Speech to Text Converter
Descript instantly turns speech into text in real time. Just start recording and watch our AI speech recognition transcribe your voice—with 95% accuracy—into text that’s ready to edit or export.


How to automatically convert speech to text with Descript
Create a project in Descript, select record, and choose your microphone input to start a recording session. Or upload a voice file to convert the audio to text.
As you speak into your mic, Descript’s speech-to-text software turns what you say into text in real time. Don’t worry about filler words or mistakes; Descript makes it easy to find and remove those from both the generated text and recorded audio.
Enter Correct mode (press the C key) to edit, apply formatting, highlight sections, and leave comments on your speech-to-text transcript. Filler words will be highlighted, which you can remove by right clicking to remove some or all instances. When ready, export your text as HTML, Markdown, Plain text, Word file, or Rich Text format.
Download the app for free
More articles and resources.

New: Free Overdub on all Descript accounts, with easier voice cloning

What is a video crossfade effect?

New one-click integrations with Riverside, SquadCast, Restream, Captivate
Other tools from descript, silence remover, video presentation maker, video compilation maker, business video maker, video brightness editor, youtube transcript generator, article to video, youtube description generator, split-screen video editor.
Speech to Text
- 3 Create a new project Drag your file into the box above, or click Select file and import it from your computer or wherever it lives.
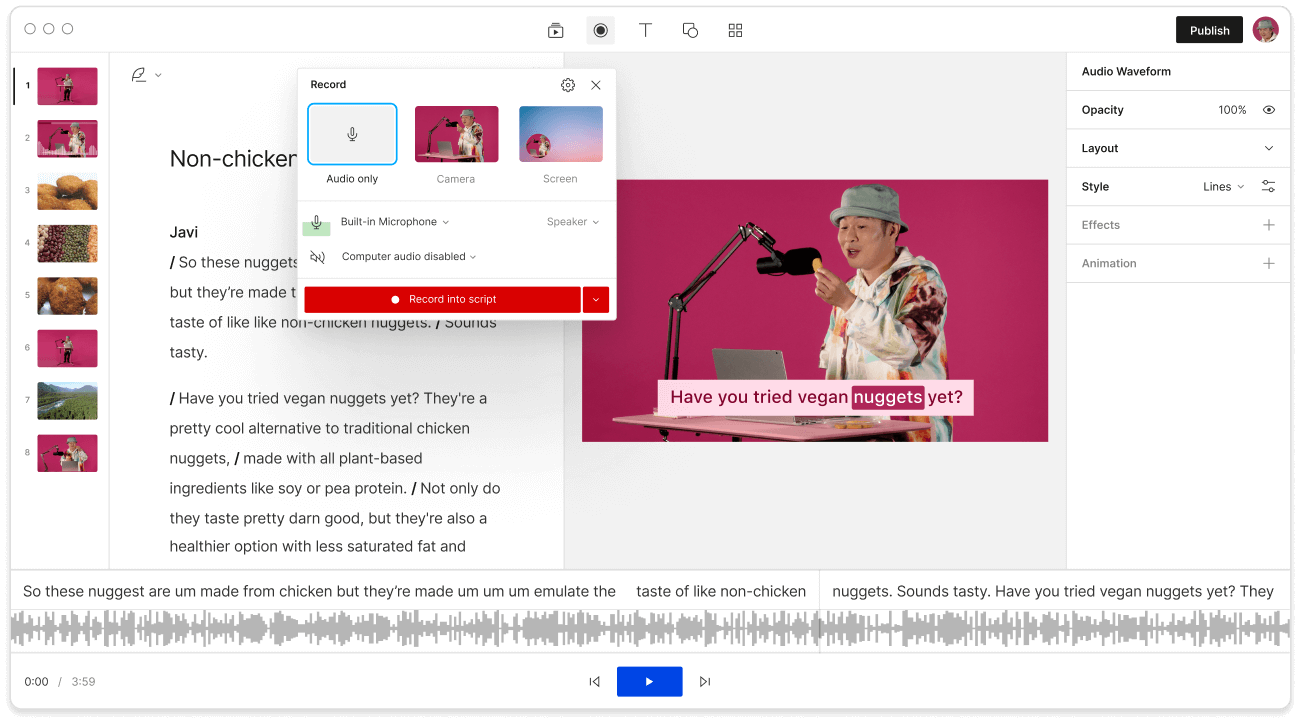
Expand Descript’s online voice recognition powers with an expandable transcription glossary to recognize hard-to-translate words like names and jargon.
Record yourself talking and turn it into text, audio, and video that’s ready to edit in Descript’s timeline. You can format, search, highlight, and other actions you’d perform in a Google Doc, while taking advantage of features like text-to-speec h, captions, and more.

Go from speech to text in over 22 different languages, plus English. Transcribe audio in French , Spanish , Italian, German and other languages from around the world. Finnish? Oh we’re just getting started.

Yes, basic real-time speech to text conversion is included for free with most modern devices (Android, Mac, etc.) Descript also offers a 95% accurate text-to-speech converter for up to 1 hour per month for free.
Speech-to-text conversion works by using AI and large quantities of diverse training data to recognize the acoustic qualities of specific words, despite the different speech patterns and accents people have, to generate it as text.
Yes! Descript‘s AI-powered Overdub feature lets you not only turn speech to text but also generate human-sounding speech from a script in your choice of AI stock voices.
Descript supports speech-to-text conversion in Catalan, Finnish, Lithuanian, Slovak, Croatian, French (FR), Malay, Slovenian, Czech, German, Norwegian, Spanish (US), Danish, Hungarian, Polish, Swedish, Dutch, Italian, Portuguese (BR), Turkish.
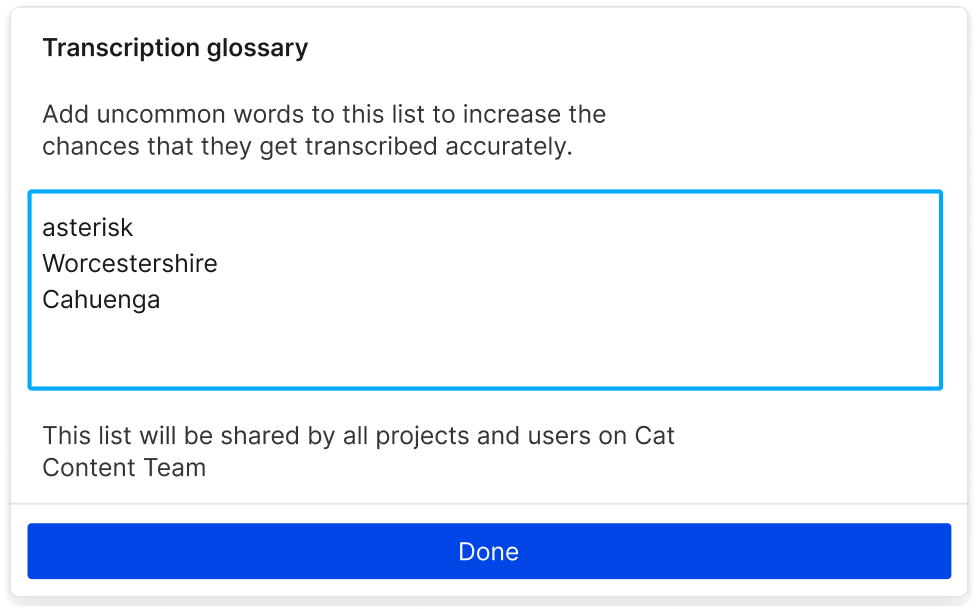
Descript’s included AI transcription offers up to 95% accurate speech to text generation. We also offer a white glove pay-per-word transcription service and 99% accuracy. Expanding your transcription glossary makes the automatic transcription more accurate over time.

Speech to text
An AI Speech feature that accurately transcribes spoken audio to text.
Make spoken audio actionable
Quickly and accurately transcribe audio to text in more than 100 languages and variants. Customize models to enhance accuracy for domain-specific terminology. Get more value from spoken audio by enabling search or analytics on transcribed text or facilitating action—all in your preferred programming language.
High-quality transcription
Get accurate audio to text transcriptions with state-of-the-art speech recognition.
Customizable models
Add specific words to your base vocabulary or build your own speech-to-text models.
Flexible deployment
Run Speech to Text anywhere—in the cloud or at the edge in containers.
Production-ready
Access the same robust technology that powers speech recognition across Microsoft products.
Accurately transcribe speech from various sources
Convert audio to text from a range of sources, including microphones , audio files , and blob storage . Use speaker diarisation to determine who said what and when. Get readable transcripts with automatic formatting and punctuation.
Customize speech models to your needs
Tailor your speech models to understand organization- and industry-specific terminology. Overcome speech recognition barriers such as background noise, accents, or unique vocabulary. Customize your models by uploading audio data and transcripts. Automatically generate custom models using Office 365 data to optimize speech recognition accuracy for your organization.
Deploy anywhere
Run Speech to Text wherever your data resides. Build speech applications that are optimized for robust cloud capabilities and on-premises using containers .
Fuel App Innovation with Cloud AI Services
Learn 5 key ways your organization can get started with AI to realize value quickly.

Comprehensive privacy and security
AI Speech, part of Azure AI Services, is certified by SOC, FedRAMP, PCI DSS, HIPAA, HITECH, and ISO.
View and delete your custom speech data and models at any time. Your data is encrypted while it's in storage.
Your data remains yours. Your audio input and transcription data aren't logged during audio processing.
Backed by Azure infrastructure, AI Speech offers enterprise-grade security, availability, compliance, and manageability.
Comprehensive security and compliance, built in
Microsoft invests more than $1 billion annually on cybersecurity research and development.

We employ more than 3,500 security experts who are dedicated to data security and privacy.

Azure has more certifications than any other cloud provider. View the comprehensive list .

Flexible pricing gives you the control you need
With Speech to Text, pay as you go based on the number of hours of audio you transcribe, with no upfront costs.
Get started with an Azure free account

After your credit, move to pay as you go to keep building with the same free services. Pay only if you use more than your free monthly amounts.

Documentation and resources
Get started.
Browse the documentation
Create an AI Speech service with the Microsoft Learn course
Explore code samples
Check out our sample code
See customization resources
Explore and customize your voice-to-text solution with Speech Studio . No code required.
Frequently asked questions about Speech to Text
What is speech to text.
It is a feature within the Speech service that accurately and quickly transcribes audio to text.
What are Azure AI Services?
AI Services are a collection of customizable, prebuilt AI models that can be used to add AI to applications. There are a variety of domains, including Speech, Decision, Language, and Vision. Speech to Text is one feature within the Speech service. Other Speech related features include Text to Speech , Speech Translation , and Speaker Recognition . An example of a Decision service is Personalizer , which allows you to deliver personalized, relevant experiences. Examples of AI Languages include Language Understanding , Text Analytics for natural language processing, QnA Maker for FAQ experiences, and Translator for language translation.
Start building with AI Services
- Audio Video Transcription
Convert Audio and Video to Text: Transcription Has Never Been Easier.
Table of contents.
In today’s fast-paced digital world, the ability to convert audio and video content into text is invaluable. Whether you’re dealing with podcasts, Zoom meetings, or YouTube videos, transcription services and software can transform your media into accessible and usable text files. Here’s a comprehensive look at how to navigate the world of audio and video transcription effectively.
Understanding Transcription
Transcription is the process of converting speech from audio or video files into written text. This can be achieved through various means, including manual dictation, automatic transcription using speech recognition technology, or a combination of both. High-quality, accurate transcription is crucial for professionals who rely on detailed and precise text outputs.
Transcription has other benefits other than what is traditionally associated with it. It is great for SEO. When you embed a video onto your webpage, having a transcription is really helpful for search bots to understand what the video is about.
Now imagine if you had a multilingual site and you were able to embed transcriptions in each language. It would make for much richer and contextual content.
Formats and File Types
Transcription supports a plethora of file formats. Common video file formats like AVI, MOV, WMV, MPEG, and WEBM, as well as audio formats such as WAV, MP3, and AAC, can all be converted to text. Whether you need to transcribe a French film in MOV format or a Spanish podcast in WAV, the right transcription tool can handle it.
Speech to Text Conversion
Speech to text technology is at the heart of modern transcription software. This technology uses advanced speech recognition to convert speech from audio recordings or video content into text transcription, making it easier than ever to produce subtitles (SRT files), DOCX documents, or simple TXT files.
Tools and Services
There are numerous transcription services and tools available that cater to different needs and budgets. Free transcription tools are a good starting point for simple tasks like converting short audio files or video clips. For more professional needs, such as transcribing lengthy recordings or ensuring that the transcription includes specific fonts and formats, paid transcription services offer more advanced features, including real-time transcription and support for multiple languages like English, Chinese, German, and French.
Applications in Social Media and Content Creation
Transcription software is also incredibly useful in social media and video editing workflows. By converting video to text, content creators can easily create accurate subtitles for their video content, enhancing accessibility and engagement on platforms like Instagram and Facebook. This also simplifies the process of editing video content, as text files can be used to refine the spoken content before the final video is produced.
Automatic vs. Manual Transcription
While automatic transcription offers a quick and cost-effective way to convert audio and video to text, it may not always provide the most accurate transcription. Automatic transcription services are continually improving, but they can still struggle with accents, overlapping speech, and background noise. For content that requires a high level of accuracy, such as legal docs or medical records, manual transcription provided by professional transcriptionists might be more appropriate.
Pricing and Security
The pricing of transcription services varies widely based on the length of the audio file, the clarity of the recording, the number of speakers, and the turnaround time. Most services charge per minute of audio transcribed, and some may require a credit card for payment. It’s also crucial to consider the security measures these services offer, especially when dealing with sensitive information.
Integrations and Compatibility
Today’s transcription tools are designed to be compatible with a wide range of applications and platforms. From Microsoft software to social media platforms, the ability to integrate seamlessly with your existing workflow is key. Whether it’s converting a video file for editing or extracting text from an audio recording for corporate records, the right tool can make all the difference.
From podcasts and audio recordings to video files and Zoom meetings, converting speech to text has never been more accessible. With the right transcription tool or service, you can enhance your workflow, improve accessibility, and ensure your video and audio content reaches a wider audience with ease. Whether you need a quick text file or a detailed document with specific formatting, transcription can help you achieve high-quality results efficiently.
Try Speechify AI Transcription
Pricing : Free to try
Effortlessly transcribe any video in a snap. Just upload your audio or video and hit “Transcribe” for the most precise transcription.
Boasting support for over 20 languages, Speechify Video Transcription stands out as the premier AI transcription service.
Speechify AI Transcription Features
- Easy to use UI
- Multilingual transcription
- Transcribe directly from YouTube or upload a video
- Transcribe your video in minutes
- Great for individuals to large teams
Speechify is the best option for AI transcription. Move seamlessly between the suite of products in Speechify Studio or use just AI transcription. Try it for yourself, for free !
Frequently Asked Questions
<strong>how do i convert audio and video to text</strong>.
To convert audio and video to text, you can use transcription software or services that allow you to upload your file and then automatically or manually transcribe the content into a text format, such as TXT, DOCX, or SRT.
<strong>How to automatically transcribe your video or audio into text?</strong>
Automatically transcribing your video or audio into text can be done using automatic transcription tools or software that utilize speech recognition technology to generate a text transcription from your audio or video files.
<strong>What is the app that converts video audio to text?</strong>
Apps like Otter.ai , Rev’s mobile app, and Transcribe are popular options that can convert video and audio to text. These apps use advanced speech recognition technologies to provide accurate transcriptions.
<strong>How can I transcribe a video to text for free?</strong>
To transcribe a video to text for free, you can use online platforms such as Otter.ai, which offers a limited amount of free transcription minutes per month, or utilize free tools provided by YouTube for videos uploaded to the platform.
- Previous How to Record Voice Overs Properly Over Gameplay: Everything You Need to Know
- Next Voice Simulator & Content Creation with AI-Generated Voices

Cliff Weitzman
Cliff Weitzman is a dyslexia advocate and the CEO and founder of Speechify, the #1 text-to-speech app in the world, totaling over 100,000 5-star reviews and ranking first place in the App Store for the News & Magazines category. In 2017, Weitzman was named to the Forbes 30 under 30 list for his work making the internet more accessible to people with learning disabilities. Cliff Weitzman has been featured in EdSurge, Inc., PC Mag, Entrepreneur, Mashable, among other leading outlets.
Recent Blogs

Voice Simulator & Content Creation with AI-Generated Voices

How to Record Voice Overs Properly Over Gameplay: Everything You Need to Know
Voicemail Greeting Generator: The New Way to Engage Callers

How to Avoid AI Voice Scams
Character AI Voices: Revolutionizing Audio Content with Advanced Technology

Best AI Voices for Video Games

How to Monetize YouTube Channels with AI Voices

Multilingual Voice API: Bridging Communication Gaps in a Diverse World
Resemble.AI vs ElevenLabs: A Comprehensive Comparison

Apps to Read PDFs on Mobile and Desktop

How to Convert a PDF to an Audiobook: A Step-by-Step Guide
AI for Translation: Bridging Language Barriers
IVR Conversion Tool: A Comprehensive Guide for Healthcare Providers
Best AI Speech to Speech Tools
AI Voice Recorder: Everything You Need to Know
The Best Multilingual AI Speech Models

Program that will Read PDF Aloud: Yes it Exists
How to Convert Your Emails to an Audiobook: A Step-by-Step Tutorial
How to Convert iOS Files to an Audiobook
How to Convert Google Docs to an Audiobook
How to Convert Word Docs to an Audiobook
Alternatives to Deepgram Text to Speech API
Is Text to Speech HSA Eligible?
Can You Use an HSA for Speech Therapy?
Surprising HSA-Eligible Items
Ultimate guide to ElevenLabs
Voice changer for Discord
How to download YouTube audio

Speechify 3.0 is the Best Text to Speech App Yet.

Voice API: Everything You Need to Know
Only available on iPhone and iPad
To access our catalog of 100,000+ audiobooks, you need to use an iOS device.
Coming to Android soon...
Join the waitlist
Enter your email and we will notify you as soon as Speechify Audiobooks is available for you.
You’ve been added to the waitlist. We will notify you as soon as Speechify Audiobooks is available for you.
403: Access Denied
Reference number: 18.45a0317.1713415967.9790ebf.
- Premium
- Extension to Read Aloud ANY Website
- Android App
- Speechnotes for Dictation
- NEW: Pairing for Meaningful Relationships
- Professional Voice Over Artists

- Auto Save
- Dark Theme
- Show /Hide Help Pane
- User-Interface Language:
- Upload to Google Drive
- Download as file (.txt)
- Word Document (.doc)
- Save Session (Ctrl+S)
Say or Click
Tip: While dictating, press Enter↵ (on keyboard) to quickly move results from buffer to text editor.
GO PREMIUM - UNLEASH CREATIVITY
Save time & energy every time you type - on ANY website! Unleash your full creativity
Remove ads & unlock premium features In addition: Dictate on ANY website One tap to insert pre-typed texts On ANY website across the web!

Speech to Text Transcription with the Cloud Speech API
Checkpoints.
Create an API Key
Create your Speech API request
Call the Speech API for English language
Call the Speech API for French language
- Setup and requirements
- Task 1. Create an API key
- Task 2. Create your API request
- Task 3. Call the Speech-to-Text API
- Task 4. Speech-to-Text transcription in different languages
- Congratulations!

The Speech-to-Text API lets you transcribe audio speech files to text files in over 80 languages.
In this lab you send an audio file to the Speech API for transcription.
What you'll learn
In this lab, you explore the following:
- Creating a Speech-to-Text API request and calling the API with curl
- Calling the Speech-to-Text API with audio files in a different language
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab , shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
If necessary, copy the Username below and paste it into the Sign in dialog.
You can also find the Username in the Lab Details panel.
Click Next .
Copy the Password below and paste it into the Welcome dialog.
You can also find the Password in the Lab Details panel.
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Since you use curl to send a request to the Speech-to-Text API, you need to generate an API key to pass in your request URL.

Click Create credentials and select API key .
Copy and record the key you just generated to use later in this lab.
Click Close .
Click Check my progress to verify the objective.
Now save your key to an environment variable to avoid having to insert the value of your API key in each request.
- To perform the next steps, connect to the linux-instance provisioned for you via SSH :
Notice the linux-instance VM in the VM instances list. VM details are to the right of the VM name.
- Click SSH to the right of the linux-instance VM name.
An interactive shell opens. Use this to perform the next operations.
- In the shell (SSH) run the following, replacing <your_api_key> with the key you just copied:
- Build your request to the API in a request.json file. Create the request.json file:
- Open the file using your preferred command line editor ( nano , vim , emacs ) or gcloud and then add the following to your request.json file, using the uri value of the sample raw audio file:
- Save the file as needed.
The request body has a config and audio object.
In config , you tell the Speech-to-Text API how to process the request:
- The encoding parameter tells the API which type of audio encoding you're using while the file is being sent to the API. FLAC is the encoding type for .raw files (Learn more about encoding types from the RecognitionConfig reference ).
- languageCode defaults to English if left out of the request.
There are other parameters you can add to your config object, but encoding is the only required one.
In the audio object, you pass the API the uri of the audio file, which is stored in Cloud Storage for this lab.
Now you're ready to call the Speech-to-Text API!
- Pass your request body, along with the API key environment variable, to the API with the following curl command (all in one single command line):
Your response is stored in a file named as result.json.
- To see the contents of file you can use:
The response returned by the curl command look something like this:
The transcript value returns the Speech API's text transcription of your audio file, and the confidence value indicates how sure the API is that it has accurately transcribed your audio.
Notice that you called the syncrecognize method in our request above. The Speech-to-Text API supports both synchronous and asynchronous speech to text transcription.
In this example a complete audio file was used, but you can also use the syncrecognize method to perform streaming speech to text transcription while the user is still speaking.
Are you multilingual? The Speech-to-Text API supports speech to text transcription in over 100 languages!
You can change the language_code parameter in request.json . You can find a list of supported languages in the Language support guide .
Try a French audio file - (for a preview, listen here ).
- Edit your request.json and change the content to the following:
Call the Speech-to-Text by running the curl command again.
See the results:
You should see the following response:
This is a sentence from a popular French children’s tale by Jean de la Fontaine. If you’ve got audio files in another language, you can try adding them to Cloud Storage and changing the languageCode parameter in your request.
You've performed speech to text transcription with the Speech API. You passed the API the Cloud Storage URI of your audio file and reviewed the alternative of passing a base64 encoded string of your audio content.
Finish your quest
This self-paced lab is part of the Intro to ML: Language Processing and Language, Speech, Text & Translation with Google CLoud APIs quests. A quest is a series of related labs that form a learning path. Completing a quest earns you a badge to recognize your achievement. You can make your badge or badges public and link to them in your online resume or social media account. Enroll in any quest that contains this lab and get immediate completion credit. Refer to the Google Cloud Skills Boost catalog for all available quests.
Take your next lab
Continue your Quest with Measuring and Improving Speech Accuracy or try one of these:
- Translate Text with the Cloud Translation API
- Classify Text into Categories with the Natural Language API
Next steps / Learn more
- Check out these tutorials in the documentation.
- Try out the Cloud Vision API and Natural Language API .
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated September 20, 2023
Lab Last Tested September 20, 2023
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.
The Cloud Speech API lets you do speech to text transcription from audio files in over 80 languages. In this hands-on lab you’ll record your own audio file and send it to the Speech API for transcription.
Duration: 2m setup · 30m access · 30m completion
AWS Region: []
Levels: introductory
Permalink: https://www.cloudskillsboost.google/catalog_lab/546
speech-to-text-demo
A sample browser app for Bluemix that use the speech-to-text service, fetching a token via Node.js

Template type: node
This sandbox is a live running version of https://www.github.com/hamed-saadallah/speech-to-text/tree/master/
Want to try a dynamic demo of ReadSpeaker’s AI voices for your application?
Get in touch with our sales team to request a full demo with your own content.
Explore ReadSpeaker's AI voices
See our Languages & Voices page for a complete list of available languages for each solution.
ReadSpeaker text-to-speech voices are humanlike, relatable voices. There are 110+ voices available in 35+ languages , with more on their way. Meet the ReadSpeaker TTS family of high-quality voice personas and put them to the test.
Industry-Leading TTS Voices
At ReadSpeaker, we have a passion for developing high-quality TTS voices. In fact, expert third party industry observers rate the US English ReadSpeaker TTS voice as being the most accurate on the market .
The enthusiastic feedback we receive from our customers confirms that we deliver the very best TTS solutions for successful online, offline, embedded, and server-based applications around the world.
Our commitment to providing outstanding TTS solutions is made possible by our uncompromising production process, designed to guarantee the quality levels that have earned ReadSpeaker TTS the trust of customers from across countries and markets.

How Our TTS Voices Are Made
To create our speech personas, we select and record professional voice talents.
Once a voice talent has been selected, she or he works with our voice development team for several days or weeks, depending on the type of voice, or the voice technology, we want to use.
A diverse script is used for the recordings, designed to contain all the sound patterns of the language in development. The team closely monitors the recording process to check for consistency in pronunciation, accentuation, and style.
Neural Voices
ReadSpeaker creates so-called neural voices, using techniques based on deep learning AI technology. This revolutionary method involves mapping linguistic properties to acoustic features using Deep Neural Networks (DNNs)
An iterative learning process minimises objectively measurable differences between the predicted acoustic features and the observed acoustic features in the training set.
One of the advantages of the new DNN TTS method is that the acoustic database can be much smaller than for a USS voice. Only a few hours of recorded speech are needed for a neural voice, compared to at least three times as many for a good quality USS voice.
Also, the resulting speech is generally smoother and even more human-like. This makes developing new, smart ReadSpeaker TTS voices with even more lifelike, expressive speech and customizable intonation faster than ever.
Custom voices
If your strategy is to offer an exclusive customer experience and you want to take your brand appeal to a new level, one of the most powerful ways to differentiate yourself is by using a custom voice to represent you.
A custom voice sets your brand apart and creates a powerful bond with your customers across your various communication touchpoints. If a preferred celebrity or other talent reflects your brand best and you want to be able to use their voice anytime you need it.
ReadSpeaker can create a custom TTS voice powered by our leading-edge speech engine, to give your brand instant recognition in the voice user interface.

- ReadSpeaker webReader
- ReadSpeaker docReader
- ReadSpeaker TextAid
- Assessments
- Text to Speech for K12
- Higher Education
- Corporate Learning
- Learning Management Systems
- Custom Text-To-Speech (TTS) Voices
- Voice Cloning Software
- Text-To-Speech (TTS) Voices
- ReadSpeaker speechMaker Desktop
- ReadSpeaker speechMaker
- ReadSpeaker speechCloud API
- ReadSpeaker speechEngine SAPI
- ReadSpeaker speechServer
- ReadSpeaker speechServer MRCP
- ReadSpeaker speechEngine SDK
- ReadSpeaker speechEngine SDK Embedded
- Accessibility
- Automotive Applications
- Conversational AI
- Entertainment
- Experiential Marketing
- Guidance & Navigation
- Smart Home Devices
- Transportation
- Virtual Assistant Persona
- Voice Commerce
- Customer Stories & e-Books
- About ReadSpeaker
- TTS Languages and Voices
- The Top 10 Benefits of Text to Speech for Businesses
- Learning Library
- e-Learning Voices: Text to Speech or Voice Actors?
- TTS Talks & Webinars
Make your products more engaging with our voice solutions.
- Solutions ReadSpeaker Online ReadSpeaker webReader ReadSpeaker docReader ReadSpeaker TextAid ReadSpeaker Learning Education Assessments Text to Speech for K12 Higher Education Corporate Learning Learning Management Systems ReadSpeaker Enterprise AI Voice Generator Custom Text-To-Speech (TTS) Voices Voice Cloning Software Text-To-Speech (TTS) Voices ReadSpeaker speechCloud API ReadSpeaker speechEngine SAPI ReadSpeaker speechServer ReadSpeaker speechServer MRCP ReadSpeaker speechEngine SDK ReadSpeaker speechEngine SDK Embedded
- Applications Accessibility Automotive Applications Conversational AI Education Entertainment Experiential Marketing Fintech Gaming Government Guidance & Navigation Healthcare Media Publishing Smart Home Devices Transportation Virtual Assistant Persona Voice Commerce
- Resources Resources TTS Languages and Voices Learning Library TTS Talks and Webinars About ReadSpeaker Careers Support Blog The Top 10 Benefits of Text to Speech for Businesses e-Learning Voices: Text to Speech or Voice Actors?
- Get started
Search on ReadSpeaker.com ...
All languages.
- Norsk Bokmål
- Latviešu valoda
Request a full dynamic demo to try our voices with your scripts!
Please provide a brief project overview for a customized dynamic demo setup.
Search code, repositories, users, issues, pull requests...
Provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications
Inference and training library for high-quality TTS models.
huggingface/parler-tts
Folders and files, repository files navigation.
Parler-TTS is a lightweight text-to-speech (TTS) model that can generate high-quality, natural sounding speech in the style of a given speaker (gender, pitch, speaking style, etc). It is a reproduction of work from the paper Natural language guidance of high-fidelity text-to-speech with synthetic annotations by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively.
Contrarily to other TTS models, Parler-TTS is a fully open-source release. All of the datasets, pre-processing, training code and weights are released publicly under permissive license, enabling the community to build on our work and develop their own powerful TTS models.
This repository contains the inference and training code for Parler-TTS. It is designed to accompany the Data-Speech repository for dataset annotation.
We're proud to release Parler-TTS Mini v0.1 , our first 600M parameter model, trained on 10.5K hours of audio data. In the coming weeks, we'll be working on scaling up to 50k hours of data, in preparation for the v1 model.
📖 Quick Index
Installation.
- Model weights and datasets
Parler-TTS has light-weight dependencies and can be installed in one line:
You can directly try it out in an interactive demo here !
Using Parler-TTS is as simple as "bonjour". Simply use the following inference snippet.
The training folder contains all the information to train or fine-tune your own Parler-TTS model. It consists of:
- 1. An introduction to the Parler-TTS architecture
- 2. The first steps to get started
- 3. A training guide
TL;DR: After having followed the installation steps , you can reproduce the Parler-TTS Mini v0.1 training recipe with the following command line:
Acknowledgements
This library builds on top of a number of open-source giants, to whom we'd like to extend our warmest thanks for providing these tools!
Special thanks to:
- Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively, for publishing such a promising and clear research paper: Natural language guidance of high-fidelity text-to-speech with synthetic annotations .
- the many libraries used, namely 🤗 datasets , 🤗 accelerate , jiwer , wandb , and 🤗 transformers .
- Descript for the DAC codec model
- Hugging Face 🤗 for providing compute resources and time to explore!
If you found this repository useful, please consider citing this work and also the original Stability AI paper:
Contribution
Contributions are welcome, as the project offers many possibilities for improvement and exploration.
Namely, we're looking at ways to improve both quality and speed:
- Train on more data
- Add more features such as accents
- Add PEFT compatibility to do Lora fine-tuning.
- Add possibility to train without description column.
- Add notebook training.
- Explore multilingual training.
- Explore mono-speaker finetuning.
- Explore more architectures.
- Compilation and static cache
- Support to FA2 and SDPA
- Add more evaluation metrics
Contributors 2
- Python 99.9%
- Makefile 0.1%
- Get Inspired
- Announcements
Gemini 1.5 Pro Now Available in 180+ Countries; With Native Audio Understanding, System Instructions, JSON Mode and More
April 09, 2024

Grab an API key in Google AI Studio , and get started with the Gemini API Cookbook
Less than two months ago, we made our next-generation Gemini 1.5 Pro model available in Google AI Studio for developers to try out. We’ve been amazed by what the community has been able to debug , create and learn using our groundbreaking 1 million context window.
Today, we’re making Gemini 1.5 Pro available in 180+ countries via the Gemini API in public preview, with a first-ever native audio (speech) understanding capability and a new File API to make it easy to handle files. We’re also launching new features like system instructions and JSON mode to give developers more control over the model’s output. Lastly, we’re releasing our next generation text embedding model that outperforms comparable models. Go to Google AI Studio to create or access your API key, and start building.
Unlock new use cases with audio and video modalities
We’re expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image (frames) and audio (speech) for videos uploaded in Google AI Studio, and we look forward to adding API support for this soon.
Gemini API Improvements
Today, we’re addressing a number of top developer requests:
1. System instructions : Guide the model’s responses with system instructions, now available in Google AI Studio and the Gemini API. Define roles, formats, goals, and rules to steer the model's behavior for your specific use case. Set System Instructions easily in Google AI Studio 2. JSON mode : Instruct the model to only output JSON objects. This mode enables structured data extraction from text or images. You can get started with cURL, and Python SDK support is coming soon. 3. Improvements to function calling : You can now select modes to limit the model’s outputs, improving reliability. Choose text, function call, or just the function itself.
A new embedding model with improved performance
Starting today, developers will be able to access our next generation text embedding model via the Gemini API. The new model, text-embedding-004 , (text-embedding-preview-0409 in Vertex AI ), achieves a stronger retrieval performance and outperforms existing models with comparable dimensions, on the MTEB benchmarks .
These are just the first of many improvements coming to the Gemini API and Google AI Studio in the next few weeks. We’re continuing to work on making Google AI Studio and the Gemini API the easiest way to build with Gemini. Get started today in Google AI Studio with Gemini 1.5 Pro, explore code examples and quickstarts in our new Gemini API Cookbook , and join our community channel on Discord .
- Alan (Australian)
- Allison (US)
- Ashley (US)
- Brenda (US)
- Bridget (UK)
- Catherine (UK)
- Daniel (UK)
- Elizabeth (UK)
- Fiona (Scottish)
- Grace (Australian)
- Karen (Australian)
- Lakshmi (Indian)
- Lee (Australian)
- Matilda (Australian)
- Moira (Irish)
- Oliver (UK)
- Olivia (UK)
- Prashant (Indian)
- Samantha (US)
- Sangeeta (Indian)
- Serena (UK)
- Steven (US)
- Tessa (South African)
- Veena (Indian)
Language ID:

Our Text-To-Speech

Our Characters


Contribute to the Microsoft Edge forum! Click here to learn more 💡
April 9, 2024
Contribute to the Microsoft Edge forum!
Click here to learn more 💡
- Search the community and support articles
- Microsoft Edge
- PDF and reading
- Search Community member
Ask a new question
Text to speech / Speech synthesis broken on mobile Edge browser
Describe the bug Speech synthesis is broken. It used to work and find voices in past verions. At some point in time it stopped working - I can no lonver get voices and therefore not use speech synthesis / tts. Is this an intentional downgrade? Interesting fact: The "read out loud" function is working. But the browser tts api is not.
To Reproduce Steps to reproduce the behavior:
Go to any live demo, e.g.: EasySpeech - Cross browser Speech Synthesis with easy API (jankapunkt.github.io)
Try to select a voice => not possible
Try to speak any text => not possible due to no voice
See error log on the right hand side and status
Expected behavior Working speech synthesis on mobile Edge. This might very well be a browser issue - maybe you have more insights on that? All other tested browsers work just fine (Desktop Edge, Chrome, Firefox, Mobile Chrome, Firefox)

Smartphone (please complete the following information):
Device: Samsung Galaxy A52
OS: One UI 6 / Android 14
Browser: Microsoft Edge on Android
Version: 123.0.2420.74
Additional context Yes, I installed voices on Android system level. Still, Edge does not resprect these settings.
I found at least one more reddit adressing the very same issue - it used to work in the past but is broken now: https://www.reddit.com/r/edge/comments/1498gcn/any_idea_why_on_android_edge_the_voices_from/
I really hope to get more insights here since some of my customers rely on MS Edge. Thanks in advance!
- Subscribe to RSS feed
Report abuse
Replies (1) .
- Microsoft Agent |
Hello, JensBühl
Welcome to the Microsoft Community.
Thanks for visiting Microsoft Community. Hello, as far as I know, you should be an experienced and professional user.
I wish I could handle your problem, however, the issues on Mobile Speech Synthesis is out of reach of the response support community. It is more suitable for publishing on Microsoft Learn (English only), you can click on "Ask a question", there are experts who can provide more professional solutions in that place.
Here is a link to the forum where you can raise specific scenarios and share your idea to help solve the problem.
Microsoft Edge - Microsoft Q&A
Sincerely hope that your question will be dealt with appropriately after contact the correct department. Thank you for your understanding!
Additionally I've also taken this issue to feedback, if I have any new progress I'll keep you posted here, thank you for your understanding and cooperation!
Thank you for your time and effort in resolving this issue.
Best regards
Bobhe | Microsoft Community Support Specialist
Was this reply helpful? Yes No
Sorry this didn't help.
Great! Thanks for your feedback.
How satisfied are you with this reply?
Thanks for your feedback, it helps us improve the site.
Thanks for your feedback.
Question Info
- Norsk Bokmål
- Ελληνικά
- Русский
- עברית
- العربية
- ไทย
- 한국어
- 中文(简体)
- 中文(繁體)
- 日本語
Mobile Menu Overlay
The White House 1600 Pennsylvania Ave NW Washington, DC 20500
Remarks as Prepared for John Podesta Columbia Global Energy Summit
New York, New York
Thanks so much, Jason. It’s great to be with all of you today. I want to commend the Columbia Center on Global Energy Policy for everything you do to advance the policy conversation on the most pressing global climate and clean energy issues.
We’re coming together at a moment when the realities of the climate crisis have never been more clear—and when our ability to address those realities has never been greater.
I. Climate Imperative
July of last year was the hottest month on record. 2023 was the hottest year on record. Last month was the hottest March on record.
And each month in between July and March was the hottest ever recorded on our planet.
Meanwhile, the ocean—which absorbs the majority of the Earth’s warming—has been shattering temperature records for over a year.
This isn’t a fluke—this is the climate crisis. And it’s affecting all corners of the globe.
Let’s just take one of the most common—and the most deadly—consequences: extreme heat.
According to a World Weather Attribution study, climate change made the scorching heat wave in West Africa in February ten times more likely.
Last year, one single heat event in India killed more than 100 people…and Iran hit a heat index of 152 degrees Fahrenheit or 67 degrees Celsius—nearing the limit for human survival.
Here in the United States, Phoenix had 31 straight days of temperatures at or above 110 degrees Fahrenheit last summer—contributing to nearly 600 deaths.
And in Europe—the fastest warming continent in the world—more than 61,000 people are estimated to have succumbed to the record-breaking summer heat of 2022.
These are not future projections. This is happening right now.
The economic toll in developed and developing countries alike is staggering.
Meanwhile, global emissions keep rising—reaching a record level last year.
While it’s true that we have made progress since Paris…we still have a lot more work to do to ensure a safe future for humanity.
II. Era of Climate Action
President Biden and Vice President Harris have taken on the climate crisis from Day 1…
By rejoining the Paris Agreement and making climate a top priority in international diplomacy…
By mobilizing a whole-of-government approach to cutting carbon pollution across every sector…in power…transportation …buildings…industry…agriculture and forestry…
And by passing the Inflation Reduction Act—the largest investment in climate and clean energy in history.
The law is unleashing private sector deployment of clean energy while boosting innovation to develop the next generation of technologies that we’ll need to get to net zero.
In the time that President Biden has been in office, private companies have announced over $380 billion in new clean energy investments.
And just since the IRA passed, over 270,000 clean energy jobs have been created across the nation.
All in all, the Inflation Reduction Act, the Bipartisan Infrastructure Law, and strong new emission reduction standards in the power and transportation are putting America on a path to reach President Biden’s climate goal of cutting our carbon pollution in half by 2030.
Here in the United States, we’ve backed up our ambition with action—and we need to see that around the world as well.
New climate targets—Nationally Determined Contributions, or NDCs—are due to be submitted under the Paris Agreement early next year.
Those NDCs need to be aligned with a 1.5 degree world. And while ambitious NDCs are necessary, they are not sufficient.
They need to be backed up with domestic policies that spur innovation and accelerate deployment of clean energy in countries at all stages of development.
Even as we invest in America to build a clean energy economy—and even as we work with our allies and partners to build more resilient, secure clean energy supply chains—we have no intention of pulling the ladder up behind us.
Every nation deserves the ability to build a clean energy economy that will protect its own citizens and support long-term growth…
The ability to build industries that can innovate, scale, and compete on a level playing field.
The ability to participate fully in building a clean energy future that prevents the worst impacts of climate change and protects the most vulnerable communities.
That’s why the United States will continue to drive a virtuous cycle of innovation and investment that lowers the cost of clean energy technologies in a fair and transparent way…
While at the same time we will continue to use our public and private dollars to support countries embarking on their own clean energy transitions—and continue to encourage multilateral institutions to make important reforms necessary to do the same.
I’ll have more to say about that in a minute.
III. The Trade Problem
But even as we increase investment at home and abroad, there’s still an elephant in the room…one that’s producing a lot of emissions…and that is global trade.
We have to take a serious look at our international economic systems, including trade—and harness them for climate action.
Our current global trading system was built to promote open and competitive markets—which it has done well—but it wasn’t built to curb emissions.
In fact, by many measures, global trade is a huge contributor to the climate problem.
Emissions from shipping and aviation are a major factor.
These emissions have received a lot of attention and they’ve been the subject of a lot of productive international cooperation to reduce emissions through the production of sustainable fuels and electrification where possible.
But we can’t just look at how we move goods around the world—we have to look at what goods we’re moving.
And when you seriously account for the emissions embodied inside tradable goods… the emissions from the production processes that create the commodities and manufactured products that we buy and sell on the global market… then traded goods account for about twenty-five percent of all global emissions.
To put it another way, if the global trade of goods was its own country, it would be the second-largest carbon polluter in the world after the PRC.
The United States alone imported over 1 gigaton of emissions from traded products—just in the year 2019. That’s the same amount of emissions we expect to reduce in 2030 thanks to the Inflation Reduction Act and Bipartisan Infrastructure Law.
This needs to change if we are to get the climate crisis under control.
Right now, our existing trade policies and the international rules that govern them don’t pay enough attention to the emissions embodied in tradeable goods.
We don’t have uniform standards or consistent, reliable data about embodied emissions.
Global trading rules incentivize carbon leakage—when manufacturing-related emissions from a country with stronger climate policies shift to a country with weaker policies.
There is no penalty for what I like to call carbon dumping—when high emissions in production are exported back into countries with stronger climate policies.
That’s bad news for climate.
It’s also bad news for competition—setting up a race away from robust, resilient, and diverse supply chains to those concentrated in countries with lax standards.
We have a system where transparent, well-structured, targeted incentives to spur fair market development and private-sector investment in clean energy are subject to challenge.
Meanwhile, countries collectively spent $1 trillion to subsidize fossil fuels in 2022 alone, and those policies have proven nearly impossible to eliminate despite near consensus on the need to.
Let me give you an example of what can happen when policy doesn’t take sufficient account of embodied carbon in tradeable goods.
The U.S. used to be the world’s largest producer of aluminum. But after decades of outsourcing and non-market behavior by some countries, only four primary aluminum smelters now remain in the U.S.
Today, over half of the world’s aluminum is made in China, where the average ton of aluminum produces 60% more emissions than it does in the U.S.
This is a bad story for the American workers who lost their jobs and the American communities that were hollowed out.
But it’s also bad for the world as a whole. Globally, aluminum production is substantially dirtier than it needs to be.
It’s what we call a “race to the bottom”—our relatively cleaner industrial base shrunk, while the emissions embodied in our imports swelled.
IV. Announcing Task Force
Instead, we need a smart, 21st century-approach to climate and trade policy that launches a “race to the top” for climate action…a global trading system that slashes pollution, creates a fair and level playing field, protects against carbon dumping, supports good manufacturing jobs and economic opportunity, and rewards every country that’s doing the right thing—no matter their stage of development.
We’re not claiming to have all the answers…but we’re ready to accelerate progress in turning conversations about climate-smart trade tools and policies into practice.
Today, we are announcing a new White House Climate and Trade Task Force, which will have three focus areas.
First, developing our climate and trade policy toolkit—with an open mind about what features and approaches will be most effective at addressing carbon leakage, carbon dumping, and embodied carbon in general.
We’re drawing on lessons we’ve learned from the ongoing negotiations, led by U.S. Trade Representative Katharine Tai, for a Global Arrangement on Steel and Aluminum between the EU and the US.
We’re open to proposals from our colleagues on Capitol Hill and policy thought leaders from inside and outside government.
We’re ready to deepen dialogue with our partners and allies around the world, from the UK to Australia to the EU as it pursues its Carbon Border Adjustment Mechanism.
Second, the Task Force will focus on ensuring that we have credible, robust, and granular data to implement smart climate and trade policies.
We will work closely with trade partners to develop standardized and authoritative ways of measuring embodied emissions so that each country can harness comparative advantages in clean manufacturing.
And we’ll take steps internationally to promote common measurement and high standards on embodied emissions.
And third, the Task Force will identify what more we can do at home and abroad to further position producers to thrive in this new race-to-the-top environment.
Here in the U.S., we want our manufacturers to be the cleanest and most competitive in the world.
As part of that effort, we recently announced $6 billion in grants from the Inflation Reduction Act and the Bipartisan Infrastructure Law to reduce emissions from the industrial sector.
One of the awards will build a new green aluminum smelter that will avoid approximately 75 percent of the emissions of a conventional facility.
It will also be the first new smelter built in the United States in 45 years.
We will continue to build on the success of our Buy Clean Initiative, which harnesses the purchasing power of the federal government to boost lower-carbon construction materials.
And even as we continue our efforts to build out transmission and get clean energy projects up and running faster…we will also explore novel policy levers to help secure affordable supplies of clean electricity for energy-intensive manufacturers.
V. International Support
But we’re not just about positioning America to compete.
Everything we’re doing to implement the Inflation Reduction Act…deploy the clean energy that’s already available…and develop and scale newer technologies…all of that is increasing supply and lowering costs for the entire world.
The Boston Consulting Group projects that the Inflation Reduction Act will drive down the cost of certain clean energy technologies by as much as 25 percent.
It’s important to understand what the Inflation Reduction Act is not doing.
President Biden’s Investing in America approach is not intended to industrially target any sector, including the clean energy sector, in order to dominate the global market.
We are not over-subsidizing domestic industry at any cost, or creating an oversupply of clean energy products, or trying to drive competitors out of the market.
The fact that our transparent, well-structured, targeted incentives are now subject to a challenge at the WTO by the People’s Republic of China—which has spent decades engaged in non-market policies and practices that have distorted the global market for clean energy products like solar, batteries, and critical minerals—is beyond ironic.
Through the Inflation Reduction Act and other investments in clean energy—including strong support for research, development, and demonstration—we’re making clean energy technologies more accessible to more nations…speeding deployment…and lowering emissions globally…all while creating high-quality production and encouraging high labor standards.
The Rhodium Group found that for every ton of carbon pollution reduced at home because of the Inflation Reduction Act, we’ll slash up to 2.9 tons of carbon pollution outside of the U.S.
That’s in large part because of how our investments will lower costs for next-generation technologies like clean hydrogen electrolyzers.
In addition to creating benefits outside our borders, we’re supporting a range of international initiatives to support developing countries in securing the capital they need to decarbonize industry and invest in their clean energy future.
At COP28 in Dubai, Vice President Harris launched the Clean Energy Supply Chain Collaborative to work together with like-minded countries to create high-quality, secure, and diverse clean energy supply chains for several critical technologies, including batteries, electrolyzers, and sustainable aviation fuels.
We also announced up to $568 million in new lending from Treasury through the Clean Technology Fund to support clean energy projects in eligible countries.
Led by Treasury Secretary Janet Yellen, the U.S. continues to support the important evolution of Multilateral Development Banks, including the World Bank, to effectively tackle 21 st century global challenges like the climate crisis.
This is being discussed at the Spring Bank Meetings this week in D.C.
And as we approach COP29 at the end of this year, countries need to work together to set a new collective, quantified goal to boost global climate finance…moving beyond the $100 billion goal set at previous COPs.
We have an opportunity to reimagine a goal that’s ambitious…realistic…and that’s more effective in expanding the ecosystem of international, domestic, public, and private contributors.
We can draw some inspiration from the Convention on Biological Diversity framework that was agreed in Montreal in 2022—which focused on international support and mobilization while capturing the range of finance that is required to unlock the needed trillions in private sector investment.
We’re serious about supporting climate and trade policies that work domestically, crafted in partnership with the labor movement…the climate movement…U.S. industry…and Congress.
We’re serious about helping developing countries secure the financing and resources they need to build strong, sustainable economies.
And we’re serious about mobilizing a global coalition of partners and allies who are ready to build a modern international trade system that confronts the climate crisis head-on.
VI. Conclusion
As I see it, we have two choices.
We can maintain the status quo—a race to the bottom—with trade policies that reward countries that use dirty production and non-market practices to gain a competitive advantage.
Or, we can work together to create a race to the top in global trade…one that rewards countries that are leading on climate action through transparent, market-based policies and practices.
A system that’s coordinated…consistent…and sends a powerful market signal to countries and companies alike.
A new global dynamic where cutting emissions isn’t just the right thing to do, it’s the only thing to do to compete and thrive.
The stakes couldn’t be higher.
But I believe if we make the right choice, we can create and maintain millions of good-paying jobs in the clean energy economy of the future…
We can mobilize billions in private investment in countries around the world…
We can maximize the impact of billions of dollars in taxpayer-funded domestic and international climate investments…
We can accelerate technological innovation and position nations to overcome the challenges of today and tomorrow…
And we can protect our planet for ourselves and for our children.
All of this is possible—as long as we do it together.
So let’s start today. Thank you.
Stay Connected
We'll be in touch with the latest information on how President Biden and his administration are working for the American people, as well as ways you can get involved and help our country build back better.
Opt in to send and receive text messages from President Biden.
Advertisement
Read Nemat Shafik’s Opening Remarks
- Share full article
In her prepared opening statement, Nemat Shafik, the president of Columbia University, laid out ways the university has been responding to antisemitism on campus.
A PDF version of this document with embedded text is available at the link below:
Download the original document (pdf)
Statement of Ms. Minouche Shafik President, Columbia University before the Committee on Education and the Workforce U.S. House of Representatives April 17, 2024 Chairwoman Foxx, Ranking Member Scott, and Members of the Committee, thank you for the opportunity to discuss Columbia University's efforts to address the rising antisemitism on our campus and within our community. Columbia strives to be a community free of discrimination and hate in all of its forms, and we condemn the antisemitism that is far too pervasive today. We have a responsibility to listen and to respond to our Jewish community. Antisemitism is antithetical to Columbia's mission, goals, values, and teachings. It has no place on our campus, and I am committed to doing everything that I can to confront it directly. It is distressing that some in our community have acted in a manner that is inconsistent with our values. I am deeply pained by the reports of members of our community feeling harassed and targeted because of their identity or faith. We have significant and important work to do to address antisemitism on our campus and to make sure that Jewish members of our community feel safe and welcome. In early October, I outlined my plan and vision for Columbia University in my inaugural address, focusing on our efforts to be a university that educates citizens and leaders, generates ideas to solve the world's problems, and is deeply embedded in local and global communities. Three days later, that vision was put to the test by the devastating brutality of Hamas's terrorist attack on Israel. Soon, it became clear that these horrific events would ignite fear and anguish across our campus. For our thousands of Jewish and Israeli students, the attack had deep personal resonance. Many in our community had family or friends who had been killed or taken hostage. Israel's very survival appeared to be at stake. For many other Columbia students, the war in Gaza is part of a larger story of Palestinian displacement as well as a humanitarian catastrophe that also affected many in our community. The University began responding immediately after the terrorist attack on October 7. We worked to contact those directly affected by the attack and to identify the forms of support we could provide our community members—both in the region and on our campus. I attended a vigil for the victims of the Hamas attack on October 9 and connected with members of our community who were dealing with deep distress. Regrettably, the events of October 7 brought to the forefront an undercurrent of antisemitism that is a major challenge for universities across the country. Like many others, Columbia has seen a rise in complaints of antisemitic incidents on campus. We are taking these complaints seriously and have implemented a number of initiatives to eradicate this hatred and
2 ensure safety on our campus. Trying to reconcile the free speech rights of those who want to protest and the rights of Jewish students to be in an environment free of harassment or discrimination has been the central challenge on our campus, and many others, in recent months. As protests grew, we worked to secure the campus and ensure the safety of our students. We restricted access to our campus to those with valid Columbia identification, increased the public safety presence across all of our campuses, brought in external security firms, and added resources to our existing safety escort programs. It also became clear that our policies and structures in place were not well designed to cope with the unprecedented scale of the challenges we faced. To address this, I along with my colleagues immediately put in place changes. We updated our policies and procedures to respond to the events on our campus, with the goal of ensuring safe and responsible events such that all members of our community can participate in their academic pursuits without fear for their safety. We launched an updated reporting and response process in an effort to make it easier to report allegations of hate speech, harassment, and other forms of disruptive behavior, including antisemitic behavior. This included improved training processes on Title VI and reporting obligations for staff working with students and groups, enhanced reporting channels, and supplementing internal resources through a team of outside investigators. We are in the process of establishing an office with the sole purpose of investigating and responding to allegations of discrimination, including antisemitism, in our community. In October, we also quickly formed a Task Force on Antisemitism with the purpose of addressing the root causes behind the antisemitic incidents at our University by independently identifying problems and offering solutions. Thus far, the Task Force has done important work, and we are already working to implement many of its recommendations. These steps will be further supported by our longer-term efforts, which include a review of our event policies, revisions to orientation sessions and mandatory training for students to specifically address antisemitism, and additional investments in scholarship and programming that elevate campus debate on difficult issues. Some of these steps have provoked strong reactions from students, faculty, and outside groups across the ideological spectrum, but we believe they were necessary. We do not, and will not, tolerate antisemitic threats, images, and other violations. We have enforced, and we will continue to enforce, our policies against such actions. We believe we can confront antisemitism and provide a safe campus environment for our community while simultaneously supporting rigorous academic exploration and freedom. This is my highest priority right now at Columbia, and I believe we are moving in the right direction. There is, to be sure, much more work to do, and we welcome feedback from our students and other members of the Columbia community, from Jewish leaders and organizations, and from this Committee. I have approached our response with four principles: ensuring the safety of Columbia's students and faculty; demonstrating care and compassion; balancing freedom of speech while ensuring members of our community feel safe and welcome; and using education to address the problem of antisemitism.
3 Safety is a Top Priority Safety is paramount and the University will take the necessary steps, no matter how unpopular, to secure Columbia's campus and apply rules around protest, harassment, and discrimination consistently and fairly to everyone. After October 7, Columbia took action to ensure the physical safety of our community, and to make clear that Columbia condemns and prohibits antisemitism in any form. On October 12, we brought law enforcement onto our Morningside Heights campus to ensure the safety of our community at a protest for the first time in more than 50 years. On an ongoing basis, we increased the public safety presence across all of our campuses, brought in external security firms for additional support, and added resources to our existing safety escort programs. This included establishing regular communication with the New York City Police Department, ensuring they were either present or on standby for all major events, including vigils and demonstrations. Despite our immediate actions, I was personally frustrated to find that Columbia's policies and structures were sometimes unable to meet the moment. The student disciplinary process at Columbia typically handled 1,000 student conduct cases per year, most of which related to academic dishonesty, the use of alcohol and illegal substances, and one-on-one student complaints. Today, student misconduct cases are far outpacing last year. Further, the University's time, place, and manner policies for events were not designed to address the types of events and protests that followed the October 7 attack. They also lacked details about consequences for violations. We are actively working, and will continue to work, to continuously improve our policies and processes. a. Updated Event Policies We modified our events policies, which clarified the rules for campus demonstrations. The University designated demonstration areas that are available for student protests during set hours. These locations are intended to be prominent and central, while limiting interference with ongoing University activities and ensuring that students who wish to stay away from these demonstrations can avoid them. If students wish to hold a demonstration outside of one of these designated areas, they must seek approval. All demonstrations require two working days' advance registration to ensure that Columbia has time to make necessary safety preparations. Finally, students may not promote a demonstration on campus until after their registration is approved. The policy also lays out a clear procedure for adjudication of alleged violations and consequences for students and student groups who break the rules. University leadership is working with the University Senate—a faculty-led University-wide policymaking body—and relevant internal stakeholders on a longer-term review of our event policies. Having clear and strong policies is important. Enforcing them is equally critical. We have taken disciplinary action against individual students who have violated our policies. We have ongoing investigations into complaints made against faculty and staff members. In November, we suspended two student groups-Students for Justice in Palestine and Jewish Voice for Peace after the groups repeatedly violated our policies and held an unauthorized demonstration on November 9. Additionally, on March 24, an event took place at a campus residential facility that the University had previously barred―twice—from occurring. While the
4 investigation is still ongoing, a number of students have been suspended in connection with policy violations related to this event. b. Task Force on Antisemitism I also established Columbia's Task Force on Antisemitism. The Task Force is led by three prominent Jewish members of our faculty. Their charge is to develop a forum for feedback and suggest improvements. The Task Force has been at the core of the University's response to antisemitism and has met with representatives from all 17 schools at Columbia to learn more about what our Jewish community is encountering on campus. The Task Force was entrusted with three critical efforts: first, to assess the events and other causes contributing to the pain in Columbia's Jewish community; second, to review the relevant policies, rules, and practices that affect our campus; and third, to propose other methods to help the entire community understand the effects of antisemitism at Columbia. To inform their efforts, the Task Force hosted listening sessions to better understand the experiences of our community. The Task Force recently released their first report, which focused on the University's Rules on Demonstrations. The report endorsed Columbia's new Interim University Policy for Safe Demonstrations aimed at promoting First Amendment rights while ensuring student safety and allowing all students to participate fully in campus life. The report also called for stronger enforcement of our policies, a goal toward which we are diligently working. The report shows we have much work to do, but its praise of the new Demonstration Policy is a heartening indication that we are moving in the right direction. The Task Force will be releasing additional reports, and we will continue incorporating their findings into our ongoing efforts to make Columbia a welcoming environment for all. Demonstrating Care and Compassion for All Columbia has long sought to be a welcoming, thriving community for a diverse community of students and faculty. As such, we must demonstrate care and compassion to everyone. Today, Columbia is home to about 5,000 Jewish students. Our students benefit from a vibrant Hillel Center, housed in the Kraft Center for Jewish Student Life, which provides religious programming and other events for the Columbia community, and a network of student groups and dedicated faculty and staff who are committed to creating safe and welcoming spaces for Jewish life on campus. We also have an active Chabad chapter on campus and a strong partnership with the Jewish Theological Seminary where we share joint academic programs. Our Palestinian students and faculty have also been affected as their families and friends suffer through a humanitarian crisis. I have heard from them too in my listening sessions and we have made support available to them through our student affairs network, mental health and well- being services, and doxing support group. I recognize that a problem as deeply entrenched and critical as antisemitism must be addressed with consistent communication between University leadership and our broader community. It was therefore important to me to open a direct channel of communication with
5 students to ensure we were incorporating a diverse array of feedback. I have had about 20 meetings with groups of students to discuss these issues. In the months after the October 7 attack, I began hosting smaller biweekly listening forums where students can share their feedback directly. These sessions are meant to be safe, respectful, and compassionate spaces for students to express their thoughts and to engage in meaningful dialogue. So far, more than 90 students have participated. I plan on continuing with these listening forums which are often emotional but incredibly valuable opportunities for students to have dialogue across different perspectives. Upholding Freedom of Speech and Ensuring Members of Our Community Feel Safe and Welcome Today, the war in Gaza is creating deep divisions and has sparked intense debate. As a global university, it is our role to foster an environment devoted to examining and to debating difficult issues that affect our world, including this conflict. In fact, at times like these, Columbia's mission—to support research and teaching on global issues—is even more critical. Columbia is committed to “ensur[ing] that all members of our community may engage in our cherished traditions of free expression and open debate."¹ Freedom of speech is a core democratic principle and foundational to scholarship and research. It allows our differences to be a source of strength, a critical part of what makes university communities like Columbia excel as incubators of knowledge and innovation. We believe that Columbia's role is not to shield individuals from positions that they find unwelcome, but instead to create an environment where different viewpoints can be tested and challenged. We understand that viewpoints will inevitably conflict, and therefore, to fulfill Columbia's mission, we must uphold both freedom of speech and mutual respect. We will not allow freedom of expression to be used to countenance intimidation or discrimination. It is essential that debates and disagreements at Columbia are rooted in academic rigor and civil discourse. No political debate can justify antisemitism or any form of bigotry; protests and debates should not make Jewish students or any other member of our community feel unsafe. Making Long Term Progress through Education I believe education is the ultimate solution to eradicating antisemitism and all forms of hate. That view is supported by research from the Anti-Defamation League. My approach to the task is informed, in part, by my own experiences. I was born in Alexandria, Egypt. When I was four years old, my family's land and property were seized by the Egyptian government as part of political upheaval in Egypt. We fled to the United States with little money and few possessions. Seemingly overnight, I was an immigrant growing up in the American South—Georgia, Florida, and North Carolina—during the desegregation era and amid significant racial tensions. My public schooling allowed me to engage with and learn from people with a wide array of backgrounds and experience overcoming discrimination firsthand. That experience gave me the 1 Rules of University Conduct, COLUM. UNIV., https://universitypolicies.columbia.edu/content/rules-university- conduct.
6 foundation to work effectively in diverse environments with mutual respect, which was key for my later professional endeavors. I have worked in international organizations for more than 25 years, where people from various nationalities, religions, and backgrounds have worked side-by-side to solve critical issues for the world. I am proud to have been part of the leadership teams of the World Bank, the International Monetary Fund, and the Bank of England; and proud to have led the United Kingdom's Department for International Development and the London School of Economics. These experiences have shown me that education is the single most powerful tool to make our communities and our world better. And, amid these challenging times, I believe it is important for the Columbia community to realize the powerful impact of our core educational mission. We have taken concrete action on this front. In December, we launched Values in Action, a set of initiatives to rededicate ourselves to fostering dialogue and civil debate, especially among those with differing opinions and viewpoints, with mutual respect. Our new Dialogue Across Difference (DxD) program is a key part of Values in Action. DxD has been holding programming, providing professional development opportunities for faculty hoping to facilitate difficult conversations in our community, and providing seed grants which will permit students, faculty, and staff hoping to create their own programs focused on facilitating dialogue across difference. in DxD has already hosted events focused on facilitating effective and respectful dialogues amongst those with differing opinions. The events have covered a diverse range of topics, including a discussion detailing the history of Middle East conflicts and the chances for peace the region, a conversation about divisions in our democracy, and a discussion on artificial intelligence and its effects on future public dialogues and freedom of speech. These events were wonderful learning experiences on a wide range of topics and demonstrations that those with differing opinions can have productive debates and discussions—even regarding high-stakes issues. In addition to these community-wide events, the University is providing professional development and training opportunities for faculty through the DxD program. In January and February of this year, DxD trained Columbia faculty on “Having Difficult Conversations” and “Employing Empathetic Objectivity in the Classroom.” DxD also partnered with an organization outside the University to provide skills trainings to Columbia staff, aimed at responding to the Israeli-Palestinian conflict, de-escalating situations that become too heated, and facilitating conversations despite difference. Finally, the DxD program provides funding to support faculty and students who want to create their own partnerships and programming to support positive conversations across differences. This will allow individuals throughout our community to play an active role in building productive bridges across difference and promote more beneficial conversations and collaboration. Although this program is still young, we are pleased with the incredible progress that has been made, and we look forward to continued growth and collaboration fostered by DxD in the coming months and years.
7 * * * It is an unfortunate reality that antisemitism has existed for about 2,000 years. It is an ancient, but terribly resilient, form of hatred. One would hope that by the twenty-first century, antisemitism would have been relegated to the dustbin of history, but it has not. The antisemitism that Jewish people have experienced on campuses and in cities across our nation, including our own, in the past few months is both real and dangerous. To confront this challenge, I believe we can look to periods in our history where antisemitism has been in abeyance. Those periods were characterized by enlightened leadership, inclusive cultures, and clarity about rights and obligations. These are the values I have learned throughout my professional career, and values I am committed to fostering at Columbia. I know together we will emerge as a stronger and more cohesive community. Thank you for the opportunity to address these critically important issues. I look forward to your comments and questions.
IMAGES
VIDEO
COMMENTS
Watson Speech to Text Demo - IBM
Accurately convert voice to text in over 125 languages and variants using Google AI and an easy-to-use API.
Edit and export your text. Enter Correct mode (press the C key) to edit, apply formatting, highlight sections, and leave comments on your speech-to-text transcript. Filler words will be highlighted, which you can remove by right clicking to remove some or all instances. When ready, export your text as HTML, Markdown, Plain text, Word file, or ...
Speechnotes is a reliable and secure web-based speech-to-text tool that enables you to quickly and accurately transcribe your audio and video recordings, as well as dictate your notes instead of typing, saving you time and effort. With features like voice commands for punctuation and formatting, automatic capitalization, and easy import/export ...
Make spoken audio actionable. Quickly and accurately transcribe audio to text in more than 100 languages and variants. Customize models to enhance accuracy for domain-specific terminology. Get more value from spoken audio by enabling search or analytics on transcribed text or facilitating action—all in your preferred programming language.
Optimize audio files. Shows you how to perform a preflight check on audio files that you're preparing for use with Speech-to-Text. Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers ...
Watson Speech to Text is an API that transcribes speech to text in a variety of languages. It's available as SaaS or for self-hosting. ... Go to the live demo Partner with IBM Accelerate your business growth as an Independent Software Vendor (ISV) by innovating with IBM. Partner with us to deliver enhanced commercial solutions embedded with ...
Explore, try out, and view sample code for some of common use cases using Azure Speech Services features like speech to text and text to speech. Captioning with speech to text Convert the audio content of TV broadcast, webcast, film, video, live event or other productions into text to make your content more accessible to your audience.
Accurately convert voice to text in over 125 languages and variants by applying Google's powerful machine learning models with an easy-to-use API.
Speech to Text is a free online tool that automatically converts spoken words from your audio recordings into written text. This feature can save you hours of manual transcription, making it perfect for journalists, researchers, students, and business professionals.
60 minutes of speech-to-text for 12 months. Extract key business insights from customer calls, video files, clinical conversations, and more. Improve business outcomes with state of the art speech recognition models that are fully managed and continuously trained. Enhance accuracy with custom models that understand your domain specific vocabulary.
TTS for Education Talk to sales & request a free demo. TTS for Business Talk to sales & request a free demo; AI Voice Generator. Al Voice Over Convert your content into a voice over and download it as an .MP3, ... Speech to text technology is at the heart of modern transcription software. This technology uses advanced speech recognition to ...
The Speech to Text service converts the human voice into the written word. The service uses deep-learning AI to apply knowledge of grammar, language structure, and the composition of audio and voice signals to accurately transcribe human speech. It can be used in applications such as voice-automated chatbots, analytic tools for customer-service call centers, and multi-media transcription ...
Choose audio files. Drag and drop audio file (s) here or. Browse for a file. (One audio file limit with free trial) Or. record audio with a microphone. (1:00 limit with free trial) Audio files. Your audio files will appear here.
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech-to-text capability to their applications. Try Transcribe Docs. Amazon Polly. Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk, and build entirely new categories of speech ...
Remove ads & unlock premium features In addition: Dictate on ANY website One tap to insert pre-typed texts On ANY website across the web! Speech to Text Online Notepad. Free. The Professional Speech Recognition Text Editor. Distraction-free, Fast, Easy to Use & Free Web App for Dictation & Typing.
The Audio API provides two speech to text endpoints, transcriptions and translations, based on our state-of-the-art open source large-v2 Whisper model.They can be used to: Transcribe audio into whatever language the audio is in. Translate and transcribe the audio into english.
After a few moments, the Google Cloud console opens in this tab. Task 1. Create an API key. Since you use curl to send a request to the Speech-to-Text API, you need to generate an API key to pass in your request URL. To create an API key, on the Navigation menu () click APIs & services > Credentials.
Get started Request a Demo. RECORD AUDIO. Upload file audio . Identified text. Powered by deep learning and the speech recognition technology, FPT.AI Speech to Text (STT) service offers an easy-to-use cloud-based API for developers to transcribe spoken words into written words. The service can be integrated with various business applications.
speech-to-text-demo. A sample browser app for Bluemix that use the speech-to-text service, fetching a token via Node.js. Explore this online speech-to-text-demo sandbox and experiment with it yourself using our interactive online playground. You can use it as a template to jumpstart your development with this pre-built solution.
Try our Text-to-Speech Demo. Select your options below to hear samples of ReadSpeaker's TTS voices. Kayla. English (US) Female. Hello, my name is Kayla, I'm one of the voices that you can use to speech enable your website. When I'm reading your text it sounds like this.
Turn text into natural-sounding speech in 220+ voices across 40+ languages and variants with an API powered by Google's machine learning technology.
Parler-TTS is a lightweight text-to-speech (TTS) model that can generate high-quality, natural sounding speech in the style of a given speaker (gender, pitch, speaking style, etc). It is a reproduction of work from the paper Natural language guidance of high-fidelity text-to-speech with synthetic annotations by Dan Lyth and Simon King, from ...
Use the sample text or enter your own text in English. Adjust speed. 0.2x 1.7x. Adjust pitch. 0%. Play voice. This system is for demonstration purposes only and is not intended to process Personal Data. No Personal Data is to be entered into this system as it may not have the necessary controls in place to meet the requirements of the General ...
We're expanding the input modalities for Gemini 1.5 Pro to include audio (speech) understanding in both the Gemini API and Google AI Studio. Additionally, Gemini 1.5 Pro is now able to reason across both image (frames) and audio (speech) for videos uploaded in Google AI Studio, and we look forward to adding API support for this soon.
Use our characters in your site or app.Try It for FREE. Try SitePal's talking avatars with our free Text to Speech online demo. Our virtual characters read text aloud naturally in over 25 languages. Use our text to speach (txt 2 speech) tool to test speech voices. No speaking software needed.
Text to speech / Speech synthesis broken on mobile Edge browser Describe the bug Speech synthesis is broken. It used to work and find voices in past verions. At some point in time it stopped working - I can no lonver get voices and therefore not use speech synthesis / tts. ... Go to any live demo, e.g.: EasySpeech - Cross browser Speech ...
New York, New York. Thanks so much, Jason. It's great to be with all of you today. I want to commend the Columbia Center on Global Energy Policy for everything you do to advance the policy ...
2 ensure safety on our campus. Trying to reconcile the free speech rights of those who want to protest and the rights of Jewish students to be in an environment free of harassment or ...
Return to text. 11. See Barlevy (2011) for an accessible survey and Tetlow and von zur Muehlen (2001) for a more technical treatment. Return to text. 12. Söderstöm (2002) establishes the result for the Bayesian case. Tetlow (2019) is a simple demonstration of that case alongside an ambiguity aversion case.