data mining Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords

Distance Based Pattern Driven Mining for Outlier Detection in High Dimensional Big Dataset
Detection of outliers or anomalies is one of the vital issues in pattern-driven data mining. Outlier detection detects the inconsistent behavior of individual objects. It is an important sector in the data mining field with several different applications such as detecting credit card fraud, hacking discovery and discovering criminal activities. It is necessary to develop tools used to uncover the critical information established in the extensive data. This paper investigated a novel method for detecting cluster outliers in a multidimensional dataset, capable of identifying the clusters and outliers for datasets containing noise. The proposed method can detect the groups and outliers left by the clustering process, like instant irregular sets of clusters (C) and outliers (O), to boost the results. The results obtained after applying the algorithm to the dataset improved in terms of several parameters. For the comparative analysis, the accurate average value and the recall value parameters are computed. The accurate average value is 74.05% of the existing COID algorithm, and our proposed algorithm has 77.21%. The average recall value is 81.19% and 89.51% of the existing and proposed algorithm, which shows that the proposed work efficiency is better than the existing COID algorithm.
Implementation of Data Mining Technology in Bonded Warehouse Inbound and Outbound Goods Trade
For the taxed goods, the actual freight is generally determined by multiplying the allocated freight for each KG and actual outgoing weight based on the outgoing order number on the outgoing bill. Considering the conventional logistics is insufficient to cope with the rapid response of e-commerce orders to logistics requirements, this work discussed the implementation of data mining technology in bonded warehouse inbound and outbound goods trade. Specifically, a bonded warehouse decision-making system with data warehouse, conceptual model, online analytical processing system, human-computer interaction module and WEB data sharing platform was developed. The statistical query module can be used to perform statistics and queries on warehousing operations. After the optimization of the whole warehousing business process, it only takes 19.1 hours to get the actual freight, which is nearly one third less than the time before optimization. This study could create a better environment for the development of China's processing trade.
Multi-objective economic load dispatch method based on data mining technology for large coal-fired power plants
User activity classification and domain-wise ranking through social interactions.
Twitter has gained a significant prevalence among the users across the numerous domains, in the majority of the countries, and among different age groups. It servers a real-time micro-blogging service for communication and opinion sharing. Twitter is sharing its data for research and study purposes by exposing open APIs that make it the most suitable source of data for social media analytics. Applying data mining and machine learning techniques on tweets is gaining more and more interest. The most prominent enigma in social media analytics is to automatically identify and rank influencers. This research is aimed to detect the user's topics of interest in social media and rank them based on specific topics, domains, etc. Few hybrid parameters are also distinguished in this research based on the post's content, post’s metadata, user’s profile, and user's network feature to capture different aspects of being influential and used in the ranking algorithm. Results concluded that the proposed approach is well effective in both the classification and ranking of individuals in a cluster.
A data mining analysis of COVID-19 cases in states of United States of America
Epidemic diseases can be extremely dangerous with its hazarding influences. They may have negative effects on economies, businesses, environment, humans, and workforce. In this paper, some of the factors that are interrelated with COVID-19 pandemic have been examined using data mining methodologies and approaches. As a result of the analysis some rules and insights have been discovered and performances of the data mining algorithms have been evaluated. According to the analysis results, JRip algorithmic technique had the most correct classification rate and the lowest root mean squared error (RMSE). Considering classification rate and RMSE measure, JRip can be considered as an effective method in understanding factors that are related with corona virus caused deaths.
Exploring distributed energy generation for sustainable development: A data mining approach
A comprehensive guideline for bengali sentiment annotation.
Sentiment Analysis (SA) is a Natural Language Processing (NLP) and an Information Extraction (IE) task that primarily aims to obtain the writer’s feelings expressed in positive or negative by analyzing a large number of documents. SA is also widely studied in the fields of data mining, web mining, text mining, and information retrieval. The fundamental task in sentiment analysis is to classify the polarity of a given content as Positive, Negative, or Neutral . Although extensive research has been conducted in this area of computational linguistics, most of the research work has been carried out in the context of English language. However, Bengali sentiment expression has varying degree of sentiment labels, which can be plausibly distinct from English language. Therefore, sentiment assessment of Bengali language is undeniably important to be developed and executed properly. In sentiment analysis, the prediction potential of an automatic modeling is completely dependent on the quality of dataset annotation. Bengali sentiment annotation is a challenging task due to diversified structures (syntax) of the language and its different degrees of innate sentiments (i.e., weakly and strongly positive/negative sentiments). Thus, in this article, we propose a novel and precise guideline for the researchers, linguistic experts, and referees to annotate Bengali sentences immaculately with a view to building effective datasets for automatic sentiment prediction efficiently.
Capturing Dynamics of Information Diffusion in SNS: A Survey of Methodology and Techniques
Studying information diffusion in SNS (Social Networks Service) has remarkable significance in both academia and industry. Theoretically, it boosts the development of other subjects such as statistics, sociology, and data mining. Practically, diffusion modeling provides fundamental support for many downstream applications (e.g., public opinion monitoring, rumor source identification, and viral marketing). Tremendous efforts have been devoted to this area to understand and quantify information diffusion dynamics. This survey investigates and summarizes the emerging distinguished works in diffusion modeling. We first put forward a unified information diffusion concept in terms of three components: information, user decision, and social vectors, followed by a detailed introduction of the methodologies for diffusion modeling. And then, a new taxonomy adopting hybrid philosophy (i.e., granularity and techniques) is proposed, and we made a series of comparative studies on elementary diffusion models under our taxonomy from the aspects of assumptions, methods, and pros and cons. We further summarized representative diffusion modeling in special scenarios and significant downstream tasks based on these elementary models. Finally, open issues in this field following the methodology of diffusion modeling are discussed.
The Influence of E-book Teaching on the Motivation and Effectiveness of Learning Law by Using Data Mining Analysis
This paper studies the motivation of learning law, compares the teaching effectiveness of two different teaching methods, e-book teaching and traditional teaching, and analyses the influence of e-book teaching on the effectiveness of law by using big data analysis. From the perspective of law student psychology, e-book teaching can attract students' attention, stimulate students' interest in learning, deepen knowledge impression while learning, expand knowledge, and ultimately improve the performance of practical assessment. With a small sample size, there may be some deficiencies in the research results' representativeness. To stimulate the learning motivation of law as well as some other theoretical disciplines in colleges and universities has particular referential significance and provides ideas for the reform of teaching mode at colleges and universities. This paper uses a decision tree algorithm in data mining for the analysis and finds out the influencing factors of law students' learning motivation and effectiveness in the learning process from students' perspective.
Intelligent Data Mining based Method for Efficient English Teaching and Cultural Analysis
The emergence of online education helps improving the traditional English teaching quality greatly. However, it only moves the teaching process from offline to online, which does not really change the essence of traditional English teaching. In this work, we mainly study an intelligent English teaching method to further improve the quality of English teaching. Specifically, the random forest is firstly used to analyze and excavate the grammatical and syntactic features of the English text. Then, the decision tree based method is proposed to make a prediction about the English text in terms of its grammar or syntax issues. The evaluation results indicate that the proposed method can effectively improve the accuracy of English grammar or syntax recognition.
Export Citation Format
Share document.
Subscribe to the PwC Newsletter
Join the community, add a new evaluation result row, data mining.
2 papers with code • 0 benchmarks • 0 datasets
Benchmarks Add a Result

Most implemented papers
A methodology based on trace-based clustering for patient phenotyping.
antoniolopezmc/A-methodology-based-on-Trace-based-clustering-for-patient-phenotyping • Knowledge-Based Systems 2021
Methods: We propose a new unsupervised machine learning technique, denominated as Trace-based clustering, and a 5-step methodology in order to support clinicians when identifying patient phenotypes.
VLSD—An Efficient Subgroup Discovery Algorithm Based on Equivalence Classes and Optimistic Estimate
antoniolopezmc/subgroups • Algorithms 2023
Subgroup Discovery (SD) is a supervised data mining technique for identifying a set of relations (subgroups) among attributes from a dataset with respect to a target attribute.
Data Mining and Modeling
The proliferation of machine learning means that learned classifiers lie at the core of many products across Google. However, questions in practice are rarely so clean as to just to use an out-of-the-box algorithm. A big challenge is in developing metrics, designing experimental methodologies, and modeling the space to create parsimonious representations that capture the fundamentals of the problem. These problems cut across Google’s products and services, from designing experiments for testing new auction algorithms to developing automated metrics to measure the quality of a road map.
Data mining lies at the heart of many of these questions, and the research done at Google is at the forefront of the field. Whether it is finding more efficient algorithms for working with massive data sets, developing privacy-preserving methods for classification, or designing new machine learning approaches, our group continues to push the boundary of what is possible.
Recent Publications
Some of our teams.
Algorithms & optimization
Climate and sustainability
Graph mining
We're always looking for more talented, passionate people.


An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Int J Environ Res Public Health
Data Mining in Healthcare: Applying Strategic Intelligence Techniques to Depict 25 Years of Research Development
Maikel luis kolling.
1 Graduate Program of Industrial Systems and Processes, University of Santa Cruz do Sul, Santa Cruz do Sul 96816-501, Brazil; [email protected] (M.L.K.); [email protected] (M.K.S.)
Leonardo B. Furstenau
2 Department of Industrial Engineering, Federal University of Rio Grande do Sul, Porto Alegre 90035-190, Brazil; rb.csinu.2xm@uanetsrufodranoel
Michele Kremer Sott
Bruna rabaioli.
3 Department of Medicine, University of Santa Cruz do Sul, Santa Cruz do Sul 96816-501, Brazil; moc.liamg@iloiabbaranurb
Pedro Henrique Ulmi
4 Department of Computer Science, University of Santa Cruz do Sul, Santa Cruz do Sul 96816-501, Brazil; [email protected]
Nicola Luigi Bragazzi
5 Laboratory for Industrial and Applied Mathematics (LIAM), Department of Mathematics and Statistics, York University, Toronto, ON M3J 1P3, Canada
Leonel Pablo Carvalho Tedesco
Associated data.
Not applicable.
In order to identify the strategic topics and the thematic evolution structure of data mining applied to healthcare, in this paper, a bibliometric performance and network analysis (BPNA) was conducted. For this purpose, 6138 articles were sourced from the Web of Science covering the period from 1995 to July 2020 and the SciMAT software was used. Our results present a strategic diagram composed of 19 themes, of which the 8 motor themes (‘NEURAL-NETWORKS’, ‘CANCER’, ‘ELETRONIC-HEALTH-RECORDS’, ‘DIABETES-MELLITUS’, ‘ALZHEIMER’S-DISEASE’, ‘BREAST-CANCER’, ‘DEPRESSION’, and ‘RANDOM-FOREST’) are depicted in a thematic network. An in-depth analysis was carried out in order to find hidden patterns and to provide a general perspective of the field. The thematic network structure is arranged thusly that its subjects are organized into two different areas, (i) practices and techniques related to data mining in healthcare, and (ii) health concepts and disease supported by data mining, embodying, respectively, the hotspots related to the data mining and medical scopes, hence demonstrating the field’s evolution over time. Such results make it possible to form the basis for future research and facilitate decision-making by researchers and practitioners, institutions, and governments interested in data mining in healthcare.
1. Introduction
Deriving from Industry 4.0 that pursues the expansion of its autonomy and efficiency through data-driven automatization and artificial intelligence employing cyber-physical spaces, the Healthcare 4.0 portrays the overhaul of medical business models towards a data-driven management [ 1 ]. In akin environments, substantial amounts of information associated to organizational processes and patient care are generated. Furthermore, the maturation of state-of-the-art technologies, namely, wearable devices, which are likely to transform the whole industry through more personalized and proactive treatments, will lead to a noteworthy increase in user patient data. Moreover, the forecast for the annual global growth in healthcare data should exceed soon 1.2 exabytes a year [ 1 ]. Despite the massive and growing volume of health and patient care information [ 2 ], it is still, to a great extent, underused [ 3 ].
Data mining, a subfield of artificial intelligence that makes use of vast amounts of data in order to allow significant information to be extracted through previously unknown patterns, has been progressively applied in healthcare to assist clinical diagnoses and disease predictions [ 2 ]. This information has been known to be rather complex and difficult to analyze. Furthermore, data mining concepts can also perform the analysis and classification of colossal bulks of information, grouping variables with similar behaviors, foreseeing future events, amid other advantages for monitoring and managing health systems ceaselessly seeking to look after the patients’ privacy [ 4 ]. The knowledge resulting from the application of the aforesaid methods may potentially improve resource management and patient care systems, assist in infection control and risk stratification [ 5 ]. Several studies in healthcare have explored data mining techniques to predict incidence [ 6 ] and characteristics of patients in pandemic scenarios [ 7 ], identification of depressive symptoms [ 8 ], prediction of diabetes [ 9 ], cancer [ 10 ], scenarios in emergency departments [ 11 ], amidst others. Thus, the utilization of data mining in health organizations ameliorates the efficiency of service provision [ 12 ], quality of decision making, and reduces human subjectivity and errors [ 13 ].
The understanding of data mining in the healthcare sector is, in this context, vital and some researchers have executed bibliometric analyses in the field with the intention of investigating the challenges, limitations, novel opportunities, and trends [ 14 , 15 , 16 , 17 ]. However, at the time of this study, there were no published works that provided a complete analysis of the field using a bibliometric performance and network analysis (BPNA) (see Table 1 . In the light of this, we have defined three research questions:
- RQ1: What are the strategic themes of data mining in healthcare?
- RQ2: How is the thematic evolution structure of data mining in healthcare?
- RQ3: What are the trends and opportunities of data mining in healthcare for academics and practitioners?
Existing bibliometric analysis of data mining in healthcare in Web of Science (WoS).
Thus, with the objective to lay out a superior understanding of the data mining usage in the healthcare sector and to answer the defined research questions, we have performed a bibliometric performance and network analysis (BPNA) to set fourth an overview of the area. We used the Science Mapping Analysis Software Tool (SciMAT), a software developed by Cobo et al. [ 18 ] with the purpose of identifying strategic themes and the thematic evolution structure of a given field, which can be used as a strategic intelligence tool. The strategic intelligence, an approach that can enhance decision-making in terms of science and technology trends [ 19 , 20 , 21 , 22 , 23 , 24 , 25 , 26 , 27 ], can help researchers and practitioners to understand the area and devise new ideas for future works as well as to identify the trends and opportunities of data mining in healthcare.
This research is structured as follows: Section 2 highlights the methodology and the dataset. Section 3 presents the bibliometric performance of data mining in healthcare. In Section 4 , the strategic diagram presents the most relevant themes according to our bibliometric indicators as well as the thematic network structure of the motor themes and the thematic evolution structure, which provide a complete overview of data mining over time. Section 5 presents the conclusions, limitations, and suggestions for future works.
2. Methodology and Dataset
Attracting attention from companies, universities, and scientific journals, bibliometric analysis enhances decision-making by providing a reliable method to collect information from databases, to transform the aforementioned data into knowledge, and to stimulate wisdom development. Furthermore, the techniques of bibliometric analysis can provide higher and different perspectives of scientific production by using advanced measurement tools and methods to depict how authors, works, journals and institutions are advancing in a specific field of research through the hidden patterns that are embedded in large datasets.
The existing works on bibliometric analysis of data mining in health care in the Web of Science are shown in Table 1 , where it is depicted that only three studies have been performed and the differences between these approaches and this work are explained.
2.1. Methodology
For this study we have applied BPNA, a method that combines science mapping with performance analysis, to the field of data mining in healthcare with the support of the SciMAT software. This methodology has been chosen in view of the fact that such a combination, in addition to assisting decision-making for academics and practitioners, allows us to perform a deep investigation into the field of research by giving a new perspective of its intricacies. The BPNA conducted in this paper was composed of four steps outlined below.
2.1.1. Discovery of Research Themes
The themes were identified using a frequency and network reduction of keywords. In this process, the keywords were firstly normalized using the Salton’s Cosine, a correlation coefficient, and then clustered through the simple center algorithm. Finally, the thematic evolution structure co-word network was normalized using the equivalence index.
2.1.2. Depicting Research Themes
The previously identified themes were then plotted on a bi-dimensional diagram composed of four quadrants, in which the “vertical axis” characterizes the density (D) and the “horizontal axis” characterizes the centrality (C) of the theme [ 28 , 29 ] ( Figure 1 a) [ 18 , 20 , 25 , 30 , 31 , 32 , 33 ].

Strategic diagram ( a ). Thematic network structure ( b ). Thematic evolution structure ( c ).
- (a) First quadrant—motor themes: trending themes for the field of research with high development.
- (b) Second quadrant—basic and transversal themes: themes that are inclined to become motor themes in the future due to their high centrality.
- (c) Third quadrant—emerging or declining themes: themes that require a qualitative analysis to define whether they are emerging or declining.
- (d) Fourth quadrant—highly developed and isolated themes: themes that are no longer trending due to a new concept or technology.
2.1.3. Thematic Network Structure and Detection of Thematic Areas
The results were organized and structured in (a) a strategic diagram (b) a thematic network structure of motor themes, and (c) a thematic evolution structure. The thematic network structure ( Figure 1 b) represents the co-occurrence between the research themes and underlines the number of relationships (C) and internal strength among them (D). The thematic evolution structure ( Figure 1 c) provides a proper picture of how the themes preserve a conceptual nexus throughout the following sub-periods [ 23 , 34 ]. The size of the clusters is proportional to the number of core documents and the links indicate co-occurrence among the clusters. Solid lines indicate that clusters share the main theme, and dashed lines represent the shared cluster elements that are not the name of the themes [ 35 ]. The thickness of the lines is proportional to the inclusion index, which indicates that the themes have elements in common [ 35 ]. Furthermore, in the thematic network structure the themes were then manually classified between data mining techniques and medical research concepts.
2.1.4. Performance Analysis
The scientific contribution was measured by analyzing the most important research themes and thematic areas using the h-index, sum of citations, core documents centrality, density, and nexus among themes. The results can be used as a strategic intelligence approach to identify the most relevant topics in the research field.
2.2. Dataset
Composed of 6138 non-duplicated articles and reviews in English language, the dataset used in this work was sourced from the Web of Science (WoS) database utilizing the following query string (“data mining” and (“health*” OR “clinic*” OR “medic* OR “disease”)). The documents were then processed and had their keywords, both the author’s and the index controlled and uncontrolled terms, extracted and grouped in accordance with their meaning. In order to remove duplicates and terms which had less than two occurrences in the documents, a preprocessing step was applied to the authors, years, publication dates, and keywords. For instance, the preprocessing has reduced the total number of keywords from 21,838 to 5310, thus improving the bibliometric analysis clarity. With the exception of the strategic diagram that was plotted utilizing a single period (1995–July 2020), in this study, the timeline was divided into three sub-periods: 1995–2003, 2004–2012, and 2013–July 2020.
Subsequently, a network reduction was applied in order to exclude irrelevant words and co-occurrences. For the network extraction we wanted to identify co-occurrence among words. For the mapping process, we used a simple center algorithm. Finally, a core mapper was used, and the h-index and sum citations were selected. Figure 2 shows a good representation of the steps of the BPNA.

Workflow of the bibliometric performance and network analysis (BPNA).
3. Bibliometric Performance of Data Mining in Healthcare
In this section, we measured the performance of the field of data mining in healthcare in terms of publications and citations over time, the most productive and cited researchers, as well as productivity of scientific journals, institutions, countries, and most important research areas in the WoS. To do this, we used indicators such as: number of publications, sum of citations by year, journal impact factor (JIF), geographic distribution of publications, and research field. For this, we examined the complete period (1995 to July 2020).
3.1. Publications and Citations Overtime
Figure 3 shows the performance analysis of publications and citations of data mining in healthcare over time from 1995 to July 2020 in the WoS. The first sub-period (1995–2003) shows the beginning of the research field with 316 documents and a total of 13,483 citations. Besides, the first article in the WoS was published by Szolovits (1995) [ 36 ] who presented a tutorial for handling uncertainty in healthcare and highlighted the importance to develop data mining techniques in order to assist the healthcare sector. This sub-period shows a slightly increasing number of citations until 2003 and the year with the highest number of citations was 2002.

Number of publications over time (1995–July 2020).
The slightly increasing number continues from the first sub-period to the second subperiod (2004–2013) with a total of 1572 publications and 55,734 citations. The year 2006 presents the highest number of citations mainly due to the study of Fawcett [ 37 ] which attracted 7762 citations. The author introduced the concept of Receiver Operating Characteristics (ROC). This technique is widely used in data mining to assist medical decision-making.
From the second to the third sub-period, it is possible to observe a huge increase in the number of publications (4250 publications) and 41,821 citations. This elevated increase may have occurred due to the creation of strategies to implement emerging technologies in the healthcare sector in order to move forward with the third digital revolution in healthcare, the so-called Healthcare 4.0 [ 1 , 38 ]. Furthermore, although the citations are showing a positive trend, it is still possible to observe a downward trend from 2014 to 2020. This may happen, as Wang [ 39 ] highlights, due to the fact that a scientific document needs three to seven years to reach its peak point of citation [ 34 ]. Therefore, this is not a real trend.
3.2. Most Productive and Cited Authors
Table 2 displays the most productive and cited authors from 1995 to July 2020 of data mining in healthcare in the WoS. Leading as the most productive researcher in the field of data mining in healthcare is Li, Chien-Feng, a pathologist at Chi Mei Hospital which is sixth-ranked in publication numbers. He dedicates his studies to the molecular diagnosis of cancer with innovative technologies. In the sequence, Acharya, U. Rajendra, ranked in the top 1% of highly cited researchers in five consecutive years (2016, 2017, 2018, 2019, and 2020) in computer science according to Thomson’s essential science indicators, shares second place with Chung, Kyungyong from the Division of Engineering and Computer Science at the Kyonggi University in Su-won-si, South Korea. On the other hand, Bate, Andrew C., a member of the Food and Drug Administration (FDA) Science Council of Pharmacovigilance Subcommittee, which is the fourth-ranked institution in publication count as the most cited researcher with 945 citations. Subsequently, Lindquist, Marie, who monitors global pharmacovigilance and data management development at the World Health Organization (WHO), is ranked second with 943 citations. Last but not least, Edwards, E.R., an orthopedic surgeon at the Royal Australasian College of Surgeons is ranked third with 888 citations. Notably, this study does not demonstrate a direct correlation between the number of publications and the number of citations.
Most Cited/Productive authors from 1995 to July 2020.
3.3. Productivity of Scientific Journals, Universities, Countries and Most Important Research Fields
Table 3 shows the journals that publish studies related to data mining in healthcare. PLOS One is the first ranked with 124 publications, followed by Expert Systems with Applications with 105, and Artificial Intelligence in Medicine with 75. On the other hand, the journal Expert Systems with Applications is the journal that had the highest Journal Impact Factor (JIF) from 2019–2020.
Journals that publish studies to data mining in healthcare.
Table 4 shows the most productive institutions and the most productive countries. The first ranked is Columbia University followed by U.S. FDA Registration and Harvard University. In terms of country productivity, United States is the first in the rank, followed by China and England. In comparison with Table 2 , it is possible to notice that the most productive author is not related to the most productive institutions (Columbia University and U.S. FDA Registration). Besides, the institution with the highest number of publications is in the United States, which is found to be the most productive country.
Institutions and countries that publish studies to data mining in healthcare.
Regarding Columbia University, it is possible to verify its prominence in data mining in healthcare through its advanced data science programs, which are one of the best evaluated and advanced in the world. We highlight the Columbia Data Science Society, an interdisciplinary society that promotes data science at Columbia University and the New York City community.
The U.S. FDA Registration has a data mining council to promote the prioritization and governance of data mining initiatives within the Center for Biological Research and Evaluation to assess spontaneous reports of adverse events after the administration of regulated medical products. In addition, they created an Advanced and Standards-Based Network Analyzer for Clinical Assessment and Evaluation (PANACEA), which supports the application of standards recognition and network analysis for reporting these adverse events. It is noteworthy that the FDA Adverse Events Reporting System (FAERS) database is the main resource that identifies adverse reactions in medications marketed in the United States. A text mining system based on EHR that retrieves important clinical and temporal information is also highlighted along with support for the Cancer Prevention and Control Division at the Centers for Disease Control and Prevention in a big data project.
The Harvard University offers online data mining courses and has a Center for Healthcare Data Analytics created by the need to analyze data in large public or private data sets. Harvard research includes funding and providing healthcare, quality of care, studies on special and disadvantaged populations, and access to care.
Table 5 presents the most important WoS subject research fields of data mining in healthcare from 1995 to July 2020. Computer Science Artificial Intelligence is the first ranked with 768 documents, followed by Medical Informatics with 744 documents, and Computer Science Information Systems with 722 documents.
Most relevant WoS subject categories and research fields.
4. Science Mapping Analysis of Data Mining in Healthcare
In this section the science mapping analysis of data mining in healthcare is depicted. The strategic diagram shows the most relevant themes in terms of centrality and density. The thematic network structure uncovers the relationship (co-occurrence) between themes and hidden patterns. Lastly, the thematic evolution structure underlines the most important themes of each sub-period and shows how the field of study is evolving over time.
4.1. Strategic Diagram Analysis
Figure 4 presents 19 clusters, 8 of which are categorized as motor themes (‘NEURAL-NETWORKS’, ‘CANCER’, ‘ELETRONIC-HEALTH-RECORDS’, ‘DIABETES-MELLITUS’, ‘ADVERSE-DRUG-EVENTS’, ‘BREAST-CANCER’, ‘DEPRESSION’ and ‘RANDOM-FOREST’), 2 as basic and transversal themes (‘CORONARY-ARTERY-DISEASE’ and ‘PHOSPHORYLATION’), 7 as emerging or declining themes (‘PERSONALIZED-MEDICINE’, ‘DATA-INTEGRATION’, ‘INTENSIVE-CARE-UNIT’, ‘CLUSTER-ANALYSIS’, ‘INFORMATION-EXTRACTION’, ‘CLOUD-COMPUTING’ and ‘SENSORS’), and 2 as highly developed and isolated themes (‘ALZHEIMERS-DISEASE’, and ‘METABOLOMICS’).

Strategic diagram of data mining in healthcare (1995–July 2020).
Each cluster of themes was measured in terms of core documents, h-index, citations, centrality, and density. The cluster ‘NEURAL-NETWORKS’ has the highest number of core documents (336) and is ranked first in terms of centrality and density. On the other hand, the cluster ‘CANCER’ is the most widely cited with 5810 citations.
4.2. Thematic Network Structure Analysis of Motor Themes
The motor themes have an important role regarding the shape and future of the research field because they correspond to the key topics to everyone interested in the subject. Therefore, they can be considered as strategic themes in order to develop the field of data mining in healthcare. The eight motor themes are discussed below, and they are displayed below in Figure 5 together with the network structure of each theme.

Thematic network structure of mining in healthcare (1995–July 2020). ( a ) The cluster ‘NEURAL-NETWORKS’. ( b ) The cluster ‘CANCER’. ( c ) The cluster ‘ELECTRONIC-HEALTH-RECORDS’. ( d ) The cluster ‘DIABETES-MELLITUS’. ( e ) The cluster ‘BREAST-CANCER’. ( f ) The cluster ‘ALZHEIMER’S DISEASE’. ( g ) The cluster ‘DEPRESSION’. ( h ) The cluster ‘RANDOM-FOREST’.
4.2.1. Neural Network (a)
The cluster ‘NEURAL-NETWORKS’ ( Figure 5 a) is the first ranked in terms of core documents, h-index, centrality, and density. The ‘NEURAL-NETWORKS’ cluster is strongly influenced by subthemes related to data science algorithms, such as ‘SUPPORT-VECTOR-MACHINE’, ‘DECISION-TREE’, among others. This network represents the use of data mining techniques to detect patterns and find important information correlated to patient health and medical diagnosis. A reasonable explanation for this network might be related to the high number of studies which conducted benchmarking of neural networks with other techniques to evaluate performance (e.g., resource usage, efficiency, accuracy, scalability, etc.) [ 40 , 41 , 42 ]. Besides, the significant size of the cluster ‘MACHINE-LEARNING’ is expected since neural networks is a type of machine learning. On the other hand, the subtheme ‘HEART-DISEASE’ stands out as the single disease in this network, which can be justified by the high number of researches with the goal to apply data mining to support decision-making in heart disease treatment and diagnosis.
4.2.2. Cancer (b)
The cluster ‘CANCER’ ( Figure 5 b) is the second ranked in terms of core documents, h-index, and density. On the other hand, it is the first in terms of citations (5810). This cluster is highly influenced by the subthemes related to the studies of cancer genes mutations, such as ‘BIOMAKERS’, ‘GENE-EXPRESSION’, among others. The use of data mining techniques has been attracting attention and efforts from academics in order to help solve problems in the field of oncology. Cancer is known as the disease that kills the most people in the 21st century due to various environmental pollutions, food pesticides and additives [ 14 ], eating habits, mental health, among others. Thus, controlling any form of cancer is a global strategy and can be enhanced by applying data mining techniques. Furthermore, the subtheme ‘PROSTATE-CANCER’ highlights that the most efforts of data mining applications focused on prostate cancer’s studies. Prostate cancer is the most common cancer in men. Although the benefits of traditional clinical exams for screening (digital rectal examination, the prostate-specific antigen and blood test and transrectal ultrasound), there is still a lack in terms of efficacy to reduce mortality with the use of such tests [ 43 ]. In this sense, data mining may be a suitable solution since it has been used in bioinformatics analyses to understand prostate cancer mutation [ 44 , 45 ] and uncover useful information that can be used for diagnoses and future prognostic tests which enhance both patients and clinical decision-making [ 46 ].
4.2.3. Electronic Health Records (HER—c)
The cluster ‘ELECTRONIC-HEALTH-RECORDS’ ( Figure 5 c) represents the concept in which patient’s health data are stored. Such data are continuously increasing over time, thereby creating a large amount of data (big data) which has been used as input (EHR) for healthcare decision support systems to enhance clinical decision-making. The clusters ‘NATURAL-LANGUAGE-PROCESSING’ and ‘TEXT MINING’ highlight that these mining techniques are the most frequently used with data mining in healthcare. Another pattern that must be highlighted is the considerable density among the clusters ‘SIGNAL-DETECTION’ and ‘PHARMACOVIGILANCE’ which represents the use of data mining to depict a broad range of adverse drug effects and to identify signals almost in real-time by using EHR [ 47 , 48 ]. Besides, the cluster ‘MISSING-DATA’ is related to studies focused on the challenge regarding to incomplete EHR and missing data in healthcare centers, which compromise the performance of several prediction models [ 49 ]. In this sense, techniques to handle missing data have been under improvement in order to move forward with the accurate prediction based on medical data mining applications [ 50 ].
4.2.4. Diabetes Mellitus (DM—d)
Nowadays, DM is one of the most frequent endocrine disorders [ 51 ] and affected more than 450 million people worldwide in 2017 and is expected to grow to 693 million by the year 2045. The same applies for the 850 billion dollars spent just in 2017 by the health sector [ 52 ]. The cluster ‘DIABETES-MELLITUS’ ( Figure 5 d) has a strong association with the risk factor subtheme group (e.g., ‘INSULIN-RESISTENCE’, ‘OBESITY’, ‘BODY-MASS-INDEX’, ‘CARDIOVASCULAR-DISEASE’, and ‘HYPERTENSION’). However, the obesity (cluster ‘OBESITY’) is the major risk factor related to DM, particularly in Type 2 Diabetes (T2D) [ 51 ]. T2D shows a prevalence of 90% of worldwide diabetic patients when compared with T1D and T3D, mainly characterized by insulin resistance [ 51 ]. Thus, this might justify the presence of the clusters ‘TYPE-2-DIABETES’ and ‘INSULIN-RESISTANCE’ which seems to be highly developed by data mining academics and practitioners. The massive number of researches into all facets of DM has led to the formation of huge volumes of EHR, in which the mostly applied data mining technique is the association rules technique. It is used to identify associations among risk factors [ 51 ], thusly justifying the appearance of the cluster ‘ASSOCIATION-RULES’.
4.2.5. Breast Cancer (e)
The cluster ‘BREAST-CANCER’ ( Figure 5 e) presents the most prevalent type of cancer affecting approximately 12.5% of women worldwide [ 53 , 54 ]. The cluster ‘OVEREXPRESSION’ and ‘METASTASIS’ highlights the high number of studies using data mining to understand the association of overexpression of molecules (e.g., MUC1 [ 54 ], TRIM29 [ 55 ], FKBP4 [ 56 ], etc.) with breast cancer metastasis. Such overexpression of molecules also appears in other forms of cancers, justifying the group of subthemes: ‘LUNG CANCER’, ‘GASTRIC-CANCER’, ‘OVARIAN-CANCER’, and ‘COLORECTALCANCER’. Moreover, the cluster ‘IMPUTATION’ highlight efforts to develop imputation techniques (data missingness) for breast cancer record analysis [ 57 , 58 ]. Besides, the application of data mining to depict breast cancer characteristics and their causes and effects has been highly supported by ‘MICROARRAY-DATA’ [ 59 , 60 ], ‘PATHWAY’ [ 61 ], and ‘COMPUTER-AIDED-DIAGNOSIS’ [ 62 ].
4.2.6. Alzheimer’s Disease (AD—f)
The cluster ‘ALZHEIMER’S DISEASE’ ( Figure 5 f) is highly influenced by subthemes related to diseases, such as ‘DEMENTIA’ and ‘PARKINSON’S-DISEASE’. This co-occurrence happens because the AD is a neurodegenerative illness which leads to dementia and Parkinson’s disease. Studies show that the money spent on AD in 2015 was about $828 billion [ 63 ]. In this sense, data mining has been widely used with ‘GENOME-WIDE-ASSOCIATION’ techniques in order to identify genes related to the AD [ 64 , 65 ] and prediction of AD by using data mining in ‘MRI’ Brain images [ 66 , 67 ]. The cluster ‘NF-KAPPA-B’ highlights the efforts to identify associations of NF-κB (factor nuclear kappa B) with AD by using data mining techniques which can be used to advance anti-drug developments [ 68 ].
4.2.7. Depression (g)
The cluster ‘DEPRESSION’ ( Figure 5 g) presents a common disease which affects over 260 million people. In the worst case, it can lead to suicide which is the second leading cause of death in young adults. The cluster ‘DEPRESSION’ is a highly associated cluster. Its connections mostly represent the subthemes that have been the research focus of data mining applications [ 69 ]. The connection between both the sub theme ‘SOCIAL-MEDIA’ and ‘ADOLESCENTS’, especially in times of social isolation, are extremely relevant to help identify early symptoms and tendencies among the population [ 70 ]. Furthermore, the presence of the ‘COMORBIDITY’ and ‘SYMPTONS’ is not surprising given knowledge discovery properties of the data mining field could provide significant insights into the etiology of depression [ 71 ].
4.2.8. Random Forest (h)
An ensemble learning method that is used in this study is the last cluster approach, which, among other things, is used for classification. The presence of the ‘BAYESIAN-NETWORK’ subtheme, supported by the connection between both and the ‘INFERENCE’, might represent another alternative to which the applications in data mining using random forest are benchmarked against [ 72 ]. Since the ‘RANDOM-FOREST’ ( Figure 5 h) cluster has barely passed the threshold from a basic and transversal theme to a motor theme, the works developed under this cluster are not yet as interconnected as the previous one. Thus, the theme with the most representativeness is the ‘AIR-POLLUTION’ in conjunction with ‘POLLUTION’, where studies have been performed in order to obtain ‘RISK-ASSESSMENT’ through the exploration of the knowledge hidden in large databases [ 73 ].
4.3. Thematic Evolution Structure Analysis
The Computer Science’s themes related to data mining and the medical research concepts, depicted, respectively, in the grey and blue areas of the thematic evolution diagram ( Figure 6 ), demonstrates the evolution of the research field over the different sub-periods addressed in this study. In this way, each individual theme relevance is illustrated through its cluster size as well as with its relationships throughout the different sub-periods. Thus, in this section, an analysis of the different trends on themes will be presented to give a brief insight into the factors that might have influenced its evolution. Furthermore, the proceeding analysis will be split into two thematic areas where, firstly, the grey area (practices and techniques related to data mining in healthcare) will be discussed followed by the blue one (health concepts and disease supported by data mining).

Thematic evolution structure of mining in healthcare (1995–July 2020).
4.3.1. Practices and Techniques Related to Data Mining in Healthcare
The cluster ‘KNOWLEDGE-DISCOVERY’ ( Figure 6 , 1995–2012), often known as a synonym for data mining, provides a broader view of the field differing in this way from the algorithm focused theme, that is data mining, where its appearance and, later in the third period, its fading could provide a first insight into the overall evolution of the data mining papers applied to healthcare. The occurrence of the cluster knowledge discovery in the first two periods could demonstrate the focus of the application of the data mining techniques in order to classify and predict conditions in the medical field. This gives rise to a competition with early machine learning techniques that could be potentially evidenced through the presence of the cluster ‘NEURAL-NETWORK’, which the data mining techniques could probably be benchmarked against. The introduction of the ‘FEATURE-SELECTION’, ‘ARTIFICIAL-INTELLIGENCE’, and ‘MACHINE-LEARNING’ clusters together with the fading of ‘KNOWLEDGE-DISCOVERY’ could imply the occurrence of a disruption of the field in the third sub-period that has led to a change in the perspective on the studies.
One instance that could represent such a disruption could have been a well-known paper published by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton [ 74 ], where a novel technique in neural networks was firstly applied to a major image recognition competition. A vast advantage over the other algorithms that have been used was obtained. The connection between the work previously mentioned and its impact on the data mining on healthcare research could be majorly supported by the disappearance of the cluster ‘IMAGE- MINING’ of the second sub-period which has no connections further on. Furthermore, the presence of the clusters ‘MACHINE-LEARNING’, ‘ARTIFICIAL-INTELLIGENCE’, ‘SUPPORT-VECTOR-MACHINES’, and ‘LOGISTIC-REGRESSION’ may be the evidence of a shift of focus on the data mining community for health care where, besides attempting to compete with machine learning algorithms, they are now striving to further improve the results previously obtained with machine learning through data mining. Moreover, given the presence of the colossal feature selection cluster, which circumscribes algorithms that enhance classification accuracy through a better selection of parameters, this trend could be given credence in consequence of its presence since it may be encompassing publications from the formerly stated clusters.
Although still small, the presence of the cluster ‘SECURITY’ in the last sub-period ( Figure 6 , 2013–2020) is, at the very least, relevant given the sensitive data that is handled in the medical space, such as patient’s history and diseases. Above all, the recent leaks of personal information have devised an ever-increasing attention to this topic focusing on, among other things, the de-identification of the personal information [ 75 , 76 , 77 ]. These kind of security processes allow, among others, data mining researchers to make use of the vast sensitive information that is stored in hospitals without any linkage that could associate a person to the data. For instance, the MIMIC Critical Care Database [ 78 ], an example of a de-identified database, has been allowing further research into many diseases and conditions in a secure way that would otherwise have been extremely impaired due to data limitations.
4.3.2. Health Concepts and Disease Supported by Data Mining
The cluster ‘GENE-EXPRESSION’ stands out in the first period and second period ( Figure 6 , 1995–2012) of medical research concepts and establishes strong co-occurrence with the cluster ‘CANCER’ in the third sub-period. This link can be explained by research involving the microarray technology, which makes it possible to detect deletions and duplications in the human genome by analyzing the expression of thousands of genes in different tissues. It is also possible to confirm the importance of genetic screening not only for cancer, but for several diseases, such as ‘ALZHEIMER’ and other brain disorders, thereby assisting in preventive medicine and enabling more efficient treatment plans [ 79 ]. For example, a research was carried out to analyze complex brain disorders such as schizophrenia from expression gene microarrays [ 80 ].
Sequencing technologies have undergone major improvements in recent decades to determine evolutionary changes in genetic, epigenetic mechanisms, and in the ‘MOLECULAR-CLASSIFICATION’, a topic that gained prominence as a cluster in the first period. An example of this can be found in a study published in 2010 which combined a global optimization algorithm called Dongguang Li (DGL) with cancer diagnostic methods based on gene selection and microarray analysis. It performed the molecular classification of colon cancers and leukemia and demonstrated the importance of machine learning, data mining, and good optimization algorithms for analyzing microarray data in the presence of subsets of thousands of genes [ 81 ].
The cluster ‘PROSTATE-CANCER’ in the second period ( Figure 6 , 2004–2012) presents a higher conceptual nexus to ‘MOLECULAR-CLASSIFICATION’ in the first sub-period and the same happens with clusters, such as ‘METASTASIS’, ‘BREAST-CANCER’, and ‘ALZHEIMER’, which appear more recently in the third sub-period. The significant increase in the incidence of prostate cancer in recent years results in the need for greater understanding of the disease in order to increase patient survival, since prostate cancer with metastasis was not well explored, despite having a survival rate much smaller compared to the early stages. In this sense, the understanding of age-specific survival of patients with prostate cancer in a hospital in using machine learning started to gain attention by academics and highlighted the importance of knowing survival after diagnosis for decision making and better genetic counseling [ 82 ]. In addition, the relationship between prostate cancer and Alzheimer’s disease is explained by the fact that the use of androgen deprivation therapy, used to treat prostate cancer, is associated with an increased risk of Alzheimer’s disease and dementia [ 81 ]. Therefore, the risks and benefits of long-term exposure to this therapy must be weighed. Finally, the relationship between prostate cancer and breast cancer in the thematic evolution can be explained due to the fact that studies are showing that men with a family history of breast cancer have a 21% higher risk of developing prostate cancer, including lethal disease [ 83 ].
The cluster ‘PHARMACOVIGILANCE’ appears in the second sub-period ( Figure 6 , 2004–2012) showing a strong co-occurrence with clusters of the third sub-period: ‘ADVERSE-DRUGS-REACTIONS’ and ‘ELECTRONIC-HEALTH-RECORDS’. In recent years, data-mining algorithms have stood out for their usefulness in detecting and screening patients with potential adverse drug reactions and, consequently, they have become a central component of pharmacovigilance, important for reducing the morbidity and mortality associated with the use of medications [ 48 ]. The importance of electronic medical records for pharmacovigilance is evident, which act as a health database and enable drug safety assessors to collect information. In addition, such medical records are also essential to optimize processes within health institutions, ensure more safety of patient data, integrate information, and facilitate the promotion of science and research in the health field [ 84 ]. These characteristics explain the large number of studies of ‘ELECTRONIC-HEALTH-RECORDS’ in the third sub-period and the growth of this theme in recent years, since the world has started to introduce electronic medical records, although currently there are few institutions that still use physical medical records.
The ‘DEPRESSION’ appears in the second sub-period ( Figure 6 , 2004–2012) and remains as a trend in the third sub-period with a significant increase in publications on the topic. It is known that this disease is numerous and is increasing worldwide, but that it still has many stigmas in its treatment and diagnosis. Globalization and the contemporary work environment [ 85 ] can be explanatory factors for the increase in the theme from the 2000s onwards and the COVID-19 pandemic certainly contributed to the large number of articles on mental health published in 2020. In this context, improving the detection of mental disorders is essential for global health, which can be enhanced by applying data mining to quantitative electroencephalogram signals to classify between depressed and healthy people and can act as an adjuvant clinical decision support to identify depression [ 69 ].
5. Conclusions
In this research, we have performed a BPNA to depict the strategic themes, the thematic network structure, and the thematic evolution structure of the data mining applied in healthcare. Our results highlighted several significant pieces of information that can be used by decision-makers to advance the field of data mining in healthcare systems. For instance, our results could be used by editors from scientific journals to enhance decision-making regarding special issues and manuscript review. From the same perspective, healthcare institutions could use this research in the recruiting process to better align the position needs to the candidate’s qualifications based on the expanded clusters. Furthermore, Table 2 presents a series of authors whose collaboration network may be used as a reference to identify emerging talents in a specific research field and might become persons of interest to greatly expand a healthcare institution’s research division. Additionally, Table 3 and Table 4 could also be used by researchers to enhance the alignment of their research intentions and partner institutions to, for instance, encourage the development of data mining applications in healthcare and advance the field’s knowledge.
The strategic diagram ( Figure 4 ) depicted the most important themes in terms of centrality and density. Such results could be used by researchers to provide insights for a better comprehension of how diseases like ‘CANCER’, ‘DIABETES-MELLITUS’, ‘ALZHEIMER’S-DISEASE’, ‘BREAST-CANCER’, ‘DEPRESSION’, and ‘CORONARY-ARTERY-DISEASE’ have made use of the innovations in the data mining field. Interestingly, none of the clusters have highlighted studies related to infectious diseases, and, therefore, it is reasonable to suggest the exploration of data mining techniques in this domain, especially given the global impact that the coronavirus pandemic has had on the world.
The thematic network structure ( Figure 5 ) demonstrates the co-occurrences among clusters and may be used to identify hidden patterns in the field of research to expand the knowledge and promote the development of scientific insights. Even though exhaustive research of the motor themes and their subthemes has been performed in this article, future research must be conducted in order to depict themes from the other quadrants (Q2, Q3, and Q4), especially emerging and declining themes, to bring to light relations between the rise and decay of themes that might be hidden inside the clusters.
The thematic evolution structure showed how the field is evolving over time and presented future trends of data mining in healthcare. It is reasonable to predict that clusters such as ‘NEURAL-NETWORKS’, ‘FEATURE-SELECTION’, ‘EHR’ will not decay in the near future due to their prevalence in the field and, most likely, due to the exponential increase in the amount of patient health that is being generated and stored daily in large data lakes. This unprecedented increase in data volume, which is often of dubious quality, leads to great challenges in the search for hidden information through data mining. Moreover, as a consequence of the ever-increasing data sensitivity, the cluster ‘SECURITY’, which is related to the confidentiality of the patient’s information, is likely to remain growing during the next years as government and institutions further develop structures, algorithms, and laws that aim to assure the data’s security. In this context, blockchain technologies specifically designed to ensure integrity and publicity of de-identified, similarly as it is done by the MIMIC-III (Medical Information Mart for Intensive Care III) [ 78 ], may be crucial to accelerate the advancement of the field by providing reliable information for health researchers across the world. Furthermore, future researches should be conducted in order to understand how these themes will behave and evolve during the next years, and interpret the cluster changes to properly assess the trends here presented. These results could also be used as teaching material for classes, as it provides strategic intelligence applications and the field’s historical data.
In terms of limitations, we used the WoS database since it has index journals with high JIF. Therefore, we suggest to analyze other databases, such as Scopus, PubMed, among others in future works. Besides, we used the SciMAT to perform the analysis and other bibliometric software, such as VOS viewer, Cite Space, Sci2tool, etc., could be used to explore different points of view. Such information will support this study and future works to advance the field of data mining in healthcare.
Author Contributions
Conceptualization, M.L.K., L.B.F., L.P.C.T. and N.L.B.; Data curation, L.B.F.; Formal analysis, L.B.F., B.R., and P.H.U.; Funding acquisition, N.L.B.; Investigation, M.L.K., L.B.F., L.P.C.T. and M.K.S.; Methodology, L.B.F.; Project administration, L.B.F., N.L.B. and L.P.C.T.; Resources, N.L.B.; Supervision, L.B.F., N.L.B. and L.P.C.T.; Validation, N.L.B. and L.P.C.T.; Visualization, N.L.B.; Writing—original draft, L.B.F. and N.L.B.; Writing—review & editing, N.L.B. All authors have read and agreed to the published version of the manuscript.
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—Brazil (CAPES)—Finance Code 001, and in part by the Brazilian Ministry of Health. N.L.B. is partially supported by the CIHR 2019 Novel Coronavirus (COVID-19) rapid research program.
Institutional Review Board Statement
Informed consent statement, data availability statement, conflicts of interest.
The authors declare no conflict of interest.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
50 selected papers in Data Mining and Machine Learning
Here is the list of 50 selected papers in Data Mining and Machine Learning . You can download them for your detailed reading and research. Enjoy!
Data Mining and Statistics: What’s the Connection?
Data Mining: Statistics and More? , D. Hand, American Statistician, 52(2):112-118.
Data Mining , G. Weiss and B. Davison, in Handbook of Technology Management, John Wiley and Sons, expected 2010.
From Data Mining to Knowledge Discovery in Databases , U. Fayyad, G. Piatesky-Shapiro & P. Smyth, AI Magazine, 17(3):37-54, Fall 1996.
Mining Business Databases , Communications of the ACM, 39(11): 42-48.
10 Challenging Problems in Data Mining Research , Q. Yiang and X. Wu, International Journal of Information Technology & Decision Making, Vol. 5, No. 4, 2006, 597-604.
The Long Tail , by Anderson, C., Wired magazine.
AOL’s Disturbing Glimpse Into Users’ Lives , by McCullagh, D., News.com, August 9, 2006
General Data Mining Methods and Algorithms
Top 10 Algorithms in Data Mining , X. Wu, V. Kumar, J.R. Quinlan, J. Ghosh, Q. Yang, H. motoda, G.J. MClachlan, A. Ng, B. Liu, P.S. Yu, Z. Zhou, M. Steinbach, D. J. Hand, D. Steinberg, Knowl Inf Syst (2008) 141-37.
Induction of Decision Trees , R. Quinlan, Machine Learning, 1(1):81-106, 1986.
Web and Link Mining
The Pagerank Citation Ranking: Bringing Order to the Web , L. Page, S. Brin, R. Motwani, T. Winograd, Technical Report, Stanford University, 1999.
The Structure and Function of Complex Networks , M. E. J. Newman, SIAM Review, 2003, 45, 167-256.
Link Mining: A New Data Mining Challenge , L. Getoor, SIGKDD Explorations, 2003, 5(1), 84-89.
Link Mining: A Survey , L. Getoor, SIGKDD Explorations, 2005, 7(2), 3-12.
Semi-supervised Learning
Semi-Supervised Learning Literature Survey , X. Zhu, Computer Sciences TR 1530, University of Wisconsin — Madison.
Introduction to Semi-Supervised Learning, in Semi-Supervised Learning (Chapter 1) O. Chapelle, B. Scholkopf, A. Zien (eds.), MIT Press, 2006. (Fordham’s library has online access to the entire text)
Learning with Labeled and Unlabeled Data , M. Seeger, University of Edinburgh (unpublished), 2002.
Person Identification in Webcam Images: An Application of Semi-Supervised Learning , M. Balcan, A. Blum, P. Choi, J. lafferty, B. Pantano, M. Rwebangira, X. Zhu, Proceedings of the 22nd ICML Workshop on Learning with Partially Classified Training Data , 2005.
Learning from Labeled and Unlabeled Data: An Empirical Study across Techniques and Domains , N. Chawla, G. Karakoulas, Journal of Artificial Intelligence Research , 23:331-366, 2005.
Text Classification from Labeled and Unlabeled Documents using EM , K. Nigam, A. McCallum, S. Thrun, T. Mitchell, Machine Learning , 39, 103-134, 2000.
Self-taught Learning: Transfer Learning from Unlabeled Data , R. Raina, A. Battle, H. Lee, B. Packer, A. Ng, in Proceedings of the 24th International Conference on Machine Learning , 2007.
An iterative algorithm for extending learners to a semisupervised setting , M. Culp, G. Michailidis, 2007 Joint Statistical Meetings (JSM), 2007
Partially-Supervised Learning / Learning with Uncertain Class Labels
Get Another Label? Improving Data Quality and Data Mining Using Multiple, Noisy Labelers , V. Sheng, F. Provost, P. Ipeirotis, in Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 2008.
Logistic Regression for Partial Labels , in 9th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems , Volume III, pp. 1935-1941, 2002.
Classification with Partial labels , N. Nguyen, R. Caruana, in Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 2008.
Imprecise and Uncertain Labelling: A Solution based on Mixture Model and Belief Functions, E. Come, 2008 (powerpoint slides).
Induction of Decision Trees from Partially Classified Data Using Belief Functions , M. Bjanger, Norweigen University of Science and Technology, 2000.
Knowledge Discovery in Large Image Databases: Dealing with Uncertainties in Ground Truth , P. Smyth, M. Burl, U. Fayyad, P. Perona, KDD Workshop 1994, AAAI Technical Report WS-94-03, pp. 109-120, 1994.
Recommender Systems
Trust No One: Evaluating Trust-based Filtering for Recommenders , J. O’Donovan and B. Smyth, In Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI-05), 2005, 1663-1665.
Trust in Recommender Systems, J. O’Donovan and B. Symyth, In Proceedings of the 10th International Conference on Intelligent User Interfaces (IUI-05), 2005, 167-174.
General resources available on this topic :
ICML 2003 Workshop: Learning from Imbalanced Data Sets II
AAAI ‘2000 Workshop on Learning from Imbalanced Data Sets
A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data , G. Batista, R. Prati, and M. Monard, SIGKDD Explorations , 6(1):20-29, 2004.
Class Imbalance versus Small Disjuncts , T. Jo and N. Japkowicz, SIGKDD Explorations , 6(1): 40-49, 2004.
Extreme Re-balancing for SVMs: a Case Study , B. Raskutti and A. Kowalczyk, SIGKDD Explorations , 6(1):60-69, 2004.
A Multiple Resampling Method for Learning from Imbalanced Data Sets , A. Estabrooks, T. Jo, and N. Japkowicz, in Computational Intelligence , 20(1), 2004.
SMOTE: Synthetic Minority Over-sampling Technique , N. Chawla, K. Boyer, L. Hall, and W. Kegelmeyer, Journal of Articifial Intelligence Research , 16:321-357.
Generative Oversampling for Mining Imbalanced Datasets, A. Liu, J. Ghosh, and C. Martin, Third International Conference on Data Mining (DMIN-07), 66-72.
Learning from Little: Comparison of Classifiers Given Little of Classifiers given Little Training , G. Forman and I. Cohen, in 8th European Conference on Principles and Practice of Knowledge Discovery in Databases , 161-172, 2004.
Issues in Mining Imbalanced Data Sets – A Review Paper , S. Visa and A. Ralescu, in Proceedings of the Sixteen Midwest Artificial Intelligence and Cognitive Science Conference , pp. 67-73, 2005.
Wrapper-based Computation and Evaluation of Sampling Methods for Imbalanced Datasets , N. Chawla, L. Hall, and A. Joshi, in Proceedings of the 1st International Workshop on Utility-based Data Mining , 24-33, 2005.
C4.5, Class Imbalance, and Cost Sensitivity: Why Under-Sampling beats Over-Sampling , C. Drummond and R. Holte, in ICML Workshop onLearning from Imbalanced Datasets II , 2003.
C4.5 and Imbalanced Data sets: Investigating the effect of sampling method, probabilistic estimate, and decision tree structure , N. Chawla, in ICML Workshop on Learning from Imbalanced Datasets II , 2003.
Class Imbalances: Are we Focusing on the Right Issue?, N. Japkowicz, in ICML Workshop on Learning from Imbalanced Datasets II , 2003.
Learning when Data Sets are Imbalanced and When Costs are Unequal and Unknown , M. Maloof, in ICML Workshop on Learning from Imbalanced Datasets II , 2003.
Uncertainty Sampling Methods for One-class Classifiers , P. Juszcak and R. Duin, in ICML Workshop on Learning from Imbalanced Datasets II , 2003.
Active Learning
Improving Generalization with Active Learning , D Cohn, L. Atlas, and R. Ladner, Machine Learning 15(2), 201-221, May 1994.
On Active Learning for Data Acquisition , Z. Zheng and B. Padmanabhan, In Proc. of IEEE Intl. Conf. on Data Mining, 2002.
Active Sampling for Class Probability Estimation and Ranking , M. Saar-Tsechansky and F. Provost, Machine Learning 54:2 2004, 153-178.
The Learning-Curve Sampling Method Applied to Model-Based Clustering , C. Meek, B. Thiesson, and D. Heckerman, Journal of Machine Learning Research 2:397-418, 2002.
Active Sampling for Feature Selection , S. Veeramachaneni and P. Avesani, Third IEEE Conference on Data Mining, 2003.
Heterogeneous Uncertainty Sampling for Supervised Learning , D. Lewis and J. Catlett, In Proceedings of the 11th International Conference on Machine Learning, 148-156, 1994.
Learning When Training Data are Costly: The Effect of Class Distribution on Tree Induction , G. Weiss and F. Provost, Journal of Artificial Intelligence Research, 19:315-354, 2003.
Active Learning using Adaptive Resampling , KDD 2000, 91-98.
Cost-Sensitive Learning
Types of Cost in Inductive Concept Learning , P. Turney, In Proceedings Workshop on Cost-Sensitive Learning at the Seventeenth International Conference on Machine Learning.
Toward Scalable Learning with Non-Uniform Class and Cost Distributions: A Case Study in Credit Card Fraud Detection , P. Chan and S. Stolfo, KDD 1998.
Recent Blogs

Artificial intelligence and machine learning: What’s the difference
Artificial Intelligence , Machine Learning

10 online courses for understanding machine learning
Machine Learning , Tutorials
How is ML Being Used to Handle Security Vulnerabilities?
Machine Learning

10 groups of machine learning algorithms

How a nearly forgotten physicist shaped internet access today
Massachuse...

FinTech 2019: 5 uses cases of machine learning in finance
Banking / Finance , Machine Learning

The biggest impact of machine learning for digital marketing professionals
Machine Learning , Marketing
Looking ahead: the innovative future of iOS in 2019

How machine learning is changing identity theft detection
Machine Learning , Privacy / Security

Wearable technology to boost the process of digitalization of the modern world

Top 8 machine learning startups you should know about
The term...
How retargeting algorithms help in web personalization
others , Machine Learning

3 automation tools to help you in your next app build

Machine learning and information security: impact and trends
Machine Learning , Privacy / Security , Sectors , Tech and Tools

How to improve your productivity with AI and Machine Learning?
Artificial Intelligence , Human Resource , Machine Learning
Artificial...
Ask Data – A new and intuitive way to analyze data with natural language
10 free machine learning ebooks all scientists & ai engineers should read, yisi, a machine translation teacher who cracks down on errors in meaning, machine learning & license plate recognition: an ideal partnership, top 17 data science and machine learning vendors shortlisted by gartner, accuracy and bias in machine learning models – overview, interview with dejan s. milojicic on top technology trends and predictions for 2019.
Artificial Intelligence , Interviews , Machine Learning
Recently,...

Why every small business should use machine learning?

Microsoft’s ML.NET: A blend of machine learning and .NET
Machine learning: best examples and ideas for mobile apps, researchers harness machine learning to predict chemical reactions, subscribe to the crayon blog.
Get the latest posts in your inbox!
Data mining model for scientific research classification: the case of digital workplace accessibility
- Research Article
- Published: 26 March 2024
Cite this article
- Radka Nacheva ORCID: orcid.org/0000-0003-3946-2416 1 ,
- Maciej Czaplewski ORCID: orcid.org/0000-0003-1888-8776 2 &
- Pavel Petrov ORCID: orcid.org/0000-0002-1284-2606 1
Explore all metrics
Research classification is an important aspect of conducting research projects because it allows researchers to efficiently identify papers that are in line with the latest research in each field and relevant to projects. There are different approaches to the classification of research papers, such as subject-based, methodology-based, text-based, and machine learning-based. Each approach has its advantages and disadvantages, and the choice of classification method depends on the specific research question and available data. The classification of scientific literature helps to better organize and structure the vast amount of information and knowledge generated in scientific research. It enables researchers and other interested parties to access relevant information in a fast and efficient manner. Classification methods allow easier and more accurate extraction of scientific knowledge to be used as a basis for scientific research in each subject area. In this regard, this paper aims to propose a research classification model using data mining methods and techniques. To test the model, we selected scientific articles on digital workplace accessibility for the disabled retrieved from Scopus and Web of Science repositories. We believe that the classification model is universal and can be applied in other scientific fields.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Source : own elaboration
Similar content being viewed by others

Text-based paper-level classification procedure for non-traditional sciences using a machine learning approach
Daniela Moctezuma, Carlos López-Vázquez, … José Pérez

Comparing paper level classifications across different methods and systems: an investigation of Nature publications
Lin Zhang, Beibei Sun, … Ying Huang

Information Tracking from Research Papers Using Classification Techniques
Aggarwal T, Salatino AA, Osborne F, Motta E (2022) R-classify: extracting research papers’ relevant concepts from a controlled vocabulary. Softw Impacts 14:100444. https://doi.org/10.1016/j.simpa.2022.100444
Article Google Scholar
ALDabbas A, Gál Z (2022) Recurrent neural network variants based model for Cassini-Huygens spacecraft trajectory modifications recognition. Neural Comput Appl 34(16):13575–13598. https://doi.org/10.1007/s00521-022-07145-0
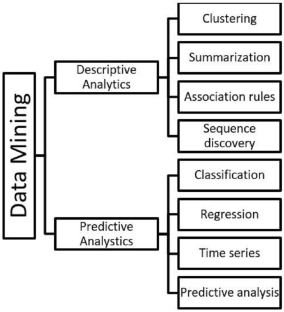
Anshu (2019) Review paper on data mining techniques and applications. https://ssrn.com/abstract=3529347 . Accessed 30 Jan 2024
Antonova K, Ivanova P (2023) How to manage people in a dynamic environment—innovative approaches and practice. J HR Technol 1:25–44
Google Scholar
Bártová B, Bína V, Váchová L (2022) A PRISMA-driven systematic review of data mining methods used for defects detection and classification in the manufacturing industry. Prod J. https://doi.org/10.1590/0103-6513.20210097
Birjandi SM, Khasteh SH (2021) A survey on data mining techniques used in medicine. J Diabetes Metab Disord 20(2):2055–2071. https://doi.org/10.1007/s40200-021-00884-2
Bose R (2009) Advanced analytics: opportunities and challenges. Ind Manag Data Syst 109(2):155–172. https://doi.org/10.1108/02635570910930073
Charbuty B, Abdulazeez AM (2021) Classification based on decision tree algorithm for machine learning. J Appl Sci Technol Trends 2(01):20–28. https://doi.org/10.38094/jastt20165
Chaudhary R, Singh P, Mahajan R (2014) A survey on data mining techniques. Int J Adv Res Comput Commun Eng 3(1):5002–5003
Chowdhury S, Schoen MP (2020) Research paper classification using supervised machine learning techniques. In: 2020 intermountain engineering, technology and computing (IETC). https://doi.org/10.1109/ietc47856.2020.9249211
Deshpande S, Thakare VM (2010) Data mining system and applications: a review. Int J Distrib Parallel Syst 1(1):32–44. https://doi.org/10.5121/ijdps.2010.1103
Dimitrova D (2023) The concept “labour power” as a term in legislation and legal doctrine. Studia Iuris 1:24–31
Dunham MH (2003) Data mining introductory and advanced topics. https://openlibrary.org/books/OL26870779M/DataMiningIntroductoryandAdvancedTopics
Esling P, Agon C (2012) Time-series data mining. ACM Comput Surv 45(1):1–34. https://doi.org/10.1145/2379776.2379788
Gu C (2022) Application of data mining technology in financial intervention based on data Fusion information entropy. J Sens 2022:1–10. https://doi.org/10.1155/2022/2192186
Gupta S, Gupta A (2019) Dealing with noise problem in machine learning data-sets: a systematic review. Procedia Comput Sci 161:466–474. https://doi.org/10.1016/j.procs.2019.11.146
Ho TK, Hull JJ, Srihari SN (1994) Decision combination in multiple classifier systems. IEEE Trans Pattern Anal Mach Intell 16(1):66–75. https://doi.org/10.1109/34.273716
Hong L, Sun X, Sun Y, Gao Y (2017) Text feature extraction based on deep learning: a review. EURASIP J Wirel Commun Netw. https://doi.org/10.1186/s13638-017-0993-1
Jüngermann F, Křetínský J, Weininger M (2022) Algebraically explainable controllers: decision trees and support vector machines join forces. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2208.12804 . Accessed 30 Jan 2024
Ketui N, Wisomka W, Homjun K (2019) Using classification data mining techniques for students performance prediction. In: 2019 joint international conference on digital arts, media and technology with ECTI northern section conference on electrical, electronics, computer and telecommunications engineering (ECTI DAMT-NCON), pp 359–363. https://doi.org/10.1109/ecti-ncon.2019.8692227
Kim S-W, Gi J-M (2019) Research paper classification systems based on TF-IDF and LDA schemes. Human-Centric Comput Inf Sci. https://doi.org/10.1186/s13673-019-0192-7
Koleva V (2023) E-recruitment and generation z job seekers. J HR Technol 1:63–75
Lim B, Zohren S (2021) Time-series forecasting with deep learning: a survey. Philos Trans R Soc 379(2194):20200209. https://doi.org/10.1098/rsta.2020.0209
Mahmoud DF, Moussa SM, Badr NL (2016) The evolution of data mining techniques to big data analytics: an extensive study with application to renewable energy data analytics. Asian J Appl Sci 4(3). https://www.ajouronline.com/index.php?journal=AJAS&page=article&op=view&path%5B%5D=3792 . Accessed 30 Jan 2024
Massi MC, Ieva F, Lettieri E (2020) Data mining application to healthcare fraud detection: a two-step unsupervised clustering method for outlier detection with administrative databases. BMC Med Inform Decis Mak 20(1):160. https://doi.org/10.1186/s12911-020-01143-9
Mukherjee S (2019) Predictive analytics and predictive modeling in healthcare. Univ Cumberl. https://doi.org/10.2139/ssrn.3403900
Nacheva R (2022) Emotions mining research framework: higher education in the pandemic context. In: Terzioğlu MK (eds) Advances in econometrics, operational research, data science and actuarial studies, pp 299–310. https://doi.org/10.1007/978-3-030-85254-2_18
Nacheva R, Koleva V (2022) Exploring gender pay gap in the IT sector. In: Proceedings of international scientific-practical conference human resource management, pp 210–224
Nagi S, Bhattacharyya DK (2013) Classification of microarray cancer data using ensemble approach. Netw Model Anal Health Inform Bioinform 2(3):159–173. https://doi.org/10.1007/s13721-013-0034-x
Narayana GS, Kolli K, Ansari MD, Gunjan VK (2020) A traditional analysis for efficient data mining with integrated association mining into regression techniques, pp 1393–1404. https://doi.org/10.1007/978-981-15-7961-5_127
Nikolov N (2023) Understanding student motivation in digital education. In: 2023 31st national conference with international participation (TELECOM), Sofia, Bulgaria, pp 1–5. https://doi.org/10.1109/TELECOM59629.2023.10409667
Nivethithaa KK, Vijayalakshmi S (2021) Survey on data mining techniques, process and algorithms. J Phys 197(1):012052. https://doi.org/10.1088/1742-6596/1947/1/012052
Noura M, Gyrard A, Heil S, Gaedke M (2019) Automatic knowledge extraction to build semantic web of things applications. IEEE Internet Things J 6(5):8447–8454. https://doi.org/10.1109/jiot.2019.2918327
Noura M, Wang Y, Heil S, Gaedke M (2021) OntoSpect: IoT ontology inspection by concept extraction and natural language generation. In: Brambilla M, Chbeir R, Frasincar F, Manolescu I (eds) Web engineering. ICWE 2021. Lecture notes in computer science, vol 12706, pp 37–52. https://doi.org/10.1007/978-3-030-74296-6_4
Olson D, Delen D (2008) Advanced data mining techniques. Springer, Berlin. https://doi.org/10.1007/978-3-540-76917-0
Book Google Scholar
Omisore MO (2015) A classification model for mining research publications from crowdsourced data. In: IEEE tech. comm. digit. libr. https://bulletin.jcdl.org/Bulletin/v11n3/papers/154-Omisore.pdf . Accessed 30 Jan 2024
Orange (2023) Preprocess text. https://orangedatamining.com/widget-catalog/text-mining/preprocesstext/ . Accessed 30 Jan 2024
Rahman N (2018) Data mining techniques and applications. Int J Strateg Inf Technol Appl 9(1):78–97. https://doi.org/10.4018/ijsita.2018010104
Rak T, Żyła R (2022) Using data mining techniques for detecting dependencies in the outcoming data of a Web-Based system. Appl Sci 12(12):6115. https://doi.org/10.3390/app12126115
Sarker IH (2021) Machine learning: algorithms, real-world applications and research directions. SN Comput Sci 2(3):160. https://doi.org/10.1007/s42979-021-00592-x
Scimago Lab (2020) Scimago journal country rank. https://www.scimagojr.com/countryrank.php?year=2021 . Accessed 30 Jan 2024
Stamenova S (2023) Improving the process of training staff in software companies through specialized software. In: 2023 international conference automatics and informatics (ICAI), pp 341–345. https://doi.org/10.1109/ICAI58806.2023.10339020
Sulova S (2021) Big data processing in the logistics industry. Econ Comput Sci 7(1):6–19
Todoranova L, Penchev B (2023) Higher education—accessible for people with disabilities. J HR Technol 2:45–56
Torkayesh AE, Tirkolaee EB, Bahrini A, Pamucar D, Khakbaz A (2023) A systematic literature review of MABAC method and applications: an outlook for sustainability and circularity. Informatica. https://doi.org/10.15388/23-infor511
UNESCO (2023) 2021 science report: statistics and resources. https://www.unesco.org/reports/science/2021/en/statistics . Accessed 30 Jan 2024
Vasilev J, Iliev I (2023) Digital competences, dependencies between mental indicators and defensive tactical performance indicators for students playing basketball. TEM J 12(1):445–451
Download references
The project "Impact of digitalization on innovative approaches in human resources management" is implemented by the University of Economics—Varna, in the period 2022–2025. The authors express their gratitude to the Bulgarian Scientific Research Fund, Ministry of Education and Science of Bulgaria for the support provided in the implementation of the project "Impact of digitalization on innovative approaches in human resources management," Grant No. BG-175467353-2022-04/12-12-2022, contract No. KP-06-H-65/4 – 2022.
Author information
Authors and affiliations.
Department of Informatics, University of Economics – Varna, 9002, Varna, Bulgaria
Radka Nacheva & Pavel Petrov
Institute of Spatial Management and Socio-Economic Geography, University of Szczecin, 70-453, Szczecin, Poland
Maciej Czaplewski
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Radka Nacheva .
Ethics declarations
Conflict of interest.
The authors have no conflict of interest to declare that are relevant to the content of this article.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Nacheva, R., Czaplewski, M. & Petrov, P. Data mining model for scientific research classification: the case of digital workplace accessibility. Decision (2024). https://doi.org/10.1007/s40622-024-00378-z
Download citation
Accepted : 20 February 2024
Published : 26 March 2024
DOI : https://doi.org/10.1007/s40622-024-00378-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Data mining
- Research classification
- Text mining
- Workplace accessibility
- Digital accessibility
- Find a journal
- Publish with us
- Track your research
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- NEWS FEATURE
- 17 July 2019
- Correction 19 July 2019
The plan to mine the world’s research papers
- Priyanka Pulla 0
Priyanka Pulla is a freelance journalist based in Bengaluru, India.
You can also search for this author in PubMed Google Scholar
Carl Malamud in front of the data store of 73 million articles that he plans to let scientists text mine. Credit: Smita Sharma for Nature
Carl Malamud is on a crusade to liberate information locked up behind paywalls — and his campaigns have scored many victories. He has spent decades publishing copyrighted legal documents, from building codes to court records, and then arguing that such texts represent public-domain law that ought to be available to any citizen online. Sometimes, he has won those arguments in court. Now, the 60-year-old American technologist is turning his sights on a new objective: freeing paywalled scientific literature. And he thinks he has a legal way to do it.
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
24,99 € / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
185,98 € per year
only 3,65 € per issue
Rent or buy this article
Prices vary by article type
Prices may be subject to local taxes which are calculated during checkout
Nature 571 , 316-318 (2019)
doi: https://doi.org/10.1038/d41586-019-02142-1
Updates & Corrections
Correction 19 July 2019 : An earlier version of this feature used the term ‘fair use’ inappropriately — the term isn’t relevant under Indian law.
Reprints and permissions
Related Articles

Text-mining block prompts online response
Text-mining spat heats up
- Developing world
- Computer science

A guide to the Nature Index
Nature Index 13 MAR 24

Decoding chromatin states by proteomic profiling of nucleosome readers
Article 06 MAR 24

‘All of Us’ genetics chart stirs unease over controversial depiction of race
News 23 FEB 24

The corpse of an exploded star and more — March’s best science images
News 28 MAR 24

How papers with doctored images can affect scientific reviews

Nature is committed to diversifying its journalistic sources
Editorial 27 MAR 24

A fresh start for the African Academy of Sciences
Editorial 19 MAR 24

Fungal diseases are spreading undetected
Outlook 14 MAR 24

Last-mile delivery increases vaccine uptake in Sierra Leone
Article 13 MAR 24
Postdoctoral positions in the integrative structural biology of cancer and immunity
Postdoctoral positions in the integrative structural biology study of signaling complexes important in cancer and the immune system
Farmington, Connecticut (US)
University of Connecticut Health Center (UCHC)
Faculty Positions & Postdocs at Institute of Physics (IOP), Chinese Academy of Sciences
IOP is the leading research institute in China in condensed matter physics and related fields. Through the steadfast efforts of generations of scie...
Beijing, China
Institute of Physics (IOP), Chinese Academy of Sciences (CAS)
Postdoctoral Scholar - PHAST Alzheimer
Memphis, Tennessee
The University of Tennessee Health Science Center (UTHSC)
Postdoctoral Associate- Neurodevelopmental Disease
Houston, Texas (US)
Baylor College of Medicine (BCM)
Supervisory Bioinformatics Specialist, CTG Program Head
National Institutes of Health (NIH) National Library of Medicine (NLM) National Center for Biotechnology Information (NCBI) Information Engineering...
Washington D.C. (US)
National Library of Medicine, National Center for Biotechnology Information
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Identifying Trends in Data Science Articles using Text Mining
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Help | Advanced Search
Computer Science > Computer Vision and Pattern Recognition
Title: video editing via factorized diffusion distillation.
Abstract: We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation procedure, Factorized Diffusion Distillation. This procedure distills knowledge from one or more teachers simultaneously, without any supervised data. We utilize this procedure to teach EVE to edit videos by jointly distilling knowledge to (i) precisely edit each individual frame from the image editing adapter, and (ii) ensure temporal consistency among the edited frames using the video generation adapter. Finally, to demonstrate the potential of our approach in unlocking other capabilities, we align additional combinations of adapters
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Creating a Corporate Social Responsibility Program with Real Impact
- Emilio Marti,
- David Risi,
- Eva Schlindwein,
- Andromachi Athanasopoulou

Lessons from multinational companies that adapted their CSR practices based on local feedback and knowledge.
Exploring the critical role of experimentation in Corporate Social Responsibility (CSR), research on four multinational companies reveals a stark difference in CSR effectiveness. Successful companies integrate an experimental approach, constantly adapting their CSR practices based on local feedback and knowledge. This strategy fosters genuine community engagement and responsive initiatives, as seen in a mining company’s impactful HIV/AIDS program. Conversely, companies that rely on standardized, inflexible CSR methods often fail to achieve their goals, demonstrated by a failed partnership due to local corruption in another mining company. The study recommends encouraging broad employee participation in CSR and fostering a culture that values CSR’s long-term business benefits. It also suggests that sustainable investors and ESG rating agencies should focus on assessing companies’ experimental approaches to CSR, going beyond current practices to examine the involvement of diverse employees in both developing and adapting CSR initiatives. Overall, embracing a dynamic, data-driven approach to CSR is essential for meaningful social and environmental impact.
By now, almost all large companies are engaged in corporate social responsibility (CSR): they have CSR policies, employ CSR staff, engage in activities that aim to have a positive impact on the environment and society, and write CSR reports. However, the evolution of CSR has brought forth new challenges. A stark contrast to two decades ago, when the primary concern was the sheer neglect of CSR, the current issue lies in the ineffective execution of these practices. Why do some companies implement CSR in ways that create a positive impact on the environment and society, while others fail to do so? Our research reveals that experimentation is critical for impactful CSR, which has implications for both companies that implement CSR and companies that externally monitor these CSR activities, such as sustainable investors and ESG rating agencies.
- EM Emilio Marti is an assistant professor at the Rotterdam School of Management (RSM) at Erasmus University Rotterdam.
- DR David Risi is a professor at the Bern University of Applied Sciences and a habilitated lecturer at the University of St. Gallen. His research focuses on how companies organize CSR and sustainability.
- ES Eva Schlindwein is a professor at the Bern University of Applied Sciences and a postdoctoral fellow at the University of Oxford. Her research focuses on how organizations navigate tensions between business and society.
- AA Andromachi Athanasopoulou is an associate professor at Queen Mary University of London and an associate fellow at the University of Oxford. Her research focuses on how individuals manage their leadership careers and make ethically charged decisions.
Partner Center
IMAGES
VIDEO
COMMENTS
Epidemic diseases can be extremely dangerous with its hazarding influences. They may have negative effects on economies, businesses, environment, humans, and workforce. In this paper, some of the factors that are interrelated with COVID-19 pandemic have been examined using data mining methodologies and approaches.
Data mining is used in computational biology and bioinformatics to detect trends or patterns without knowledge of the meaning of the data. Latest Research and Reviews.
Explore the latest full-text research PDFs, articles, conference papers, preprints and more on DATA MINING. Find methods information, sources, references or conduct a literature review on DATA MINING
Read the latest Research articles in Data mining from Scientific Reports. ... data mining. Atom; ... Calls for Papers Guide to referees ...
Big Data Mining and Analytics. Big Data Mining and Analytics (Published by Tsinghua University Press) discovers hidden patterns, correlations, insig
Data mining research has been significantly motivated by and benefited from real-world applications in novel domains. This special issue was proposed and edited to draw attention to domain-driven data mining and disseminate research in foundations, frameworks, and applications for data-driven and actionable knowledge discovery. Along with this special issue, we also organized a related ...
Despite these limitations, the K-means clustering algorithm is credited with flexibility, efficiency, and ease of implementation. It is also among the top ten clustering algorithms in data mining [59], [217], [105], [94].The simplicity and low computational complexity have given the K-means clustering algorithm a wide acceptance in many domains for solving clustering problems.
Wu X. (2010) 10 years of data mining research: retrospect and prospect. Proceedings of the 10th IEEE International Conference on Data Mining (ICDM), Sydney, Australia, 13-17 December 2010 , p.
Overview. Data Mining and Knowledge Discovery is a leading technical journal focusing on the extraction of information from vast databases. Publishes original research papers and practice in data mining and knowledge discovery. Provides surveys and tutorials of important areas and techniques. Offers detailed descriptions of significant ...
About This Journal. Statistical Analysis and Data Mining addresses the broad area of data analysis, including data mining algorithms, statistical approaches, and practical applications. Topics include problems involving massive and complex datasets, solutions utilizing innovative data mining algorithms and/or novel statistical approaches. .
Stay informed on the latest trending ML papers with code, research developments, libraries, methods, and datasets. ... We propose a new unsupervised machine learning technique, denominated as Trace-based clustering, and a 5-step methodology in order to support clinicians when identifying patient phenotypes. ... is a supervised data mining ...
Search for more papers by this author. Mohamed Medhat Gaber, ... Although the study of big scholarly data is relatively new, some studies have emerged on how to investigate scholarly data usage in different disciplines. ... We also discuss open challenges that remain unsolved to foster future research in the field of scholarly data mining. This ...
Databases process" [11]. It listed three stages of research involving data warehouse which are staging, integration, and y for the purpose of reporting and analysis in the Review of Data Mining Techniques in Cloud Computing Database by [10]. In addition to the problems associated with data mining on
Data mining lies at the heart of many of these questions, and the research done at Google is at the forefront of the field. Whether it is finding more efficient algorithms for working with massive data sets, developing privacy-preserving methods for classification, or designing new machine learning approaches, our group continues to push the ...
Exploration of data mining and machine learning in public health sector. 2011-2019: Investigation of medical data mining using VOSviewer and CiteSpace software. This paper: 1995-2020: A BPNA of data mining in healthcare: performance analysis, strategic themes, thematic evolution structure, trends and future opportunities using SciMAT software.
Machine learning articles from across Nature Portfolio. Machine learning is the ability of a machine to improve its performance based on previous results. Machine learning methods enable computers ...
The rapid growth of data science in medicine has been fueled by the digitalization of the medical services, which has resulted in a flood of clinical huge data. The information gathered from this flood of data should be organized in such a way that it can provide better healthcare insights. The efficiency and effectiveness of the medical care systems can be improved by data mining algorithms ...
Active Sampling for Feature Selection, S. Veeramachaneni and P. Avesani, Third IEEE Conference on Data Mining, 2003. Heterogeneous Uncertainty Sampling for Supervised Learning, D. Lewis and J. Catlett, In Proceedings of the 11th International Conference on Machine Learning, 148-156, 1994. Learning When Training Data are Costly: The Effect of ...
Classification is a basic problem in the field of data mining. It is one of the key steps that intelligent systems take when extracting meaningful information from complex and massive data. This paper introduces a new classification approach based on the theory of human vision from the perspective of bionics. The experimental results show that the new algorithm is efficient for the classification.
The study is organized as follows. Section 2 brings the brief examples of several datamining software that use visual form in stage of workflow design. In addition, the basic concept of visual vocabulary of Orange software is presented. Section 5 describes in depth the application of the Physics of Notations (PoN) theory for assessing effective cognition using the Orange software.
Research classification is an important aspect of conducting research projects because it allows researchers to efficiently identify papers that are in line with the latest research in each field and relevant to projects. There are different approaches to the classification of research papers, such as subject-based, methodology-based, text-based, and machine learning-based. Each approach has ...
The power of data mining. The JNU data store could sweep aside barriers that still deter scientists from using software to analyse research, says Max Häussler, a bioinformatics researcher at the ...
This paper attempts, how data mining can be applied in retail industry to improve market campaign. ... Join ResearchGate to discover and stay up-to-date with the latest research from leading ...
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that ...
Abstract: The research conducted in this paper presents a detailed analysis of the latest research publications related to Data Science using information retrieval and text mining approach. The database used in this study was created by collecting the latest research papers from well-reputed Journals and Conference proceedings published by IEEE and Springer.
We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation ...
A new research paper published recently in Annual Reviews of Earth and Planetary Sciences, coordinated by scientists from The University of New Mexico and collaborating institutions, addresses the ...
Exploring the critical role of experimentation in Corporate Social Responsibility (CSR), research on four multinational companies reveals a stark difference in CSR effectiveness. Successful ...
Today, we're sharing details on two versions of our 24,576-GPU data center scale cluster at Meta. These clusters support our current and next generation AI models, including Llama 3, the successor to Llama 2, our publicly released LLM, as well as AI research and development across GenAI and other areas . A peek into Meta's large-scale AI ...