The Beckman Report on Database Research
- Hacker News
- Download PDF
- Join the Discussion
- View in the ACM Digital Library
- Introduction

Key Insights
Research challenges, community challenges, going forward, acknowledgments.

A group of database researchers meets periodically to discuss the state of the field and its key directions going forward. Past meetings were held in 1989, 6 1990, 11 1995, 12 1996, 10 1998, 7 2003, 1 and 2008. 2 Continuing this tradition, 28 database researchers and two invited speakers met in October 2013 at the Beckman Center on the University of California-Irvine campus for two days of discussions. The meeting attendees represented a broad cross-section of interests, affiliations, seniority, and geography. Attendance was capped at 30 so the meeting would be as interactive as possible. This article summarizes the conclusions from that meeting; an extended report and participant presentations are available at http://beckman.cs.wisc.edu .
Back to Top
- Thirty leaders from the database research community met in October 2013 to discuss the state of the field and important future research directions.
- Big data was identified as a defining challenge for the field. Five related challenges were called out: developing scalable data infrastructures, coping with increased diversity in both data and data management, addressing the end-to-end data-to-knowledge pipeline, responding to the adoption of cloud-based computing, and accommodating the many and changing roles of individuals in the data life cycle.
- College-level education needs modernization to catch up with the many changes in database technology of the past decade and to meet the demands of the emerging disciplines of data science.
The meeting participants quickly converged on big data as a defining challenge of our time. Big data arose due to the confluence of three major trends. First, it has become much cheaper to generate a wide variety of data, due to inexpensive storage, sensors, smart devices, social software, multiplayer games, and the Internet of Things, which connects homes, cars, appliances, and other devices. Second, it has become much cheaper to process large amounts of data, due to advances in multicore CPUs, solid state storage, inexpensive cloud computing, and open source software. Finally, data management has become democratized. The process of generating, processing, and consuming data is no longer just for database professionals. Decision makers, domain scientists, application users, journalists, crowd workers, and everyday consumers now routinely do it.
Due to these trends, an unprecedented volume of data needs to be captured, stored, queried, processed, and turned into knowledge. These goals are remarkably well aligned with those that have driven the database research community for decades. Many early systems for big data abandoned database management system (DBMS) principles, such as declarative programming and transactional data consistency, in favor of scalability and fault tolerance on commodity hardware. However, the latest generation of big data systems is rediscovering the value of these principles and is adopting concepts and methods that have been long-standing assets of the database community. Building on these principles and assets, the database community is well positioned to drive transformative improvements to big data technology.
But big data also brings enormous challenges, whose solutions will require massive disruptions to the design, implementation, and deployment of data management solutions. The main characteristics of big data are volume, velocity, and variety. The database community has worked on volume and velocity for decades, and has developed solutions that are mission critical to virtually every commercial enterprise on the planet. The unprecedented scale of big data, however, will require a radical rethinking of existing solutions.
Variety arises from several sources. First, there is the problem of integrating and analyzing data that comes from diverse sources, with varying formats and quality. This is another long-standing topic of database work, yet it is still an extremely laborintensive journey from raw data to actionable knowledge. This problem is exacerbated by big data, causing a major bottleneck in the data processing pipeline. Second, there is the variety of computing platforms needed to process big data: hardware infrastructures; processing frameworks, languages, and systems; and programming abstractions. Finally, there is a range of user sophistication and preferences. Designing data management solutions that can cope with such extreme variety is a difficult challenge.
Moving beyond the three Vs, many big data applications will be deployed in the cloud, both public and private, on a massive scale. This requires new techniques to offer predictable performance and flexible interoperation. Many applications will also require people to solve semantic problems that still bedevil current automatic solutions. This can range from a single domain expert to a crowd of workers, a user community, or the entire connected world (for example, Wikipedia). This will require new techniques to help people be more productive and to reduce the skill level needed to solve these problems.
Many big data applications will be deployed in the cloud, both public and private, on a massive scale. This requires new techniques to offer predictable performance and flexible interoperation.
Finally, big data brings important community challenges. We must rethink the approach to teaching data management, reexamine our research culture, and adapt to the emergence of data science as a discipline.
The meeting identified five big data challenges: scalable big/fast data infrastructures; coping with diversity in data management; end-to-end processing of data; cloud services; and the roles of people in the data life cycle. The first three challenges deal with the volume, velocity, and variety aspects of big data. The last two deal with deploying big data applications in the cloud and managing the involvement of people in these applications.
These big data challenges are not an exclusive agenda to be pursued at the expense of existing work. In recent years the database community has strengthened core competencies in relational DBMSs and branched out into many new directions. Some important issues raised repeatedly during the meeting are security, privacy, data pricing, data attribution, social and mobile data, spatiotemporal data, personalization and contextualization, energy-constrained processing, and scientific data management. Many of these issues cut across the identified big data challenges and are captured in the discussion here.
It is important to note that some of this work is being done in collaboration with other computer science fields, including distributed systems, artificial intelligence, knowledge discovery and data mining, human-computer interaction, and e-science. In many cases, these fields provided the inspiration for the topic and the data management community has joined in, applying its expertise to produce robust solutions. These collaborations have been very productive and should continue to grow.
Scalable big/fast data infrastructures. Parallel and distributed processing. In the database world, parallel processing of large structured datasets has been a major success, leading to several generations of SQL-based products that are widely used by enterprises. Another success is data warehousing, where database researchers defined the key abstraction of data cube (for online analytic processing, or OLAP) and strategies for querying it in parallel, along with support for materialized views and replication. The distributed computing field has achieved success in scaling up data processing for less structured data on large numbers of unreliable, commodity machines using constrained programming models such as MapReduce. Higher-level languages have been layered on top, to enable a broader audience of developers to use scalable big data platforms. Today, open source platforms such as Hadoop 3 —with its MapReduce programming model, large-scale distributed file system, and higher-level languages, such as Pig 5 and Hive 4 —are seeing rapid adoption for processing less structured data, even in traditional enterprises.
Query processing and optimization. Given the enthusiastic adoption of declarative languages for processing big data, there is a growing recognition that more powerful cost-aware query optimizers and set-oriented query execution engines are needed, to fully exploit large clusters of many-core processors, scaling both “up” and “out.” This will create challenges for progress monitoring, so a user can diagnose and manage queries that are running too slowly or consuming excessive resources. To adapt to the characteristics of previously unseen data and reduce the cost of data movement between stages of data analysis, query processors will need to integrate data sampling, data mining, and machine learning into their flows.
New hardware. At datacenter scale, the ratio between the speed of sequential processing and interconnects is changing with the advent of faster networks, full bisection bandwidth networks between servers, and remote direct memory access. In addition to clusters of general-purpose multicore processors, more specialized processors should be considered. Commercially successful database machines have shown the potential of hardwaresoftware co-design for data management. Researchers should continue to explore ways of leveraging specialized processors, for example, graphics processing units, field-programmable gate arrays, and application-specific integrated circuits, for processing very large datasets. These changes in communications and processing technologies will require a reconsideration of parallel and distributed query-processing algorithms, which have traditionally focused on more homogeneous hardware environments.
Cost-efficient storage. The database research community must learn how best to leverage emerging memory and storage technologies. Relative to commodity magnetic disks, solid-state disks are expensive per gigabyte but cheap per I/O operation. Various nonvolatile random-access memory technologies are under development, all with different speed, power, and durability characteristics.
Both server-attached and network-attached storage architectures need to be considered. Distributed file systems like HDFS, which are server-attached yet shared across the network, are a hybrid of both approaches. How best to use this range of storage configurations reopens many questions reminiscent of past debates of shared memory vs. shared disk vs. shared nothing, questions many have considered to be “closed” for parallel relational systems.
High-speed data streams. For data that arrives at ever-higher speeds, new scalable techniques for ingesting and processing streams of data will be needed. Algorithms will need to be tuned carefully to the behavior of hardware, for example, to cope with non-uniform memory access and limited transfer rates across layers of the memory hierarchy. Some very high-speed data sources, often with lower information density, will need to be processed online and then discarded without being persisted in its entirety. Rather, samples and aggregations of such data will need to be selected and stored persistently to answer queries that arrive after the raw data is no longer available. For such data, progressive query processing will be important to provide incremental and partial results with increasing accuracy as data flows through the processing pipeline.
Late-bound schemas. For data that is persisted but processed just once (if ever), it makes little sense to pay the substantial price of storing and indexing it first in a database system. Instead, it should be stored as a binary file and interpreted as a structured record only if and when it is read later. Record structure may be self-describing via attribute-value pairs, such as JavaScript Object Notation (JSON), interpreted via predefined schemas, or deduced using data mining. To offer the benefits of database queries in such scenarios, we need query engines that can run efficiently over raw files with late-bound schemas.
Consistency. Today’s world brings new requirements for data capture, updates, and simple and fast data access. Handling high rates of data capture and updates for schema-less data has led to the development of NoSQL systems. There are many such systems, with a range of transaction models. Most provide only basic data access and weak atomicity and isolation guarantees, making it difficult to build and reason about reliable applications. As a result, a new class of big data system has emerged that provides full-fledged database-like features over key-value stores or similar substrates. For some applications, the stored data is still managed and updated as “the source of truth” for an enterprise. For others, such as the Internet of Things, the stored data reflects ongoing events in the outside world that applications can use to recognize and respond to situations of interest. This creates an opportunity to revisit programming models and mechanisms for data currency and consistency and to design new models and techniques for developing robust applications.
Metrics and benchmarks. Finally, scalability should be measured not only in petabytes of data and queries per second, but also total cost of ownership (including management and energy use), end-to-end processing speed (that is, time from raw data arrival to eventual insights), brittleness (for example, the ability to continue despite failures such as partial data parse errors), and usability (especially for entry-level users). To measure progress against such broader metrics, new types of benchmarks will be required.
Diversity in data management. No one-size-fits-all. Today’s data-driven world involves a richer variety of data types, shapes, and sizes than traditional enterprise data, which is stored in a data warehouse optimized for analysis tasks. Today, data is often stored in different representations managed by different software systems with different application programming interfaces, query processors, and analysis tools. It seems unlikely a single, one-size-fits-all, big data system will suffice for this degree of diversity. Instead, we expect multiple classes of systems to emerge, each addressing a particular need (for example, data deduplication, analysis of large graphs, diverse scientific experiments, and real-time stream processing) or exploiting a particular type of hardware platform (for example, clusters of inexpensive machines or large multicore servers). Addressing these scenarios will require applying expertise in set-oriented parallel processing and in efficiently handling datasets that do not fit in main memory.
Cross-platform integration. Given this diversity of systems, platforms will need to be integrated or federated to enable data analysts to combine and analyze data across systems. This will involve not only hiding the heterogeneity of data formats and access languages, but also optimizing the performance of accesses that span diverse big data systems and of flows that move data between them. It will also require managing systems that run on diverse devices and span large datacenters. Disconnected devices will become increasingly common, raising challenges in reliable data ingestion, query processing, and data inconsistency in such sometimes-connected, wide-area environments.
Programming models. A diverse and data-driven world requires diverse programming abstractions to operate on very large datasets. A single data analysis language for big data, such as an extension of SQL, will not meet everyone’s needs. Rather, users must be able to analyze their data in the idiom they find most natural: SQL, Pig, R, Python, a domain-specific language, or a lower-level constrained programming model such as MapReduce or Valiant’s bulk synchronous processing model. This also suggests the development of reusable middle-layer components that can support multiple language-specific bindings, such as scalable support for matrix multiplication, list comprehension, and stylized iterative execution models. Another potentially fruitful focus is tools for the rapid development of new domain-specific data analysis languages—tools that simplify the implementation of new scalable, data-parallel languages.
Data processing workflows. To handle data diversity, we need platforms that can span both “raw” and “cooked” data. The cooked data can take many forms, for example, tables, matrices, or graphs. Systems will run end-to-end workflows that mix multiple types of data processing, for example, querying data with SQL and then analyzing it with R. To unify diverse systems, lazy computation is sometimes beneficial—lazy data parsing, lazy conversion and loading, lazy indexing and view construction, and just-in-time query planning. Big data systems should become more interoperable like “Lego bricks.” Cluster resource managers, such as Hadoop 2.0’s YARN, provide some inspiration at the systems level, as do workflow systems for the Hadoop ecosystem and tools for managing scientific workflows.
End-to-end processing of data. The database research community should pay more attention to end-to-end processing of data. Despite years of R&D, surprisingly few tools can go from raw data all the way to extracted knowledge without significant human intervention at each step. For most steps, the intervening people need to be highly computer savvy.
Data-to-knowledge pipeline. The steps of the raw-data-to-knowledge pipeline will be largely unchanged: data acquisition; selection, assessment, cleaning, and transformation (also called “data wrangling”); extraction and integration; mining, OLAP, and analytics; and result summarization, provenance, and explanation. In addition to greater scale, what has significantly changed is the greater diversity of data and users. Data today comes in a wide variety of formats. Often, structured and unstructured data must be used together in a structured fashion. Data tools must exploit human feedback in every step of the analytical pipeline, and must be usable by subject-matter experts, not just by IT professionals. For example, a journalist may want to clean, map, and publish data from a spreadsheet file of crime statistics. Tools must also be tailored to data scientists, the new class of data analysis professionals that has emerged.
Tool diversity. Since no one-size-fits-all tool will cover the wide variety of data analysis scenarios ahead, we need multiple tools, each solving a step of the raw-data-to-knowledge pipeline. They must be seamlessly integrated and easy to use for both lay and expert users, with best-practice guidance on when to use each tool.
Tool customizability. Tools should be able to exploit domain knowledge, such as dictionaries, knowledge bases, and rules. They should be easy to customize to a new domain, possibly using machine learning to automate the customization process. Handcrafted rules will remain important, though, as many analysis applications require very high precision, such as e-commerce. For such applications, analysts often write many rules to cover “corner cases” that are not amenable to learning and generalization. Thus, tools should provide support for writing, evaluating, applying, and managing handcrafted rules.
Open source. Few tools in this area are open source. Most are expensive proprietary products that address certain processing steps. As a result, existing tools cannot easily benefit from ongoing contributions by the data integration research community.
Understanding data. Explanation, provenance, filtering, summarization, and visualization requirements will be critical to making analytic tools easy to use. Capturing and managing appropriate meta-information is key to enable explanation, provenance, reuse, and visualization. Visual analytics is receiving growing attention in the database, visualization, and HCI communities. Continued progress in this area is essential to help users cope with big data volumes.
Knowledge bases. The more knowledge we have about a target domain, the better that tools can analyze the domain. As a result, there has been a growing trend to create, share, and use domain knowledge to better understand data. Such knowledge is often captured in knowledge bases (KBs) that describe the most important entities and relationships in a domain, such as a KB containing profiles of tens of thousands of biomedical researchers along with their publications, affiliations, and patents. Such KBs are used for improving the accuracy of the raw-data-to-knowledge pipeline, answering queries about the domain, and finding domain experts. Many companies have also built KBs for answering user queries, annotating text, supporting e-commerce, and analyzing social media. The KB trend will likely accelerate, leading to a proliferation of community-maintained “knowledge centers” that offer tools to query, share, and use KBs for data analysis.
While some progress has been made on this topic, more work is needed on tools to help groups of users with different skill levels collaboratively build, maintain, query, and share domain-specific KBs.
Cloud services. Cloud computing comes in three main forms: Infrastructure as a Service (IaaS), where the service is virtualized hardware; Platform as a Service (PaaS), where the service is virtualized infrastructure software such as a DBMS; and Software as a Service (SaaS), where the service is a virtualized application such as a customer relationship management solution. From a data platform perspective, the ideal goal is a PaaS for data, where users can upload data to the cloud, query it as they do today over their on-premise SQL databases, and selectively share the data and results easily, all without worrying about how many instances to rent, what operating system to run on, how to partition databases across servers, or how to tune them. Despite the emergence of services such as Database.com from Salesforce.com , Big Query from Google, Redshift from Amazon, and Azure SQL Database from Microsoft, we have yet to achieve the full ideal. Here, we outline some of the critical challenges to realize the complete vision of a Data PaaS in the cloud.
Elasticity. Data can be prohibitively expensive to move. Network-attached storage makes it easier to scale out a database engine. However, network latency and bandwidth limit database performance. Server-attached storage reduces these limitations, but then server failures can degrade availability and failover can interfere with load balancing and hence violate service-level agreements (SLAs).
A diverse and data-driven world requires diverse programming abstractions to operate on very large datasets.
An open question is whether the same cloud storage service can support both transactions and analytics; how caching best fits into the overall picture is also unclear. To provide elasticity, database engines and analysis platforms in a Data PaaS will need to operate well on top of resources that can be allocated quickly during workload peaks but possibly preempted for users paying for premium service.
Data replication. Latency across geographically distributed datacenters makes it difficult to keep replicas consistent yet offer good throughput and response time to updates. Multi-master replication is a good alternative, when conflicting updates on different replicas can be automatically synchronized. But the resulting programming model is not intuitive to mainstream programmers. Thus, the challenge is how best to trade-off availability, consistency performance, programmability, and cost.
System administration and tuning. In the world of Data PaaS, database and system administrators simply do not exist. Therefore, all administrative tasks must be automated, such as capacity planning, resource provisioning, and physical data management. Resource control parameters must also be set automatically and be highly responsive to changes in load, such as buffer pool size and admission control limits.
Multitenancy. To be competitive, a Data PaaS should be cheaper than an on-premises solution. This requires providers to pack multiple tenants together to share physical resources to smooth demand and reduce cost. This introduces several problems. First, the service must give security guarantees against information leakage across tenants. This can be done by isolating user databases in separate files and running the database engine in separate virtual machines (VMs). However, this is inefficient for small databases, and makes it difficult to balance resources between VMs running on the same server. An alternative is to have users share a single database and database engine instance. But then special care is needed to prevent cross-tenant accesses. Second, users want an SLA that defines the level of performance and availability they need. Data PaaS providers want to offer SLAs too, to enable tiered pricing. However, it is challenging to define SLAs that are understandable to users and implementable by PaaS providers. The implementation challenge is to ensure performance isolation between tenants, to ensure a burst of demand from one tenant does not cause a violation of other tenants’ SLAs.
Data sharing. The cloud enables sharing at an unprecedented scale. One problem is how to support essential services such as data curation and provenance collaboratively in the cloud. Other problems include: how to find useful public data, how to relate self-managed private data with public data to add context, how to find high-quality data in the cloud, how to share data at fine-grained levels, how to distribute costs when sharing computing and data, and how to price data. The cloud also creates new life-cycle challenges, such as how to protect data if the current cloud provider fails and to preserve data for the long term when users who need it have no personal or financial connection to those who provide it. The cloud will also drive innovation in tools for data governance, such as auditing, enforcement of legal terms and conditions, and explanation of user policies.
Hybrid clouds. There is a need for interoperation of database services among the cloud, on-premise servers, and mobile devices. One scenario is off-loading. For example, users may run applications in their private cloud during normal operation, but tap into a public cloud at peak times or in response to unanticipated workload surges. Another is cyber-physical systems, such as the Internet of Things. For example, cars will gather local sensor data, upload some of it into the cloud, and obtain control information in return based on data aggregation from many sources. Cyber-physical systems involve data streaming from multiple sensors and mobile devices, and must cope with intermittent connectivity and limited battery life, which pose difficult challenges for real-time and perhaps mission-critical data management in the cloud.
We need to build platforms that allow people to curate data easily and extend relevant applications to incorporate such curation.
Roles of humans in the data life cycle. Back when data management was an enterprise-driven activity, roles were clear: developers built databases and database-centric applications, business analysts queried databases using (SQL-based) reporting tools, end users generated data and queried and updated databases, and database administrators tuned and monitored databases and their workloads. Today, a single individual can play multiple roles in the data life cycle, and some roles may be served by crowdsourcing. Thus, human factors need to be considered for query understanding and refinement, identifying relevant and trustworthy information sources, defining and incrementally refining the data processing pipeline, visualizing relevant patterns, obtaining query answers, and making the various micro-tasks doable by domain experts and end users. We can classify people’s roles into four general categories: producers, curators, consumers, and community members.
Data producers. Today, virtually anyone can generate a torrent of data from mobile phones, social platforms and applications, and wearable devices. One key challenge for the database community is to develop algorithms and incentives that guide people to produce and share the most useful data, while maintaining the desired level of data privacy. When people produce data, how can we help them add metadata quickly and accurately? For example, when a user uploads an image, Facebook automatically identifies faces in the image so users can optionally tag them. Another example is tools to automatically suggest tags for a tweet. What else can we do, and what general principles and tools can we provide?
Data curators. Data is no longer just in databases controlled by a DBA and curated by the IT department. Now, a wide variety of people are empowered to curate it. Crowdsourcing is one approach. A key challenge, then, is to obtain high-quality datasets from a process based on often-imperfect human curators. We need to build platforms that allow people to curate data easily and extend relevant applications to incorporate such curation. For these people-centric challenges, data provenance and explanation will be crucial, as will privacy and security.
Data consumers. People want to use messier data in complex ways, raising many challenges. In the enterprise, data consumers usually know how to ask SQL queries, over a structured database. Today’s data consumers may not know how to formulate a query at all, for example, a journalist who wants to “find the average temperature of all cities with population over 100,000 in Florida” over a structured dataset. Enabling people to get such answers themselves requires new query interfaces, for example, based on multi-touch, not just console-based SQL. We need multimodal interfaces that combine visualization, querying, and navigation. When the query to ask is not clear, people need other ways to browse, explore, visualize, and mine the data, to make data consumption easier.
Online communities. People want to create, share, and manage data with other community members. They may want to collaboratively build community-specific knowledge bases, wikis, and tools to process data. For example, many researchers have created their own pages on Google Scholar, thereby contributing to this “community” knowledge base. Our challenge is to build tools to help communities produce usable data as well as to exploit, share, and mine it.
In addition to research challenges, the database field faces many community issues. These include database education, data science, and research culture. Some of these are new, brought about by big data. Other issues, while not new, are exacerbated by big data and are becoming increasingly important.
Database education. The database technology taught in standard database courses today is increasingly disconnected from reality. It is rooted in the 1980s, when memory was small relative to database size, making I/O the bottleneck to most database operations, and when servers used relatively expensive single-core processors. Today, many databases fit in main memory, and many-core servers make parallelism and cache behavior critical to database performance. Moreover, although SQL DBMSs are still widely used, so are key-value stores, data stream processors, and MapReduce frameworks. It is time to rethink the database curriculum.
Data science. As we discussed earlier, big data has generated a rapidly growing demand for data scientists who can transform large volumes of data into actionable knowledge. Data scientists need skills not only in data management, but also in business intelligence, computer systems, mathematics, statistics, machine learning, and optimization. New cross-disciplinary programs are needed to provide this broad education. Successful research and educational efforts related to data science will require close collaboration with these other disciplines and with domain specialists. Big data presents computer science with an opportunity to influence the curricula of chemistry, earth sciences, sociology, physics, biology, and many other fields. The small computer science parts of those curricula could be grown and redirected to give data management and data science a more prominent role.
Research culture. Finally, there is much concern over the increased emphasis of citation counts instead of research impact. This discourages large systems projects, end-to-end tool building, and sharing of large datasets, since this work usually takes longer than solving point problems. Program committees that value technical depth on narrow topics over the potential for real impact are partly to blame. It is unclear how to change this culture. However, to pursue the big data agenda effectively, the field needs to return to a state where fewer publications per researcher per time unit is the norm, and where large systems projects, end-to-end tool sets, and data sharing are more highly valued.
This is an exciting time for database research. In the past it has been guided by, but also restricted by, the rigors of the enterprise and relational database systems. The rise of big data and the vision of a data-driven world present many exciting new research challenges related to processing big data; handling data diversity; exploiting new hardware, software, and cloud-based platforms; addressing the data life cycle, from creating data to analyzing and sharing it; and facing the diversity, roles, and number of people related to all aspects of data. It is also time to rethink approaches to education, involvement with data consumers, and our value system and its impact on how we evaluate, disseminate, and fund our research.
We thank the reviewers for invaluable suggestions. The Beckman meeting was supported by donations from the Professor Ram Kumar Memorial Foundation, Microsoft Corporation, and @WalmartLabs.
Submit an Article to CACM
CACM welcomes unsolicited submissions on topics of relevance and value to the computing community.
You Just Read
©2016 ACM 0001-0782/16/02
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and full citation on the first page. Copyright for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or fee. Request permission to publish from [email protected] or fax (212) 869-0481.
The Digital Library is published by the Association for Computing Machinery. Copyright © 2016 ACM, Inc.
February 2016 Issue
Published: February 1, 2016
Vol. 59 No. 2
Pages: 92-99
Related Reading
Research and Advances
The Seattle Report on Database Research
Computing Applications
Advertisement
Join the Discussion (0)
Become a member or sign in to post a comment, the latest from cacm.
Safety Fears Raised Over Risks of ‘Penetrative AI’

The Risks of Source Code Breaches

Conversations with AI

Shape the Future of Computing
ACM encourages its members to take a direct hand in shaping the future of the association. There are more ways than ever to get involved.
Communications of the ACM (CACM) is now a fully Open Access publication.
By opening CACM to the world, we hope to increase engagement among the broader computer science community and encourage non-members to discover the rich resources ACM has to offer.
The Beckman Report on Database Research
Research areas.
Data Management
Meet the groups behind our innovation
Our teams advance the state of the art through research, systems engineering, and collaboration across Google.

The beckman report on database research
Preserved fulltext.

- Update Request & User Guide (TAU staff only)
The beckman report on database research
Daniel Abadi, Rakesh Agrawal, Anastasia Ailamaki, Magdalena Balazinska, Philip A. Bernstein, Michael J. Carey, Surajit Chaudhuri, Jeffrey Dean, Anhai Doan, Michael J. Franklin, Johannes Gehrke, Laura M. Haas, Alon Y. Halevy, Joseph M. Hellerstein, Yannis E. Ioannidis, H. V. Jagadish, Donald Kossmann, Samuel Madden, Sharad Mehrotra, Tova Milo Jeffrey F. Naughton, Raghu Ramakrishnan, Volker Markl, Christopher Olston, Beng Chin Ooi, Christopher Ré, Dan Suciu, Michael Stonebraker, Todd Walter, Jennifer Widom Show 10 others Show less
- School of Computer Science
Research output : Contribution to journal › Article › peer-review
Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that Big Data has now become a defining challenge of our time, and that the database research community is uniquely positioned to address it, with enormous opportunities to make transformative impact. To do so, the report recommends significantly more attention to five research areas: scalable big/fast data infrastructures; coping with diversity in the data management landscape; end-to-end processing and understanding of data; cloud services; and managing the diverse roles of people in the data life cycle.
Access to Document
- 10.1145/2694428.2694441
Other files and links
- Link to publication in Scopus
Fingerprint
- Information management Engineering & Materials Science 100%
- Big data Engineering & Materials Science 97%
- Life cycle Engineering & Materials Science 93%
T1 - The beckman report on database research
AU - Abadi, Daniel
AU - Agrawal, Rakesh
AU - Ailamaki, Anastasia
AU - Balazinska, Magdalena
AU - Bernstein, Philip A.
AU - Carey, Michael J.
AU - Chaudhuri, Surajit
AU - Dean, Jeffrey
AU - Doan, Anhai
AU - Franklin, Michael J.
AU - Gehrke, Johannes
AU - Haas, Laura M.
AU - Halevy, Alon Y.
AU - Hellerstein, Joseph M.
AU - Ioannidis, Yannis E.
AU - Jagadish, H. V.
AU - Kossmann, Donald
AU - Madden, Samuel
AU - Mehrotra, Sharad
AU - Milo, Tova
AU - Naughton, Jeffrey F.
AU - Ramakrishnan, Raghu
AU - Markl, Volker
AU - Olston, Christopher
AU - Ooi, Beng Chin
AU - Ré, Christopher
AU - Suciu, Dan
AU - Stonebraker, Michael
AU - Walter, Todd
AU - Widom, Jennifer
PY - 2014/9/1
Y1 - 2014/9/1
N2 - Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that Big Data has now become a defining challenge of our time, and that the database research community is uniquely positioned to address it, with enormous opportunities to make transformative impact. To do so, the report recommends significantly more attention to five research areas: scalable big/fast data infrastructures; coping with diversity in the data management landscape; end-to-end processing and understanding of data; cloud services; and managing the diverse roles of people in the data life cycle.
AB - Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that Big Data has now become a defining challenge of our time, and that the database research community is uniquely positioned to address it, with enormous opportunities to make transformative impact. To do so, the report recommends significantly more attention to five research areas: scalable big/fast data infrastructures; coping with diversity in the data management landscape; end-to-end processing and understanding of data; cloud services; and managing the diverse roles of people in the data life cycle.
UR - http://www.scopus.com/inward/record.url?scp=84916884800&partnerID=8YFLogxK
U2 - 10.1145/2694428.2694441
DO - 10.1145/2694428.2694441
M3 - ???researchoutput.researchoutputtypes.contributiontojournal.article???
AN - SCOPUS:84916884800
SN - 0163-5808
JO - SIGMOD Record
JF - SIGMOD Record
The Beckman Report on Database Research
Content maybe subject to copyright Report
194 citations
152 citations
62 citations
View 1 citation excerpt
Cites background from "The Beckman Report on Database Rese..."
... In this new setting five research areas in the database community became critical [1]: (i) scalable big/fast data infrastructures; (ii) ability to cope with diversity in the data management landscape; (iii) end-to-end processing and understanding of data; (iv) cloud services; and (v) managing the diverse roles of people in the data life cycle. ...
61 citations
View 4 citation excerpts
... The first such meeting was held in conjunction with VLDB 1988 [3] and the last one prior to Seattle took place in Irvine in 2013 [2]. ...
... While we have made progress in some of the key challenges articulated in the last report [2], many of the di cult questions remain relevant today. ...
... In fact, the last report identified Big Data as our field’s central challenge [2]. ...
... The last report observed that “Cloud Computing has become mainstream” [2], and indeed, usage of managed cloud data systems has grown tremendously in the last five years. ...
59 citations
226 citations
218 citations
215 citations
208 citations
203 citations
Related Papers (5)
Ask Copilot
Related papers
Contributing institutions
Related topics
Help | Advanced Search
Computer Science > Computation and Language
Title: realm: reference resolution as language modeling.
Abstract: Reference resolution is an important problem, one that is essential to understand and successfully handle context of different kinds. This context includes both previous turns and context that pertains to non-conversational entities, such as entities on the user's screen or those running in the background. While LLMs have been shown to be extremely powerful for a variety of tasks, their use in reference resolution, particularly for non-conversational entities, remains underutilized. This paper demonstrates how LLMs can be used to create an extremely effective system to resolve references of various types, by showing how reference resolution can be converted into a language modeling problem, despite involving forms of entities like those on screen that are not traditionally conducive to being reduced to a text-only modality. We demonstrate large improvements over an existing system with similar functionality across different types of references, with our smallest model obtaining absolute gains of over 5% for on-screen references. We also benchmark against GPT-3.5 and GPT-4, with our smallest model achieving performance comparable to that of GPT-4, and our larger models substantially outperforming it.
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
Published on
‘Landmark in survey research’: How the COVID States Project analyzed the pandemic with objectivity
Four years ago David Lazer formed the Northeastern-led effort — resulting in more than 100 cutting-edge reports and national media coverage.
David Lazer ran into a fellow Northeastern University professor Alessandro Vespignani . It was February 2020. One month before the COVID-19 shutdowns.
“I said, ‘Tell me: How bad is it going to be?’” says Lazer, University Distinguished Professor of Political Science and Computer Sciences at Northeastern. “And he laid out how bad it would be.”
They were facing a life-changing event, warned Vespignani, director of the Network Science Institute and Sternberg Family Distinguished Professor at Northeastern. SARS-CoV-2, the virus that causes COVID-19, was spreading fast throughout the U.S. and beyond just three months after its emergence in Wuhan, China.
“He talked about how things were going to shut down over the following month and how there was going to be an indefinite time of having to modify our lives in order to protect ourselves individually and collectively,” Lazer recalls of that conversation. “He really got the broad parameters spot on.
“I obviously was quite distressed. I was thinking, ‘What can I do to contribute to the moment?’”
The answer would become known as the COVID States Project , a Northeastern-led effort by four universities that would analyze newly collected data in order to make sense of the evolving and volatile COVID-19 pandemic.
Over the next four years the project would put out more than 100 reports — all relevant to urgent issues — that were reflected by media coverage across the country.
Sharing their expertise across a variety of fields — computational social science, network science, public opinion polling, epidemiology, public health, psychiatry, communication and political science — the researchers framed and conducted surveys that enabled them to identify national and regional trends that influenced (and were influenced by) the spread of the virus.
“It was an act of improvisation — we didn’t know exactly what we were going to do,” Lazer says. “But we felt quite committed to having a positive impact and using our tools, our skill set, to do something during this horrible moment.”Built into their real-time research was an understanding that social behaviors would play a large role in a pandemic that has claimed close to 1.2 million lives nationally, according to the Centers for Disease Control and Prevention (though there is reason to believe many more people have died ).

The project’s surveys and reports reflected national moods and trends while also providing reliable information for policymakers at a time when the future was difficult to predict.
“David, being a political scientist, told me that he had this idea that a survey would be helpful,” says Mauricio Santillana , an original member of the COVID States Project who has since joined Northeastern as director of the Machine Intelligence Group for the betterment of Health and the Environment (MIGHTE) at the Network Science Institute. “I told him it was very appropriate because rather than seeing a population reaction to a public health crisis, the pandemic was evolving into a sociological problem — one where people were reacting more from their political views rather than scientific evidence.
“He had this idea of having a project where we could monitor people’s feelings, emotions and their changing behaviors in response to pronounced increases in COVID-19 infections and we could record their political affiliations,” adds Santillana, who was focused on mathematically modeling the pandemic. “The project became a really important tool for me to understand why things were getting worse and worse.”
Their work was based in objectivity — the need to respect all points of view while prioritizing understanding and dismissing judgment.
“By shedding light on things in a way that has visibility,” Lazer says, “one hopes that you are informing individual people who are reading about our stories in the media as well as policy elites about what decisions should be made.”
‘The best data out there’
It began with Lazer contacting colleagues at other universities. The COVID States Project became an effort coordinated by Lazer, Santillana, Matthew Baum and Roy Perlis of Harvard, Katherine Ognyanova of Rutgers and James Druckman of Northwestern. Weekly meetings were held at 10 a.m. on Fridays as the project grew to include undergraduate and postdoctoral students — all contributing on a volunteer basis.
“We went out into the field in April and we started collecting data,” Lazer says. “We realized that we could get useful results for all 50 states. We could see the numbers pile up and that was an exciting moment, like, maybe this thing can actually work.”
Northeastern provided the startup funding (and many of the volunteers, and much of the person power, as authors of project reports included three postdoctoral fellows and six students from Northeastern). Additional financial support would come from the National Science Foundation, the National Institutes of Health and other supporters that enabled the project to grow and expand. The project’s work on COVID-19 is continuing even now.
“We’re still putting out data on vaccination rates and infection rates,” says Lazer, whose team relied on a third-party vendor for online surveys that represent a new frontier for public polling. “It turns out that our data are better than the official data, because the official data are seriously flawed in important ways.”
Those official numbers can be faulty because individual states have difficulty linking residents with the number of vaccinations they’ve received, says Lazer.
The COVID States Project team has learned how to not only frame questions with the precision to deal with relevant issues, but also to re-weigh the answers to provide representative analysis.
“If you want to know the vaccination rates of a given state, I think our data are the best data out there,” Lazer says. “It’s pretty mind-blowing that we have done 1,400 to 1,500 state-level surveys.”
Initial efforts were focused on understanding the basics of the pandemic. While all 50 states were developing plans to reopen for business in June 2020, the project found that most people preferred a more cautious approach, with only 15% of respondents favoring an immediate reopening.
“The project is a landmark in survey research,” says Alexi Quintana Mathé , a fourth-year Ph.D. student working with Lazer at Northeastern. “We surveyed more than 20,000 respondents roughly every month, with viable samples in every U.S. state and good representativity of the general population. This allowed us to closely monitor behaviors, opinions and consequences of the COVID-19 pandemic across the country with a special focus on differences by state, which were particularly relevant during the pandemic.”
Their work was able to show that Black people waited longer for test results than other people in the U.S.
“It’s important to illuminate and create accountability,” Lazer says.
The project’s tracking of social distance behaviors in October 2020 helped predict which states would experience surges the following month.
A survey in summer 2020 accurately predicted the rates of people who would submit to vaccinations when the shots became available that December. Another survey was able to show which demographic groups would be reluctant to be vaccinated.
“The team found that concerns over vaccine safety, as well as distrust, were key reasons [for reluctance],” says Kristin Lunz Trujillo, now a University of South Carolina assistant professor of political science who worked on the COVID States Project as a Northeastern postdoctoral fellow. “This report sparked a lot of other ongoing work on the project and gave a fuller picture of COVID vaccine hesitancy than what our typical survey measures provided.”
“People still needed to be convinced, and I think that was a very natural response,” says Santillana, a Northeastern professor of physics and electrical and computer engineering. “The fact that people were concerned about their health when being exposed to a vaccine is a natural thing. But that was being interpreted as, ‘Oh, then you are a denier.’ There was no room to be a normal person who wants to learn as we experience things. For me, being a mathematician and physicist and hearing my political-scientist colleagues discussing issues of trust in medical research and medical professionals, it became a multidisciplinary learning experience.”
A constructive role by academia
In the midst of their COVID-19 work, the researchers delved into other major U.S. events. They were able to identify the demographics of the widespread Black Lives Matter protests that followed the May 2020 murder of George Floyd. And they were able to show that those outdoor protests did not result in upsurges of pandemic-related illness.
“The diverse expertise of scientists on the project meant that we could investigate public health issues both broadly and deeply,” says Alauna Safarpour, a Northeastern postdoctoral contributor to the project who now serves as assistant professor of political science at Gettysburg College. “We not only analyzed misinformation related to the pandemic, vaccine skepticism and depression/mental health concerns, but also abortion attitudes, support for political violence and even racism as a public health concern.”
In anticipation of the role that mail-in ballots would play in the 2020 election, the project anticipated which state results would change as the late-arriving votes were counted.
“We had a piece predicting the shift after Election Day,” Lazer says. “We said there’s going to be a shift towards Biden in some states and it will be a very large shift — and we got the states right, we got the estimates right.
“We were trying to prepare people that there was nothing fishy going on here. That this is what is expected.”
After the insurrection of Jan. 6, 2021, the project predicted accurately that Donald Trump would retain his influence as leader of the Republic Party.
“There were a lot of people right after Jan. 6 who said Trump is finished,” Lazer says. “We went into the field a couple of days later, did a survey and we said, ‘The [typical] Republican believes the election was stolen and says Trump’s endorsement would still matter a lot.’”
The Supreme Court’s overturning of Roe v. Wade in June 2022 was followed by a COVID States Project report accurately forecasting a Democratic backlash .
“There’s a story here around the constructive role that academia can play in moments of crisis — the tools that we have are really quite practical,” Lazer says. “As the information ecosystem of our country has diminished — we see the news media firing people left and right — there is a role for universities to take some of that capacity for creating knowledge and translating that to help with the crises of the day.”
Next up: CHIP50
“It uncovered the impact of the social and political changes that Americans went through over the last four years at the national level, but more importantly it broke down the findings to demographic and regional groups,” says Ata Aydin Uslu , a third-year Ph.D. student at the Lazer Lab at Northeastern. “I see CSP as a successful attempt to mic up the American public. We enabled Americans to make their point to the local and federal decision-makers, and the decision-makers to make informed decisions and resource allocations — something that was of utmost importance during a once-in-a-century crisis.”
Entering its fifth year, the project is taking on an identity to reflect the changing times. The newly named Civic Health and Institutions Project, a 50 States Survey (CHIP50) is building on the lessons learned by the COVID States Project team during the pandemic.
“The idea is to institutionalize the notion of doing 50 state surveys in a federal country,” Lazer says. “We have this perspective on states that no other research ever has.”
Their ongoing work will include competitions to add questions from outside scholars, Lazer says. “We’re still going to issue reports, but less often, and we’re going to be turning more to scholarship while still trying to get that translational element of what does this mean, what people should think, what policymakers should do and so on.”
During a recent interview, as Lazer is recounting the work of the past four years via a Zoom call, his head is bobbing back and forth. When the pandemic forced him to isolate, he explains, he made a habit of working while walking a treadmill in his attic. At times he was responding to the pressures of the pandemic by working 16 hours while logging 40,000 steps daily — and developing plantar fasciitis along the way.
“All of this has made me think much more about the underlying sociological and psychological realities of how people process information — and the role that trust in particular plays,” Lazer says. “It has really shaped my thinking about what is core in understanding politics.”
Ian Thomsen is a Northeastern Global News reporter. Email him at [email protected] . Follow him on X/Twitter @IanatNU .
- Copy Link Link Copied!
Forced labor in the clothing industry is rampant and hidden. This AI-powered search platform can expose it.
Supply Trace combines AI with on-the-ground investigation to trace apparel to regions with a high risk of forced labor.

This Northeastern graduate thinks you’d be perfect for ‘The Amazing Race’
As a casting professional, Alex Sharp has unearthed talent for reality competition shows including ‘Lego Masters’ and ‘Chopped.’

Mike Sirota, rated as a high first-round pick, could be Northeastern’s greatest baseball player
Sirota, a 6-foot-3-inch junior, is ranked among the top 11 picks overall in the upcoming Major League Baseball Draft.

We can’t combat climate change without changing minds. This psychology class explores how.
PSYC-4660: Humans & Nature is part of a larger push at Northeastern to explore the intersection between environmental and brain sciences.

Daniel Gwynn sat on death row for 30 years. Meet the Northeastern law grad who helped set him free
“We’re lifting up the humanity of our clients,” says Gretchen Engel, a 1992 graduate of Northeastern School of Law.

No sign of greenhouse gases increases slowing in 2023
- April 5, 2024
Levels of the three most important human-caused greenhouse gases – carbon dioxide (CO 2 ), methane and nitrous oxide – continued their steady climb during 2023, according to NOAA scientists.
While the rise in the three heat-trapping gases recorded in the air samples collected by NOAA’s Global Monitoring Laboratory (GML) in 2023 was not quite as high as the record jumps observed in recent years, they were in line with the steep increases observed during the past decade.
“NOAA’s long-term air sampling program is essential for tracking causes of climate change and for supporting the U.S. efforts to establish an integrated national greenhouse gas measuring, monitoring and information system,” said GML Director Vanda Grubišić. “As these numbers show, we still have a lot of work to do to make meaningful progress in reducing the amount of greenhouse gases accumulating in the atmosphere.”
The global surface concentration of CO 2 , averaged across all 12 months of 2023, was 419.3 parts per million (ppm), an increase of 2.8 ppm during the year. This was the 12th consecutive year CO 2 increased by more than 2 ppm, extending the highest sustained rate of CO 2 increases during the 65-year monitoring record. Three consecutive years of CO 2 growth of 2 ppm or more had not been seen in NOAA’s monitoring records prior to 2014. Atmospheric CO 2 is now more than 50% higher than pre-industrial levels.
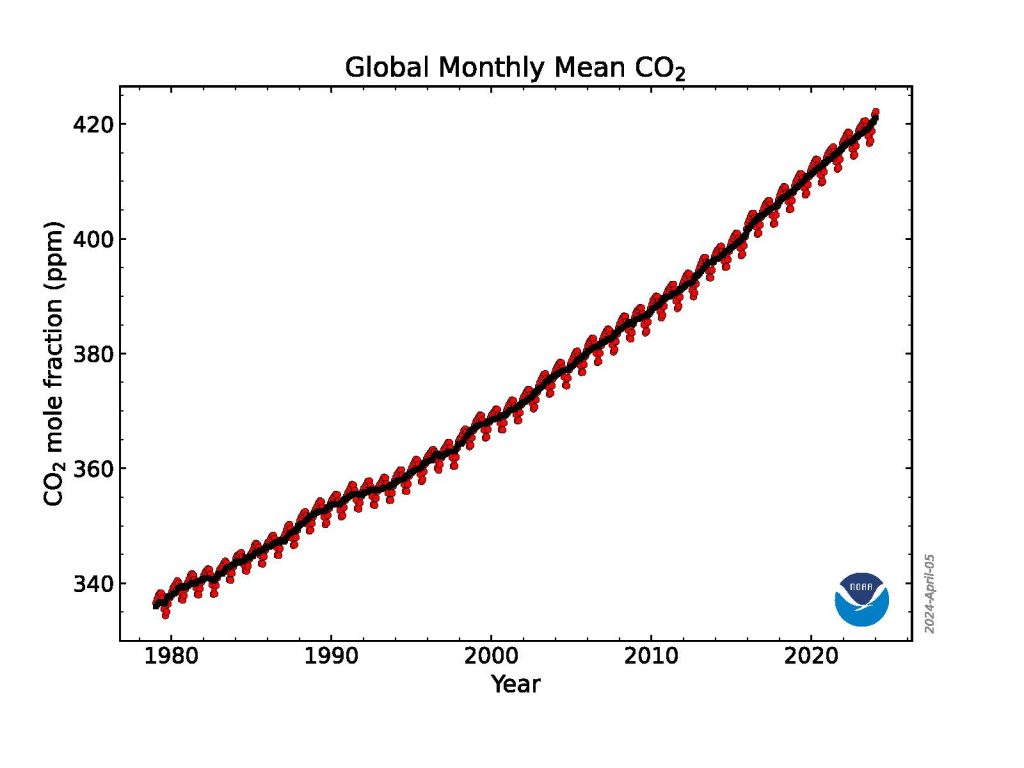
This graph shows the globally averaged monthly mean carbon dioxide abundance measured at the Global Monitoring Laboratory’s global network of air sampling sites since 1980. Data are still preliminary, pending recalibrations of reference gases and other quality control checks. Credit: NOAA GML
“The 2023 increase is the third-largest in the past decade, likely a result of an ongoing increase of fossil fuel CO 2 emissions, coupled with increased fire emissions possibly as a result of the transition from La Nina to El Nino,” said Xin Lan, a CIRES scientist who leads GML’s effort to synthesize data from the NOAA Global Greenhouse Gas Reference Network for tracking global greenhouse gas trends .
Atmospheric methane, less abundant than CO 2 but more potent at trapping heat in the atmosphere, rose to an average of 1922.6 parts per billion (ppb). The 2023 methane increase over 2022 was 10.9 ppb, lower than the record growth rates seen in 2020 (15.2 ppb), 2021(18 ppb) and 2022 (13.2 ppb), but still the 5th highest since renewed methane growth started in 2007. Methane levels in the atmosphere are now more than 160% higher than their pre-industrial level.
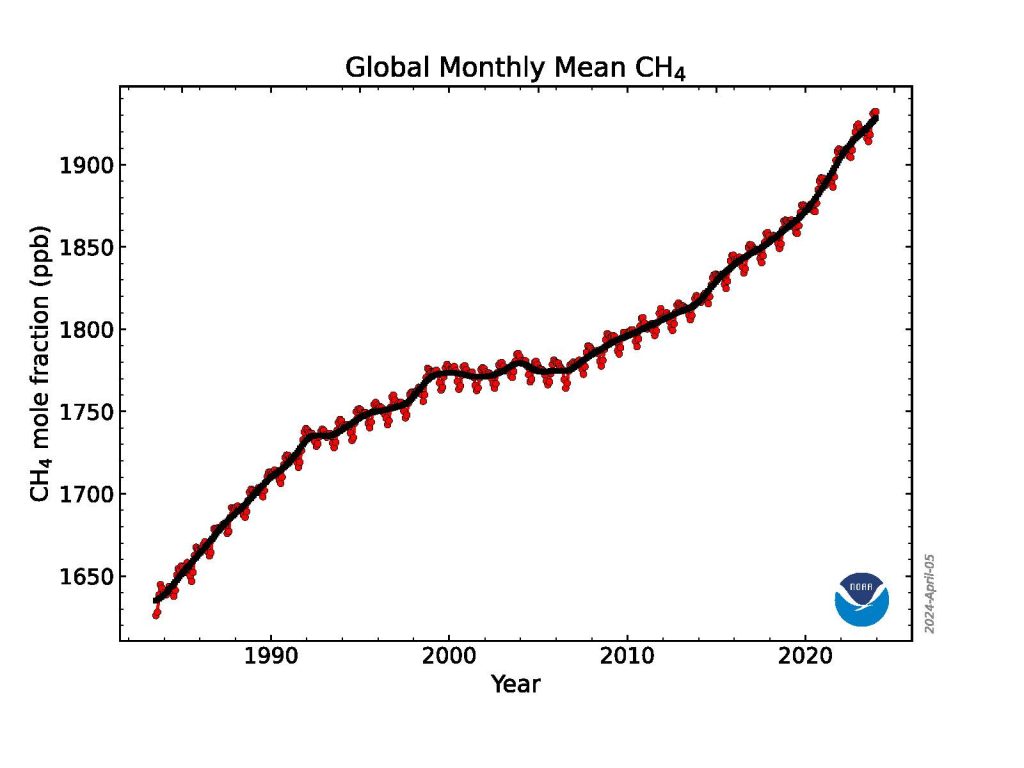
This graph shows globally-averaged, monthly mean atmospheric methane abundance determined from marine surface sites for the full NOAA time-series starting in 1983. Values for the last year are preliminary, pending recalibrations of standard gases and other quality control steps. Credit: NOAA GM
In 2023, levels of nitrous oxide, the third-most significant human-caused greenhouse gas, climbed by 1 ppb to 336.7 ppb. The two years of highest growth since 2000 occurred in 2020 (1.3 ppb) and 2021 (1.3 ppb). Increases in atmospheric nitrous oxide during recent decades are mainly from use of nitrogen fertilizer and manure from the expansion and intensification of agriculture. Nitrous oxide concentrations are 25% higher than the pre-industrial level of 270 ppb.
Taking the pulse of the planet one sample at a time NOAA’s Global Monitoring Laboratory collected more than 15,000 air samples from monitoring stations around the world in 2023 and analyzed them in its state-of-the-art laboratory in Boulder,
Colorado. Each spring, NOAA scientists release preliminary calculations of the global average levels of these three primary long-lived greenhouse gases observed during the previous year to track their abundance, determine emissions and sinks, and understand carbon cycle feedbacks.
Measurements are obtained from air samples collected from sites in NOAA’s Global Greenhouse Gas Reference Network , which includes about 53 cooperative sampling sites around the world, 20 tall tower sites, and routine aircraft operation sites from North America.
Carbon dioxide emissions remain the biggest problem
By far the most important contributor to climate change is CO 2 , which is primarily emitted by burning of fossil fuels. Human-caused CO 2 pollution increased from 10.9 billion tons per year in the 1960s – which is when the measurements at the Mauna Loa Observatory in Hawaii began – to about 36.6 billion tons per year in 2023. This sets a new record, according to the Global Carbon Project , which uses NOAA’s Global Greenhouse Gas Reference Network measurements to define the net impact of global carbon emissions and sinks.
The amount of CO 2 in the atmosphere today is comparable to where it was around 4.3 million years ago during the mid- Pliocene epoch , when sea level was about 75 feet higher than today, the average temperature was 7 degrees Fahrenheit higher than in pre-industrial times, and large forests occupied areas of the Arctic that are now tundra.
About half of the CO 2 emissions from fossil fuels to date have been absorbed at the Earth’s surface, divided roughly equally between oceans and land ecosystems, including grasslands and forests. The CO 2 absorbed by the world’s oceans contributes to ocean acidification, which is causing a fundamental change in the chemistry of the ocean, with impacts to marine life and the people who depend on them. The oceans have also absorbed an estimated 90% of the excess heat trapped in the atmosphere by greenhouse gases.
Research continues to point to microbial sources for rising methane
NOAA’s measurements show that atmospheric methane increased rapidly during the 1980s, nearly stabilized in the late-1990s and early 2000s, then resumed a rapid rise in 2007.
A 2022 study by NOAA and NASA scientists and additional NOAA research in 2023 suggests that more than 85% of the increase from 2006 to 2021 was due to increased microbial emissions generated by livestock, agriculture, human and agricultural waste, wetlands and other aquatic sources. The rest of the increase was attributed to increased fossil fuel emissions.
“In addition to the record high methane growth in 2020-2022, we also observed sharp changes in the isotope composition of the methane that indicates an even more dominant role of microbial emission increase,” said Lan. The exact causes of the recent increase in methane are not yet fully known.
NOAA scientists are investigating the possibility that climate change is causing wetlands to give off increasing methane emissions in a feedback loop.
To learn more about the Global Monitoring Laboratory’s greenhouse gas monitoring, visit: https://gml.noaa.gov/ccgg/trends/.
Media Contact: Theo Stein, [email protected] , 303-819-7409

5 science wins from the 2023 NOAA Science Report

Filling A Data Gap In The Tropical Pacific To Reveal Daily Air-Sea Interactions

Scientists detail research to assess viability and risks of marine cloud brightening

How social science helps us combat climate change
Popup call to action.
A prompt with more information on your call to action.
AI Index Report
The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Our mission is to provide unbiased, rigorously vetted, broadly sourced data in order for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The report aims to be the world’s most credible and authoritative source for data and insights about AI.
Read the 2023 AI Index Report

Coming Soon: 2024 AI Index Report!
The 2024 AI Index Report will be out April 15! Sign up for our mailing list to receive it in your inbox.
Steering Committee Co-Directors

Ray Perrault
Steering committee members.

Erik Brynjolfsson

John Etchemendy

Katrina Ligett

Terah Lyons

James Manyika

Juan Carlos Niebles

Vanessa Parli

Yoav Shoham

Russell Wald
Staff members.

Loredana Fattorini

Nestor Maslej
Letter from the co-directors.
AI has moved into its era of deployment; throughout 2022 and the beginning of 2023, new large-scale AI models have been released every month. These models, such as ChatGPT, Stable Diffusion, Whisper, and DALL-E 2, are capable of an increasingly broad range of tasks, from text manipulation and analysis, to image generation, to unprecedentedly good speech recognition. These systems demonstrate capabilities in question answering, and the generation of text, image, and code unimagined a decade ago, and they outperform the state of the art on many benchmarks, old and new. However, they are prone to hallucination, routinely biased, and can be tricked into serving nefarious aims, highlighting the complicated ethical challenges associated with their deployment.
Although 2022 was the first year in a decade where private AI investment decreased, AI is still a topic of great interest to policymakers, industry leaders, researchers, and the public. Policymakers are talking about AI more than ever before. Industry leaders that have integrated AI into their businesses are seeing tangible cost and revenue benefits. The number of AI publications and collaborations continues to increase. And the public is forming sharper opinions about AI and which elements they like or dislike.
AI will continue to improve and, as such, become a greater part of all our lives. Given the increased presence of this technology and its potential for massive disruption, we should all begin thinking more critically about how exactly we want AI to be developed and deployed. We should also ask questions about who is deploying it—as our analysis shows, AI is increasingly defined by the actions of a small set of private sector actors, rather than a broader range of societal actors. This year’s AI Index paints a picture of where we are so far with AI, in order to highlight what might await us in the future.
- Jack Clark and Ray Perrault
Our Supporting Partners

Analytics & Research Partners

Stay up to date on the AI Index by subscribing to the Stanford HAI newsletter.
- About Communications
- ACM Resources
- Alerts & Feeds
Communications of the ACM
The beckman report on database research.

Credit: Maksim Kabakou
A group of database researchers meets periodically to discuss the state of the field and its key directions going forward. Past meetings were held in 1989, 6 1990, 11 1995, 12 1996, 10 1998, 7 2003, 1 and 2008. 2 Continuing this tradition, 28 database researchers and two invited speakers met in October 2013 at the Beckman Center on the University of California-Irvine campus for two days of discussions. The meeting attendees represented a broad cross-section of interests, affiliations, seniority, and geography. Attendance was capped at 30 so the meeting would be as interactive as possible. This article summarizes the conclusions from that meeting; an extended report and participant presentations are available at http://beckman.cs.wisc.edu .
Back to Top
- Key Insights
The meeting participants quickly converged on big data as a defining challenge of our time. Big data arose due to the confluence of three major trends. First, it has become much cheaper to generate a wide variety of data, due to inexpensive storage, sensors, smart devices, social software, multiplayer games, and the Internet of Things, which connects homes, cars, appliances, and other devices. Second, it has become much cheaper to process large amounts of data, due to advances in multicore CPUs, solid state storage, inexpensive cloud computing, and open source software. Finally, data management has become democratized. The process of generating, processing, and consuming data is no longer just for database professionals. Decision makers, domain scientists, application users, journalists, crowd workers, and everyday consumers now routinely do it.
Due to these trends, an unprecedented volume of data needs to be captured, stored, queried, processed, and turned into knowledge. These goals are remarkably well aligned with those that have driven the database research community for decades. Many early systems for big data abandoned database management system (DBMS) principles, such as declarative programming and transactional data consistency, in favor of scalability and fault tolerance on commodity hardware. However, the latest generation of big data systems is rediscovering the value of these principles and is adopting concepts and methods that have been long-standing assets of the database community. Building on these principles and assets, the database community is well positioned to drive transformative improvements to big data technology.
But big data also brings enormous challenges, whose solutions will require massive disruptions to the design, implementation, and deployment of data management solutions. The main characteristics of big data are volume, velocity, and variety. The database community has worked on volume and velocity for decades, and has developed solutions that are mission critical to virtually every commercial enterprise on the planet. The unprecedented scale of big data, however, will require a radical rethinking of existing solutions.
Variety arises from several sources. First, there is the problem of integrating and analyzing data that comes from diverse sources, with varying formats and quality. This is another long-standing topic of database work, yet it is still an extremely laborintensive journey from raw data to actionable knowledge. This problem is exacerbated by big data, causing a major bottleneck in the data processing pipeline. Second, there is the variety of computing platforms needed to process big data: hardware infrastructures; processing frameworks, languages, and systems; and programming abstractions. Finally, there is a range of user sophistication and preferences. Designing data management solutions that can cope with such extreme variety is a difficult challenge.
Moving beyond the three Vs, many big data applications will be deployed in the cloud, both public and private, on a massive scale. This requires new techniques to offer predictable performance and flexible interoperation. Many applications will also require people to solve semantic problems that still bedevil current automatic solutions. This can range from a single domain expert to a crowd of workers, a user community, or the entire connected world (for example, Wikipedia). This will require new techniques to help people be more productive and to reduce the skill level needed to solve these problems.
Many big data applications will be deployed in the cloud, both public and private, on a massive scale. This requires new techniques to offer predictable performance and flexible interoperation.
Finally, big data brings important community challenges. We must rethink the approach to teaching data management, reexamine our research culture, and adapt to the emergence of data science as a discipline.
- Research Challenges
The meeting identified five big data challenges: scalable big/fast data infrastructures; coping with diversity in data management; end-to-end processing of data; cloud services; and the roles of people in the data life cycle. The first three challenges deal with the volume, velocity, and variety aspects of big data. The last two deal with deploying big data applications in the cloud and managing the involvement of people in these applications.
These big data challenges are not an exclusive agenda to be pursued at the expense of existing work. In recent years the database community has strengthened core competencies in relational DBMSs and branched out into many new directions. Some important issues raised repeatedly during the meeting are security, privacy, data pricing, data attribution, social and mobile data, spatiotemporal data, personalization and contextualization, energy-constrained processing, and scientific data management. Many of these issues cut across the identified big data challenges and are captured in the discussion here.
It is important to note that some of this work is being done in collaboration with other computer science fields, including distributed systems, artificial intelligence, knowledge discovery and data mining, human-computer interaction, and e-science. In many cases, these fields provided the inspiration for the topic and the data management community has joined in, applying its expertise to produce robust solutions. These collaborations have been very productive and should continue to grow.
Scalable big/fast data infrastructures. Parallel and distributed processing. In the database world, parallel processing of large structured datasets has been a major success, leading to several generations of SQL-based products that are widely used by enterprises. Another success is data warehousing, where database researchers defined the key abstraction of data cube (for online analytic processing, or OLAP) and strategies for querying it in parallel, along with support for materialized views and replication. The distributed computing field has achieved success in scaling up data processing for less structured data on large numbers of unreliable, commodity machines using constrained programming models such as MapReduce. Higher-level languages have been layered on top, to enable a broader audience of developers to use scalable big data platforms. Today, open source platforms such as Hadoop 3 —with its MapReduce programming model, large-scale distributed file system, and higher-level languages, such as Pig 5 and Hive 4 —are seeing rapid adoption for processing less structured data, even in traditional enterprises.
Query processing and optimization. Given the enthusiastic adoption of declarative languages for processing big data, there is a growing recognition that more powerful cost-aware query optimizers and set-oriented query execution engines are needed, to fully exploit large clusters of many-core processors, scaling both "up" and "out." This will create challenges for progress monitoring, so a user can diagnose and manage queries that are running too slowly or consuming excessive resources. To adapt to the characteristics of previously unseen data and reduce the cost of data movement between stages of data analysis, query processors will need to integrate data sampling, data mining, and machine learning into their flows.
New hardware. At datacenter scale, the ratio between the speed of sequential processing and interconnects is changing with the advent of faster networks, full bisection bandwidth networks between servers, and remote direct memory access. In addition to clusters of general-purpose multicore processors, more specialized processors should be considered. Commercially successful database machines have shown the potential of hardwaresoftware co-design for data management. Researchers should continue to explore ways of leveraging specialized processors, for example, graphics processing units, field-programmable gate arrays, and application-specific integrated circuits, for processing very large datasets. These changes in communications and processing technologies will require a reconsideration of parallel and distributed query-processing algorithms, which have traditionally focused on more homogeneous hardware environments.
Cost-efficient storage. The database research community must learn how best to leverage emerging memory and storage technologies. Relative to commodity magnetic disks, solid-state disks are expensive per gigabyte but cheap per I/O operation. Various nonvolatile random-access memory technologies are under development, all with different speed, power, and durability characteristics.
Both server-attached and network-attached storage architectures need to be considered. Distributed file systems like HDFS, which are server-attached yet shared across the network, are a hybrid of both approaches. How best to use this range of storage configurations reopens many questions reminiscent of past debates of shared memory vs. shared disk vs. shared nothing, questions many have considered to be "closed" for parallel relational systems.
High-speed data streams. For data that arrives at ever-higher speeds, new scalable techniques for ingesting and processing streams of data will be needed. Algorithms will need to be tuned carefully to the behavior of hardware, for example, to cope with non-uniform memory access and limited transfer rates across layers of the memory hierarchy. Some very high-speed data sources, often with lower information density, will need to be processed online and then discarded without being persisted in its entirety. Rather, samples and aggregations of such data will need to be selected and stored persistently to answer queries that arrive after the raw data is no longer available. For such data, progressive query processing will be important to provide incremental and partial results with increasing accuracy as data flows through the processing pipeline.
Late-bound schemas. For data that is persisted but processed just once (if ever), it makes little sense to pay the substantial price of storing and indexing it first in a database system. Instead, it should be stored as a binary file and interpreted as a structured record only if and when it is read later. Record structure may be self-describing via attribute-value pairs, such as JavaScript Object Notation (JSON), interpreted via predefined schemas, or deduced using data mining. To offer the benefits of database queries in such scenarios, we need query engines that can run efficiently over raw files with late-bound schemas.
Consistency. Today's world brings new requirements for data capture, updates, and simple and fast data access. Handling high rates of data capture and updates for schema-less data has led to the development of NoSQL systems. There are many such systems, with a range of transaction models. Most provide only basic data access and weak atomicity and isolation guarantees, making it difficult to build and reason about reliable applications. As a result, a new class of big data system has emerged that provides full-fledged database-like features over key-value stores or similar substrates. For some applications, the stored data is still managed and updated as "the source of truth" for an enterprise. For others, such as the Internet of Things, the stored data reflects ongoing events in the outside world that applications can use to recognize and respond to situations of interest. This creates an opportunity to revisit programming models and mechanisms for data currency and consistency and to design new models and techniques for developing robust applications.
Metrics and benchmarks. Finally, scalability should be measured not only in petabytes of data and queries per second, but also total cost of ownership (including management and energy use), end-to-end processing speed (that is, time from raw data arrival to eventual insights), brittleness (for example, the ability to continue despite failures such as partial data parse errors), and usability (especially for entry-level users). To measure progress against such broader metrics, new types of benchmarks will be required.
Diversity in data management. No one-size-fits-all. Today's data-driven world involves a richer variety of data types, shapes, and sizes than traditional enterprise data, which is stored in a data warehouse optimized for analysis tasks. Today, data is often stored in different representations managed by different software systems with different application programming interfaces, query processors, and analysis tools. It seems unlikely a single, one-size-fits-all, big data system will suffice for this degree of diversity. Instead, we expect multiple classes of systems to emerge, each addressing a particular need (for example, data deduplication, analysis of large graphs, diverse scientific experiments, and real-time stream processing) or exploiting a particular type of hardware platform (for example, clusters of inexpensive machines or large multicore servers). Addressing these scenarios will require applying expertise in set-oriented parallel processing and in efficiently handling datasets that do not fit in main memory.
Cross-platform integration. Given this diversity of systems, platforms will need to be integrated or federated to enable data analysts to combine and analyze data across systems. This will involve not only hiding the heterogeneity of data formats and access languages, but also optimizing the performance of accesses that span diverse big data systems and of flows that move data between them. It will also require managing systems that run on diverse devices and span large datacenters. Disconnected devices will become increasingly common, raising challenges in reliable data ingestion, query processing, and data inconsistency in such sometimes-connected, wide-area environments.
Programming models. A diverse and data-driven world requires diverse programming abstractions to operate on very large datasets. A single data analysis language for big data, such as an extension of SQL, will not meet everyone's needs. Rather, users must be able to analyze their data in the idiom they find most natural: SQL, Pig, R, Python, a domain-specific language, or a lower-level constrained programming model such as MapReduce or Valiant's bulk synchronous processing model. This also suggests the development of reusable middle-layer components that can support multiple language-specific bindings, such as scalable support for matrix multiplication, list comprehension, and stylized iterative execution models. Another potentially fruitful focus is tools for the rapid development of new domain-specific data analysis languages—tools that simplify the implementation of new scalable, data-parallel languages.
Data processing workflows. To handle data diversity, we need platforms that can span both "raw" and "cooked" data. The cooked data can take many forms, for example, tables, matrices, or graphs. Systems will run end-to-end workflows that mix multiple types of data processing, for example, querying data with SQL and then analyzing it with R. To unify diverse systems, lazy computation is sometimes beneficial—lazy data parsing, lazy conversion and loading, lazy indexing and view construction, and just-in-time query planning. Big data systems should become more interoperable like "Lego bricks." Cluster resource managers, such as Hadoop 2.0's YARN, provide some inspiration at the systems level, as do workflow systems for the Hadoop ecosystem and tools for managing scientific workflows.
End-to-end processing of data. The database research community should pay more attention to end-to-end processing of data. Despite years of R&D, surprisingly few tools can go from raw data all the way to extracted knowledge without significant human intervention at each step. For most steps, the intervening people need to be highly computer savvy.
Data-to-knowledge pipeline. The steps of the raw-data-to-knowledge pipeline will be largely unchanged: data acquisition; selection, assessment, cleaning, and transformation (also called "data wrangling"); extraction and integration; mining, OLAP, and analytics; and result summarization, provenance, and explanation. In addition to greater scale, what has significantly changed is the greater diversity of data and users. Data today comes in a wide variety of formats. Often, structured and unstructured data must be used together in a structured fashion. Data tools must exploit human feedback in every step of the analytical pipeline, and must be usable by subject-matter experts, not just by IT professionals. For example, a journalist may want to clean, map, and publish data from a spreadsheet file of crime statistics. Tools must also be tailored to data scientists, the new class of data analysis professionals that has emerged.
Tool diversity. Since no one-size-fits-all tool will cover the wide variety of data analysis scenarios ahead, we need multiple tools, each solving a step of the raw-data-to-knowledge pipeline. They must be seamlessly integrated and easy to use for both lay and expert users, with best-practice guidance on when to use each tool.
Tool customizability. Tools should be able to exploit domain knowledge, such as dictionaries, knowledge bases, and rules. They should be easy to customize to a new domain, possibly using machine learning to automate the customization process. Handcrafted rules will remain important, though, as many analysis applications require very high precision, such as e-commerce. For such applications, analysts often write many rules to cover "corner cases" that are not amenable to learning and generalization. Thus, tools should provide support for writing, evaluating, applying, and managing handcrafted rules.
Open source. Few tools in this area are open source. Most are expensive proprietary products that address certain processing steps. As a result, existing tools cannot easily benefit from ongoing contributions by the data integration research community.
Understanding data. Explanation, provenance, filtering, summarization, and visualization requirements will be critical to making analytic tools easy to use. Capturing and managing appropriate meta-information is key to enable explanation, provenance, reuse, and visualization. Visual analytics is receiving growing attention in the database, visualization, and HCI communities. Continued progress in this area is essential to help users cope with big data volumes.
Knowledge bases. The more knowledge we have about a target domain, the better that tools can analyze the domain. As a result, there has been a growing trend to create, share, and use domain knowledge to better understand data. Such knowledge is often captured in knowledge bases (KBs) that describe the most important entities and relationships in a domain, such as a KB containing profiles of tens of thousands of biomedical researchers along with their publications, affiliations, and patents. Such KBs are used for improving the accuracy of the raw-data-to-knowledge pipeline, answering queries about the domain, and finding domain experts. Many companies have also built KBs for answering user queries, annotating text, supporting e-commerce, and analyzing social media. The KB trend will likely accelerate, leading to a proliferation of community-maintained "knowledge centers" that offer tools to query, share, and use KBs for data analysis.
While some progress has been made on this topic, more work is needed on tools to help groups of users with different skill levels collaboratively build, maintain, query, and share domain-specific KBs.
Cloud services. Cloud computing comes in three main forms: Infrastructure as a Service (IaaS), where the service is virtualized hardware; Platform as a Service (PaaS), where the service is virtualized infrastructure software such as a DBMS; and Software as a Service (SaaS), where the service is a virtualized application such as a customer relationship management solution. From a data platform perspective, the ideal goal is a PaaS for data, where users can upload data to the cloud, query it as they do today over their on-premise SQL databases, and selectively share the data and results easily, all without worrying about how many instances to rent, what operating system to run on, how to partition databases across servers, or how to tune them. Despite the emergence of services such as Database.com from Salesforce.com , Big Query from Google, Redshift from Amazon, and Azure SQL Database from Microsoft, we have yet to achieve the full ideal. Here, we outline some of the critical challenges to realize the complete vision of a Data PaaS in the cloud.
Elasticity. Data can be prohibitively expensive to move. Network-attached storage makes it easier to scale out a database engine. However, network latency and bandwidth limit database performance. Server-attached storage reduces these limitations, but then server failures can degrade availability and failover can interfere with load balancing and hence violate service-level agreements (SLAs).
A diverse and data-driven world requires diverse programming abstractions to operate on very large datasets.
An open question is whether the same cloud storage service can support both transactions and analytics; how caching best fits into the overall picture is also unclear. To provide elasticity, database engines and analysis platforms in a Data PaaS will need to operate well on top of resources that can be allocated quickly during workload peaks but possibly preempted for users paying for premium service.
Data replication. Latency across geographically distributed datacenters makes it difficult to keep replicas consistent yet offer good throughput and response time to updates. Multi-master replication is a good alternative, when conflicting updates on different replicas can be automatically synchronized. But the resulting programming model is not intuitive to mainstream programmers. Thus, the challenge is how best to trade-off availability, consistency performance, programmability, and cost.
System administration and tuning. In the world of Data PaaS, database and system administrators simply do not exist. Therefore, all administrative tasks must be automated, such as capacity planning, resource provisioning, and physical data management. Resource control parameters must also be set automatically and be highly responsive to changes in load, such as buffer pool size and admission control limits.
Multitenancy. To be competitive, a Data PaaS should be cheaper than an on-premises solution. This requires providers to pack multiple tenants together to share physical resources to smooth demand and reduce cost. This introduces several problems. First, the service must give security guarantees against information leakage across tenants. This can be done by isolating user databases in separate files and running the database engine in separate virtual machines (VMs). However, this is inefficient for small databases, and makes it difficult to balance resources between VMs running on the same server. An alternative is to have users share a single database and database engine instance. But then special care is needed to prevent cross-tenant accesses. Second, users want an SLA that defines the level of performance and availability they need. Data PaaS providers want to offer SLAs too, to enable tiered pricing. However, it is challenging to define SLAs that are understandable to users and implementable by PaaS providers. The implementation challenge is to ensure performance isolation between tenants, to ensure a burst of demand from one tenant does not cause a violation of other tenants' SLAs.
Data sharing. The cloud enables sharing at an unprecedented scale. One problem is how to support essential services such as data curation and provenance collaboratively in the cloud. Other problems include: how to find useful public data, how to relate self-managed private data with public data to add context, how to find high-quality data in the cloud, how to share data at fine-grained levels, how to distribute costs when sharing computing and data, and how to price data. The cloud also creates new life-cycle challenges, such as how to protect data if the current cloud provider fails and to preserve data for the long term when users who need it have no personal or financial connection to those who provide it. The cloud will also drive innovation in tools for data governance, such as auditing, enforcement of legal terms and conditions, and explanation of user policies.
Hybrid clouds. There is a need for interoperation of database services among the cloud, on-premise servers, and mobile devices. One scenario is off-loading. For example, users may run applications in their private cloud during normal operation, but tap into a public cloud at peak times or in response to unanticipated workload surges. Another is cyber-physical systems, such as the Internet of Things. For example, cars will gather local sensor data, upload some of it into the cloud, and obtain control information in return based on data aggregation from many sources. Cyber-physical systems involve data streaming from multiple sensors and mobile devices, and must cope with intermittent connectivity and limited battery life, which pose difficult challenges for real-time and perhaps mission-critical data management in the cloud.
We need to build platforms that allow people to curate data easily and extend relevant applications to incorporate such curation.
Roles of humans in the data life cycle. Back when data management was an enterprise-driven activity, roles were clear: developers built databases and database-centric applications, business analysts queried databases using (SQL-based) reporting tools, end users generated data and queried and updated databases, and database administrators tuned and monitored databases and their workloads. Today, a single individual can play multiple roles in the data life cycle, and some roles may be served by crowdsourcing. Thus, human factors need to be considered for query understanding and refinement, identifying relevant and trustworthy information sources, defining and incrementally refining the data processing pipeline, visualizing relevant patterns, obtaining query answers, and making the various micro-tasks doable by domain experts and end users. We can classify people's roles into four general categories: producers, curators, consumers, and community members.
Data producers. Today, virtually anyone can generate a torrent of data from mobile phones, social platforms and applications, and wearable devices. One key challenge for the database community is to develop algorithms and incentives that guide people to produce and share the most useful data, while maintaining the desired level of data privacy. When people produce data, how can we help them add metadata quickly and accurately? For example, when a user uploads an image, Facebook automatically identifies faces in the image so users can optionally tag them. Another example is tools to automatically suggest tags for a tweet. What else can we do, and what general principles and tools can we provide?
Data curators. Data is no longer just in databases controlled by a DBA and curated by the IT department. Now, a wide variety of people are empowered to curate it. Crowdsourcing is one approach. A key challenge, then, is to obtain high-quality datasets from a process based on often-imperfect human curators. We need to build platforms that allow people to curate data easily and extend relevant applications to incorporate such curation. For these people-centric challenges, data provenance and explanation will be crucial, as will privacy and security.
Data consumers. People want to use messier data in complex ways, raising many challenges. In the enterprise, data consumers usually know how to ask SQL queries, over a structured database. Today's data consumers may not know how to formulate a query at all, for example, a journalist who wants to "find the average temperature of all cities with population over 100,000 in Florida" over a structured dataset. Enabling people to get such answers themselves requires new query interfaces, for example, based on multi-touch, not just console-based SQL. We need multimodal interfaces that combine visualization, querying, and navigation. When the query to ask is not clear, people need other ways to browse, explore, visualize, and mine the data, to make data consumption easier.
Online communities. People want to create, share, and manage data with other community members. They may want to collaboratively build community-specific knowledge bases, wikis, and tools to process data. For example, many researchers have created their own pages on Google Scholar, thereby contributing to this "community" knowledge base. Our challenge is to build tools to help communities produce usable data as well as to exploit, share, and mine it.
- Community Challenges
In addition to research challenges, the database field faces many community issues. These include database education, data science, and research culture. Some of these are new, brought about by big data. Other issues, while not new, are exacerbated by big data and are becoming increasingly important.
Database education. The database technology taught in standard database courses today is increasingly disconnected from reality. It is rooted in the 1980s, when memory was small relative to database size, making I/O the bottleneck to most database operations, and when servers used relatively expensive single-core processors. Today, many databases fit in main memory, and many-core servers make parallelism and cache behavior critical to database performance. Moreover, although SQL DBMSs are still widely used, so are key-value stores, data stream processors, and MapReduce frameworks. It is time to rethink the database curriculum.
Data science. As we discussed earlier, big data has generated a rapidly growing demand for data scientists who can transform large volumes of data into actionable knowledge. Data scientists need skills not only in data management, but also in business intelligence, computer systems, mathematics, statistics, machine learning, and optimization. New cross-disciplinary programs are needed to provide this broad education. Successful research and educational efforts related to data science will require close collaboration with these other disciplines and with domain specialists. Big data presents computer science with an opportunity to influence the curricula of chemistry, earth sciences, sociology, physics, biology, and many other fields. The small computer science parts of those curricula could be grown and redirected to give data management and data science a more prominent role.
Research culture. Finally, there is much concern over the increased emphasis of citation counts instead of research impact. This discourages large systems projects, end-to-end tool building, and sharing of large datasets, since this work usually takes longer than solving point problems. Program committees that value technical depth on narrow topics over the potential for real impact are partly to blame. It is unclear how to change this culture. However, to pursue the big data agenda effectively, the field needs to return to a state where fewer publications per researcher per time unit is the norm, and where large systems projects, end-to-end tool sets, and data sharing are more highly valued.
- Going Forward
This is an exciting time for database research. In the past it has been guided by, but also restricted by, the rigors of the enterprise and relational database systems. The rise of big data and the vision of a data-driven world present many exciting new research challenges related to processing big data; handling data diversity; exploiting new hardware, software, and cloud-based platforms; addressing the data life cycle, from creating data to analyzing and sharing it; and facing the diversity, roles, and number of people related to all aspects of data. It is also time to rethink approaches to education, involvement with data consumers, and our value system and its impact on how we evaluate, disseminate, and fund our research.
- Acknowledgments
We thank the reviewers for invaluable suggestions. The Beckman meeting was supported by donations from the Professor Ram Kumar Memorial Foundation, Microsoft Corporation, and @WalmartLabs.
1. Abiteboul, S. et al. The Lowell database research self-assessment. Commun. ACM 48, 5 (May 2005), 111–118.
2. Agrawal, R. et al. The Claremont report on database research. Commun. ACM 52, 6 (June 2009), 56–65.
3. Apache Software Foundation. Apache Hadoop; http://hadoop.apache.org , accessed Sept. 12, 2014.
4. Apache Software Foundation. Apache Hive; http://hive.apache.org , accessed on Nov. 9, 2014.
5. Apache Software Foundation. Apache Pig; http://pig.apache.org , accessed on July 4, 2014.
6. Bernstein, P. et al. Future directions in DBMS research—The Laguna Beach participants. ACM SIGMOD Record 18, 1 (1989), 17–26.
7. Bernstein, P. et al. The Asilomar report on database research. ACM SIGMOD Record 27, 4 (1998), 74–80.
8. [C11] Cattell, R. Scalable SQL and NoSQL data stores. SIGMOD Record 39, 4 (2011), 12–27.
9. Dean, J. and Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 51, 1 (2008), 107–113.
10. Silberschatz, A. et al. Strategic directions in database systems—breaking out of the box. ACM Computing Surveys 28, 4 (1996), 764–778.
11. Silberschatz, A., Stonebraker, M. and Ullman, J.D. Database systems: Achievements and opportunities. Commun. ACM 34, 10 (Oct. 1991), 110–120.
12. Silberschatz, A., Stonebraker, M. and Ullman, J.D. Database research: Achievements and opportunities into the 21 st century. ACM SIGMOD Record 25, 1 (1996), 52–63.
The following authors served as editors of this article (the third author also served as corresponding author):
Philip A. Bernstein ( [email protected] ) is a Distinguished Scientist at Microsoft Research, Redmond, WA.
Michael J. Carey ( [email protected] ) is a professor in the Bren School of Information and Computer Sciences at the University of California, Irvine.
AnHai Doan ( [email protected] ) is a professor in the Department of Computer Science at the University of Wisconsin-Madison.
©2016 ACM 0001-0782/16/02
Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and full citation on the first page. Copyright for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or fee. Request permission to publish from [email protected] or fax (212) 869-0481.
The Digital Library is published by the Association for Computing Machinery. Copyright © 2016 ACM, Inc.
No entries found
Article Contents:
- Introduction
Medical Imaging Fails Dark Skin. Researchers Fixed It
Disinformation 2.0 in the age of ai: a cybersecurity perspective, all photos are fake until proven real.
Read our research on: Gun Policy | International Conflict | Election 2024
Regions & Countries
Most americans favor legalizing marijuana for medical, recreational use, legalizing recreational marijuana viewed as good for local economies; mixed views of impact on drug use, community safety.
Pew Research Center conducted this study to understand the public’s views about the legalization of marijuana in the United States. For this analysis, we surveyed 5,140 adults from Jan. 16 to Jan. 21, 2024. Everyone who took part in this survey is a member of the Center’s American Trends Panel (ATP), an online survey panel that is recruited through national, random sampling of residential addresses. This way nearly all U.S. adults have a chance of selection. The survey is weighted to be representative of the U.S. adult population by gender, race, ethnicity, partisan affiliation, education and other categories. Read more about the ATP’s methodology .
Here are the questions used for the report and its methodology .
As more states pass laws legalizing marijuana for recreational use , Americans continue to favor legalization of both medical and recreational use of the drug.

An overwhelming share of U.S. adults (88%) say marijuana should be legal for medical or recreational use.
Nearly six-in-ten Americans (57%) say that marijuana should be legal for medical and recreational purposes, while roughly a third (32%) say that marijuana should be legal for medical use only.
Just 11% of Americans say that the drug should not be legal at all.
Opinions about marijuana legalization have changed little over the past five years, according to the Pew Research Center survey, conducted Jan. 16-21, 2024, among 5,14o adults.
The impact of legalizing marijuana for recreational use
While a majority of Americans continue to say marijuana should be legal , there are varying views about the impacts of recreational legalization.

About half of Americans (52%) say that legalizing the recreational use of marijuana is good for local economies; just 17% think it is bad and 29% say it has no impact.
More adults also say legalizing marijuana for recreational use makes the criminal justice system more fair (42%) than less fair (18%); 38% say it has no impact.
However, Americans have mixed views on the impact of legalizing marijuana for recreational use on:
- Use of other drugs: About as many say it increases (29%) as say it decreases (27%) the use of other drugs, like heroin, fentanyl and cocaine (42% say it has no impact).
- Community safety: More Americans say legalizing recreational marijuana makes communities less safe (34%) than say it makes them safer (21%); 44% say it has no impact.
Partisan differences on impact of recreational use of marijuana
There are deep partisan divisions regarding the impact of marijuana legalization for recreational use.

Majorities of Democrats and Democratic-leaning independents say legalizing recreational marijuana is good for local economies (64% say this) and makes the criminal justice system fairer (58%).
Fewer Republicans and Republican leaners say legalization for recreational use has a positive effect on local economies (41%) and the criminal justice system (27%).
Republicans are more likely than Democrats to cite downsides from legalizing recreational marijuana:
- 42% of Republicans say it increases the use of other drugs, like heroin, fentanyl and cocaine, compared with just 17% of Democrats.
- 48% of Republicans say it makes communities less safe, more than double the share of Democrats (21%) who say this.
Demographic, partisan differences in views of marijuana legalization
Sizable age and partisan differences persist on the issue of marijuana legalization though small shares of adults across demographic groups are completely opposed to it.

Older adults are far less likely than younger adults to favor marijuana legalization.
This is particularly the case among adults ages 75 and older: 31% say marijuana should be legal for both medical and recreational use.
By comparison, half of adults between the ages of 65 and 74 say marijuana should be legal for medical and recreational use, and larger shares in younger age groups say the same.
Republicans continue to be less supportive than Democrats of legalizing marijuana for both legal and recreational use: 42% of Republicans favor legalizing marijuana for both purposes, compared with 72% of Democrats.
There continue to be ideological differences within each party:
- 34% of conservative Republicans say marijuana should be legal for medical and recreational use, compared with a 57% majority of moderate and liberal Republicans.
- 62% of conservative and moderate Democrats say marijuana should be legal for medical and recreational use, while an overwhelming majority of liberal Democrats (84%) say this.
Views of marijuana legalization vary by age within both parties
Along with differences by party and age, there are also age differences within each party on the issue.

A 57% majority of Republicans ages 18 to 29 favor making marijuana legal for medical and recreational use, compared with 52% among those ages 30 to 49 and much smaller shares of older Republicans.
Still, wide majorities of Republicans in all age groups favor legalizing marijuana at least for medical use. Among those ages 65 and older, just 20% say marijuana should not be legal even for medical purposes.
While majorities of Democrats across all age groups support legalizing marijuana for medical and recreational use, older Democrats are less likely to say this.
About half of Democrats ages 75 and older (53%) say marijuana should be legal for both purposes, but much larger shares of younger Democrats say the same (including 81% of Democrats ages 18 to 29). Still, only 7% of Democrats ages 65 and older think marijuana should not be legalized even for medical use, similar to the share of all other Democrats who say this.
Views of the effects of legalizing recreational marijuana among racial and ethnic groups

Substantial shares of Americans across racial and ethnic groups say when marijuana is legal for recreational use, it has a more positive than negative impact on the economy and criminal justice system.
About half of White (52%), Black (53%) and Hispanic (51%) adults say legalizing recreational marijuana is good for local economies. A slightly smaller share of Asian adults (46%) say the same.
Criminal justice
Across racial and ethnic groups, about four-in-ten say that recreational marijuana being legal makes the criminal justice system fairer, with smaller shares saying it would make it less fair.
However, there are wider racial differences on questions regarding the impact of recreational marijuana on the use of other drugs and the safety of communities.
Use of other drugs
Nearly half of Black adults (48%) say recreational marijuana legalization doesn’t have an effect on the use of drugs like heroin, fentanyl and cocaine. Another 32% in this group say it decreases the use of these drugs and 18% say it increases their use.
In contrast, Hispanic adults are slightly more likely to say legal marijuana increases the use of these other drugs (39%) than to say it decreases this use (30%); 29% say it has no impact.
Among White adults, the balance of opinion is mixed: 28% say marijuana legalization increases the use of other drugs and 25% say it decreases their use (45% say it has no impact). Views among Asian adults are also mixed, though a smaller share (31%) say legalization has no impact on the use of other drugs.
Community safety
Hispanic and Asian adults also are more likely to say marijuana’s legalization makes communities less safe: 41% of Hispanic adults and 46% of Asian adults say this, compared with 34% of White adults and 24% of Black adults.
Wide age gap on views of impact of legalizing recreational marijuana

Young Americans view the legalization of marijuana for recreational use in more positive terms compared with their older counterparts.
Clear majorities of adults under 30 say it is good for local economies (71%) and that it makes the criminal justice system fairer (59%).
By comparison, a third of Americans ages 65 and older say legalizing the recreational use of marijuana is good for local economies; about as many (32%) say it makes the criminal justice system more fair.
There also are sizable differences in opinion by age about how legalizing recreational marijuana affects the use of other drugs and the safety of communities.
Sign up for our Politics newsletter
Sent weekly on Wednesday
Report Materials
Table of contents, most americans now live in a legal marijuana state – and most have at least one dispensary in their county, 7 facts about americans and marijuana, americans overwhelmingly say marijuana should be legal for medical or recreational use, clear majorities of black americans favor marijuana legalization, easing of criminal penalties, religious americans are less likely to endorse legal marijuana for recreational use, most popular.
About Pew Research Center Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
IMAGES
VIDEO
COMMENTS
Report. Abstract: Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that Big Data has now become a ...
The Beckman Report on Database Research. Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14- 15, ...
ideas about data valuation and ownership, and the emerging data economy, also need to be consid-ered and may a ect our training programs and research agendas. However, we will not focus on these aspects in this report. Over the two days of the Beckman meeting, participants extensively discussed the above issues.
The Beckman Report on Database Research; The Beckman Report on Database Research. Daniel J. Abadi Rakesh Agrawal Anastasia Ailamaki Magdalena Balazinska Philip A. Bernstein Michael J. Carey ...
The Beckman Report on Database Research. Database researchers paint big data as a defining challenge. To make the most of the enormous opportunities at hand will require focusing on five research areas. A group of database researchers meets periodically to discuss the state of the field and its key directions going forward.
Abstract. Abstract Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the ...
The Beckman Report on Database Research. Daniel J. Abadi; Rakesh Agrawal; Anastasia Ailamaki; Magdalena Balazinska; ... Data Management. Learn more about how we do research We maintain a portfolio of research projects, providing individuals and teams the freedom to emphasize specific types of work.
Abstract. Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14- 15, 2013 in Irvine, California. It observes that Big Data has now become a defining ...
It is observed that Big Data has now become a defining challenge of the authors' time, and that the database research community is uniquely positioned to address it, with enormous opportunities to make transformative impact. Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report ...
Database researchers paint big data as a defining challenge. To make the most of the enormous opportunities at hand will require focusing on five research areas. The Beckman report on database research | Communications of the ACM
This report summarizes the discussion and conclusions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that Big Data has now become a defining challenge of our time, and that the database research community is uniquely positioned to address it, with enormous opportunities to make transformative impact.
The Beckman report on database research. Communications of the ACM | February 2016 , Vol 59 (2): pp. 92-99. DOI. Database researchers paint big data as a defining challenge. To make the most of the enormous opportunities at hand will require focusing on five research areas.
The Beckman report on database research @article{Abadi2016TheBR, title={The Beckman report on database research}, author={Daniel J. Abadi and Rakesh Agrawal and Anastasia Ailamaki and Magdalena Balazinska and Philip A. Bernstein and Michael J. Carey and Surajit Chaudhuri and Jeffrey Dean and AnHai Doan and Michael J. Franklin and Johannes ...
The beckman report on database research. Daniel Abadi, Rakesh Agrawal, Anastasia Ailamaki, Magdalena Balazinska, Philip A. Bernstein, Michael J. Carey, Surajit Chaudhuri, Jeffrey Dean, Anhai Doan, ... Research output: Contribution to journal › Review article › peer-review.
To do so, the report recommends significantly more attention to five research areas: scalable big/fast data infrastructures; coping with diversity in the data management landscape; end-to-end processing and understanding of data; cloud services; and managing the diverse roles of people in the data life cycle.
Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclusions of the eighth such meeting, held October 14- 15, 2013 in Irvine, California. It observes that Big Data has now become a defining challenge of our time, and that the database research ...
Abstract. Every few years a group of database researchers meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and. conclusions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that.
@article{bernstein2016the, author = {Bernstein, Phil and Chaudhuri, Surajit and Gehrke, Johannes and al, et}, title = {The Beckman report on database research}, year = {2016}, month = {February}, abstract = {Database researchers paint big data as a defining challenge.
meets to discuss the state of database research, its impact on practice, and important new directions. This report summarizes the discussion and conclu-sions of the eighth such meeting, held October 14-15, 2013 in Irvine, California. It observes that Big Data has now become a defining challenge of our time, and that the database research ...
Explore Research Products in the NSF-PAR. Search For Terms: ... The Beckman Report on Database Research; Citation Details; ...
ReALM: Reference Resolution As Language Modeling. Reference resolution is an important problem, one that is essential to understand and successfully handle context of different kinds. This context includes both previous turns and context that pertains to non-conversational entities, such as entities on the user's screen or those running in the ...
Four years and more than 100 reports ago David Lazer formed the COVID States Project to analyze the pandemic with objectivity. ... a Northeastern-led effort by four universities that would analyze newly collected data in order to make sense of the evolving and volatile COVID-19 ... "The project is a landmark in survey research," says Alexi ...
The Beckman report on database research. Commun. ACM 59, 2 (Feb. 2016), 92--99. Google Scholar Digital Library; Abadi, D. et al. The Seattle report on database research. SIGMOD Rec. 48, 4 (2019) 44--53 (2019) Google Scholar; Abiteboul, S. et al. The Lowell database research self-assessment.
About half of U.S. adults (51%) say the country's public K-12 education system is generally going in the wrong direction. A far smaller share (16%) say it's going in the right direction, and about a third (32%) are not sure, according to a Pew Research Center survey conducted in November 2023.
"The 2023 increase is the third-largest in the past decade, likely a result of an ongoing increase of fossil fuel CO 2 emissions, coupled with increased fire emissions possibly as a result of the transition from La Nina to El Nino," said Xin Lan, a CIRES scientist who leads GML's effort to synthesize data from the NOAA Global Greenhouse ...
The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Our mission is to provide unbiased, rigorously vetted, broadly sourced data in order for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI.
A group of database researchers meets periodically to discuss the state of the field and its key directions going forward. Past meetings were held in 1989, 6 1990, 11 1995, 12 1996, 10 1998, 7 2003, 1 and 2008. 2
And Americans' use of the chatbot is ticking up: 23% of U.S. adults say they have ever used it, according to a Pew Research Center survey conducted in February, up from 18% in July 2023. The February survey also asked Americans about several ways they might use ChatGPT, including for workplace tasks, for learning and for fun.
A 57% majority of Republicans ages 18 to 29 favor making marijuana legal for medical and recreational use, compared with 52% among those ages 30 to 49 and much smaller shares of older Republicans. Still, wide majorities of Republicans in all age groups favor legalizing marijuana at least for medical use. Among those ages 65 and older, just 20% ...