learning. Unpublished doctoral dissertation . Cambridge: MIT.
Tenenbaum, J. B., & Griffiths, T. L. (2001). Generalization, similarity, and Bayesian inference. Behavioral and Brain Sciences , 24 (04), 629–640.
Tenenbaum, J. B., Griffiths, T. L., & Kemp, C. (2006). Theory-based Bayesian models of inductive learning and reasoning. Trends in Cognitive Sciences , 10 (7), 309–318.
Thomas, R. P., Dougherty, M. R. P., Sprenger, A. M., & Harbison, J. I. (2008). Diagnostic hypothesis generation and human judgment. Psychological Review , 115 , 155–185.
Trueswell, J. C., Medina, T. N., Hafri, A., & Gleitman, L. R. (2013). Propose but verify: Fast mapping meets cross-situational word learning. Cognitive Psychology , 66 (1), 126–156.
Tschirgi, J. E. (1980). Sensible reasoning: A hypothesis about hypotheses. Child Development , 51 (1), 1–10.
Tversky, A., & Edwards, W. (1966). Information versus reward in binary choices. Journal of Experimental Psychology , 71 (5), 680–683.
Ullman, S., Vidal-Naquet, M., & Sali, E. (2002). Visual features of intermediate complexity and their use in classification. Nature Neuroscience , 5 (7), 682– 687.
U. S. Department of Education (2017). Reimagining the role of technology in education: 2017 national education technology plan update (Technical Report). Office of Educational Technology.
van Schijndel, T., Visser, I., van Bers, B., & Raijmakers, M. (2015). Preschoolers perform more informative experiments after observing theory-violating evidence. Journal of Experimental Child Psychology , 131 , 104–119.
Vul, E., Goodman, N. D., Griffiths, T. L., & Tenenbaum, J. B. (2014). One and done? Optimal decisions from very few samples. Cognitive Science , 38 (4), 599–637. https://doi.org/10.1111/cogs.12101
Article PubMed Google Scholar
Vygotsky, L. (1962) Thought and language . Cambridge: MIT Press.
Waldmann, M. R., & Hagmayer, Y. (2005). Seeing versus doing: Two modes of accessing causal knowledge. Journal of Experimental Psychology: Learning, Memory, and Cognition , 31 (2), 216–227.
Wason, P. C. (1960). On the failure to eliminate hypotheses in a conceptual task. Quarterly Journal of Experimental Psychology , 12 (3), 129–140.
Wason, P. C. (1966). Reasoning. In B., Foss. (Ed.) New horizons in psychology (pp. 135–151). Harmondsworth: Penguin Books.
Woodward, A. L. (1998). Infants selectively encode the goal object of an actor’s reach. Cognition , 69 (1), 1–34.
Xu, F., & Tenenbaum, J. B. (2007). Word learning as Bayesian inference. Psychological Review , 114 (2), 245–272.
Zhang, L., Tong, M. H., Marks, T. K., Shan, H., & Cottrell, G. W. (2008). Sun: A Bayesian framework for saliency using natural statistics. Journal of Vision , 8 (7), 32–32.
Download references
Acknowledgements
We thank Neil Bramley, Justine Hoch, Doug Markant, Greg Murphy, and Marjorie Rhodes for many helpful comments on a draft of this paper. We also thank Kylan Larson for assistance with illustrations. This work was supported by BCS-1255538 from the National Science Foundation, the John S. McDonnell Foundation Scholar Award, and a UNSW Sydney Visiting Scholar Fellow, to TMG; and by NE 1713/1-2 from the Deutsche Forschungsgemeinschaft (DFG) as part of the ”New Frameworks of Rationality” (SPP 1516) priority program, to JDN.
Author information
Authors and affiliations.
New York University, New York, NY, USA
Anna Coenen & Todd M. Gureckis
Max Planck Institute for Human Development, Berlin, Germany
Jonathan D. Nelson
University of Surrey, Guildford, UK
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Anna Coenen .
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Coenen, A., Nelson, J.D. & Gureckis, T.M. Asking the right questions about the psychology of human inquiry: Nine open challenges. Psychon Bull Rev 26 , 1548–1587 (2019). https://doi.org/10.3758/s13423-018-1470-5
Download citation
Published : 04 June 2018
Issue Date : October 2019
DOI : https://doi.org/10.3758/s13423-018-1470-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Information search
- Information gain
- Optimal experiment design
- Active learning
- Question asking
- Find a journal
- Publish with us
- Track your research
Final dates! Join the tutor2u subject teams in London for a day of exam technique and revision at the cinema. Learn more →
Reference Library
Collections
- See what's new
- All Resources
- Student Resources
- Assessment Resources
- Teaching Resources
- CPD Courses
- Livestreams
Study notes, videos, interactive activities and more!
Psychology news, insights and enrichment
Currated collections of free resources
Browse resources by topic
- All Psychology Resources
Resource Selections
Currated lists of resources
A hypothesis is a testable prediction about the variables in a study. The hypothesis should always contain the independent variable (IV) and the dependent variable (DV). A hypothesis can be directional (one-tailed) or non-directional (two-tailed).
- Share on Facebook
- Share on Twitter
- Share by Email
Example Answers for Research Methods: A Level Psychology, Paper 2, June 2019 (AQA)
Exam Support
Research Methods: MCQ Revision Test 1 for AQA A Level Psychology
Topic Videos
Example Answers for Research Methods: A Level Psychology, Paper 2, June 2018 (AQA)
Example answer for question 14 paper 2: as psychology, june 2017 (aqa), a level psychology topic quiz - research methods.
Quizzes & Activities
Our subjects
- › Criminology
- › Economics
- › Geography
- › Health & Social Care
- › Psychology
- › Sociology
- › Teaching & learning resources
- › Student revision workshops
- › Online student courses
- › CPD for teachers
- › Livestreams
- › Teaching jobs
Boston House, 214 High Street, Boston Spa, West Yorkshire, LS23 6AD Tel: 01937 848885
- › Contact us
- › Terms of use
- › Privacy & cookies
© 2002-2024 Tutor2u Limited. Company Reg no: 04489574. VAT reg no 816865400.
A-Level AQA Psychology Questions by Topic
Filter by paper, core content, 1. social influence, 3. attachment, 4 . psychopathology, 5 . approaches in psychology, 6. biopsychology, 7 . research methods, 8. issues and debates in psychology, 9. relationships, 11. cognition and development, 12. schizophrenia, 13. eating behaviour, 15. aggression, 16. forensic psychology, 17. addiction.
PSYCHOLOGY GCSE: LANG T&C - SAPIR WHORF HYPOTHESIS P1. The Study with Me Podcast
Hey guys, another episode out - woo!! So as promised, questions of the episode and answers to LAST WEEKS because I forgot to record them for this week, soz. Anyway answers here: 1. Piaget's theory refers to the idea that thought comes before language. In order to express a concept, an individual must have a schema of it. 2. Sapir Whorf 3. Schema refers to a mental structure that stores information and gets more complex with more information and experience 4. Preoperational 5. Face validity, child language development, but schemas are not possible to physically measure and so lack of scientific physical evidence, and lastly, the Sapir Whorf hypothesis opposes the theory and has more evidence to support. NOW THIS WEEKS: 1. What was the evidence to support the Sapir Whorf hypothesis? 2. What is language determinism 3. What is the weak version of the hypothesis? 4. What is a criticism of the hypothesis 5. How many words for snow did the Eskimos really have?
- More Episodes
- Malika Mamajonova
Top Podcasts In Education

How Your Brain Uses 3 Pathways to Knowledge
The scientific method is terrific, but remember intuition and experts..
Posted March 31, 2024 | Reviewed by Ray Parker
- Why Education Is Important
- Find a Child Therapist
- There are three historical methods of knowledge acquisition.
- When we ask experts, scholars, and specialists, we gain knowledge without exhausting time and energy.
- Intuition is a mysterious process that is hard to explain, but we use it, especially in creativity.
- The scientific method is fundamental for advancing scientific knowledge and gaining enlightenment.

Knowledge is power, but what happens when you are having trouble picking up new ideas? It wasn't all that long ago in human history that our access to facts, figures, and statistics was very limited. Before artificial intelligence (AI), there were search engines like Google and Bing. At first, they were available only on computers, but then the technology shrank down so small it could fit on a mobile smartphone that travels with you in a coat pocket.
Going back in time a little bit more, television, radio, and movie theaters were avant-garde. Entertainment, current events, and new ideas were spread on a mass scale using these innovations. Still, they were not interactive. You could never ask an old vacuum-tube television to pull up the funniest cat memes . Now, imagine a world in which none of these exists. For 99 percent of human existence, this was precisely the world we inhabited. Here are three ways we have acquired knowledge throughout history and that we continue to use today.
1. Appeal to Authority
How do we come to know things? Put another way, "How do we know what we know?" Here are a few questions we can answer in our modern world with just a few clicks online.
- Why is everyone born with an appendix?
- What is the emotion of embarrassment ?
- Why is our cognitive system structured the way it is?
- Why do babies seem to all follow a predictable developmental trajectory (e.g., walking, talking)?
Before the scientific revolution (and centuries before the internet), if we wanted to know the answer to questions like these, we could consult an expert, such as a religious leader , educated philosopher, naturalist, or village shaman. These authority figures would be happy to reveal truths about the way the world works.
For example, 25 percent of Americans believe the sun revolves around the Earth, according to a 2012 survey . This represents a significant shift in beliefs compared to 400 years ago when most humans believed the earth was the center of the universe and everything revolved around us. In 1543, Nicolaus Copernicus challenged the ancient teaching of the Earth as the center of the universe but was unable to convince the masses. Later, Galileo Galilei boldly advocated Copernican theory, and he was forced to retract his beliefs before an inquisition. It wasn't until 1993 that the Vatican officially recognized the validity of his work.
Note: The fact that roughly one in four Americans today believe incorrectly that the sun revolves around the earth is distressing and worthy of a separate discussion.
In the 1800s, Gregor Mendel postulated the existence of small units for transmitting genetic information even though he’d never seen them. For years, before minuscule genes were eventually seen under high-powered microscopes or astronomical black holes were observed in deep space, people could choose to accept the word of the scientists. Nonexpert laypeople had no other options. Either we trust the experts, or we just make up wild explanations on our own.
In the past, if we couldn’t see something for ourselves, we would have to accept the statements of authority figures. Even today, we still do this by talking with professionals or reading scholarly publications. Today, the internet serves as an authority, but beware, not everything on the internet can be trusted.
2. Intuition
Creative people sometimes refer to intuition or sudden insight that springs into conscious awareness as the most important step in acquiring knowledge. A person might find the solution to a problem they’ve been working on for years while simply walking down the street. There is no systematic approach to acquiring knowledge using this technique. It is a mysterious process that most people can’t explain–it just happens.
Mathematician John Nash, the focus of the 2001 movie A Beautiful Mind , introduced a stable strategy for positive outcomes among multiple players in competition . In the film, he experiences an epiphany while sitting in a pub with friends, contemplating who will succeed at gaining the attention of an attractive woman. This insight into game theory ultimately led to the Nash Equilibrium and earned him the Nobel Prize in Economics.

Many artists rely on intuition because it is compatible with creative expression. A pure artist may bristle at the thought of using mathematical formulas to generate art. After all, how can you apply an equation to make things that should be appreciated primarily for their beauty or emotional power?
When June Carter and Johnny Cash first conceived the classic tune, Ring of Fire , it did not include the signature Mexican trumpet sounds. After spending several days working on the song, Johnny Cash claims to have had a dream where he heard Mexican trumpets. He did not rely on any scientific strategies, nor did he just ask an expert how to write a great tune. Almost overnight, the song itself ascended to legendary status.
The intuitive approach looks more magical than it probably is because the ideas that seem to pop into consciousness suddenly are usually coming from minds that have spent days, if not years, on a particular subject. Neither you nor I will wake up tomorrow with the formula for cold fusion, but a physicist who spent a career studying it might. The same can be said for mathematicians, singer-songwriters, and anyone who is dedicated to the pursuit of their passions.
3. Scientific Method
The scientific method is an empirical method for acquiring knowledge that has characterized the development of science since at least the 17th century. This approach is the gold standard for generating new ideas in modern science, including psychology. It is iterative, meaning that the process often involves revisiting and refining hypotheses based on new evidence or insights gained from experimentation.
Key components of this method include observations, questions, hypotheses, predictions, experiments, and analyses. Based on these steps, scientists conclude and evaluate whether their hypothesis is supported by the evidence. There is no need for intuition, and the process is more comprehensive than simply asking an expert to tell you the answer.
The scientific method can be used to reject old but often cherished ideas when their time has come. For example, many people have long believed that one must drink eight glasses of water a day for optimal health. However, when this folk psychology was exposed to scientific scrutiny , it was found to be untrue. Individuals who drank eight glasses of water per day were no healthier than those who drank less. Thank you, Scientific Method.
Despite the various methods for acquiring knowledge, one fundamental desire remains constant across individuals: We have an unquenchable thirst for new ideas and the kind of wisdom that will make our lives easier. The challenge is finding the best path forward to achieving meaningful insight into ourselves and the world we inhabit.
©2024 Kevin Bennett PhD, all rights reserved
Bennett, K. (2018). Teaching the Monty Hall dilemma to explore decision-making, probability, and regret in behavioral science classrooms. International Journal for the Scholarship of Teaching and Learning, 12 (2), 1-7. https://doi.org/10.20429/ijsotl.2018.120213

Kevin Bennett, Ph.D., is a teaching professor of social-personality psychology at Penn State University Beaver Campus and host of Kevin Bennett Is Snarling, a podcast about danger, deception, and desire.
- Find a Therapist
- Find a Treatment Center
- Find a Support Group
- International
- New Zealand
- South Africa
- Switzerland
- Asperger's
- Bipolar Disorder
- Chronic Pain
- Eating Disorders
- Passive Aggression
- Personality
- Goal Setting
- Positive Psychology
- Stopping Smoking
- Low Sexual Desire
- Relationships
- Child Development
- Therapy Center NEW
- Diagnosis Dictionary
- Types of Therapy

Understanding what emotional intelligence looks like and the steps needed to improve it could light a path to a more emotionally adept world.
- Coronavirus Disease 2019
- Affective Forecasting
- Neuroscience
IMAGES
VIDEO
COMMENTS
What is a hypothesis and how can you write a great one for your research? A hypothesis is a tentative statement about the relationship between two or more variables that can be tested empirically. Find out how to formulate a clear, specific, and testable hypothesis with examples and tips from Verywell Mind, a trusted source of psychology and mental health information.
Examples. A research hypothesis, in its plural form "hypotheses," is a specific, testable prediction about the anticipated results of a study, established at its outset. It is a key component of the scientific method. Hypotheses connect theory to data and guide the research process towards expanding scientific understanding.
study) Describe the experiences (e.g., phenomenology) Report the stories (e.g., narrative research) Use these more exploratory verbs that are nondirectional rather than directional words that suggest quantitative research, such as "affect," "influence," "impact," "determine," "cause," and "relate.".
Experiments using sounds suggest that we are less responsive during stages 3 and 4 sleep (deep sleep) than during stages 1, 2, or REM sleep (lighter sleep). Thus, the researcher predicts that research participants will be less responsive to odors during stages 3 and 4 sleep than during the other stages of sleep.
5. Phrase your hypothesis in three ways. To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable. If a first-year student starts attending more lectures, then their exam scores will improve.
The second way is to describe one or more existing theories, derive a hypothesis from one of those theories, test the hypothesis in a new study, and finally reevaluate the theory. This format works well when there is an existing theory that addresses the research question—especially if the resulting hypothesis is surprising or conflicts with ...
The first is to raise a research question, answer that question by conducting a new study, and then offer one or more theories (usually more) to explain or interpret the results. This format works well for applied research questions and for research questions that existing theories do not address. The second way is to describe one or more ...
Theories and Hypotheses. Before describing how to develop a hypothesis it is imporant to distinguish betwee a theory and a hypothesis. A theory is a coherent explanation or interpretation of one or more phenomena.Although theories can take a variety of forms, one thing they have in common is that they go beyond the phenomena they explain by including variables, structures, processes, functions ...
In this chapter, we examine the principal types of research questions or problems, give examples of each, and review the design expectations that each type of question establishes. Then we address the complex matter of causation and raise issues that must be resolved whenever the research question involves a causal relationship. Finally, we discuss the importance of defining the terms involved ...
Hypotheses. A hypothesis (plural hypotheses) is a precise, testable statement of what the researchers predict will be the outcome of the study. This usually involves proposing a possible relationship between two variables: the independent variable (what the researcher changes) and the dependant variable (what the research measures).
INTRODUCTION. Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses.1,2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results.3,4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the ...
"A hypothesis is a conjectural statement of the relation between two or more variables". (Kerlinger, 1956) "Hypothesis is a formal statement that presents the expected relationship between an independent and dependent variable."(Creswell, 1994) "A research question is essentially a hypothesis asked in the form of a question."
(3) A Null Hypothesis: states that the IV will have no significant effect on the DV, for example, 'eating smarties will have no effect in an individuals dancing ability.' Exam Tip: One of the questions that you may get asked in the exam is 'when would a psychologist decide to use a directional hypothesis?' In general, psychologists use a directional hypothesis when there has been ...
The people who consume vitamin c have more glowing skin than the people who consume vitamin E. Hair growth is faster after the consumption of Vitamin E than vitamin K. Plants will grow faster with fertilizer X than with fertilizer Y. 6. Statistical Hypothesis Examples.
Task 1: Without knowing much about how to write a hypothesis in psychology, try and write a hypothesis for this research aim: investigating the power of uniforms in ... study would show the same results on leading questions. They asked 20 participants to watch a film of a car crash, then asked 10 of them how fast was the car travelling in MPH
Relativist social constructionism. This is a school of thought that has its roots in other disciplines, such as sociology, and began to emerge in social psychology in the 1970s. It is very different from positivism and has been a major infl uence on the growth of qualitative research methods within psychology.
Variables and Operational Definitions. Part of generating a hypothesis involves identifying the variables that you want to study and operationally defining those variables so that they can be measured. Research questions in psychology are about variables. A variable is a quantity or quality that varies across people or situations.
Olivia Guy-Evans, MSc. Research methods in psychology are systematic procedures used to observe, describe, predict, and explain behavior and mental processes. They include experiments, surveys, case studies, and naturalistic observations, ensuring data collection is objective and reliable to understand and explain psychological phenomena.
Aims and Hypotheses. Observations of events or behaviour in our surroundings provoke questions as to why they occur. In turn, one or multiple theories might attempt to explain a phenomenon, and investigations are consequently conducted to test them. One observation could be that athletes tend to perform better when they have a training partner ...
Her passion (apart from Psychology of course) is roller skating and when she is not working (or watching 'Coronation Street') she can be found busting some impressive moves on her local roller rink. Revision notes on 7.2.2 Hypothesis for the AQA A Level Psychology syllabus, written by the Psychology experts at Save My Exams.
Despite many successes, we argue that the OED hypothesis remains lacking as a theory of human inquiry and that research in the area often fails to confront some of the most interesting and important questions. In this critical review, we raise and discuss nine open questions about the psychology of human inquiry.
A Level Psychology Topic Quiz - Research Methods. A hypothesis is a testable prediction about the variables in a study. The hypothesis should always contain the independent variable (IV) and the dependent variable (DV). A hypothesis can be directional (one-tailed) or non-directional (two-tailed).
15. Aggression. 16. Forensic Psychology. 17. Addiction. A-Level Psychology past paper questions by topic for AQA. Also offering past papers and videos for Edexcel and OCR.
Hey guys, another episode out - woo!! So as promised, questions of the episode and answers to LAST WEEKS because I forgot to record them for this week, soz. Anyway answers here: 1. Piaget's theory refers to the idea that thought comes before language. In order to express a concept, an individ…
Key components of this method include observations, questions, hypotheses, predictions, experiments, and analyses. Based on these steps, scientists conclude and evaluate whether their hypothesis ...
An example of a bad study that Haidt cites in his book is one that paid $15 each to 1,787 self-selected internet respondents, aged 19 to 32, to answer 15 minutes' worth of questions online.